基于改進ReliefF算法的Honeynet告警日志分析
2011-09-07 10:16:40蔣玉嬌安和平
計算機工程與設計 2011年7期
畢 凱, 周 煒, 蔣玉嬌, 安和平
(空軍工程大學導彈學院,陜西三原713800)
0 引 言
Honeypot是一種安全資源,其價值體現在被探測、攻擊或者摧毀的時候[1]。Honeypot是一個被嚴格控制的欺騙環境,由真實的或者軟件模擬的網絡和主機構成,但其系統中存在許多虛假的文件信息,用以實現對入侵者的誘騙。在誘騙環境中,我們可以收集入侵信息,觀察入侵者行為,記錄其活動,以便分析入侵者目的、手段、工具等信息。Honeynet是一種高交互的Honeypot系統,它提供了整個操作系統和軟件,用于和入侵者進行交互。真實的環境,使誘騙系統更具有迷惑性,而高度的交互性,使得Honeynet非常適合捕獲未知的入侵行為。
目前針對Honeynet的研究主要集中在其部署以及捕獲入侵上,但在對捕獲數據的分析方面還很薄弱。HoneynetProject對使用高交互度Honeypot進行數據分析所需的時間做過一次研究。根據他們的發現,對于攻擊者花費在被黑系統上的每30分鐘時間,若要對捕獲數據加以較為詳細的分析大約要花費40小時[1]。可見,數據分析已經成為影響甚至制約Heneynet快速發展的瓶頸。Kreibich等人提出了一種比較簡單LCS(longest-common-substring)算法[2],但是提取的質量較差。Thakar通過可視化、統計分析等方法輔助人工篩選出可疑數據,然后采用LCS算法自動提取攻擊特征[3]。Yegneswaran等人利用協議的語義實現從Honeynet數據中自動提取攻擊特征[4]。本文提出了一種基于PCA和改進ReliefF算法的模式識別方法,用以分析Honeynet告警日志,并用實驗證明了其可行性。
1 模型結構
Honeynet結構如圖1所示,包括3個主要功能:數據控制,數據捕獲,數據分析[1]。
數據控制是Honeynet必備的核心技術之一,它通過限制入侵者的行為,以保護Honeypot自身以及內部主機的安全。目前常用的數據控制方法有基于IPTables的外出連接數限制和snort-inline入侵防御系統。
數據捕獲的目的是隱蔽的捕獲入侵者的攻擊行為,包括入侵者的身份、攻擊的手段和工具以及在被黑主機上的操作等行為。Honeynet技術通常結合 Argus、Snort、p0f、Sebek 對攻擊數據進行多層次捕獲,以保證為數據分析提供豐富的資料。
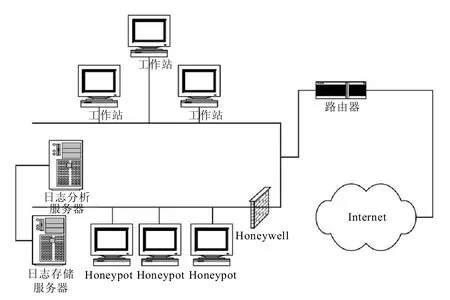
圖1 Honeynet結構
針對捕獲到的入侵行為高度復雜性的特點,提出了DAPR(dataanalyzebasedonPCAandReliefF)數據分析模型,如圖2所示。
