基于句對質量和覆蓋度的統計機器翻譯訓練語料選取
2011-06-28 01:55:44姚樹杰朱靖波
中文信息學報 2011年2期
姚樹杰,肖 桐,朱靖波
(1. 東北大學 自然語言處理實驗室,遼寧 沈陽 110004;2. 醫學影像計算教育部重點實驗室(東北大學),遼寧 沈陽 110819)
1 引言
在統計機器翻譯(Statistical Machine Translation,簡寫為SMT)領域[1-2],系統的訓練需要有大規模的高質量雙語句對語料庫的支持。一般來說增加訓練語料規模有助于獲得穩定的模型參數和SMT系統翻譯性能的提高。但是訓練語料越多,訓練和解碼需要的時間越長,并且平行語料中存在的一些噪聲數據,也會影響到訓練的可靠性。
呂雅娟[1,3]等人曾提出一種基于信息檢索模型的統計機器翻譯訓練數據選擇與優化方法,她們通過選擇現有訓練數據資源中與待翻譯文本相似的句子組成訓練子集,在不增加計算資源的情況下獲得與使用全部數據相當甚至更好的機器翻譯結果。
但是,在實際應用中,待翻譯文本往往是未知的,Eck等[4]對不依賴于待翻譯文本的訓練語料選取技術進行了研究。他們提出一種基于N-gram的覆蓋度的方法來構建一個較小規模的訓練語料子集,并且用這個子集達到了一個和原始全部語料相比可觀的翻譯性能。
此外,多數平行語料庫包含著錯誤或噪音,它們也會對統計機器翻譯系統的性能產生影響。如果能對雙語語料(句對)進行有效地評價,也會有助于除去噪聲,選擇更加優質的數據來訓練統計機器翻譯系統。針對雙語語料的質量評價的問題,陳毅東,史曉東[5]等曾研究了一種面向處理平行語料庫的篩選的排序模型。這個模型利用預先設定的特征將已有的平行語料進行打分排序,之后選取分數靠前的部分組成訓練語料。
為了更有效地對統計機器翻譯語料進行篩選來降低SMT系統訓練和解碼的代價,本文提出了一種從大規模訓練語料中選取小規模高質量子集的方法。該方法同時考慮了語料本身的質量和整體的覆蓋度因素來選取訓練語料。實驗結果表明本文的方法在近百萬規模訓練語料上取得了明顯的效果,使用選取的小規模(原始語料的20%)數據即達到了與使用全部數據時相接近的翻譯性能。
2 訓練語料子集選取框架
本文提出方法的基本框架為:輸入原始大規模訓練語料;首先對每一句對的質量進行自動評價并給出一個分數;然后,按質量評價分數的高低對句對排序;在句對按質量排序的基礎上考慮覆蓋度的因素,動態選取一個子集;輸出從原始語料中選取的子集作為SMT系統的訓練語料。

圖1 基于句對質量評價和覆蓋度的訓練語料子集選取框架
