地點(diǎn)信息在話題檢測(cè)中的應(yīng)用
2012-06-01 02:55:00謝林燕戚銀城
電子科技 2012年1期
謝林燕,戚銀城,孫 卓
(華北電力大學(xué)電子與通信工程系,河北保定 071003)
隨著信息傳播手段的進(jìn)步,尤其是互聯(lián)網(wǎng)的出現(xiàn),已對(duì)信息爆炸的情況,如何快捷準(zhǔn)確地獲取有效信息是人們關(guān)注的主要問(wèn)題。由于網(wǎng)絡(luò)信息數(shù)量過(guò)大,與一個(gè)話題相關(guān)的信息往往孤立分散在不同地方,并出現(xiàn)在不同的時(shí)間,僅通過(guò)這些孤立的信息,人們對(duì)某些事件難以做到全面把握。因此人們迫切希望擁有一種工具,能夠自動(dòng)把相關(guān)話題的信息匯總供人查閱。話題檢測(cè)與跟蹤(Topic Detection and Tracking,TDT[1])技術(shù)在這種情況下應(yīng)運(yùn)而生。話題檢測(cè)與跟蹤是一項(xiàng)旨在依據(jù)事件對(duì)語(yǔ)言文本信息流進(jìn)行組織、利用的研究,也是為應(yīng)對(duì)信息過(guò)載問(wèn)題而提出的一項(xiàng)應(yīng)用研究。話題檢測(cè)是TDT測(cè)評(píng)中的一項(xiàng)測(cè)評(píng)任務(wù),即將新聞數(shù)據(jù)流中的報(bào)道歸入不同的話題,并在必要時(shí)建立新話題的技術(shù)。話題檢測(cè)可分為兩個(gè)階段:檢測(cè)新話題的出現(xiàn)和將后續(xù)報(bào)道加入相關(guān)的話題。圖1為話題檢測(cè)的基本思想。
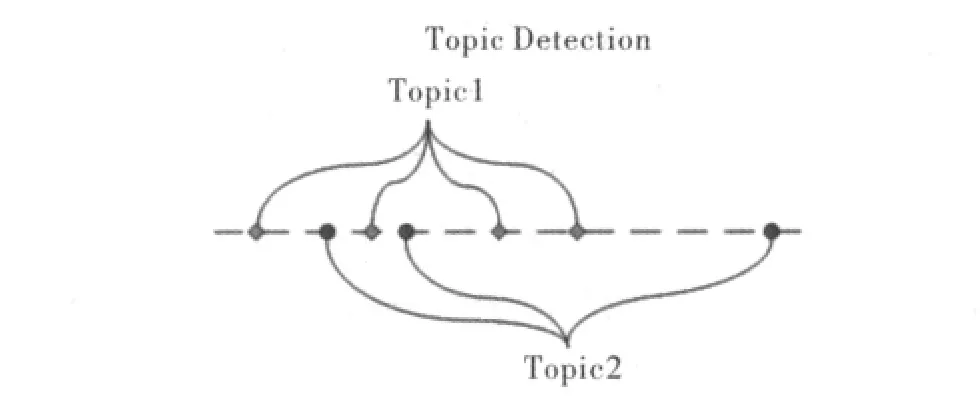
圖1 話題檢測(cè)基本思想
目前,已有多位學(xué)者針對(duì)話題檢測(cè)技術(shù)展開(kāi)研究,并取得了一定的進(jìn)展。文獻(xiàn)[2]提出了一種帶有時(shí)間窗口的單遍聚類方法,話題和報(bào)道之間的相似度計(jì)算主要采用向量夾角余弦值,但根據(jù)時(shí)間因素利用一個(gè)時(shí)間窗口作調(diào)整。UMass[3]大學(xué)系統(tǒng)的核心算法仍是單遍聚類算法,在質(zhì)心比較策略中,設(shè)置了兩個(gè)閾值θmatch和θcertain,當(dāng)前報(bào)道與某話題類的質(zhì)心相似度高于θmatch時(shí),就斷定該報(bào)道應(yīng)當(dāng)歸入此類,只有當(dāng)它們之間相似度值高于θcertain時(shí),才用當(dāng)前報(bào)道調(diào)整該話題類的質(zhì)心,即該話題類的向量表示。文獻(xiàn)[4]提出了基于多層聚類的有向無(wú)環(huán)圖生成算法,通過(guò)將單層文本聚類變?yōu)槎鄬泳垲悾涗浉鲗哟伍g結(jié)點(diǎn)的合并過(guò)程,得到話題層次結(jié)構(gòu)。