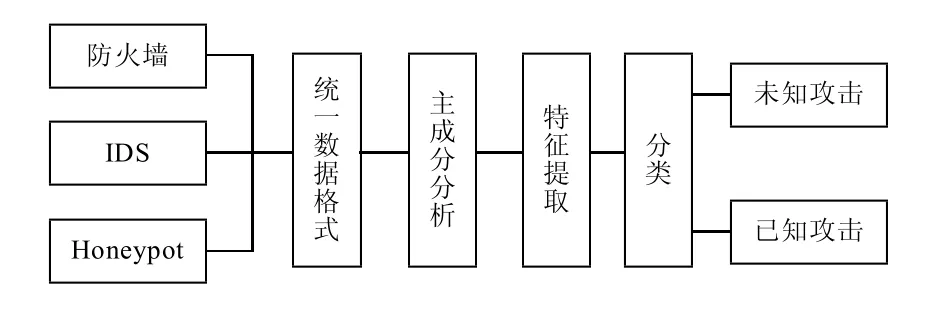
圖2 DAPR數據分析模型
由于捕獲的數據來自分別來自于防火墻、入侵檢測系統和Honeypot,格式存在較大差異,因此我們首先需要進行數據融合,統一格式,以方便數據處理。我們將融合后的數據用n維向量(x1,x2,…,xn)表示,每個維度表示該數據的一個特征。
對于同一個入侵行為,在防火墻、入侵檢測系統以及Honeypot都留有痕跡,這樣不可避免造成大量數據的冗余。就是單一入侵行為,其不同特征之間,也存在相關性,這些數據的冗余性和相關性,給數據分類分析帶來了不必要的工作量。我們利用基于PCA和改進的ReliefF的特征選擇方法,對數據進行特征選擇,降低數據維度,以減少分類的時間復雜度。而后利用SVM對入侵行為進行分類,判斷攻擊類型,生成報警信息。
2 改進的ReliefF算法
根據是否以分類精度作為評價函數,通常可以將特征選擇方法分為兩大類:過濾方法(filter)和封裝方法(wrapper)[5],Relief算法是公認的效果較好的filter式特征評估算法[6]。
Relief算法是Kira和Rendell在1992年提出的,但是該算法主要用于解決二分類問題。1994年Kononenko擴展了Relief算法,并提出了ReliefF算法,將分類視為一類對多類關系,可以解決多類問題以及回歸問題。
ReliefF算法根據特征值在區分臨近樣本點的能力上對特征賦予權值。首先將訓練數據集D中各特征的權值賦0,然后隨機選取樣本X,在訓練數據集D中找出與X同類的k個最近鄰樣本pj,j=1,2,…,k,分別從其余各類中找出X的k個最近鄰樣本 Mj(c),j=1,2,…,k,c=1,2,…,C 更新每一個特征,C 為樣本類別總數,c≠c(X),c(X)表示樣本X的類別。然后利用權值更新式(1)更新a的權值
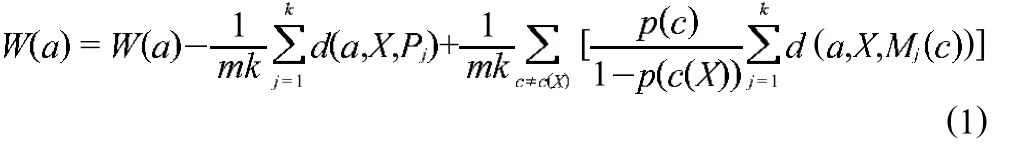
式中:d(a,X,Y)——在特征a下,樣本X和樣本Y的距離;p(c)——c類目標的概率,可以簡單記為Mj(c)——第c類目標的第j個樣本;m——算法迭代次數,m和k可根據樣本數量以及樣本維數進行設定。而后反復執行迭代過程,直至滿足迭代的次數要求。算法流程圖如圖3所示。
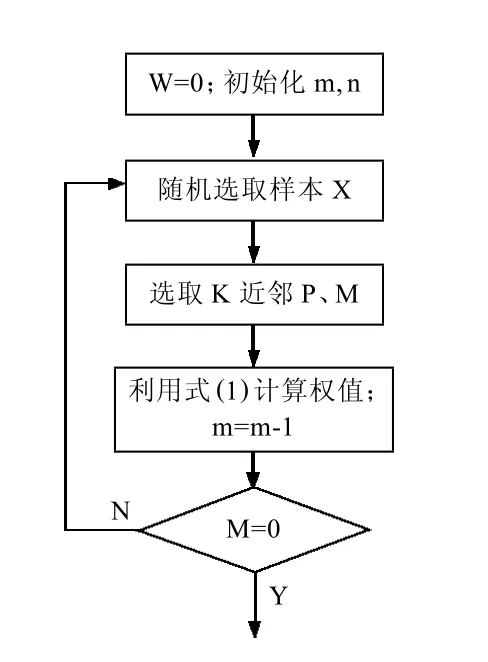
圖3 ReliefF算法流程
但是,經典的ReliefF算法仍然存在不足之處:
(1)隨機選取樣本會使小類別被選中進行權值計算的概率小,有時可能完全被忽略[7];
(2)在無小類別參與的情形下,所得到的特征權值是不科學的,從而對分類精度產生一定負面影響。在Honeynet數據分析中,小樣本往往具有潛在威脅的攻擊,不能將其忽視[8]。
