塊備份數據多版本融合方法
2011-08-10 01:51:16王樹鵬吳廣君吳志剛云曉春
通信學報 2011年12期
關鍵詞:融合
王樹鵬,吳廣君,吳志剛,云曉春
(1.中國科學院 計算技術研究所,北京 100190;2. 災備技術國家工程實驗室,北京 100876;3. 北京郵電大學 網絡技術研究院,北京 100876)
1 引言
各種災難事件、突發事件通常會引起數據的丟失或者不可訪問,為企業、部門甚至個人都會帶來巨大的經濟損失[1,2]。國標GB/T 20988-2007《信息安全技術 信息系統災難恢復規范》中將災難定義為:由于人為或自然等原因,造成信息系統運行嚴重故障或癱瘓,使信息系統支持的業務功能停頓或服務水平不可接受。根據上述標準,典型的災難事件包括自然災害,如火災、洪水、地震、颶風等;人為錯誤,如管理員誤操作、病毒攻擊等。數據的備份和恢復技術便成為數據安保,恢復癱瘓系統的最后一道防線。
多版本塊數據備份技術通常在邏輯卷層次或磁盤驅動器層次實現與應用無關的數據復制,支持任意歷史版本的數據恢復。常見的備份技術如圖 1所示,隨著數據復制時間粒度的提高,數據保護性能會越好。目前通常使用在線數據復制技術支持細粒度多版本數據的備份與恢復。在線數據復制技術主要包括以COW(copy-on-write)技術為代表的寫時舊版本數據復制技術和 ROW (redirect-on-write)技術為代表的寫時新版本數據復制技術。COW 技術在發生寫操作時首先復制出舊版本數據,按序存儲各個歷史版本序列。在數據恢復時從當前時間點開始依次恢復之前版本的備份數據,實現歷史狀態的回滾。這類技術廣泛存在于多版本文件系統中,如Elephant[3], Ext3cow[4],CVFS[5]等。但是COW技術具有如下2個缺點。1) COW具有明顯的寫延遲。COW 技術需要把原始系統中的一次寫操作變為讀舊數據,存儲舊數據,最后執行寫入的3次操作。盡管舊版本數據的轉存,新版本數據的寫入可以并發執行[6],但是仍然具有明顯的延遲。2) COW無法實現系統級別的全量恢復,僅能恢復由于誤操作導致的局部數據污染[7]。ROW技術直接復制寫數據流或數據塊,寫入到新分配的存儲空間。ROW技術可以應用在數據復制頻率較高的場合,如CDP(continuous data protection)等。結合快照備份數據,ROW技術可以實現系統級別的全量恢復,但是隨著數據復制頻率的增加和數據保存時間的延長,備份數據版本數目會不斷增長,形成版本之間相互依賴的版本鏈條,使得數據管理越來越復雜,直接影響著數據的可恢復性和恢復效率。
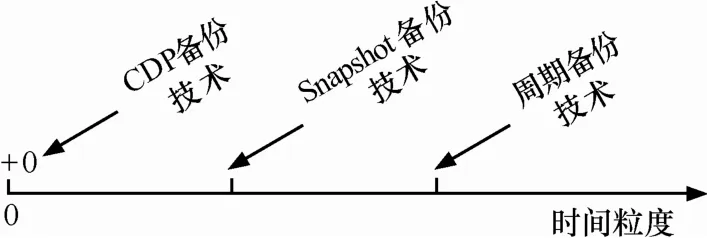
圖1 數據保護技術的分類