文獻(xiàn)[5]提出基于單遍聚類算法和改進(jìn)的KNN算法相結(jié)合的方法進(jìn)行話題檢測(cè)。這些方法的共同點(diǎn)是均采用聚類的方法來(lái)實(shí)現(xiàn)話題檢測(cè),以語(yǔ)法信息為基礎(chǔ)計(jì)算話題和報(bào)道的相似度,通過(guò)改進(jìn)聚類方法來(lái)提高檢測(cè)精度。然而在話題檢測(cè)研究中存在一個(gè)難題,就是難以區(qū)分相似話題[6],比如兩次不同的地震災(zāi)害或者恐怖事件,因?yàn)殛P(guān)于這些事件的報(bào)道中所用的詞匯大部分是相同的,所以單一地依靠文本內(nèi)容的相似度計(jì)算,難以將這些報(bào)道正確地進(jìn)行分類。
文中將地點(diǎn)信息運(yùn)用到話題檢測(cè)中,將報(bào)道與話題語(yǔ)料用向量空間模型表示。改進(jìn)基于Baseline模型中的文本內(nèi)容相似度計(jì)算方法,將新聞報(bào)道中涉及的地點(diǎn)因素應(yīng)用到相似度計(jì)算中,并與文本內(nèi)容相似度相結(jié)合,兩者的加權(quán)和作為最終的新聞報(bào)道與話題的相似度,由此來(lái)克服相似話題的難以區(qū)分問(wèn)題。實(shí)驗(yàn)證明,該方法提高了檢測(cè)精度。
1 建立報(bào)道與話題模型
1.1 預(yù)處理與報(bào)道模型
對(duì)收集到的報(bào)道語(yǔ)料進(jìn)行分詞,分詞結(jié)果中含有大量的冠詞、介詞、連詞等出現(xiàn)頻率較高的詞匯,其對(duì)文本表達(dá)的意思基本沒(méi)有任何貢獻(xiàn),更多的作用在于語(yǔ)法上,即稱為停用詞。為去除噪聲,降低后續(xù)處理流程的復(fù)雜度,減輕整個(gè)算法的計(jì)算開(kāi)銷,提高檢測(cè)精度,首先要去除停用詞。
采用VSM模型表示報(bào)道和話題。基本思想是:它把文本表示成為一個(gè)空間向量,向量的每一維代表該文本的一個(gè)特征(Term),假設(shè)F為經(jīng)過(guò)預(yù)處理的報(bào)道,term1,term2,…,termm是報(bào)道S中的m個(gè)不同的詞,那么S可以表示為:S=(term1,ω1;term2,ω2;…;termm,ωm),ωi是 termi在報(bào)道S中的權(quán)值,文中采用TF - IDF[7]公式來(lái)計(jì)算特征項(xiàng)權(quán)值
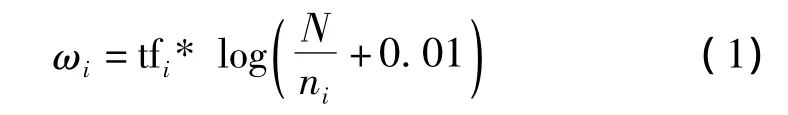
其中,tfi是termi在報(bào)道S中的詞頻;N是所有已輸入報(bào)道的總數(shù);ni是N篇報(bào)道中含有termi報(bào)道的數(shù)量。
1.2 話題模型