一種解決方案就是增加迭代的次數。因為每次迭代都要隨機選擇樣本,在較多選擇機會下,可以降低小樣本被漏選的可能性。但是,這將大大增加系統的開銷,降低時效性。
為解決上述問題,這里我們采用多次分類的方法。由于自動化攻擊手段的廣泛應用,Honeynet捕獲的大部分攻擊都是已知的和重復性的攻擊。我們可以把所有的小樣本作為一個整體,以擴大其在樣本空間中所占比例,通過第一次分類,分離出絕大部分的入侵行為,并將其從分析數據源中剔除掉。這樣單個小類別樣本在樣本整體中的比例將大大增加。針對余下的包含小類別和未知攻擊的活動,進行再分類分析。我們可以根據實際需要設置合理的分類次數n或者直至符合分類精度要求。算法流程如圖4所示。
3 主成分分析 (PCA)
ReliefF算法雖然能夠進行特征選擇,但其不能避免各特征之間存在的冗余現象。對于所有和類別相關性高的特征,算法都會賦予較高的權值,而不考慮特征之間的冗余性。
鑒于此,結合主成分分析方法(principle component analysis,PCA),去除特征之間的相關性,以達到簡化算法復雜性的目的。
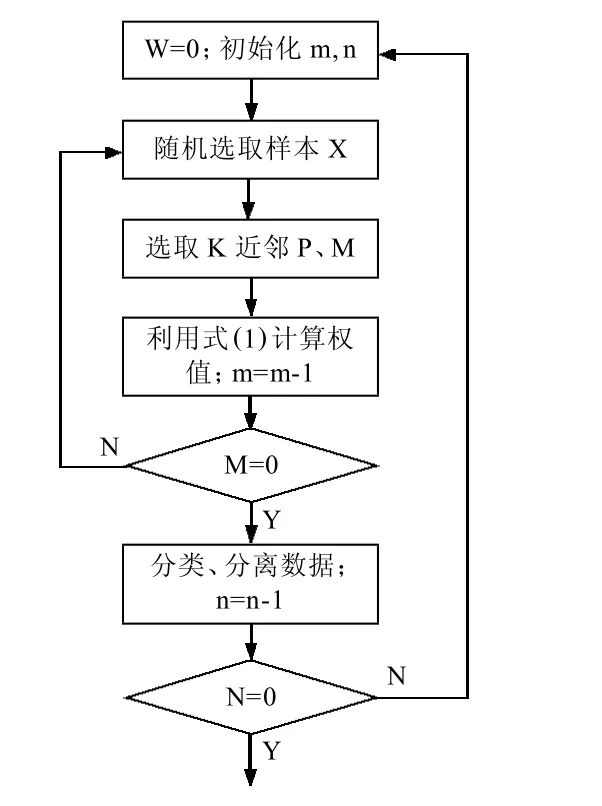
圖4 多次分類流程
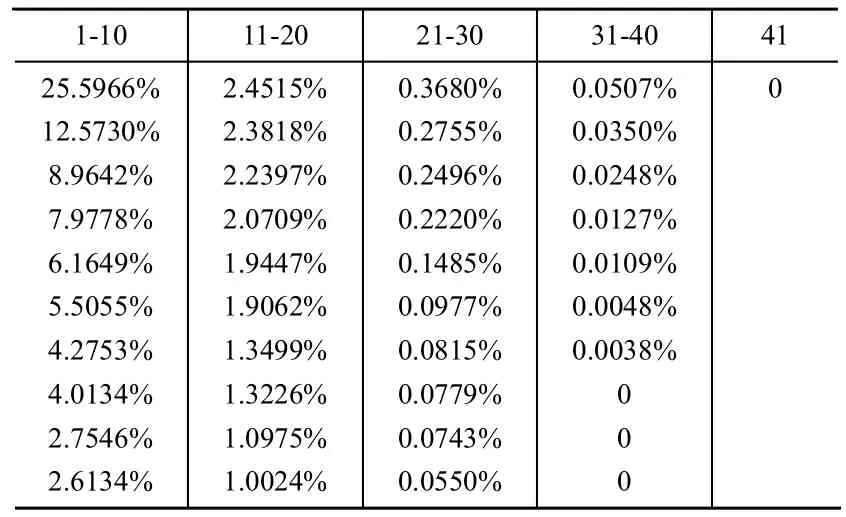
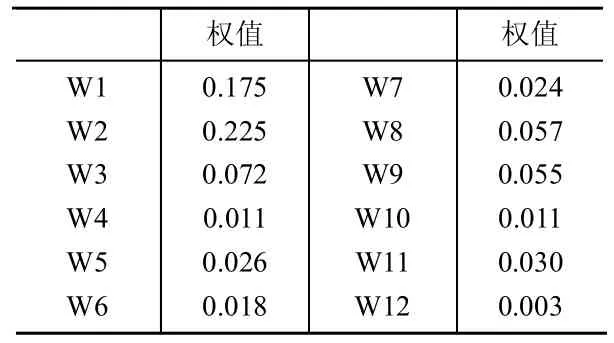
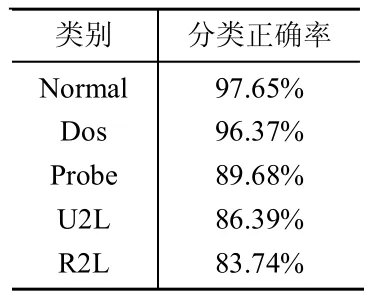
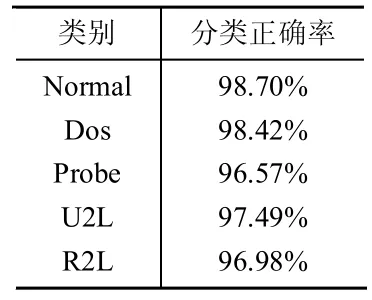
PCA,一種簡化數據集的技術,為一種線性變換。這個變換把數據變換到一個新的坐標系中。對于一個n m的矩陣,PCA的目標是尋求r(r 設輸入的數據矩陣 X∈Rmn已經按列零均值化或標準化,其中m為樣本個數,n為特征向量個數。定義X的協方差矩陣為 正交分解,得 式中:D=diag(1,2,…,n)——i降序排列所構成的對角矩陣,Pn=[p1,p2,…,pn]——與特征值 相對應的特征矩陣,其中pi為特征值i所對應的特征向量。前k個主元所涵蓋的測量變量的信息量可由前k個主元的方差貢獻率來表示。若前m個主元的方差貢獻率大于或等于某閾值Q(通常選取Q>85%),而前m-1個主元的方差貢獻貢獻率小于Q,則可令k=m,以此來確定符合條件的主元。當主元確定后,即可得主元模型 而原測量矩陣可以重構為 式中:X~——X 的殘差,X~=TPTk,T——主元矩陣;Pk——負荷矩陣。 通過Rn—>Rk的線性變換,用包含X絕大部分信息的前k個特征向量構成的PCA子空間來代替X,以達到了特征提取和降低變量維數的目的。 本文所用的實驗數據為KDD-CUP-99數據集。該數據集是哥倫比亞大學WenkeLee研究組為1999年舉行的第三次國際KDD競賽而提取的數據集,是對MIT98數據集提供的9周tcpdump數據進行了適當處理和特征提取。