整個框架大致分為兩個部分:句對質量的評價和基于覆蓋度的訓練語料選取。利用②整合不同的特征來綜合評價句對質量(見第3節)。③整個語料的候選句對按質量評價分數的高低排序;④考慮覆蓋度選取語料的一個子集作為訓練數據(基于覆蓋度選取訓練語料的流程在第4節做詳細描述)。下面對句對質量的評價和基于覆蓋度的訓練語料選取技術進行討論。
3 句對質量評價
從現有語料中選取一個高質量的相對規模較小的訓練子集,就單個句對來講,我們希望優先考慮的是那種質量較好的個體。假定質量高的句對需滿足以下條件:①構成句對的源語句和目標語句都是比較流暢的句子。②源語句和目標語句的互譯比較準確。基于這樣的考慮,本文提出一種線性模型整合不同特征來綜合評價句對的質量,后面將詳細介紹。
3.1 句對質量評價方法
為描述雙語句對的好壞本文引入三類特征:基于雙語詞典的翻譯質量,語言模型,翻譯模型概率。最后,在3.1.4中本文提出一種線性模型整合這些特征來綜合評價句對質量。
3.1.1 特征一:基于雙語翻譯詞典的翻譯質量
利用現有雙語翻譯詞典,本文給出下式來評價句對翻譯質量:
(1)
其中,s是表示源語言句子,t表示目標語句子;ws和wt分別表示雙語句對源語句中的詞和目標句的詞;length(s)和length(t)分別表示源語句和目標語句的長度(即包含的詞的個數);ΣwsTranslate(ws)表示源語句中所有在目標句能找到譯文的詞的總數;ΣwtTranslate(wt)表示目標句中所有在源語句能找到譯文的詞的總數。對于Translate(w),如果詞在它對應的目標與句子中存在翻譯項則為1,否則為0。
3.1.2 特征二:語言模型
引入語言模型的目的是考察每一句對的單語部分是否流暢。本文把候選訓練語料句對的源語句語言模型和目標語句的語言模型作為兩個特征加入到句對質量評價線性模型中。假設句子中單詞的出現概率僅與其前面的N-1個單詞有關,句長為n的句子用語言模型概率來考察候選句的流暢度表示如下:
(2)
其中PLM(w)的下標LM是Language Model的簡寫。語言模型參數在大規模雙語訓練語料上訓練得到。實驗中對句對的中文句和英文句分別計算其五元語言模型(N=5),每個句子的語言模型按句子長度進行了歸一化處理。
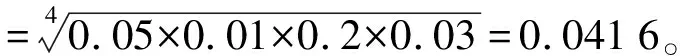
3.1.3 特征三:翻譯模型概率
本文對IBM model 1 翻譯模型在假設基礎上進行了進一步簡化,并計算句對源語言到目標語和目標語到源語句翻譯概率作為衡量一個句對翻譯質量的特征。
對于句對(f,e),假定源語句f有m個詞,目標語句e有l個詞。假設所有源語句的詞至多有一個目標語詞對齊,對齊概率只依賴于t(fj|ei),對于每一個源語單詞我們在目標語中尋找一個最能解釋它的目標語詞;每個源語句中的詞僅由和它對齊的那個目標語詞生成;忠誠度不依賴于目標語和源語句的長度。在此基礎上,用下面的式子表示每一句對目標語對源語翻譯的忠誠度。
