模糊關(guān)聯(lián)規(guī)則挖掘模型及其在分解爐中的應(yīng)用
2011-09-19 13:24:12黨勤華朱曉東吳振杰
自動化儀表 2011年8期
王 杰 黨勤華 朱曉東 吳振杰
(鄭州大學(xué)電氣工程學(xué)院,河南 鄭州 450001)
0 引言
隨著數(shù)據(jù)庫技術(shù)的發(fā)展以及企業(yè)中生產(chǎn)設(shè)備自動化程度的提高,許多企業(yè)對生產(chǎn)過程中的重要設(shè)備都進行了監(jiān)控。監(jiān)控的各種狀態(tài)和數(shù)據(jù)形成大型數(shù)據(jù)庫,包括設(shè)備運行狀態(tài)的各種特征。但是由于數(shù)據(jù)本身的雜亂無章,致使數(shù)據(jù)庫包含的特征并不明顯[1]。數(shù)據(jù)挖掘(data mining)就是發(fā)現(xiàn)海量的數(shù)據(jù)中潛在的、有效的知識的過程。關(guān)聯(lián)規(guī)則(association rules)的挖掘作為數(shù)據(jù)挖掘技術(shù)中的重要組成部分,其目的就是尋找數(shù)據(jù)庫中事物和屬性之間的關(guān)系。
水泥工業(yè)在國民經(jīng)濟中占據(jù)著不可動搖的地位,近些年已經(jīng)取得了突飛猛進的進展。在水泥生產(chǎn)過程中,參數(shù)基本是通過各種儀表進行采集與顯示的,但具體的操作實現(xiàn)還需依靠操作人員積累的經(jīng)驗來執(zhí)行。操作經(jīng)驗因人而異。本文正是通過模糊關(guān)聯(lián)規(guī)則挖掘技術(shù),采用聚類方法對生產(chǎn)數(shù)據(jù)進行聚類劃分,并選取合適的支持度與置信度,獲取較為完備的生產(chǎn)操作信息,從而解決了專家經(jīng)驗獲取的瓶頸,這也為水泥行業(yè)各個生產(chǎn)環(huán)節(jié)的溫度和壓力等的控制提供了理論指導(dǎo)。
1 模糊關(guān)聯(lián)規(guī)則
關(guān)聯(lián)規(guī)則最早是由Agrawal等人提出的,它是數(shù)據(jù)挖掘研究的主要內(nèi)容之一。并聯(lián)規(guī)則自提出之后,眾多學(xué)者對此進行了研究并提出了很多算法,比較典型的有 Apriori、FP-Tree、TreeProjiection以及各種方法的改進算法[2-3]。
關(guān)聯(lián)規(guī)則挖掘的兩個重要概念分別為支持度(support)和置信度(confidence),支持度表示規(guī)則在所有數(shù)據(jù)中的重要程度,置信度意味著規(guī)則可以信賴的程度。進行關(guān)聯(lián)規(guī)則的挖掘時,首先要確定最小支持度(minsup)和最小置信度(minconf),隨后挖掘出滿足最小支持度和最小置信度的規(guī)則。
由于客觀世界的多樣性和復(fù)雜性,使得對許多事物的描述需要使用模糊的概念。基于模糊概念表示的關(guān)聯(lián)規(guī)則就稱為模糊關(guān)聯(lián)規(guī)則。相對于傳統(tǒng)的布爾型關(guān)聯(lián)規(guī)則挖掘,模糊關(guān)聯(lián)規(guī)則的獲取得出的規(guī)則更貼近實際、更加準確,符合人們的思維習(xí)慣[4]。
