基于數據挖掘技術的電力網絡參數估計方法研究
2012-06-17 08:19:14李吉德彭生剛王承民
山東電力技術 2012年1期
李吉德,彭生剛,王承民
(1.長島供電公司,山東 煙臺 265812;2.平度供電公司,山東 青島 266700;3.上海交通大學電子信息與電氣工程學院,上海 200030)
0 引言
狀態估計是能量管理系統(EMS)的重要組成部分,安全分析、經濟運行等功能在很大程度上取決于狀態估計所提供的估計值的正確性。而狀態估計結果的正確性依賴于量測量的正確性、量測量的冗余度及正確的網絡拓樸和網絡參數。對于量測量的誤差現有較多的方法解決,而且效果較好[1];而網絡拓樸結構的錯誤一般會造成較明顯錯誤的狀態估計值,所以也比較容量辯識;但一般網絡參數值誤差較難發現,而且這種誤差如不被發現的話,一直使用會使狀態估計產生永遠的誤差。
導致給定參數值與實際值之間誤差的原因通常為:1)有時因缺少實測參數量而直接采用設計參數或參數測量條件與實際運行條件差別較大,這都會使給定的參數值與實際運行中的元件參數有差別;2)實際運行中的元件參數因改線、改建,或因環境變化等原因而局部地、緩慢地發生著變化;3)調度中心對運行中的自動調壓變壓器的分接位置或補償電容器的組數掌握得不一定確切。特別是輸電線路,一般給定的參數值是在理想情況下的,但實際線路的情況與理想情況有時相差很大,因此一般給定的線路參數值和實際值相比大約有 25%~30%的誤差[2]。
錯誤的參數值會造成以下結果:1)參數錯誤對所包含錯誤支路參數的狀態估計量產生較大的誤差,從而影響其它一些應用,如安全分析等;2)一些在正常范圍內的測量值因與網絡參數不一致而被檢測成壞數據;3)長期的誤差使運行部門對狀態估計的結果失去信心;4)直接使用給定的參數值減弱了狀態估計檢測辯識壞數據的能力;5)功率分配不經濟,特別是實施電力市場以后,在一些情況下可能增加交易成本,文獻[2]舉例說明了此種情況。
因此網絡參數估計在電力系統分析中得到越來越多的關注,與狀態估計和拓撲估計一樣變得重要。研究這方面的文章較多[3-8],但對參數估計大致可以分為以下兩種方法:1)基于殘差和量測誤差之間關系的靈敏度分析[3-4],這種基于靈敏度分析的狀態估計與參數估計,采用一般的狀態向量,在狀態估計結束后再進行參數估計;2)基于增廣矩陣的估計,又可以分為基于常規法方程的增廣狀態估計[5-6]和基于卡爾曼濾波的增廣狀態估計[7-8]兩種。基于常規法方程的增廣狀態估計方法受權重影響較大,而且增加了估計的矢量,矩陣的行和列向量也得到了增加了,降低了計算效率,特別是應用于在線計算時,處理速度較慢。此方法適用于估計值為常量的參數。基于卡爾曼濾波的增廣狀態估計方法一般認為后一時刻的值等于前一時刻的估計值,但如果負荷變化比較快時,濾波的收斂性會較差,此方法適用于估計值隨時間變化的參數。