該數據集包括訓練數據集和測試數據集兩部分。其中訓練數據集包括了500萬個連接數據,測試數據集包括了200萬個連接數據。其包括5類數據:normal數據,Probe攻擊,DOS攻擊,U2L攻擊,R2L攻擊。每個連接共有41種定性和定量的特征,其中有7個特征是離散型變量,34個特征是連續性變量。 首先,我們構造訓練樣本集。對于原始數據集,由于規模較大,我們隨機選取其8057個數據記錄,進行處理。經統計發現,Normal、DOS、Probe、R2L、U2L所占比例分別為51%、38%、6%、3%、2%,與實際情況基本相符。 然后,我們進行數據預處理。由于上述特征包括數字型和字符型,為了訓練和測試所設計的分析系統,需要對原始數據進行預處理。首先將特征中的字符型數據做數據化處理,即為每個字符進行十進制編碼。而后對這些特征的取值范圍進行規范,控制其取值范圍在[0,1]中。一些字符屬性如protocol_type(3 個不同的標記)、flag(11 個不同的標記)、service(70個不同的標記)都將各符號映射到0和N-1之間,N為標記的個數。然后再將其映射到[0,1]區間內。連續的數值型數據也按比例縮映到[0,1]。其它屬性要么是邏輯值,其值為1或0,要么是在[0,1]范圍內的連續數據,不需要進行預處理。這樣預處理的優點主要在于:一方面可以均衡不同取值范圍的特征,避免取值范圍大的特征支配那些取值范圍小的特征;另一方面可以提取算法的運行效率。 在選取的數據集中,我們發現第9、15、20、21屬性值全為0,對于分類分析沒有意義,可以將其設為0,剩余37個屬性。 對于本數據集,由于只包含5種類別,且小類別數量差異較小,我們令n=2,m=10。下面將處理好的數據進行主成分分析,結果如表1表示。 表1 主成分分析結果 在特征貢獻率Q≥85%的基礎上,我們選取前12個屬性。 利用改進的ReliefF算法,對經過PCA簡化的數據集進行特征選擇。權值如表2所示。 選取8個權值最大的屬性用于分類,結果如表3所示。 由表3可見,經過第一次分類,可以以較高的正確率最常見的Normal和Dos行為檢測出來。而對于Probe、U2L、R2L,由于在訓練數據集中,所占比例偏小,分類正確率偏低。 將檢測出的Normal、Dos數據剔除,對余下的小樣本數據進行第二次特征選擇以及分類,綜合兩次分類,結果如表4所示。 表2 特征權值 表3 首次分類結果 由表4可以看到,經過第二次的分類,精度較第一次分類顯著提高,能夠將各種行為區分開來。 表4 再次分類結果 由實驗我們可以看到,經過特征提取和特征選擇,對數據屬性進行約減,去除冗余和與分類無關的屬性,能夠在保證分類精度的基礎上有效簡化計算的時間和空間的復雜性,提高數據分析的效率。 