設(shè) T={t1,t2,…,tn}為一數(shù)據(jù)庫,I={i1,i2,…,im}為T中全部屬性的集合,vij為T中的i個記錄的第j個屬性的值,對于I中的每一個數(shù)值屬性ik,都有一個與之相聯(lián)系的模糊集。模糊關(guān)聯(lián)規(guī)則的形式表達為 <X,A>? <Y,B>,其中,X?I,Y?I,并且X∩Y=?,A和B分別為X和Y對應(yīng)的模糊集,<X,A>表示X中屬性取A中相應(yīng)的值。
對于任意模糊屬性集 X={y1,y2,…,yp},X 的模糊支持率為:
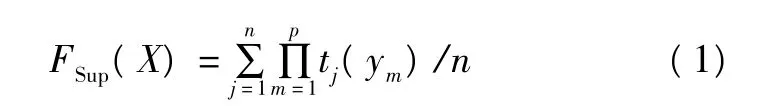
模糊關(guān)聯(lián)規(guī)則“X?Y”的模糊支持率定義為:

模糊信任度定義為:
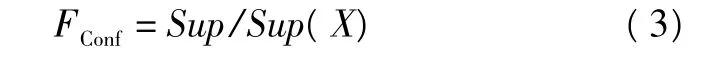
2 模糊聚類算法的選取
聚類就是將一組對象分成若干個簇的過程。聚類后的結(jié)果使得每個簇之內(nèi)的差異性最小,而簇與簇之間的差異性最大。聚類算法中比較經(jīng)典的有K-means算法和FCM算法。K-means是一種硬聚類算法,F(xiàn)CM是一種模糊聚類算法。這兩種算法均存在需要事先給定聚類個數(shù)以及對初始聚類中心相當敏感的問題[5-6]。因此,針對此問題,采用將 K-means和 FCM 算法相結(jié)合形成KFCM算法,即利用K-means獲取聚類中心,以此聚類中心作為FCM算法的初始聚類中心,避免了在FCM算法的迭代過程中初始聚類中心的選取不當而造成分類錯誤的問題[7-8]。
對于 X={x1,x2,…,xn}?Rs的樣本點集合,KFCM算法的具體步驟如下。
① 確定聚類參數(shù):聚類個數(shù)k、閾值ε。
②隨機選取k個對象作為初始聚類中心,根據(jù)相似度準則將數(shù)據(jù)分配到最接近的聚類中心,初始化隸屬度矩陣。
④上述步驟得出的k個聚類中心作為FCM的初始聚類中心 c(i)(i=1,2,…,k)。
相對于K-means和FCM,KFCM聚類方法分類的正確率較高。在實際應(yīng)用中,面對大量的生產(chǎn)數(shù)據(jù),采用該方法聚類將得出更為準確的結(jié)果。同時,利用KFCM作為模糊關(guān)聯(lián)規(guī)則挖掘的第一步,過程正確率較高,為獲取更加準確的規(guī)則提供了良好的基礎(chǔ)。
3 模糊關(guān)聯(lián)規(guī)則流程
本文所采用的模糊關(guān)聯(lián)規(guī)則挖掘算法(mining fuzzy association rules,MFAR),具體描述如下[9-10]。
① 應(yīng)用KFCM算法將數(shù)據(jù)庫數(shù)據(jù)T={t1,t2,…,tn}離散化,并將數(shù)據(jù)劃分為若干個模糊集等級;
②對于聚類后的數(shù)據(jù),其隸屬度值構(gòu)成一個新的數(shù)據(jù)庫;
③在新數(shù)據(jù)庫中計算所有的1-模糊屬性集的模糊支持率,得到1-模糊頻繁屬性集、組合1-模糊頻繁屬性集,得到2-模糊候選屬性集;
④計算所有的2-模糊候選屬性集的模糊支持度,刪除小于最小支持度的屬性集,得到所有的2-模糊頻繁屬性集并對其組合,得到3-模糊候選屬性集;
⑤查看3-模糊候選屬性集的子集,刪除含有不是2-模糊頻繁屬性集的3-模糊候選屬性集,計算剩余3-模糊候選屬性集的模糊支持度,刪除小于最小支持度的屬性集,得到3-模糊頻繁屬性集;
