異構數據源集成系統查詢優化
2012-04-19 01:20:10張杰
科技傳播 2012年16期
張 杰
國防信息學院,湖北武漢 430013
伴隨著計算機網絡的不斷普及和World Wide Web的出現,導致若干Web異構數據源形成,異構數據源集成為這些自然分布的異構數據源提供了完整的模式和較為一致的接口,可以消除異構、實現數據源的透明分布。對于系統查詢而言,網絡信息量的大幅增加與網絡延遲二者之間形成了強烈的反差及矛盾,導致網絡擁擠不堪,使得網絡用戶難以獲得應有或理想的服務效果。異構源數據源集成系統中,由于不同數據源具備著不同的查詢功能及不同效率,使得系統往往需要進行大量的數據處理工作,因此必須對系統的查詢功能進行優化。
為使其延遲性得到系統改善,優化過程中必須以縮減系統處理用戶請求的時間為前提基礎。對于計算機網絡中存在的各種不同存儲結構的數據,所有異構數據源集成系統均可以實現集成,因此對于HTML、XML文件等半結構化數據源,DBMS等可處理結構化數據源和文本文件等非結構化數據源等都能處理[1]。異構數據集成系統需要處理大量的數據,且各數據之間的結構大不相同,嚴重影響了查詢速度,因此必須采取優化措施改善查詢效率。本文結合實際,談談利用緩存技術和預取技術對查詢進行優化的思路。
1 緩存技術
通常情況下將程序中響應消息的本地存儲區以及控制傳輸信息存儲、刪除或獲取的子系統,也即是指臨時文件交換區[2],將其定義為緩存。利用緩存保存可以對消息進行緩存響應,能夠降低網絡的帶寬消耗和將來的響應時間,對于請求消息也同樣適用。
異構數據源集成系統具有很高的數據查詢能力,能夠實現對大量HTML、XML以及文本文件等進行處理,通常情況下,該類數據文件的查詢速度較慢,所所有的查詢均從局部數據源進行檢索,其速度必然很慢。異構數據源集成系統利用緩存技術提高數據查詢速度,它有效的實現所有用戶對全局視圖查詢結構的緩存存放,同時對新結果不斷更新,以此來替代數據源中的舊有的結果,從而有效提高緩存中數據的檢索命中率。在緩存中,保存查詢所需的全局視圖名和選擇條件,如果用戶的查詢與這些條件符合,可以由緩存直接讀取查詢結果。如用戶所需的查詢結果未存在于緩存中,然后再將查詢內容進行分解,并將分解后的結果送至各數據源,以此來獲取整個數據查詢結果。通常緩存中可以命中的查詢結果越多其查詢速度也就越快,這與緩存采用的替換算法有很大關系。在選擇緩存的的替換算法時,可以進行如下考慮:
1)局部視圖變化后,對緩存中舊的內容進行修改;2)當數據源中的數據不斷更新時,比較適合采用LRU替換算法;3)由于不同數據源的數據具有不同的訪問,由此看來傳統的LRU算法亟待改進,根據不同數據其訪問品讀的不同,將Cache塊劃分成不同的區域,同時將所有數據源均單獨分配一個獨立區域,同時該區域內容只允許請求結果進行替代。
通過緩存技術的應用,有效改善了系統性能,然而任何事物都有其兩面性,緩存技術也一樣,當緩存中所對應的存儲局部視圖出現了一定變化時,就會產生緩存中的數據結果與局部數據源數據結果不一致的現象,必須進行刷新。針對這一情況,根據不同的應用需求,異構數據源集成系統采取按需刷新和定期刷新的方式進行數據源的刷新。定期(根據數據源信息更新的時間確定)對局部視圖檢查,看其是否有所變化,同時根據其變化來對緩存內容作出相應的修改,對于一些需要快速響應的查詢處理,可從緩存種中直接進行數據的讀取。當然緩存內容一般會對局部視圖在兩次刷新前改變的情況不能進行很好的反映。如果是一些對精準度要求極高的查詢需求,定期的刷新顯然已無法滿足用戶的需求了。異構數據源集成系統則可以彌補其不足,通過按需刷新的方式,若出現新用戶查詢請求時,首先對緩存中視圖變化進行檢查,若緩存視圖中未出現變化情況,可直接提出緩存中的相應數據結果,如果緩存中查不到所需結果,則對查詢進行分解,在各個數據源中查詢更新后的數據,同時修改緩存的內容。
