詞結(jié)合型未登錄詞識(shí)別方法研究
2012-04-20 09:31:36周蕾朱巧明
常熟理工學(xué)院學(xué)報(bào) 2012年4期
周蕾,朱巧明
(1.常熟理工學(xué)院計(jì)算機(jī)科學(xué)與工程學(xué)院,江蘇常熟 215500;2.江蘇省計(jì)算機(jī)信息處理技術(shù)重點(diǎn)實(shí)驗(yàn)室,江蘇蘇州 215006)
詞結(jié)合型未登錄詞識(shí)別方法研究
周蕾,朱巧明
(1.常熟理工學(xué)院計(jì)算機(jī)科學(xué)與工程學(xué)院,江蘇常熟 215500;2.江蘇省計(jì)算機(jī)信息處理技術(shù)重點(diǎn)實(shí)驗(yàn)室,江蘇蘇州 215006)
介紹一種基于詞結(jié)合提取的未登錄詞識(shí)別方法.該方法對(duì)碎片分詞后的文本建立二元模型,結(jié)合互信息和規(guī)則過濾提取由若干個(gè)詞組合而成的未登錄詞(組).測(cè)試結(jié)果準(zhǔn)確率為84.71%,召回率為72.13%.
未登錄詞;二元模型;互信息
隨著互聯(lián)網(wǎng)的發(fā)展,“中文信息處理”日益成為計(jì)算機(jī)研究的重要領(lǐng)域,而未登錄詞的存在是該領(lǐng)域研究的一個(gè)難題.很多學(xué)者對(duì)此展開研究,韓艷[1]通過對(duì)分詞后的碎片建立左右鄰信息來識(shí)別二元未登錄詞,其利用統(tǒng)計(jì)的方法,對(duì)語(yǔ)料庫(kù)的要求很高,缺少規(guī)則的調(diào)節(jié);閆蓉[2]應(yīng)用遺傳算法在分詞后的碎片中識(shí)別未登錄詞,是一次大膽的嘗試,但遺傳算法的影響因子比較多,識(shí)別的精度有待提高.程沖[3]通過建立多種規(guī)則,利用小語(yǔ)料庫(kù)識(shí)別多種領(lǐng)域中的未登錄詞,但該方法未使用統(tǒng)計(jì)方法,單純依賴規(guī)則識(shí)別,對(duì)規(guī)則的要求很高.綜觀多種方案,我們發(fā)現(xiàn)大部分學(xué)者選擇在分詞后的碎片中識(shí)別未登錄詞,縮小了識(shí)別范圍產(chǎn)生遺漏.本人也在前不久提出了一種基于分詞碎片的未登錄詞識(shí)別方案,開發(fā)測(cè)試的準(zhǔn)確率為71.79%,召回率為72.72%,效果并不理想.經(jīng)過研究發(fā)現(xiàn):在碎片分詞的基礎(chǔ)上,建立詞與詞的二元模型并且通過互信息進(jìn)行“詞結(jié)合”提取,進(jìn)一步識(shí)別未登錄詞,開放測(cè)試的結(jié)果顯示識(shí)別精度有所提高.本文主要介紹“詞結(jié)合”識(shí)別未登錄詞的具體方法.
1 未登錄詞識(shí)別整體流程介紹
經(jīng)過多次實(shí)驗(yàn)發(fā)現(xiàn),很多未登錄詞由詞詞組合而成,這種未登錄詞以新詞居多.在這些未登錄詞中,由兩個(gè)連續(xù)詞語(yǔ)組成未登錄詞的可能性最大[4].為此,本方法為連續(xù)兩詞創(chuàng)建二元模型,再根據(jù)互信息識(shí)別“詞結(jié)合”型的未登錄詞.圖1是該方法的整體流程圖.圖中待處理文本是經(jīng)過一次粗切分,并且產(chǎn)生的碎片也經(jīng)過分詞處理的文本.該方法分為三個(gè)步驟:
步驟一:兩遍掃描待處理文本,建立相鄰詞組的二元模型,計(jì)算二元模型的構(gòu)詞可信度.挑選可信度大于閾值1的二元組作為二元模型識(shí)別的未登錄詞候選;
步驟二:對(duì)構(gòu)詞可信度小于閾值1的二元組分別計(jì)算二元組的互信息值,挑選互信息值大于閾值2的二元組作為互信息識(shí)別的未登錄詞候選;
步驟三:建立規(guī)則,過濾步驟一和步驟二識(shí)別的未登錄詞,得到詞結(jié)合方法識(shí)別的未登錄詞集合.