⑥采用同樣的方法得到k-模糊頻繁屬性集,從所有的模糊頻繁屬性集中生成不小于最小支持度和最小信任度的模糊關(guān)聯(lián)規(guī)則。
通過應(yīng)用模糊聚類算法得到了數(shù)據(jù)歸屬于某一類的隸屬度值,之后選取合適的閾值,從而將變量的數(shù)量型屬性轉(zhuǎn)化為布爾型,進行關(guān)聯(lián)規(guī)則的挖掘。
4 模糊關(guān)聯(lián)規(guī)則實現(xiàn)
本文的試驗數(shù)據(jù)來自于河南某水泥公司DCS系統(tǒng)采集的數(shù)據(jù),數(shù)據(jù)量豐富,為數(shù)據(jù)挖掘提供了良好的數(shù)據(jù)資源。針對本文的研究目的,首先對采集的數(shù)據(jù)進行了篩選,挑選出與分解爐控制相關(guān)的因素,整理后形成新的數(shù)據(jù)庫。同時,調(diào)整參數(shù)形成有效的模糊關(guān)聯(lián)規(guī)則挖掘模型。
4.1 選取的生產(chǎn)參數(shù)
在本文的研究過程中,選用分解爐出口溫度作為關(guān)聯(lián)規(guī)則的后項輸出,根據(jù)現(xiàn)場工作人員對分解爐的控制經(jīng)驗,選取與溫度控制相關(guān)的變量。選取的相關(guān)參數(shù)如表1所示。
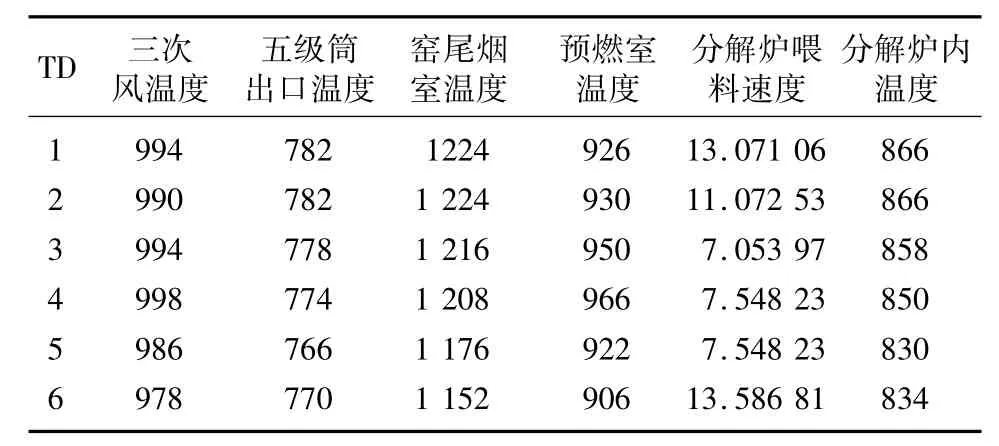
表1 選取的相關(guān)參數(shù)Tab.1 Selection of related parameters
本文一共利用了五個主要相關(guān)變量作為關(guān)聯(lián)規(guī)則的前項條件,分別為三次風(fēng)溫度、五級筒出口溫度、窯尾煙室溫度、預(yù)燃室溫度和分解爐喂料速度,并選取300個采樣點的數(shù)據(jù)進行研究。
在確定判斷參數(shù)之后,使用本文的聚類算法進行聚類劃分。數(shù)據(jù)被分為三類,分別取語言值為小、中、大,得出數(shù)據(jù)在各個類上的隸屬度值,并根據(jù)隸屬度值將初始的數(shù)量型屬性轉(zhuǎn)化為布爾型,從而可以使用關(guān)聯(lián)規(guī)則挖掘算法進行發(fā)掘。
選取的參數(shù)模糊集合如表2所示,表中S代表語言值“小”(small)、M 代表語言值“中”(middle)、B代表語言值“大”(big)。

表2 選取的參數(shù)模糊集合表Tab.2 Fuzzy set of the selected parameters
4.2 具體實現(xiàn)
在規(guī)則挖掘過程中設(shè)置適當?shù)拈撝担笥谠撻撝档闹?,反之置0,從而將規(guī)則轉(zhuǎn)化為布爾型。本文閾值設(shè)置為0.5,同時對于規(guī)則的獲取,若設(shè)置最小支持度為20%,最小置信度為40%,則可得出60條規(guī)則;若設(shè)置最小支持度為30%,最小置信度為50%,則可得出21條規(guī)則。挖掘的部分規(guī)則如表3所示。

表3 挖掘的部分規(guī)則Tab.3 Partial mining rules
從挖掘出的部分規(guī)則可以看出,規(guī)則的置信度都是比較好的,即得出的規(guī)則的正確性與可靠性較高。當規(guī)則為五級筒溫度大、預(yù)燃室溫度小時,推導(dǎo)出分解爐內(nèi)溫度小,通過和現(xiàn)場專家經(jīng)驗進行比較,表明得出的規(guī)則是正確的。