上述兩種方法的參數估計值與量測值的精確度有很大關系。如果量測量比較正確,那么估計的參數值精確度就會高于不估計的參數值;但如果參數值較為正確,而量測值誤差較大,則會適得其反。而且如果與估計參數相關的量測量的誤差沒有檢測出來的話,所得的參數估計值精確也較低。
數據挖掘技術也被稱為數據庫知識發現KDD(Knowledge Discovery in Database),主要目的是從大量的數據中抽取正確的、未知的、有價值的模式或規律等知識的復雜過程。數據挖掘所得到的知識雖因具體應用目的不同而有所不同,但總而言之是一種能夠為人們用于輔助決策的知識。本文提出了一種基于數據挖掘技術的參數估計方法,利用SCADA系統所保存的大量歷史量測數據進行分析,消除各種因素帶來的誤差。首先對歷史數據進行了預處理,然后對預處理后的數據進行聚類分析,得到各個分類,之后把各個類的數據代入線性回歸方程,就可用最小二乘法解出各種情況下的網絡參數值。在應用的時候只要把實際量測的數據歸入其中一類就可得到此種情況下的參數值,以供狀態估計等所用。從預處理算法直至后期的回歸算法都對大量的歷史量測數據給予了充分的考慮,因而最后計算得到的參數估計值能夠正確反映網絡的實際情況。
1 樣本選擇
聚類分析是數據挖掘中一種十分重要的分析方法。所謂聚類是一個將數據集劃分為若干組或類的過程,并使得同一組內的數據對象具有較高的相似度,而不同組中的數據對象則是不相似的。相似或不相似的度量是基于數據對象描述屬性的值確定的。通常是利用(各對象間)距離進行描述的。
輸電網絡主要有兩個設備的參數,一是輸電線路的參數,另一是變壓器的參數。輸電線路的電導、電納等參數主要受電流,周圍溫度以及風等幾個因素影響,同時時間也是一個主要因素,這是因為隨著時間的增長,線路會不斷的老化,從而線路參數會不斷發生變化。所以在進行數據挖掘過程中,如數據的保存時間太久的話一般就不作為挖掘的對象了。而變壓器參數主要是變壓器抽頭的錯誤所帶來的影響。所以在聚類分析時,線路參數分類主要依據周圍環境、天氣、溫度及負荷水平等,而變壓器參數分類則主要依據負荷水平和兩端電壓。在線路聚類分析中用到的數據矩陣的結構如下:

上式中Weather代表天氣,Temp代表溫度。變壓器的矩陣結構形式和上式一樣。
根據線路和變壓器的數據矩陣結構,文章采用基于劃分方法的聚類分析。基于劃分的聚類算法就是把給定包含n個數據對象的數據庫和所要形成的聚類個數K,劃分算法將對象集合劃分為K份(K<n),其中,每個劃分代表一個聚類。所形成的聚類將使得邇客觀劃分標準(常稱為相似函數,如:距離)最優化,從而使得一個聚類中的對象是“相似”的,而不同聚類中的對象是“不相似”的。
劃分方法采用k-means算法。此算法的步驟如下:
①初始化。確定分組的個數K,在樣本空間中選擇K個點,稱為種子,這些種子構成初始聚類中心,它們之間應該有足夠的距離用于改善算法的收斂性。一般要求選出的K個觀測數據(種子)間距離的倒數大于給定的閥值,而且它們的距離應該大于它們與觀測數據的聚類的距離。一旦形成了種子,就形成了觀測數據的初始劃分,將觀測數據分到離中心較近的組中。