話題是用質(zhì)心來(lái)表示,質(zhì)心是用向量空間模型表示。為了將話題表示成質(zhì)心,需經(jīng)過(guò)抽取特征項(xiàng)和計(jì)算特征項(xiàng)權(quán)值兩步。實(shí)驗(yàn)過(guò)程中,從收集到的相關(guān)語(yǔ)料中隨機(jī)抽取4篇作為訓(xùn)練語(yǔ)料形成相應(yīng)話題。首先對(duì)訓(xùn)練語(yǔ)料進(jìn)行預(yù)處理,然后分別計(jì)算每篇訓(xùn)練語(yǔ)料的特征項(xiàng)權(quán)重。最后進(jìn)行話題特征項(xiàng)的權(quán)重計(jì)算。文中通過(guò)式(2)計(jì)算話題特征項(xiàng)權(quán)重。
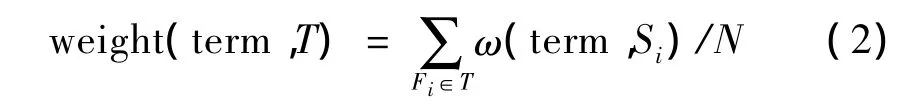
其中,weight(term,T)表示特征項(xiàng)term在話題T中的權(quán)重;Si是話題T中包含的新聞報(bào)道;N為話題T包含新聞報(bào)道的總數(shù)量;ω(term,Si)是特征項(xiàng)term在Si中的權(quán)重值。
2 報(bào)道與話題相似度計(jì)算
2.1 基于Baseline模型的報(bào)道與話題相似度計(jì)算
在基于Baseline模型的報(bào)道與話題的相似度計(jì)算中,選用向量夾角余弦函數(shù)作為相似度計(jì)算方法。假設(shè)報(bào)道S與話題T的向量空間模型分別為S=(ws1,ws2,…,wsn)和T=(wt1,wt2,…,wtn),那么報(bào)道S與話題T基于夾角余弦函數(shù)的相似度如式(3)所示。
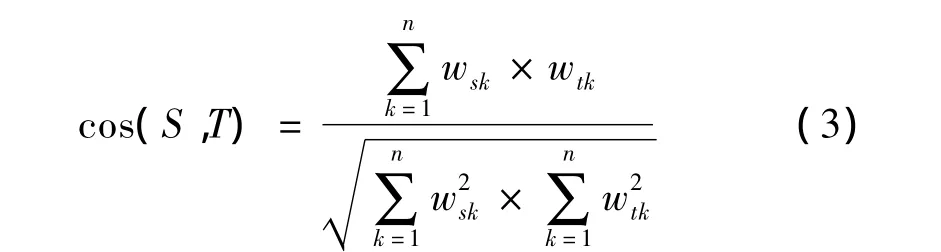
2.2 地點(diǎn)信息報(bào)道與話題相似度計(jì)算
特定話題中涉及到的地點(diǎn)信息在解決相似話題難以區(qū)分的問(wèn)題中起著不可忽視的作用。由于相似話題通常采用相同的詞語(yǔ)進(jìn)行描述,如兩次不同的交通事故或恐怖事件,僅采用基于Baseline模型的相似度計(jì)算方法很難將相似話題正確區(qū)分。文中提出結(jié)合地點(diǎn)信息的話題檢測(cè)方法,通過(guò)構(gòu)造地點(diǎn)相似度計(jì)算函數(shù),獲得地點(diǎn)相似度,并將其計(jì)算結(jié)果應(yīng)用于話題檢測(cè)中。實(shí)驗(yàn)結(jié)果證明,提出的結(jié)合地點(diǎn)相似度的話題檢測(cè)方法能很好地改進(jìn)系統(tǒng)性能指標(biāo)。
提取報(bào)道的地點(diǎn)信息形成地點(diǎn)向量,并與相應(yīng)話題的地點(diǎn)向量進(jìn)行相似度計(jì)算,計(jì)算公式如式(4)所示。
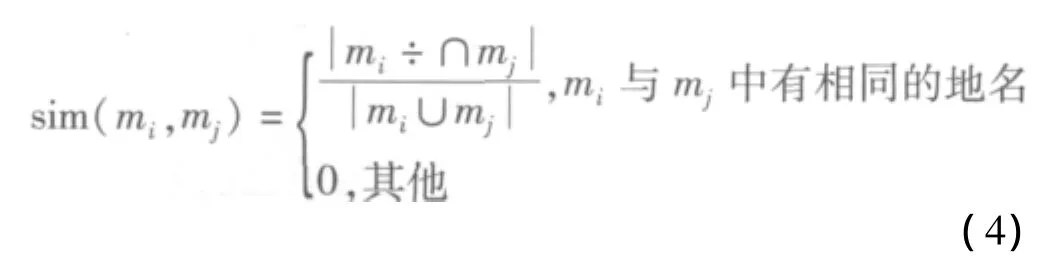

將基于Baseline模型的相似度和地點(diǎn)相似度分別計(jì)算,通過(guò)兩類相似度計(jì)算結(jié)果線性組合的方式得到最終的相似度
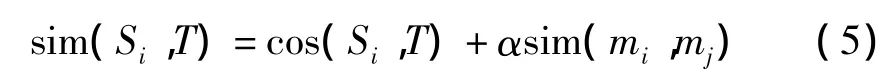
其中,α為設(shè)定的參數(shù),實(shí)驗(yàn)中α=0.4。
3 話題檢測(cè)算法