(3)
其中,t(fj|ei)表示句子e的第i個詞到句f第j個詞的翻譯概率。PTM(w)的下標TM是Translate Model的簡寫。源語句對目標語句的忠誠度也類似表示。
3.1.4 句對質量評價線性模型
怎樣考慮前述的特征來綜合評價句對質量的好壞?用Q(f,e)來表示句對(f,e)的質量,本文通過下面的表達形式整合以上提到的特征:
(4)
k表示該模型整合的特征的個數。e與f分別表示句對的源語句和目標語句;這里wi分別表示每個對應特征的權重,每個權重可在人工構造的少量訓練集上通過自動或人工的方法得到。為實現的方便,本文暫時采用了人工的方法。
本文相關實驗k=5,P1到P5依次指Pdic(f,e),PLM(e),PLM(f),PTM(f|e),PTM(e|f)。
4 基于覆蓋度的訓練語料選取
4.1 考慮覆蓋度的動機
從原始語料中選取一個子集作為訓練語料,是要用有限的語料覆蓋盡可能多的語言現象,句對之間也不應該存在太多冗余。假如說句對質量評價是考慮這種語言現象的可靠性,那么覆蓋度就是要保證要包含廣泛的語言現象。本文認為一個較好的訓練子集要有足夠的覆蓋度,并且本文的有關實驗也表明,相同規模的數據,高的冗余會導致不好的訓練效果,這也是本文在選取訓練子集時考慮覆蓋度的一個原因。
4.2 基于覆蓋度的訓練語料子集選取
本文比較了包括N-gram在內的三種不同覆蓋度,采用一種動態的考慮覆蓋度的方法來重新分布訓練語料,最后從重新分布的語料中取前N個句對構成一個子集作為訓練語料。
覆蓋度大小的衡量分別比較三個參考指標:①詞的覆蓋;②N-gram(包括Unigram Bigram Trigram)的覆蓋;③短語翻譯對的覆蓋。
參照覆蓋度選取訓練語料子集:用候選訓練語料的第一個句對作為所選出的訓練語料子集的第一個元素,然后依次向后掃描候選語料,如果當前的句對對增加已選訓練語料子集覆蓋度有貢獻(比如包含新的短語翻譯對),則優先選擇這個句對添加到訓練語料子集。
5 結合句對質量和覆蓋度的訓練語料選取框架
本文的平行語料選取框架綜合考慮了句對質量和覆蓋度,利用句對質量評價線性模型將候選語料的全部句對按質量打分排序,之后按4.2節所述的考慮覆蓋度選取訓練子集的方法從按句對質量排序的語料中選出一個子集作為訓練語料,具體如算法1所示。
算法1基于句對質量和覆蓋度的訓練語料選取
輸入:候選平行語料D={(s1,t1),(s2,t2),…}
輸出:選出的小規模的訓練語料
算法:
step1. 循環Forifrom 1 ton//i表示句對編號,用句對質量評價線性模型給句對(si,ti)打分;
step2. 所有句對按step1得到的句對按質量分數高低排序,得到重排序的訓練語料集Dq;
step3. 從前往后掃描Dq,按優先考慮覆蓋度的方法選出一個子集,輸出這個子集作為所選訓練語料。
6 相關實驗與分析
6.1 Baseline系統
Baseline系統描述:本文實驗所使用的統計機器翻譯系統為東北大學自然語言處理實驗室開發的基于短語的統計機器翻譯系統[6-7],系統實現采用對數線性模型。分詞采用東北大學自然語言處理實驗室分詞系統;詞對齊使用GIZA++工具。實驗數據使用CWMT2008語料預處理后的70萬,將句對的分布先后順序隨機排列,從首句對起順次分別取1%,5%,10%,20%,(30%),40%,60%,80%和100%作為Baseline訓練語料,利用SMT系統的BLEU值來估計這些不同規模訓練數據的質量。另外的一些實驗相關信息如表1所示。
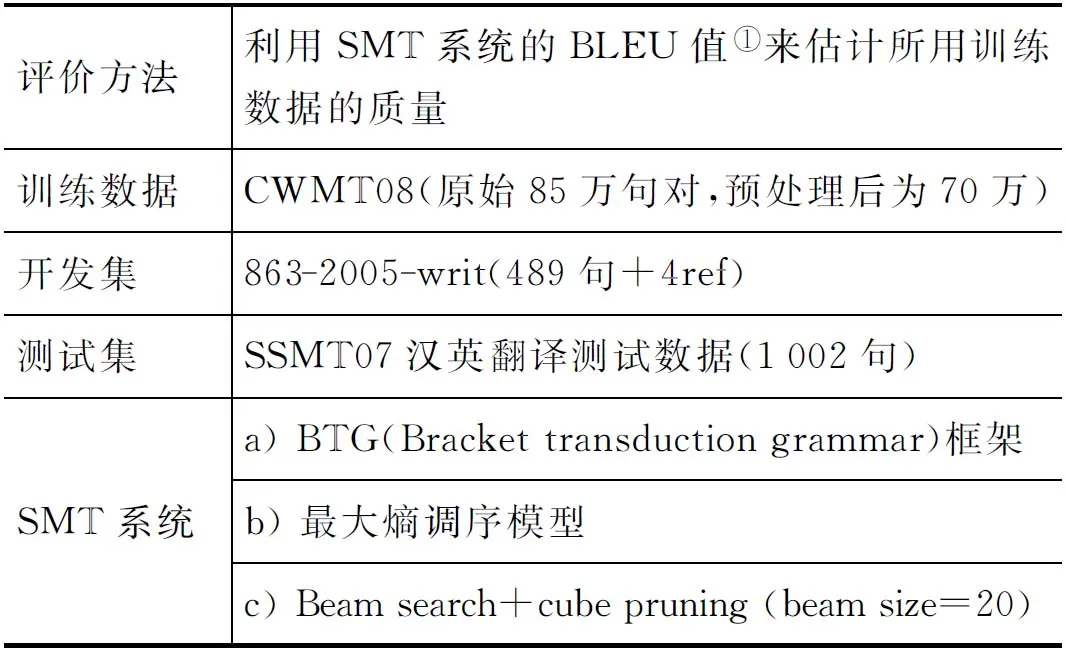
表1 一些實驗相關信息
6.2 不同覆蓋度指標的比較實驗
只考慮覆蓋度,用4.2節提到的方法分別以詞,N-gram和短語翻譯對(Phrase pair)為覆蓋度指標,從原始未經句對質量評價的語料中選取不同規模子集作為訓練語料,其效果與Baseline做了比較。需要注意的是:詞是指源語言出現的詞(Unigram除去禁用詞);短語翻譯對從候選的平行句對獲得,參考了文獻[8]中的方法;N-gram實驗中n=1,2,3,同時包含Unigram Bigram 和Trigram。
實驗結果如圖2,縱坐標表示選取不同規模語料作為訓練數據所達到的機器翻譯性能(用BLEU值表示),橫坐標表示所用數據占整個原始語料的百分比。不難發現在選取的語料規模比較小時,優先考慮語料的覆蓋度,能夠很大程度上影響SMT系統的訓練效果,并且相同規模上用短語翻譯對(Phrase pair)作為覆蓋度指標選取的語料訓練效果要好于基于詞(unigram)和基于N-gram(unigram~trigram),三個指標中使用短語翻譯對達到的效果最明顯。
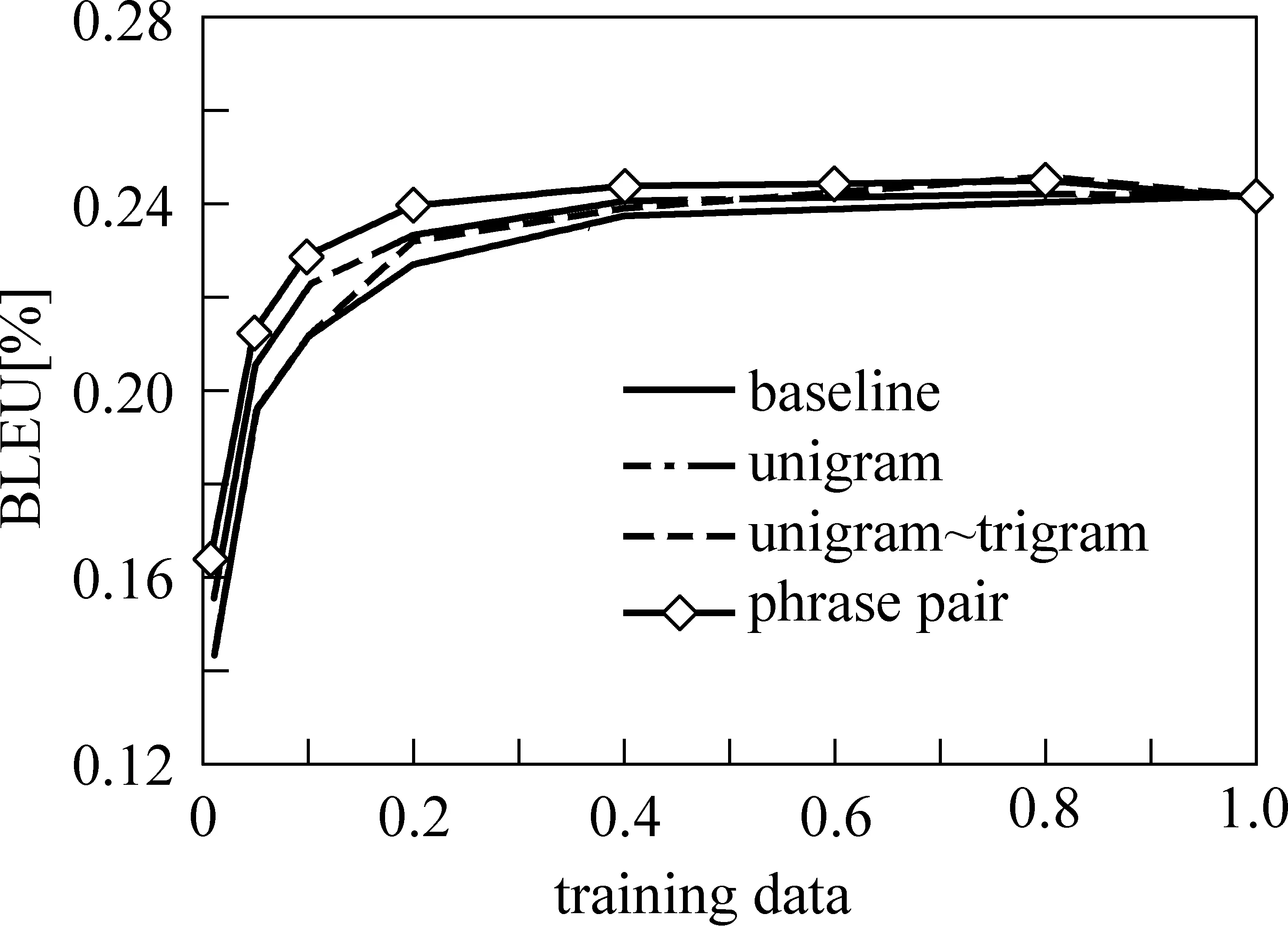
圖2 依不同覆蓋度指標選取的語料的訓練效果比較