②轉移評價:計算每個觀測數據到K個聚類中心的距離,觀察數據和被分配到組間中心的距離應最小。如果不是最小,觀察數據就應該被分到另一個離它最近的組中,再次計算舊組和新組的聚類中心。
③循環:重復步驟2,直到得到一個較為穩定的分組。
為了計算觀測數據和組中心的距離,k-means算法采用了歐式距離,在第t步的迭代中,第i個觀測數據和第l個聚類中心的距離等于
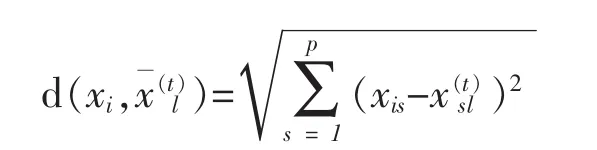
i=1,2…n;l=1,2…K
此方法的一個缺點就是如何確定K的數值。K太多了會影響每次搜索類的時間,增加了計算時間,實時性就會比較差;K太少了又不能正確反映網絡參數的真值。
2 數據處理
在進行數據挖掘以前,首先要進行數據的處理。因為對于大量的數據,肯定會存在不完整、含噪聲和不一致的數據,而如果不對這些數據處理,會影響數據挖掘所獲模式知識的質量。
2.1 空缺值的處理
由SCADA所提供的量測數據中,因通信通道問題,或量測裝置問題,肯定會有一部分量測量是沒有傳送到調度中心的;或送到了數據庫,但沒有保存到數據庫。所有這些造成了數據的缺失。對于數據缺失值的處理,應盡可能的利用其同一時段其它所采集到的數據來進行填補。
文章采用rough理論的ROUSTIDA算法來進行補全缺失值。ROUSTIDA基本思想是:缺失數據值的填補應使完整化的信息系統產生的分類規則具有盡可能高的支持度,產生的規則盡量集中。該算法的目標是使具有缺失值的對象和信息系統的其他相似對象的屬性值盡可能保持一致,并盡可能使屬性值之間的差異最小。
具體算法的實現:可辨識矩陣反映了對象間的屬性差異,因此利用可辨識矩陣作為算法的基礎,是一種很自然的想法。由于不完備信息系統中存在多個屬性值和其不同的分布,因此對信息系統遺失數據值的填補不是通過對初始可辨識矩陣的一次運算并加以完整化分析就能對所有的遺失值進行補齊;實際上要經過多次對擴充差異矩陣的計算和完整化分析,直至終止條件成立。為此,設初始信息系統為S0,對象集為,相應的可辨識矩陣為M0,xi的遺失屬性集為,無差別對象集為;第r次完整化分析后的信息系統為Sr,對象集為,相應的可辨識矩陣為 Mr,xi的遺失屬性集為,無差別對象集為,完整化分析所依賴可辨識矩陣計算,具體過程如下:設Mr+1=[Mr+1(i,j)]n×n],r=0,1,2…,則 Mr+1(i,j)計算如下:
這樣就可以把缺失值以最有可能值來進行填補。
2.2 異常點的判斷處理