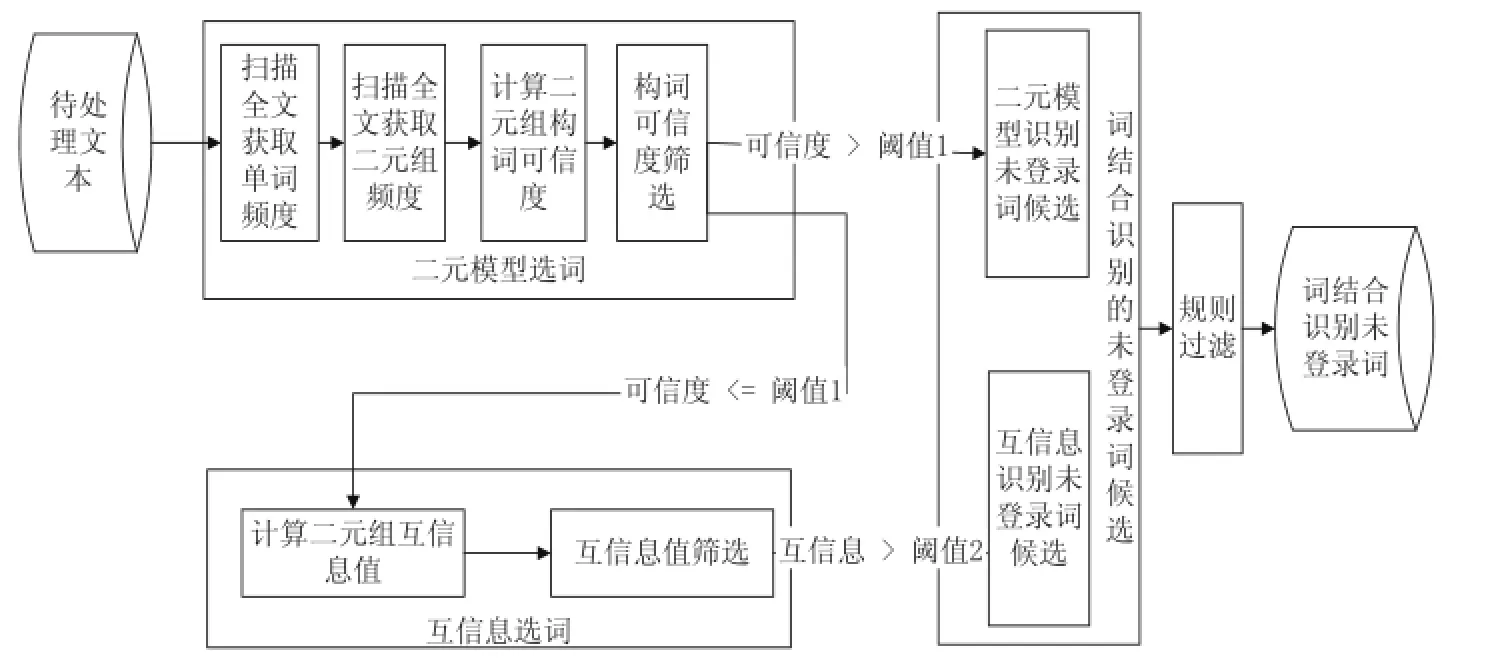
圖1 未登錄詞識(shí)別整體流程圖
2 二元模型和互信息篩選方法
2.1 二元模型選取未登錄詞
N元模型是統(tǒng)計(jì)學(xué)中經(jīng)常使用的計(jì)算方法,現(xiàn)在被很多學(xué)者用于計(jì)算機(jī)語(yǔ)言學(xué)中.原理為:把字符串根據(jù)一個(gè)長(zhǎng)度值切分,組成固定長(zhǎng)度的子串.如:字符串“CDEFG”(每個(gè)字符代表一個(gè)詞),按固定長(zhǎng)度2進(jìn)行切分,組成的二元子串集合為:CD/DE/EF/FG,共4組.下面分4步詳細(xì)介紹二元模型的選詞方法.