Baseline不考慮覆蓋度隨機選取數據作為訓練語料,至少用60%訓練語料達到BLEU值(0.239 8)與用全部語料時的BLEU值(0.242 4)相接近。而通過考慮覆蓋度來選取,基于詞(Unigram)選取40%語料達到0.241 1,N-gram(unigram~trigram)選取40%達到0.239 6,而以短語翻譯對覆蓋度選取僅占全部候選語料20%的數據就達到了0.240 4,與使用全部語料的水平(0.242 4)相接近。而Baseline用20%的數據達到的性能僅為0.227 7。實驗結果表明訓練語料的覆蓋度對訓練效果有很大影響,尤其當要選取的語料規模較小時覆蓋度就顯得更加重要。
通過這個實驗的結果,也不難看到考慮覆蓋度來選取語料子集要比隨機選取的相同規模的語料的訓練效果好;另外分析所用的三個覆蓋度指標,詞或N-gram作為覆蓋度指標僅考慮了單語,而短語翻譯對覆蓋度指標是在詞對齊基礎上同時考慮雙語信息,相比其他兩個對選取高質量SMT平行訓練語料的影響更大。
6.3 綜合考慮句對翻譯質量和覆蓋度來選取語料實驗
用3.1.4節中提到的句對質量評價線性模型來評價候選句對的質量。實驗中本文暫時采用了人工的方法來設定各個特征的權重:權值開始設置為1,然后人工觀察在較小訓練集合上的自動句對質量評價結果,之后再根據這個結果的合理性,對權值進行調整,如此反復多次,最后每一個特征的權重由人工給定一個認為合理的經驗值。
實驗中分別為0.1,0.5,0.5,0.5,0.5。另外,實驗中選用短語翻譯對作為覆蓋度指標。綜合考慮句對質量和覆蓋度,按照圖1所示整個框架流程來選取訓練語料。選取的訓練語料子集分別為全部原始語料規模的1%,5%,10%,20%,30%,40%,60%,80%,100%,并與Baseline做對比。圖3 中our method曲線表示利用本文提到的框架,綜合考慮句對質量和覆蓋度選取的訓練語料所達到的翻譯性能。可以看出,利用本文的方法從較大規模平行語料中選取較小的子集作為訓練語料能使機器翻譯性能明顯高于Baseline,甚至用20%的句對就到達了與用全部訓練語料時相接近的性能。實驗表明本文所提出的方法用在高質量訓練語料子集的選取上是有效的。
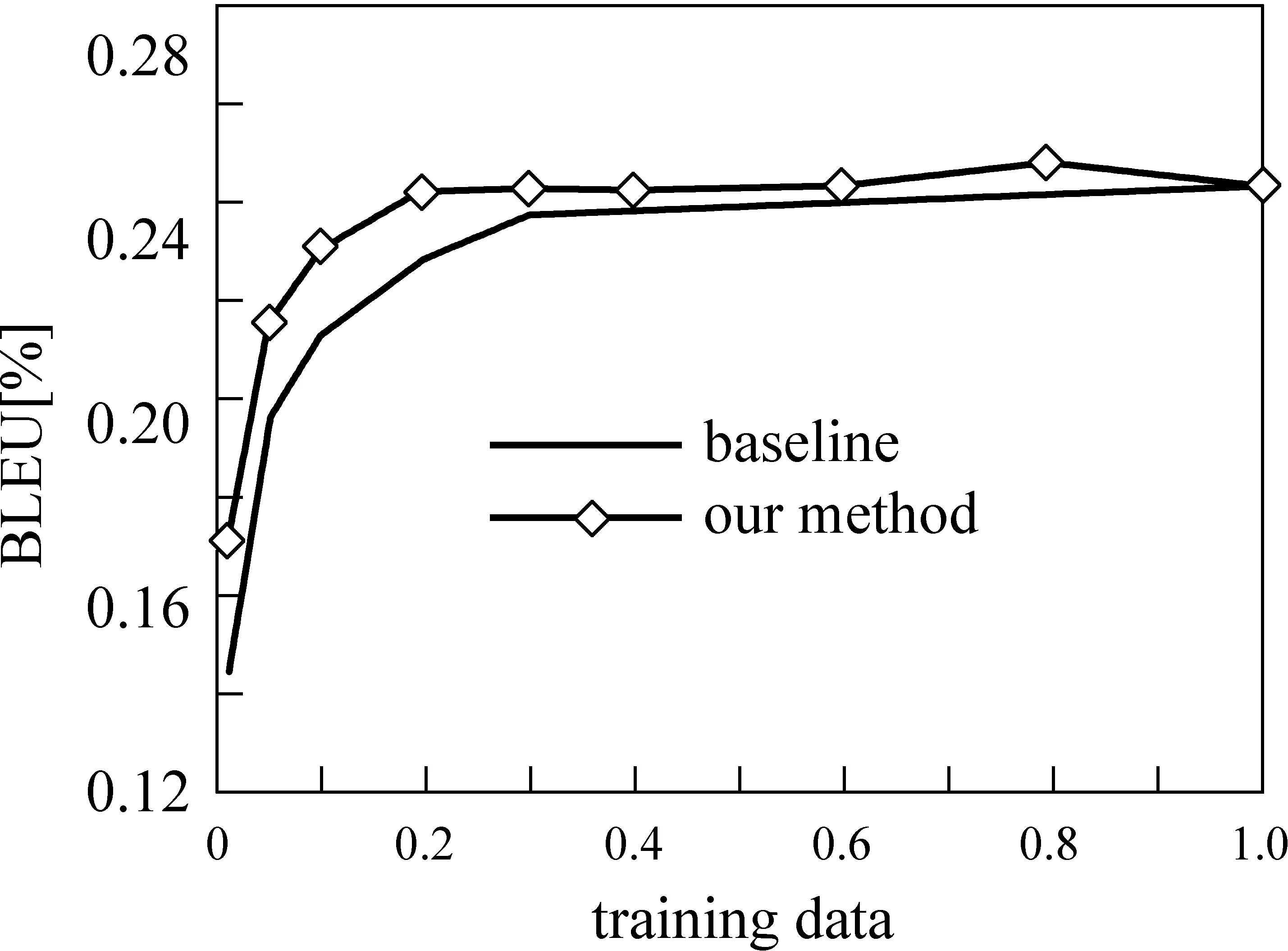
圖3 本文方法選取的不同規模訓練語料訓練與Baseline的比較
6.4 引入句對質量評價的影響
評價本文句對質量評價模型不是件很容易的事,我們通過比較引入句對翻譯質量評價前后所選取的相等規模的數據的訓練效果來間接考察句對質量評價方法的有效性。
通過比較兩組實驗的數據可以發現,在句對質量評價基礎上考慮覆蓋度選取訓練語料子集的效果要優于單純考慮覆蓋度;反映在BLEU值上如表2(這里的覆蓋度僅指短語翻譯對的覆蓋)。可以看出,綜合考慮句對質量和覆蓋度來選取小規模的訓練語料能夠比單純考慮覆蓋度更好些,盡管在本文目前所用數據的實驗結果上并不是很明顯。