文獻[8~10]中通過專用系統或硬件實現增量備份數據版本序列的管理,但是無法管理分離存儲的備份數據。為了提高備份數據管理效率,降低數據備份恢復成本,目前迫切需要建立獨立于主端系統的第三方備份數據管理中心[11]。TRAP[12,13]把實時復制的更新數據塊單獨保存在 CDP數據盤中,實現持續數據保護。但是TRAP在檢索目標版本數據時通過按序掃描版本序列,檢索時間隨著版本序列長度線性增長。文獻[14]和文獻[15]在定長的版本序列中插入全量鏡像數據或快照數據,加速版本鏈的檢索過程。但是頻繁的產生系統級別的鏡像數據或全量快照數據不僅增加主端系統的備份負擔,而且產生的周期備份數據與已經存儲的版本序列存在版本冗余現象:即內容相同的數據塊保存在多個版本中。如何利用存儲端存儲的備份數據版本序列構建出任意歷史時間點的全量快照備份數據,是提高細粒度多版本條件下備份系統效率的主要途徑。
本文基于上述背景,提出塊備份數據多版本融合方法,通過版本序列的融合構建出任意歷史時間點的全量快照備份數據,避免主端系統頻繁產生快照備份數據而降低系統性能。在具體實現中,本文結合塊備份數據的分布特點,以版本序列中邏輯地址連續的數據塊,作為版本融合單位,降低了版本融合帶來的計算負擔;最后文章給出了版本融合技術在多版本備份數據管理中的應用案例和性能分析。
2 塊備份數據版本融合原理
多版本塊備份數據是通過加載在主端的備份代理結合在線數據復制技術而產生的。塊數據復制技術本質是復制一定時間保護粒度(T),邏輯地址空間(x)內的變化的數據,可使用寫密度函數 wT(x)抽象表達二者關系,如式(1)所示。由寫密度函數產生的數據量(d)可以表示為式(2),其中,Length是每個邏輯地址單元對應的數據塊長度。式(3)和式(4)進一步給出在整個邏輯地址空間和備份數據生命周期內產生的備份數據總量,公式具體含義在文獻[16]中有詳細分析。

其中,[0, N]表示一個邏輯卷的地址空間;[0, H]表示備份數據的生命周期,超過生命周期的備份數據直接刪除或做進一步的歸檔處理。
通過式(4)和式(5)可以得出,在備份數據生命周期內,備份數據量的版本序列長度(M)隨著數據復制時間粒度的減小(T)而增加。
為了進一步描述多版本序列與主端系統之間的對應關系,引入 Markov轉換過程表示。如圖 2所示,給出了在一定數據復制頻率下主端的數據狀態和備份數據版本序列之間的狀態轉換關系。其中,D表示主端的數據狀態,Δ表示增量備份數據。不同版本的數據狀態使用版本號i進行區分,Di表示版本號為i數據狀態。版本序列和數據狀態之間通過版本號進行關聯,如由數據狀態Di產生更新數據Δi,i+1后變化到數據狀態Di+1。
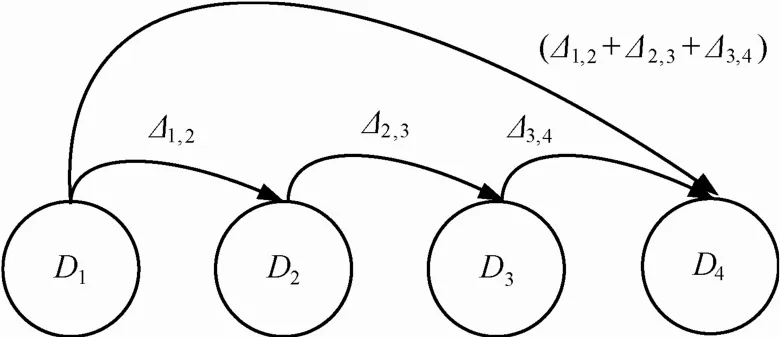
圖2 基于Markov過程的數據狀態轉換過程
利用Markov過程中的狀態轉換可以表示多版本條件下,數據恢復過程中目標版本的檢索過程,比如要恢復早期數據狀態,需要利用某一個版本的數據狀態點作為起點,結合增量備份數據版本序列轉換到目標版本數據狀態。傳統方法是通過數據備份產生數據狀態點,并結合增量備份數據版本序列實現數據狀態轉換;一種更優化的方法是通過把多個增量版本序列融合,利用產生的融合版本加快狀態之間轉換。如圖D1到D4的狀態轉換可以通過Δ1,2+Δ2,3+Δ3,4版本之間的融合,實現數據狀態之間的轉換。塊備份數據版本融合過程可以形式化定義為