2.1.1 模型創(chuàng)建
取文本中處于標(biāo)點(diǎn)之間的詞片斷,以固定長(zhǎng)度2進(jìn)行切分,構(gòu)成二元模型.二元模型中記錄每個(gè)詞“WDi”和每個(gè)二元詞組“WDiWDj”在整個(gè)文本出現(xiàn)的次數(shù).
2.1.2 算法介紹
獲取“WDi”和“WDiWDj”的出現(xiàn)次數(shù),需要兩次遍歷整個(gè)文本.一次遍歷獲取文本中所有單詞,并記錄每個(gè)單詞出現(xiàn)次數(shù)DFi;第二次遍歷以每個(gè)單詞作為首詞Fst_word,記錄該詞與其他單詞Lst_word共同出現(xiàn)的次數(shù)DFij,表示為
存儲(chǔ)結(jié)構(gòu)如圖2所示,由詞表,鏈表和索引表三部分組成.詞表中存儲(chǔ)了文本中的所有單詞,按首字順序排列,其中iFword、iFcount、iHead、iLast、iPos分別記錄單詞本身、出現(xiàn)次數(shù)、鏈表地址起始、鏈表地址末尾、單詞性質(zhì);鏈表存儲(chǔ)每個(gè)首詞后跟隨的尾詞情況,其中Freqi、Posi、next分別記錄兩詞共同出現(xiàn)的次數(shù)、尾詞在詞表的位置、下一指針;索引表存儲(chǔ)單詞中的首個(gè)字符,增快搜索單詞的速度.
2.1.3 詞組選取
計(jì)算兩詞組合“WDiWDj”能成為一個(gè)未登錄詞的概率

DFi代表單詞WDi在文本中的總次數(shù),DFij代表“WDiWDj”出現(xiàn)次數(shù).
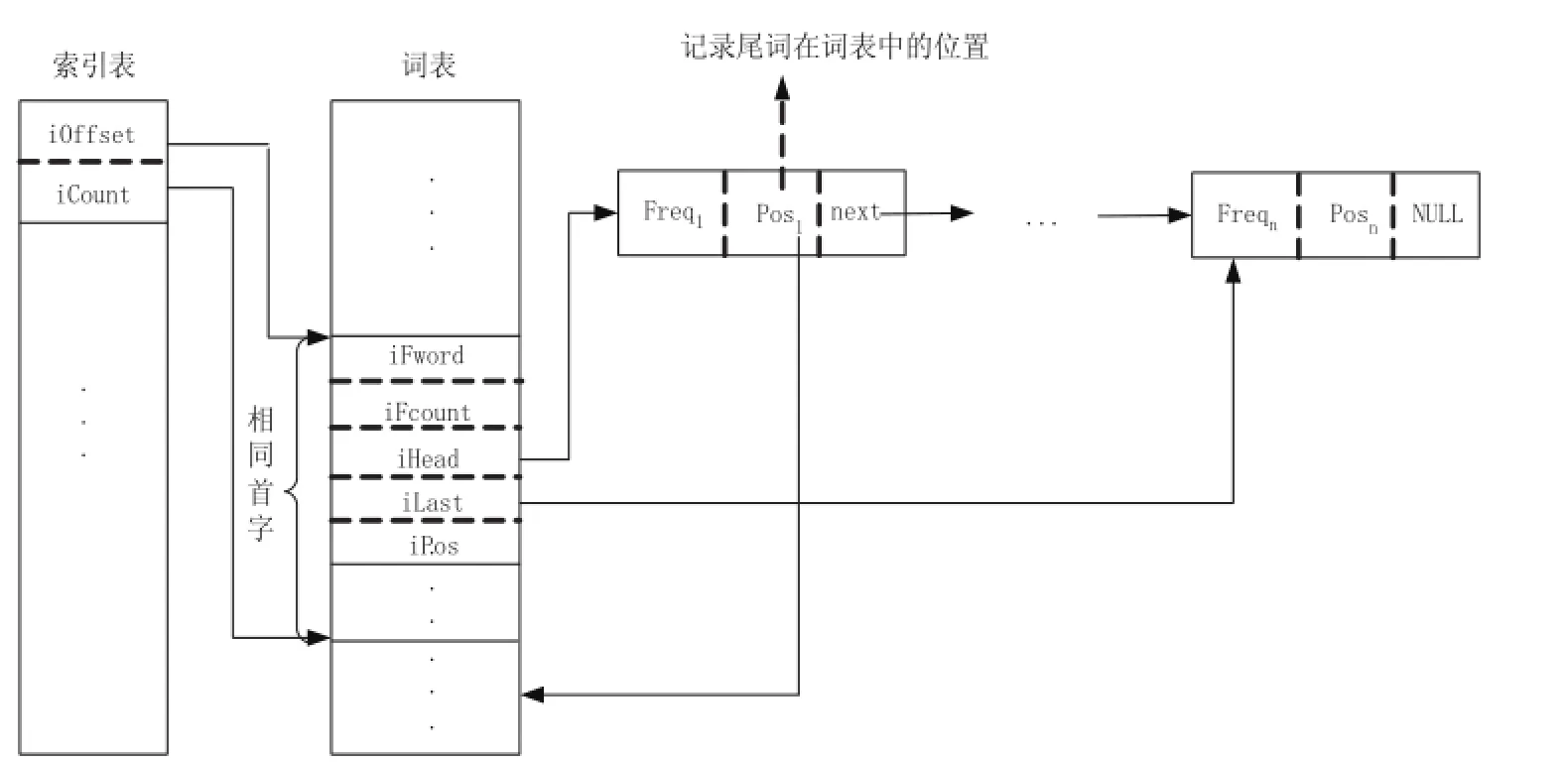
圖2 待處理文本中所有詞的存儲(chǔ)結(jié)構(gòu)
計(jì)算兩詞組合中以單詞“WDi”為首詞的概率均值
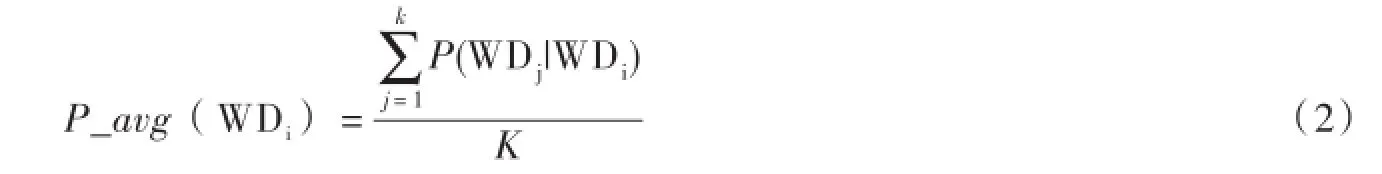