本文針對蜜罐中分析系統的不足,提出了基于PCA和改進ReliefF算法的告警日志分析方法,通過特征提取和特征選擇,在保證分類精度的基礎上,減少數據屬性的冗余性和無用性,有效簡化了數據分析的規模。通過多次、不斷細化的分類操作,可以將網絡攻擊中不常見的小類別攻擊方式從大量的攻擊中較為準確的提取出來,這些小類別的攻擊行為,往往是我們了解較少,具有巨大潛在威脅的攻擊行為。然而對于特征選擇和分類的次數,要視分析數據的規模和特性等情況給出,沒有一個較易得到的方法,這將成為今后研究中解決的一個問題。 [1]The honeynet project:know your enemy:honeynets[DB/OL].http://www.Honeynet.org/papers/honeynet/,2005. [2]Kreibich C,Crowcroft J.Honeycomb:creating intrusion detection signatures using honeypots[J].ACM SIGCOMM Computer Communication Review,2004,34(1):51-56. [3]Urjita Thakar.HoneyAnalyzer:analysis and extraction of intrusion detection patterns&signatures using honeypot[C].Dubai,UAE:The 2nd Int'l Conf on Innovations in Information Technology,2005. [4]Yegneswaran.An architecture for generation semanties-aware signatures[C].Baltimore,MD:Usenix Security Symposium,2005. [5]Liu Y,Zheng Y.F1 FS_SFS:A novel feature selection method for support vector machines[J].Pattern Recognition,2006,39(7):1333-1345. [6]張麗新,王家欽,趙雁南,等.基于Relief的組合式特征選擇[J].復旦學報(自然科學版),2004,43(5):893-898. [7]吳艷文,胡學鋼,陳效軍.基于Relief算法的特征選擇學習聚類[J].合肥學院學報(自然科學版),2008,18(2):45-48. [8]吳浩苗,尹中航,孫富春.Relief算法在筆跡識別中的應用[J].計算機應用,2006,22(1):174-177.



4 實 驗
5 結束語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