定義1 版本融合。設 2個相鄰版本的塊備份數據 Δi={(x, d)|x∈Ni, d∈D};Δi+1={(x', d')|x'∈Ni+1, d'∈D'};其中,N表示塊數據的邏輯地址空間,D, D'表示邏輯地址空間內的數據,把Δi與Δi+1合并成一個新融合版本Δ′,構成Δ′的數據塊集合可以表示為式(6),這一過程稱為版本融合。
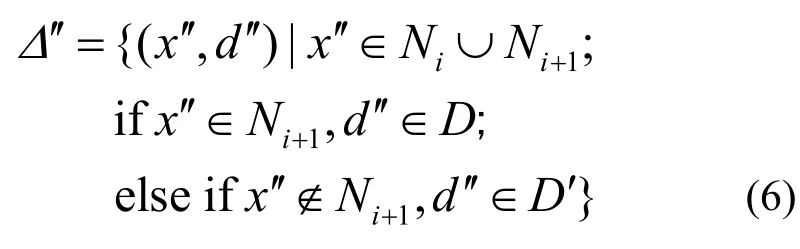
版本融合的基本思想是根據塊備份數據邏輯地址的相對關系,通過塊數據的替換產生新版本的備份數據。版本融合可以在相鄰的多個版本構成的版本序列依次使用,于是得出如下引理。
引理 1 多版本塊備份數據構成的版本序列中,可以把版本相鄰的序列,融合成一個版本,這一過程可以通過式(7)表示。
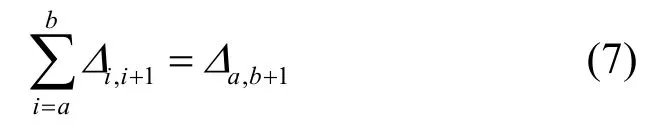
根據版本融合定義,容易證明上述定理,具體的證明過程不再詳述。利用定理1可以把一個增量備份數據版本序列融合為一個版本,進而縮短版本鏈的長度,加快版本鏈的檢索過程。
3 塊備份數據版本融合算法
文獻[17]中分析了磁盤數據局部訪問特性,由此產生的備份數據版本序列是由一系列邏輯地址相對連續的數據塊集合構成,本文根據數據塊分布的特征提出一種變長數據塊版本融合方法。在變長數據塊版本融合操作中,需要根據 2個版本數據塊的相對關系進行匹配。設新版本中,數據塊r的一個連續邏輯地址空間為[a, b], a≤b;舊版本中,數據塊R的一個連續邏輯地址空間為[A, B],A≤B;則數據塊r與R的匹配關系可以描述成如下6種情況。
定義 2 左獨立。if(b<A),則新版本數據塊 r相對于舊版本R左獨立,如圖3中的①,簡稱左獨立,記為Left-Independent。
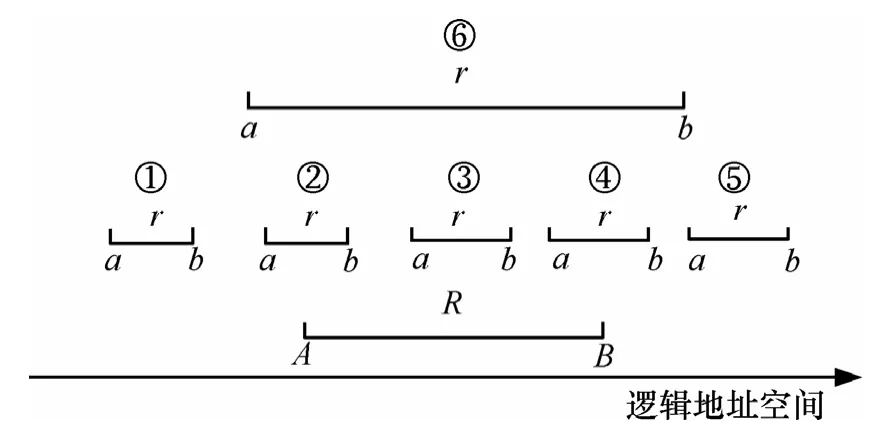
圖3 r和R的6種區間匹配關系
定義 3 左重疊。if(a<A and b≥A and b≤B),則稱新版本數據塊 r相對于舊版本數據塊 R左重疊,如圖 3中的②,簡稱左重疊,記為 Left-Overlapping;
定義 4 包含。if(a>A and b<B),則稱新版本數據塊r包含于舊版本數據塊R中,如圖3中的③,簡稱包含,記為Included;
定義 5 右重疊。if(a≥A and a≤B and b>B),則稱新版本數據塊 r相對于舊版本數據塊 R右重疊,如圖 3中的④,簡稱右重疊,記為Right-Overlapping;
定義 6 右獨立。if(a>B),則稱新版本數據塊r相對于舊版本數據塊R右獨立,如圖3中的⑤,簡稱右獨立,記為Right-Independent;
定義 7 覆蓋。if(a≤A and b≥B),則稱新版本數據塊r相對于舊版本數據塊R滿足覆蓋關系,如圖3中的⑥,簡稱覆蓋,記為Overlapping。
在系統軟件和磁盤調度算法中通常使用起始地址加數據長度記錄RAW Data的分布,但是所記錄的數據塊之間都滿足獨立的關系,如圖3中的①和⑤所示,r全部在R的左側或右側。在版本融合過程中 2個數據塊會發生重疊情況,如Left-Overlapping、Included以及 Right-Overlapping等情況,需要進行預處理,把舊版本數據塊進行分割,分割后的子區間滿足獨立或覆蓋的關系。數據塊區間分割方法包括如下2種方法。