K代表以“WDi”為首詞的兩詞組合個(gè)數(shù).
將計(jì)算出的P_avg(WDi)值作為閾值1,選取概率大于閾值1的組合作為二元模型選取的未登錄詞候選.
2.1.4 結(jié)果分析
二元模型的選擇方式主要取決于P(WDj|WDi)的值相對(duì)于P_avg(WDi)的高低情況.根據(jù)(1)式,造成P(WDj|WDi)的值偏低的主要原因:
①DFi的值偏大,這同樣會(huì)引起P_avg(WDi)的值偏低,對(duì)選擇結(jié)果沒有影響.
②DFij的值偏低,這不會(huì)影響P_avg(WDi)值,因此會(huì)影響到這類兩詞組合被選為登錄詞候選.結(jié)論:二元模型對(duì)于由生僻字構(gòu)成的未登錄詞組合很難識(shí)別.
2.2 互信息選取未登錄詞
互信息主要反映詞與詞之間的結(jié)合度.對(duì)于被閾值1篩選下的二元詞組,本文選擇用互信息進(jìn)一步識(shí)別.
秋季安全生產(chǎn)調(diào)研反饋問題解決落實(shí)得怎么樣?春節(jié)前“零事故”安全保障措施有哪些?……11月26日,郯城縣高峰頭鎮(zhèn)人大舉行聯(lián)席會(huì)議,就全鎮(zhèn)安全生產(chǎn)工作情況開展專題詢問。鎮(zhèn)安監(jiān)辦、經(jīng)貿(mào)辦、派出所、交通運(yùn)輸及7大社區(qū)、48個(gè)村莊、23家涉危涉爆經(jīng)營(yíng)項(xiàng)目負(fù)責(zé)人到會(huì)應(yīng)詢。
2.2.1 算法介紹
互信息MI可由(3)式計(jì)算

其中DFi、DFj、DFij分別代表單詞“WDi”、“WDj”和二詞組合“WDij”在總文本中的出現(xiàn)次數(shù),N代表文本中所有出現(xiàn)的單詞個(gè)數(shù).