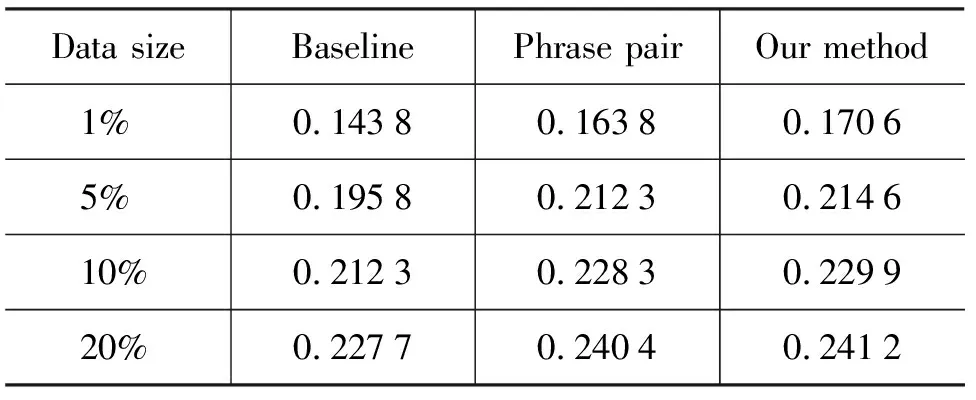
表2 引入句對質量評價前后按覆蓋度選取的訓練語料的訓練效果比較
7 討論與未來的工作
統計機器翻譯所用的雙語平行語料不同于單語語料,其句對中源語句和目標語句有著緊密的關系。比較幾種不同的覆蓋度指標的實驗表明在用雙語特征(短語翻譯對)作為覆蓋度指標時選取訓練語料子集效果最好,20%的數據規模即達到接近Baseline用全部數據時的訓練效果。而同時考慮Unigram Bigram和Trigram在40%左右達到相當的性能。在實驗基礎上,本文認為在選取SMT雙語訓練語料時采用雙語的特征(比如短語翻譯對)來衡量覆蓋度這一指標更合理。
同時,句對的質量好壞也是影響訓練效果的因素,為評價句對的質量本文考慮多種特征提出一種線性模型,這些特征包括:基于雙語詞典的句對翻譯質量,語言模型,翻譯模型概率等。將句對質量評價引入到訓練語料子集的選取框架中,發現在選取的語料規模較小的時候有微弱提升。雖然效果不夠明顯,但這也間接說明句對質量評價起到了一定作用。分析本文實驗中單句質量評價對選取的訓練子集質量影響微弱的原因,可能是因為候選語料本身規模就比較小,低質量句對的比例也較低。究竟單句對的質量對選取高質量的SMT訓練語料的影響有多大本文還不能給出定論。
總之,本文提出了一種綜合考慮句對質量和覆蓋度選取統計機器翻譯訓練語料的方法,利用該方法從大規模平行語料中選取高質量的小規模的子集作為訓練語料,在不明顯損失機器翻譯性能的前提下降低訓練和解碼的代價。從70萬句對中選取其中20%的語料即達到了與用整個語料相當的機器翻譯性能,通過實驗驗證了本文方法的有效性。
本文當前的實驗中句對質量評價線性模型中各個特征的權重是還只是由人工在較小訓練集上調整,給出的一個經驗值,后面的工作中我們將考慮采用自動的方式來訓練得到各特征的權重。
下一步,我們還將進一步完善本文的訓練語料選取框架,并在千萬級規模的平行語料上進行相關實驗以進一步驗證句對質量評價方法在過濾噪聲數據方面的功能是否顯著。
[1] 黃瑾,呂雅娟,劉群. 基于信息檢索方法的統計翻譯系統訓練數據選擇與優化[J]. 中文信息學報, 2008,22(2):40-46.
[2] Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-based translation[C]//Proc. of HLT-NAACL, 2003. May: 127-133.