定義 8 區間疊加。在滿足Overlapping關系條件下,即r覆蓋R時,R中任意一點在r中都有與之對應的部分,使用r替代R的過程稱為區間疊加,記為:r+R;
定義 9 區間分割。在區間關系左重疊,包含以及右重疊等條件下,把R進行分割,產生的區間子項 Ra、Rb、Rc,其中,r與 Ra具有 Right-Independent的區間關系;r與 Rb具有 Overlapping關系,r與Rc具有Left-Independent的區間關系,把這一過程稱為區間分割,記為:R/r。
結合上述基本定義和描述,可以給出變長數據塊版本融合基本算法描述。設每個版本內的數據塊集合記為F。多次復制過程中產生的版本序列記為:{F1, F2, …, Fn},版本融合算法如下所示。
算法1 版本融合算法:VersionMerge (Fr, FR)
輸入:Fr, FR
輸出:Ft
Fr表示新版本數據塊集合;FR表示舊版本數據塊集合;Ft表示融合后的數據塊集合;假設FR, Fr集合內的所有數據塊都是按照邏輯地址遞增的順序排列;
VersionMerge (Fr, FR){
1) i=1, k=1;//i為Fr內的數據塊的標示;k為FR內的數據塊標示;
2) for(each ri∈Fr, Rk∈FR){
3) if(Frand FR都沒有結束){
4) switch(compare(ri, Rk);) {
5) case Left-Independent:
6) add rito Ft;i++;break;
7) case Left-Overlapping or Included or Right-Overlapping:
8) Rk/ ri→Ra,Rb,Rc;
9) if(Ra≠NULL) add Rato Ft;
10) if(Rb≠NULL) {
11) ri/Rb→ra, rb, rc;
12) if(ra≠NULL) add rato Ft;
13) if(rb≠NULL) add rbto Ft;
14) if(rc≠NULL) rc→ri;}
15) if(Rc≠NULL) Rc→Rk;
16) break;
17) case Right-Independent:
18) add Rkto Ft;
19) k++;break;
20) case Overlapping:
21) k++;break;}}}
22) if (Fr尚未處理結束) 把Fr沒有處理的部分直接加入到Ft中;
23) if (FR尚未處理結束) 把FR沒有處理的部分直接加入到Ft中;
24) return Ft;}
算法1給出2個版本融合的具體實現過程,在變長數據塊分割算法中, 具有重疊關系的數據塊可能會被頻繁分割處理,這部分數據塊的長度在融合版本中會逐漸趨近于磁盤寫操作的最小分配單元,如sector長度。版本融合過程使用算符“⊕”表示,也稱為版本的疊加,算法1可以表示為Ft=Fr⊕ FR。
4 版本融合在多版本備份數據管理中的應用
4.1 基于版本融合的快照檢索方法