選擇互信息MI值大于閾值2的所有二詞組合作為互信息選取的未登錄詞候選.
2.2.2 結(jié)果分析
根據(jù)式(3),造成二詞組合MI值偏低有兩個(gè)原因:
②DFi*DFj的結(jié)果偏高:說明在這個(gè)二詞組合中有常用詞,這類詞組合在前面的二元模型中就可以識(shí)別,因此不存在無法識(shí)別的問題.
通過以上分析,二元模型和互信息存在互補(bǔ),能在一定程度上擴(kuò)大未登錄詞獲取范圍.
2.3 規(guī)則篩選
以上都是統(tǒng)計(jì)的方法,存在較多垃圾詞串.為了提高識(shí)別的精度,建立以下規(guī)則進(jìn)一步篩選.
(1)去除無意義單詞.將文本中詞性為助詞、嘆詞、副詞等的單詞設(shè)為無意義詞,例如“的”、“啊”等,其不參與二詞組合.
(2)去除量詞.“一”、“1”等的量詞,其不參與二詞組合.
(3)去除地名、人名.
(4)去除固定稱謂詞.例如“主任”、“校長(zhǎng)”等,其不參與二詞組合.
3 實(shí)驗(yàn)結(jié)果分析
語(yǔ)料構(gòu)成:人民日?qǐng)?bào)2005-2012年各類別報(bào)道,共120.3萬篇.選取其中1500篇進(jìn)行粗切分和碎片分詞后作為待處理文本,將人工識(shí)別后的未登錄詞作為標(biāo)準(zhǔn)答案.
封閉式測(cè)試:?jiǎn)为?dú)使用二元模型或互信息對(duì)識(shí)別效果都不理想,將兩者結(jié)合后能大幅提高識(shí)別準(zhǔn)確率和召回率.
(1)如圖3、圖4所示,閾值1不變,增大閾值2,識(shí)別未登錄詞的準(zhǔn)確率先提高后基本維持不變,召回率先略微降低后大幅降低.
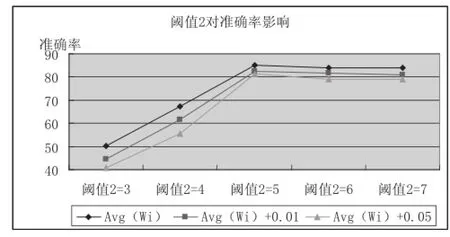
圖3 閾值2改變對(duì)準(zhǔn)確率的影響
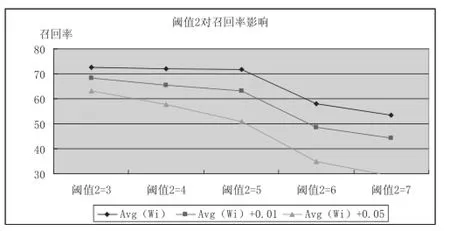
圖4 閾值2改變對(duì)召回率的影響
(2)如圖5、6所示,閾值2不變,增大閾值1,識(shí)別未登錄詞的準(zhǔn)確率基本保持不變,召回率不斷降低.
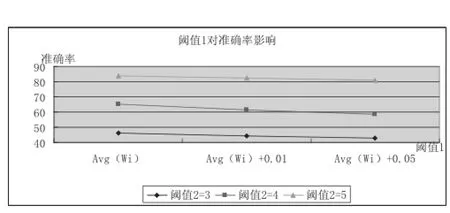
圖5 閾值1改變對(duì)準(zhǔn)確率的影響
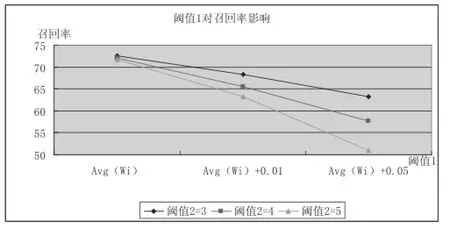
圖6 閾值1改變對(duì)召回率的影響
根據(jù)封閉測(cè)試結(jié)果,最后選取閾值1=P_avg(WDi),閾值2=5,準(zhǔn)確率為84.71%,召回率為72.13%.開放式測(cè)試:隨機(jī)抽取10篇語(yǔ)料測(cè)試,準(zhǔn)確率為79.23%,召回率為65.35%.