文中以Single-Pass聚類策略為基礎(chǔ)實(shí)現(xiàn)話題檢測(cè)算法,該算法按新聞報(bào)道輸入的先后順序依次處理信息流中的報(bào)道,直到所有的報(bào)道處理完畢,具體過(guò)程如下:
(1)對(duì)新聞報(bào)道進(jìn)行預(yù)處理,然后利用上述的特征權(quán)重計(jì)算方法計(jì)算報(bào)道和話題中各個(gè)特征詞的權(quán)值,分別建立報(bào)道模型和話題模型。
(2)計(jì)算新聞報(bào)道與話題的相似度,與預(yù)設(shè)的閾值進(jìn)行比較,報(bào)道與話題的相似度高于閾值,則判定該報(bào)道與話題相關(guān),否則判定該報(bào)道與話題不相關(guān)。
(3)重復(fù)上述過(guò)程直到信息流中的所有報(bào)道都處理完畢。
4 實(shí)驗(yàn)結(jié)果與分析
4.1 評(píng)價(jià)指標(biāo)
文中實(shí)驗(yàn)采用的性能指標(biāo)為正確率(Precision)、召回率(Recall)和F1指數(shù),其定義如表1所示。
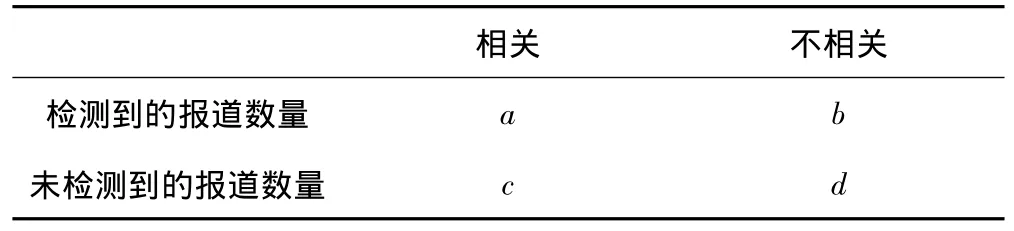
表1 評(píng)價(jià)指標(biāo)
其中,收集到的測(cè)試新聞?wù)Z料中與話題相關(guān)的報(bào)道數(shù)目為a+c,不相關(guān)的報(bào)道數(shù)目為b+d。檢測(cè)結(jié)果中,判定與話題相關(guān)的報(bào)道數(shù)目為a+b,不相關(guān)的報(bào)道數(shù)目為c+d。正確率、召回率和F1指數(shù)計(jì)算方法如下所示。

4.2 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)采用從互聯(lián)網(wǎng)收集到的新聞報(bào)道作為評(píng)測(cè)語(yǔ)料,該語(yǔ)料包含725篇中文報(bào)道,定義了10個(gè)話題,表2為話題事件與相關(guān)新聞報(bào)道數(shù)目。
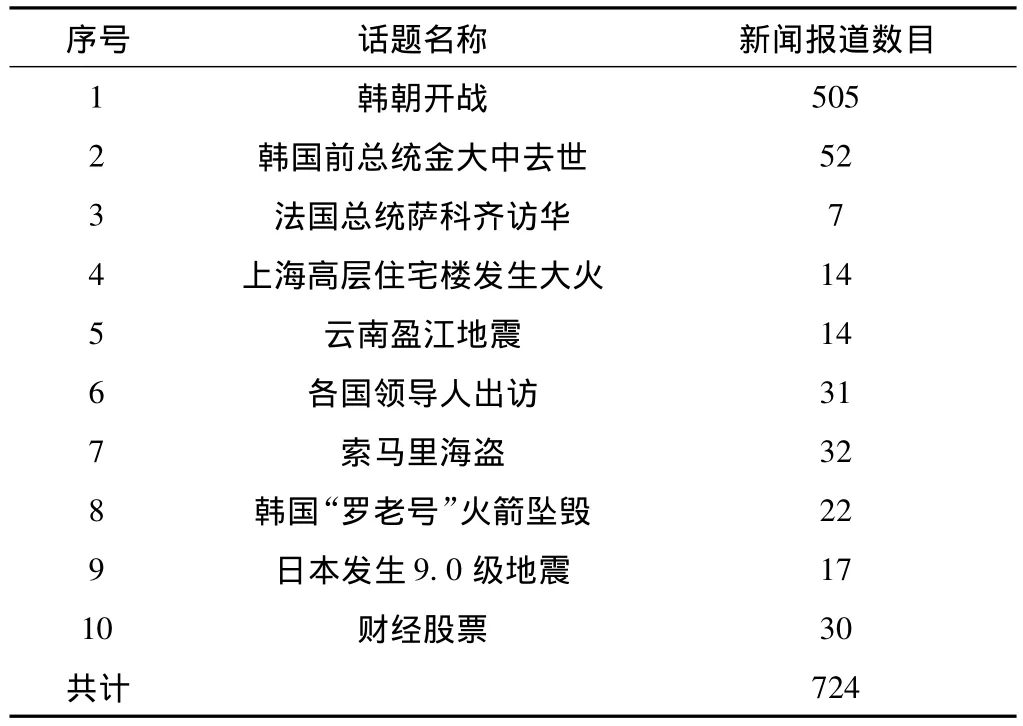
表2 話題事件與相關(guān)新聞報(bào)道數(shù)
隨機(jī)選取4篇與韓朝開(kāi)戰(zhàn)相關(guān)的新聞報(bào)道作為訓(xùn)練語(yǔ)料,構(gòu)建話題模型,剩余720篇新聞報(bào)道作為測(cè)試語(yǔ)料,其中選取韓朝開(kāi)戰(zhàn)事件作為本次實(shí)驗(yàn)的相關(guān)話題,其余話題作為與該話題不相關(guān)的反例話題,共計(jì)219篇。分別對(duì)基于Baseline模型和結(jié)合地點(diǎn)信息兩種方法進(jìn)行實(shí)驗(yàn)對(duì)比,實(shí)驗(yàn)結(jié)果如表3所示。

?