快照備份數據描述一個時間點的瞬時數據鏡像,對保證數據的可恢復性,加快多版本檢索過程具有重要意義。結合算法 1,在備份數據版本序列中,從目標版本開始, 逆序融合每個版本, 直到最近的全量備份數據為止, 這一過程可以使用算法 2表示,記為SnapshotSearch (i, S)。
算法 2在版本序列中循環利用版本融合算法,獲取時間點為 i的全量快照備份數據, 可以使用式(8)表達這一檢索過程。
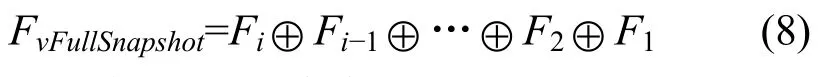
算法2 快照融合算法: SnapshotSearch(i, S)
i:待檢快照版本號;S: 版本序列;Fi:第i個版本;FVFullSnapshot: 結果快照數據塊集合;
輸入:i, S(1≤i≤n)
輸出:FVFullSnapshot

版本序列的融合操作可以在備份系統空閑時發起,并保存融合后的結果版本加速后期的版本檢索過程。基于版本融合,可以進一步實現多版本序列的刪除操作。對于超過備份數據生命周期的版本序列可以利用版本融合技術,融合成一個新版本的備份數據,起到版本序列刪除的作用。
4.2 多版本差異恢復模式
備份數據主要用于數據恢復。根據第2部分的分析,以ROW技術為代表的分離存儲系統中,數據恢復過程通常選擇距離目標時間點最近的全量數據作為數據的一致性狀態,然后再結合更新數據版本序列,逐次前向恢復到目標時間點。在分離存儲的備份系統中,需要恢復的數據量是影響恢復效率的主要因素。利用版本融合技術,結合算法2可以直接計算出版本序列中目標時間點的全量快照數據,結合校驗技術可以快速判斷當前的主端系統的數據狀態與歷史數據狀態實際發生變化的數據,通過僅恢復變化數據提高恢復效率。這一數據恢復過程稱為多版本差異恢復,記為 Diffdo,利用算法3表示。
算法3 多版本差異恢復過程:Diffdo(T)
T:待恢復的版本號,1Tn≤≤;
1) 存儲端根據算法2,計算版本號為T的全量快照數據FVFullSnapshot(T):
FVFullSnapshot(T)=FT⊕FT-1⊕…⊕F1
2) 存儲端根據 FVFullSnapshot(T)計算快照數據的校驗文件:CheckFile(T),并發送到主端;CheckFile(T)包括校驗規則和校驗值:
Check(FVFullSnapshot(T)) →CheckFile(T)
3) 主端根據CheckFile(T)計算本地磁盤當前數據塊的校驗值,并與 CheckFile(T)中對應的校驗值比對,記錄校驗不一致的數據塊對應的邏輯地址,生成CheckErrorFile(T),并發送到存儲端:
CheckFile(T)→CheckErrorFile(T)
4) 存儲端根據CheckErrorFile(T)和FVFullSnapshot(T)檢索備份數據,計算差異恢復索引文件DiffdoLog(T),并根據DiffdoLog(T)進行差異數據恢復:
CheckErrorFile(T)+FVFullSnapshot(T)→DiffdoLog(T)
Diffdo利用版本融合技術,構建版本序列中目標時間點的全量快照數據,可以直接與主端系統當前數據狀態進行比對,只恢復實際發生變化的數據塊,通過減少恢復數據量提高恢復效率。