在規(guī)則的獲取過程中,由于閾值設(shè)置、算法支持度和置信度的不同,得出的規(guī)則會有不同,對于算法挖掘出的大量規(guī)則,需要進行進一步的篩選與調(diào)整。
5 結(jié)束語
本文采用基于模糊聚類的模糊關(guān)聯(lián)規(guī)則對水泥生產(chǎn)中分解爐溫度控制的大量歷史數(shù)據(jù)進行分析[11],通過使用模糊聚類KFCM算法,將分解爐溫度控制相關(guān)因素聚成若干個模糊類別,求出數(shù)據(jù)在類上的隸屬度值;然后運用MFAR算法對模糊化的現(xiàn)場分解爐溫度控制的相關(guān)參數(shù)進行分析,得到了符合實際專家經(jīng)驗的模糊規(guī)則。
試驗表明,此模糊規(guī)則解決了實際工業(yè)中專家經(jīng)驗獲取的瓶頸問題,也為實際溫度控制提供了理論依據(jù),起到了生產(chǎn)優(yōu)化的作用。
[1]胡鍇,徐巍華,渠瑜.改進模糊關(guān)聯(lián)規(guī)則及其在故障診斷中的應(yīng)用[J].組合機床與自動化加工技術(shù),2008(10):8 -12.
[2]譚華,謝赤,儲慧斌.基于模糊關(guān)聯(lián)規(guī)則的股票市場交易規(guī)則抽取[J].系統(tǒng)工程,2007,25(4):92 -97.
[3]Molina C,Sanchez D,Serrano J M,et al.Finding fuzzy association rules via restriction levels[C]∥IEEE International Conference on Fuzzy Systems,2009,Korea:1157 -1162.
[4]閆偉,張浩,陸劍峰.基于模糊聚類的模糊關(guān)聯(lián)規(guī)則在流程企業(yè)中的應(yīng)用[J].計算機應(yīng)用,2005(11):2676 -2678.
[5]陳鐵梅.模糊聚類在數(shù)據(jù)預(yù)處理中的應(yīng)用研究[J].自動化儀表,2008,29(5):36 -39.
[6]陳壽文,李明東.一種混合均值聚類算法的實現(xiàn)[J].計算機工程與應(yīng)用,2010,46(18):132 -134.
[7]汪軍,王傳玉,周鳴爭.半監(jiān)督的改進K-均值聚類算法[J].計算機工程與應(yīng)用,2009,45(28):137 -139.
[8]尹海麗,王穎潔,白鳳波.軟硬結(jié)合的快速模糊C-均值聚類算法的研究[J].計算機工程與應(yīng)用,2008,44(22):172 -174.
[9]陸建江,張亞非,宋自林.模糊關(guān)聯(lián)規(guī)則的研究與應(yīng)用[M].北京:科學(xué)出版社,2008:28 -39.
[10]鄒曉峰,陸建江,宋自林.基于模糊分類關(guān)聯(lián)規(guī)則的分類系統(tǒng)[J].計算機研究與發(fā)展,2003,40(5):651 -656.
[11]程志江,李劍波.基于遺傳算法的智能小車模糊控制系統(tǒng)的研發(fā)[J].自動化儀表,2009,30(8):4 -7.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
財經(jīng)(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