[3] Yajuan Lü, Jin Huang and Qun Liu. Improving Statistical Machine Translation Performance by Training Data Selection and Optimization[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2007:343-350.
[4] Matthias Eck, Stephan Vogel, Alex Waibel Low cost portability for statistical machine translation based on n-gram coverage[C]//MT Summit X: 2005:227-234.
[5] 陳毅東,史曉東,周昌樂.平行語料處理初探:一種排序模型[J]. 中文信息學報,2006,增刊:66-70.
[6] Tong Xiao, Rushan Chen, Tianning Li, Muhua Zhu, Jingbo Zhu, Huizhen Wang and Feiliang Ren. NEUTrans: a Phrase-Based SMT System for CWMT2009[C]//5th China workshop on Machine Translation (CWMT), Nanjing, China, 2009: 40-46.
[7] Deyi Xiong, Qun Liu and Shouxun Lin. Maximum Entropy Based Phrase Reordering Model for Statistical Machine Translation[C]//Proc. of ACL Sydney, 2006: 521-528.
[8] Franz Josef Och Hermann Ney. The Alignment Template Approach to Statistical Machine Translation[C]//Association for Computational Linguistics. 2004.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國生殖健康(2019年2期)2019-08-23 08:12:08
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
汽車觀察(2016年3期)2016-02-28 13:16:26
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