5 實驗與結果分析
本文采用標準 trace和具體備份系統相結合的方法展開實驗分析。首先利用HP cello99 trace分析在持續數據保護背景下使用版本融合技術和定期產生快照備份數據 2種技術產生的備份數據量比較。然后結合具體系統,給出版本融合技術在多版本備份數據管理中的效率分析。
5.1 版本融合后產生的數據量分析
Cello99 trace是HP實驗室記錄UNIX服務器全年的磁盤I/O trace。實驗中選取cello99-03-03的I/O trace進行分析。本文回放連續24h的磁盤I/O操作,分析2種技術產生的備份數據量關系。圖4中給出了實驗結果。實驗中選取每次寫操作作為一個版本,快照周期選取版本序列長度為:40、80、120、160、200產生快照備份數據。實驗結束時,使用版本融合技術比周期快照技術少產生備份數據量43.4%左右。實驗中進一步發現隨著快照周期內版本序列長度的增加產生的快照備份數據量會有所減少,這一現象主要是由于磁盤具有寫局部性造成的,一個快照周期內邏輯地址相同的數據塊會發生重復寫操作,如果能夠統計重復寫的比率,進而控制融合版本序列的長度,會進一步提高版本融合的效率。
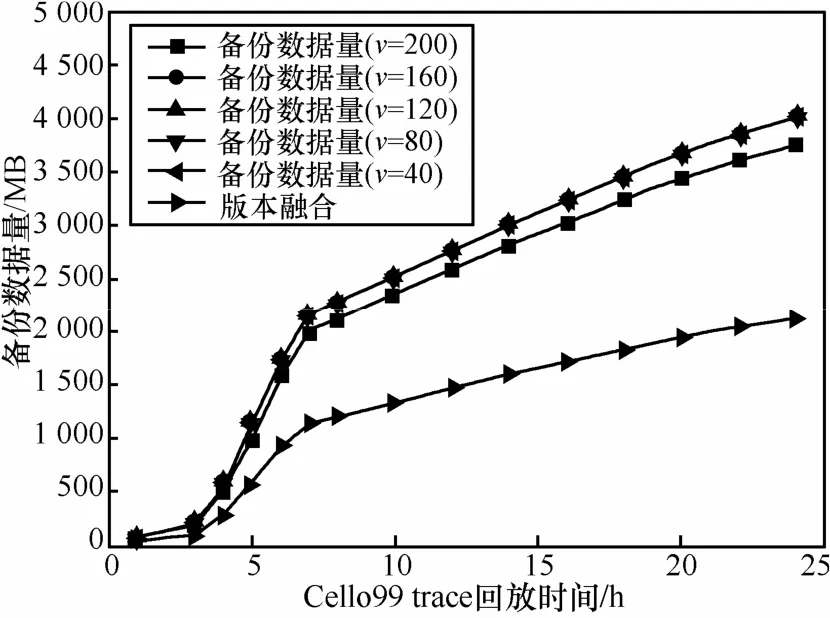
圖4 版本融合技術產生的備份數據量比較
5.2 變長數據塊索引技術效率分析
本文進一步通過實際的數據備份恢復系統分析版本融合具體的性能。備份系統中主端選取 XP操作系統的PC機,具體配置為Intel(R) Core(TM)2 CPU 1.8GHz/1.79GHz, 1GB內存,NTFS文件系統,目標邏輯卷為20GB。存儲端由4臺存儲服務器構成的存儲集群,具體配置為Inter(R) Core(TM)2 Duo CPU2.2GHz/2.19GHz,1GB 內存;Realtek 100M(2);Inter(R) Core(TM)2 Duo CPU 2.2GHz/2.19GHz,2GB內存,Realtek 100M(2)。實驗中利用磁盤過濾驅動技術,監控主端目標邏輯卷,產生周期性的增量備份數據。備份周期為10~30min,共產生50個版本的備份數據。
圖5給出了定長數據塊與變長數據塊在多版本數據管理中的索引量比較。索引數據量直接與數據塊的分割方式有關,版本融合技術中以邏輯地址連續的數據塊作為多版本管理單位,可以比靜態數據塊多版本管理方法減少 2~3個數量級的索引數據量,為降低版本融合計算復雜度提供基礎。圖6給出了利用變長數據塊融合方法檢索全量快照備份數據的時間消耗。變長數據塊版本融合的時間消耗明顯低于定長數據塊多版本管理方法。
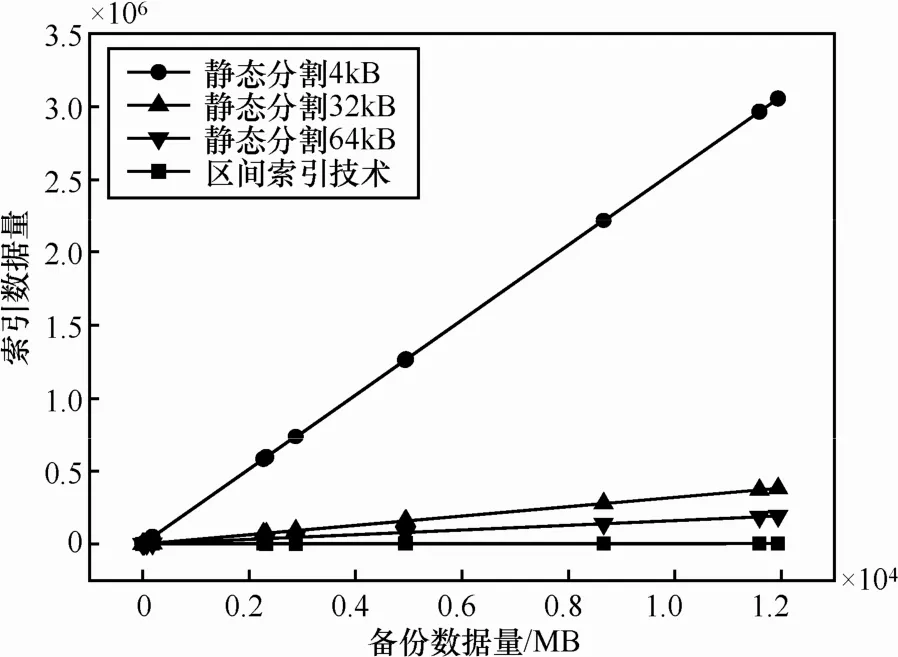
圖5 索引數據量的比較

圖6 全量快照檢索時間比較(圖中使用雙y軸,靜態分割4kB的索引技術使用左側的y軸,另外3種技術使用右側的y軸)
5.3 數據恢復效率分析
備份數據恢復效率通常使用RTO(recovery time objective)表示[18]。在分離存儲模式下,數據恢復時間消耗主要包括從發生數據丟失一直到業務重新啟動的時間間隔,可以表示為