2 預取技術
緩存技術具有統一模式的機制特點,預取技術彌補了它的這一不足,在提高互聯網信息檢索速度上受到越來越多的重視,在備受關注的Web檢索系統中有著十分廣泛的應用[3]。其技術理論依據為:首先使用者在向服務器發出兩次HTTP請求間存在一定的使用者空閑和思考時間,其長度一般為幾秒到幾分鐘不等。若想將此段時間充分利用,即將使用的文件提前進行取回,并將其存放于緩存中,以此來減少相應等待的時間。也即是將用戶即將訪問的數據,在用戶的請求發出之前,先放置于緩存中,當用戶對其數據發出相應的請求信息后,由于該數據已經提前存放于緩存中,便可有效減少用戶等待的時間,從而將數據訪問等待的時間降到最小[4]。
這種理論應用到異構數據源集成系統也同樣適用。
異構數據源集成系統中有多種多樣的用戶需求,查詢模式也各不相同,且請求具有隨機性。同時,也不可避免的存在這種情況:有些用戶經常進行相同的查詢,他們只希望瀏覽結果而不想執行查詢;有些服務固定或相對固定。針對這種用戶的需求特點,通過服務器自動提供所需信息給那些需求相對固定的用戶,我們將其定義為服務器領取,其本質也即是服務定制。一般情況下異構數據源集成系統服務器會通過手工定制的方法來實現其數據訪問,預取過程中用戶不想在訪問中花費太多的等待時間,可提前填寫申請定制服務表,對其服務內容起始時間以及訪問周期、所需服務的時間等內容的詳細填寫。當用戶提出瀏覽請求時,不需要及時做出處理,只需將服務器端處理好的結果及時進行顯示即可[5]。
異構數據源集成系統引入預取技術提高了查詢的效率,同時針對不同用戶的不同訪問模式,借助服務器預取服務以及客戶預取服務科有效提高其使用的效率。
3 不同策略的綜合運用
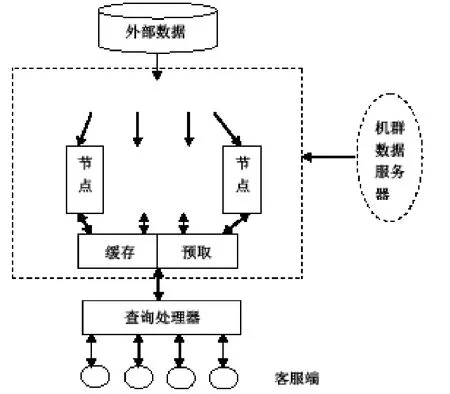
圖1 系統結構圖
異構數據源集成系統整體數據由基于機群的數據分布進行預處理,通過緩存、預取、基于用戶需求等策略,能夠提高系統的應答效率。結合緩存、預取和基于機群的數據分布三種查詢優化策略,同時從用戶請求以及數據信息等方面來提高系統運行的效率,進而提高系統對不同用戶不同請求方式和海量數據的查詢效率[6]。對系統的整體優化結構見圖1所示。
總而言之,異構數據集成系統可以對各種數據進行集成,并具有強大的數據處理量,進行查詢優化是必須處理的工作。
[1]張亞棟.分布式異構數據源集成研究[D].河北工業大學碩士學位論文,2005.
[2]麻亮. 信息集成系統中查詢結果合成研究[D].西安電子科技大學碩士學位論文,2008.
[3]唐九陽,楊強,張維明,等. 異構集成系統中面向查詢規劃的數據源能力描述框架[J],2006,27(8):1509-1513.
[4]何穎,王于同.異構數據源集成系統的查詢重寫技術研究[J].杭州電子科技大學學報,2005,25(2):65-68.
[5]尚蕾,孫志揮.基于X ML的異構數據集成系統的查詢處理[J].計算機工程,2005,31(5):79-82.
[6]馬偉.一種基于XML的異構數據源集成系統的研究[D].西安電子科技大學碩士學位論文,2008.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
甘肅教育(2020年14期)2020-09-11 07:57:42
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
時代英語·高二(2015年1期)2015-03-16 00:08:11
創業家(2015年5期)2015-02-27 07:53:25