由上述實(shí)驗(yàn)可知,通過(guò)設(shè)定不同的相似度閾值發(fā)現(xiàn),隨著該值的增大,正確率提高,召回率下降;結(jié)合地點(diǎn)信息的話題檢測(cè)方法的召回率在同等條件下,高于基于Baseline模型的檢測(cè)結(jié)果,同時(shí),F(xiàn)1測(cè)試值較Baseline模型改進(jìn)了7.306%,說(shuō)明結(jié)合地點(diǎn)信息的話題檢測(cè)系統(tǒng)的檢測(cè)性能優(yōu)于基于Baseline模型的話題檢測(cè)系統(tǒng)。綜上所述,將地點(diǎn)信息應(yīng)用到話題檢測(cè)是一種行之有效的方法。
5 結(jié)束語(yǔ)
針對(duì)話題檢測(cè)方法進(jìn)行了初步研究,通過(guò)分析新聞報(bào)道語(yǔ)料的特點(diǎn),將新聞報(bào)道中的地點(diǎn)信息融入報(bào)道與話題的相似度計(jì)算中,即構(gòu)建地點(diǎn)相似度計(jì)算公式,并結(jié)合基于Baseline模型的相似度計(jì)算結(jié)果,將兩類相似度的計(jì)算結(jié)果進(jìn)行線性組合,從而得到報(bào)道和話題的相似度計(jì)算結(jié)果,完成話題檢測(cè)任務(wù)。實(shí)驗(yàn)結(jié)果表明,將地點(diǎn)信息應(yīng)用于話題檢測(cè)能夠提高性能指標(biāo)。
[1]李保利,俞士汶.話題識(shí)別與跟蹤研究[J].計(jì)算機(jī)工程與應(yīng)用,2003,39(17):7 -10.
[2]YANG Y,CARBONELL J,BROWN R,et al.Multi- strategy learning for topic detection and tracking[C].Proc.of the TDT2002 Workshop,2002:85 -114.
[3]KUPIEC J,PEDERSEN J.A trainable document summarizer[C].Seattle,Washington,USA:Proceedings of the 18th Annual Int'l ACM SIGIR Conf on Research and Development in Information Retrieval(SIGIR'95),1995:68 -73.
[4]于滿泉,駱衛(wèi)華,許洪波,等.話題識(shí)別與跟蹤中的層次化話題識(shí)別技術(shù)研究[J].計(jì)算機(jī)研究與發(fā)展,2006,43(3):489-495.
[5]李保利.漢語(yǔ)新聞報(bào)道中的話題跟蹤與識(shí)別研究[D].北京:北京大學(xué),2003.
[6]洪宇,張宇,劉挺,等.話題檢測(cè)與跟蹤的評(píng)測(cè)及研究綜述[J].中文信息學(xué)報(bào),2007,21(6):71 -87.
[7]劉海峰,王元元,劉守生.一種組合型中文分類特征選擇方法[J].廣西師范大學(xué)學(xué)報(bào):自然科學(xué)版,2007,25(4):208-211.
猜你喜歡
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中外會(huì)展(2014年4期)2014-11-27 07:46:46