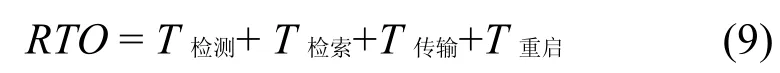
T檢測:表示從災難發生到檢測到數據丟失的時間;
T檢索:表示在存儲端按照一定的恢復模式, 檢索待恢復備份數據的時間;
T傳輸:表示備份數據由存儲端傳輸到主端的數據傳輸時間;
T重啟:表示數據成功恢復后, 重新啟動業務的時間;
T檢測、T重啟與具體的業務相關,在本文中忽略不計,于是RTO可以表示為

T檢索與存儲端的備份數據組織方式有關,T傳輸與待恢復的備份數據量和傳輸帶寬相關,在傳輸帶寬一定的條件下,T傳輸由恢復數據量決定。為了進一步描述T檢索和T傳輸的相對關系,引入檢索時間占有率因子α,如式(11)所示:
α表示在存儲端檢索備份數據的時間占全部數據恢復時間的比率;α主要由備份數據的索引結構和版本序列的組織方式決定。α值越大表示存儲端的計算開銷越大。
本文主要比較Redo,Diffdo的恢復效率,同時也測試了 COW 數據復制下通常使用的回滾恢復(Undo)效率,3種恢復方式的具體含義如下:
Undo:是指通過回滾方式, 陸續恢復前一個版本數據實現數據恢復;
Redo:是指首先恢復到距離目標時間點最近的全量數據,通過恢復全鏡像數據和更新數據版本序列實現數據恢復;
Diffdo:是指本文提出的基于多版本管理技術的差異恢復模式。
圖7給出了不同恢復模式下恢復效率的比較。不同恢復模式下,需要恢復的數據量以及備份數據的檢索方式不同,導致α有很大的差別。實驗中首先選取傳輸帶寬為2MB/s,在Redo恢復模式下,由于恢復的數據量大,RTO值最大。Undo恢復模式由于只恢復變化的數據,恢復的數據量少,RTO值最小。Diffdo恢復的數據量與Undo相同,但是由于引入了數據校驗過程,RTO值介于二者之間。在實驗環境下,Diffdo模式的RTO值是Redo恢復模式的1/4到1/5左右。圖8中進一步給出不同恢復模式下檢索時間的占有率情況分析。Redo模式下,數據傳輸時間占RTO的主要部分,α值很小,占1%左右;但是在Undo和Diffdo恢復模式下需要檢索全量快照α值較大。由于Diffdo增加了數據的校驗過程,α值最大。根據實驗結果可以得出,Diffdo可實現基于時間點的完整數據恢復,是一種適用于低帶寬,大數據量的數據恢復場合。
6 結束語
在增量備份數據版本序列中利用版本融合技術可以計算出目標版本全量快照數據,避免通過備份產生全量快照數據。為了降低版本融合的計算負擔,本文以邏輯地址連續的數據塊作為版本融合單位,可加快版本的融合過程。利用版本融合技術可以實現多種有現實意義的具體應用,如快照檢索,多版本差異恢復等操作。但是版本融合技術是建立在所有版本數據的正確性得到保證的條件下實現的,否則任意一個版本數據出現錯誤都會擴散到融合版本中,為此確保備份數據的可靠性,成為進一步研究的主要方向。
[1] MCKNIGHT J, ASARO T, BABINEAU B. Digital Archiving:End-user Survey and Market Forecast 2006–2010[R]. The Enterprise Strategy Group, 2006.