4 結(jié)語(yǔ)
本文提出一種新型的未登錄詞識(shí)別方法,將二元模型和互信息相結(jié)合擴(kuò)大未登錄詞的識(shí)別范圍,建立規(guī)則篩選增強(qiáng)識(shí)別的精度.從測(cè)試的結(jié)果看,能有效地識(shí)別“詞結(jié)合”型未登錄,特別適用于輸入法的更新.識(shí)別的準(zhǔn)確率和召回率還有待進(jìn)一步提高,在實(shí)際使用中,將碎片分詞和詞結(jié)合共同使用效果更好.
[1]韓艷,林煜熙,姚建民.基于統(tǒng)計(jì)信息的未登錄詞的擴(kuò)展識(shí)別方法[J].中文信息學(xué)報(bào),2009,23(3):24-30.
[2]閆蓉,張蕾.基于遺傳算法的漢語(yǔ)未登錄詞識(shí)別[J].計(jì)算機(jī)應(yīng)用與軟件,2008,25(7):88-90.
[3]程沖,黃水清.自適應(yīng)分詞算法中的未登錄詞識(shí)別技術(shù)研究[J].情報(bào)學(xué)報(bào),2009,28(4):530-536.
[4]李榮,鄭家恒,郭梅英.基于遺傳算法的隱馬爾可夫模型在名詞短語(yǔ)識(shí)別中的應(yīng)用研究[J].計(jì)算機(jī)科學(xué),2009,36(10):244-247.
[5]孫茂松,鄒嘉彥.漢語(yǔ)自動(dòng)分詞研究評(píng)述[EB/OL].http://blog.csdn.net/dzkadin/archive/2004/12/02/202190.aspx.
[6]都菁,熊海靈.基于論壇語(yǔ)料識(shí)別中文未登錄詞的方法[J].計(jì)算機(jī)工程與設(shè)計(jì),2010,31(3):630-633.
[7]唐旭日,陳小荷,許超,等.基于篇章的中文地名識(shí)別研究[J].中文信息學(xué)報(bào),2010,24(2):24-32.
[8]程傳鵬.一種基于位置信息的未登錄詞的識(shí)別方法[J].中原工學(xué)院學(xué)報(bào),2008,19(6):32-33.
[9]http://202.119.104.100/wxy/cipp/main.asp,CIPP中文信息處理平臺(tái).
Research on the Recognition Method of Unknown Chinese Words Based On Compound Words Recognition
ZHOU Lei,ZHU Qiao-ming
(1.(School of Computer Science and Engineering,ChangShu Institute of Technology,Changshu 215500,China; 2.Jiangsu Provincial Key Laboratory for Computer Information Processing Technology,Suzhou 215006,China)
This paper introduces a method to extract unknown Chinese words based on compound words recogni?tion.This method builds a bi-gram model on the text which is processed by fragments segmentation,and it uses mutual information and regulations to combine some adjacent words to unknown words.The precision on the open test sets is 84.71%and recall is 72.13%.
unknown Chinese words;bi-gram model;mutual information
TP391
A
1008-2794(2012)04-0110-05
2012-02-28
江蘇省自然科學(xué)基金資助項(xiàng)目“基于超媒體引擎的個(gè)人辦公移動(dòng)桌面”(BK2003030);江蘇省教育廳自然基金資助項(xiàng)目“漢語(yǔ)新詞匯自動(dòng)抽取和發(fā)布信息網(wǎng)格的研究”(04KKB320134)
周蕾(1980—),女,江蘇常熟人,講師,碩士,研究方向:中文信息處理.
朱巧明(1963—),男,江蘇昆山人,教授,博導(dǎo),研究方向:中文信息處理技術(shù),分節(jié)式計(jì)算.
猜你喜歡
閱讀(快樂英語(yǔ)高年級(jí))(2020年8期)2020-01-08 02:21:16
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
意林(繪英語(yǔ))(2017年5期)2017-05-15 02:17:23
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