[2] KEETON K, SANTOS C, BEYER D. Designing for disasters[A].Proceedings of 3rd Conference on File and Storage Technologies[C].USENIX Association, 2004. 59-72.
[3] SANTRY D S, FREELY M J, HUCHINSON N C, et al. Deciding when to forget in the elephant file system[J]. Operating Systems Review, 1999, 33(5): 110-123.
[4] PETERSON Z, BURNS R C. Ext3cow: a time-shifting file system for regulatory compliance[J]. ACM Transactions on Storage, 2005, 1(2):190-212.
[5] SOULES C A, GOODSON G R, STRUNK J D, et al. Metadata efficiency in versioning file systems[A]. Proceedings of the 2nd Usenix Conference on File and Storage Technologies (Fast'03)[C]. Usenix Association, 2003. 43-58.
[6] LIU J N, YANG T M, LI Z H. TSPSCDP: a time-stamp continuous data protection approach based on pipeline strategy[A]. Japan-China Joint Workshop on Frontier of Computer Science and Technology(FCST '08)[C]. 2008. 96-102.
[7] XIAO W J, YANG Q. Can we really recover data if storage subsystem fails?[A]. Proceedings of the 28th International Conference on Distributed Computing Systems (ICDCS 2008)[C]. Beijing: China,2008.597-604.
[8] HITZ D, LAU D, MALCOLM M. File system design for an NFS file server appliance[A]. Proceedings of the USENIX Winter Technical Conference[C]. USENIX Association, 1994. 235-245.
[9] PATTERSON H, MANLEY S, FEDERWISCH M. SnapMirror (R):file system based asynchronous mirroring for disaster recovery[A].Proceedings of the Conference on File and Storage Technologies(Fast'02)[C]. Usenix Association , 2002. 117-129.
[10] FLOURIS M D, BILAS A. Clotho: transparent data versioning at the block I/O level[A]. Proceedings of the 21st IEEE Conference on Mass Storage Systems and Technologies/12th NASA Goddard Conference on Mass Storage Systems and Technologies (MSST’04)[C]. IEEE Computer Society, 2004.315-328
[11] 楊朝紅, 宮云戰, 桑偉前等. 基于主從異步復制技術的容災實時系統研究與實現[J]. 計算機研究與發展, 2003, 40(7): 1104-1109.YANG Z H, GONG Y Z, SANG W Q, et al. A primary-backup lazy replication system for disaster tolerance[J]. Journal of Computer Research and Development, 2003, 40(7): 1104-1109.
[12] YANG Q, XIAO W J, REN J. TRAP-array: a disk array architecture providing timely recovery to any point-in-time[A]. Proceedings of the 33rd Annual International Symposium on Computer Architecture(ISCA’06:)[C]. 2006. 289-300.
[13] XIAO W J, REN J, YANG Q. A case for continuous data protection at block level in disk array storages[J]. IEEE Transactions on Parallel and Distributed Systems, 2009, 20(6): 898-911.
[14] AGUILERA M K, KIMBERLY K, MERCHANT A, et al. Improving recoverability in multi-tier storage systems[A]. Proceedings of the 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks(DSN '07)[C]. 2007. 677-686.
[15] 李旭, 謝長生, 楊靖. 一種改進的塊級連續數據保護機制[J]. 計算機研究與發展, 2009, 46(5): 762-769.LI X, XIE C S, YANG J, et al. An improved block-level continuous data protection mechanism[J]. Journal of Computer Research and Development, 2009,46(5): 762-769.
[16] 吳廣君, 云曉春, 方濱興. HCSIM: 一種長期高頻Block-Level快照索引技術[J]. 計算機學報, 2009, 32(10): 2080-2090.WU G J, YUN X C, FANG B X, et al. HCSIM: an indexing method for long-lived frequent block-level snapshot[J]. Chinese Journal of Computers, 2009, 32(10): 2080-2090.
[17] RUEMMLER C, WILKES J. Unix disk access patterns[A]. Proceedings of the Winter 1993 Usenix Conference[C]. USENIX Association,1993. 405-420.
[18] KEETON K, SANTOS C, BEYER D, et al. Designing for disasters[A].Proceedings of the 3rd USENIX Conference on File and Storage Technologies[C]. USENIX Association, 2004.59-72.
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