異常點就是與數據庫中的大部分數值有很大的不同或不一致。對于異常數據,采用基于距離的檢測方法。基于距離的基本思想:如果樣本S中至少有一部分數量為p的樣本到Si的距離比d大,那么樣本Si是數據集S中的一個異常樣本。判斷的標準建立在兩個參數p、d的基礎上,兩個參數的值可根據數據的相關知識來確定。文章把5個采樣斷面作為一組,因此把p設為3,d值則隨功率,電壓的不同而選擇,一般線路功率 d值不超過線路所傳輸功率的20%左右,電壓d值一般是線路額定電壓的10%左右。如果在此組數據中檢測到異常值,則此異常值用另外幾個數據的平均值來替換。
2.3 數據的替換
對于每次采集的數據,進行完數據處理以后,就保存于數據庫。但是實際運行中的元件參數因時間的變化會緩慢的發生變化。因此在進行數據挖掘時,數據間的時間間隔不能太長。因此每次存入新的采集數據時,把距此次數據時間間隔最長的那批數據替換掉,以保證數據庫中的數據能反映最近的網絡實況。
3 基于線性回歸方法的參數估計
在聚類分析完成以后,可得到按照天氣、溫度與負荷水平等劃分的各個類別的樣本數據。把各類的大量數據代入線性回歸方程就可以計算不同天氣、溫度與負荷水平等條件下的網絡的參數值。
3.1 多元線性回歸方程
多元線性回歸方程的表達式:
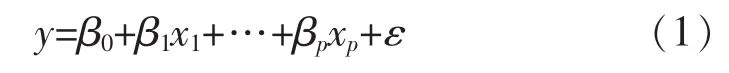
其中ε是服從正態分布N(0,σ2)的隨機變量。
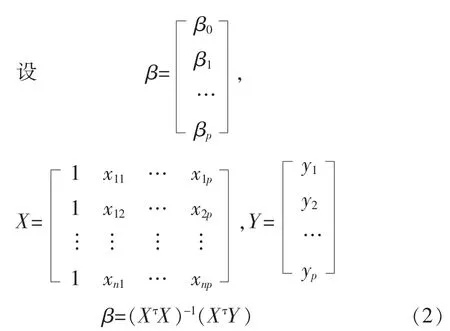
其中β是回歸系統,它是一個無偏估計,β的協方差矩陣等于 ?2C,其中 C=(XτX)-1,Xτ為 X 的轉置矩陣。
由于β是無偏估計,所以利用大量的數據進行計算,可降低β的誤差,當數據足夠多的時候,誤差將會趨向于零。
3.2 線路參數的回歸方程
輸電線路的潮流方程如下:
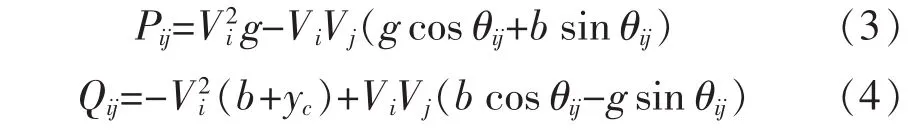
式中Pij、Qij分別代表線路ij的始端有功、無功功率,其方向規定:由i流向j為正,由j流向i為負。
把(1)和(2)式右邊的第一項移到左邊后兩邊平方:

把(7)式展開合并移項以后得到如下式子:
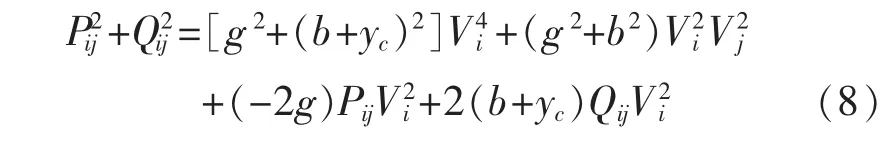
其中 Pij、Qij、Vi、Vj為量測量,并對(8)式進行如下的變量代換
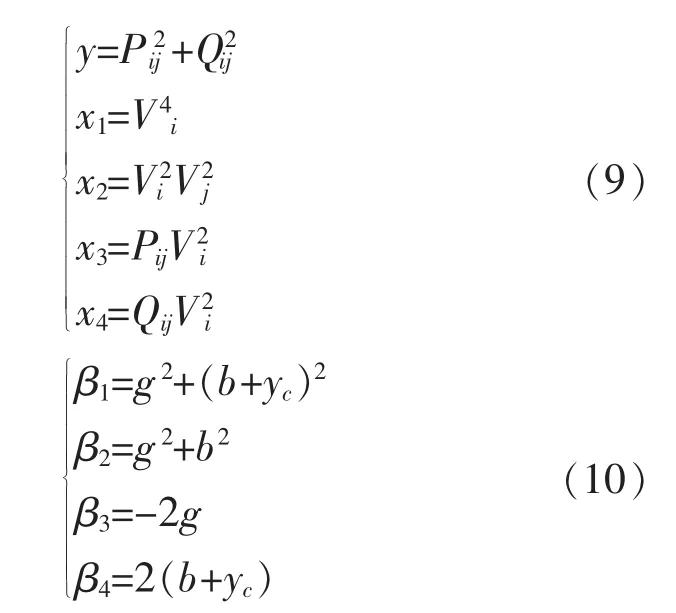
(8)式就變換成如下的等式:

其中β0=0,(11)式就是一個線性回歸方程,把上面聚類分析所得到的各個類的數據代入(9),由(2)式就可以求得各個類所對應的 β1、β2、β3、β4。 在(10)式中,有三個變量,四個等式,因此可用最小二乘法求取參數g、b、yc的估計值。
3.3 變壓器參數的回歸方程
變壓器支路的潮流方程如下
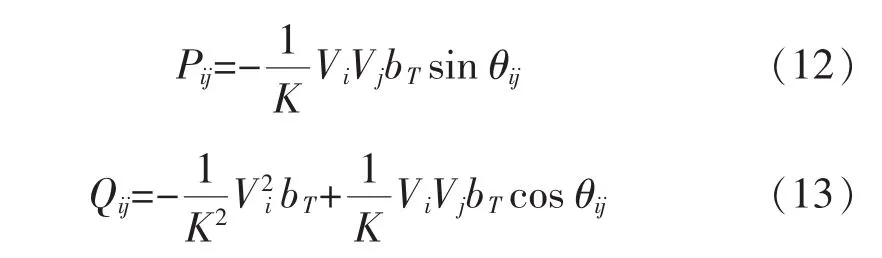
式中:K為變壓器非標準變比;j為標準側,變比為1;i為非標準側,變比為K;bT為變壓器標準側(j側)的電納。
求取參數K、bT的方法和求取線路參數的方法一樣,其中
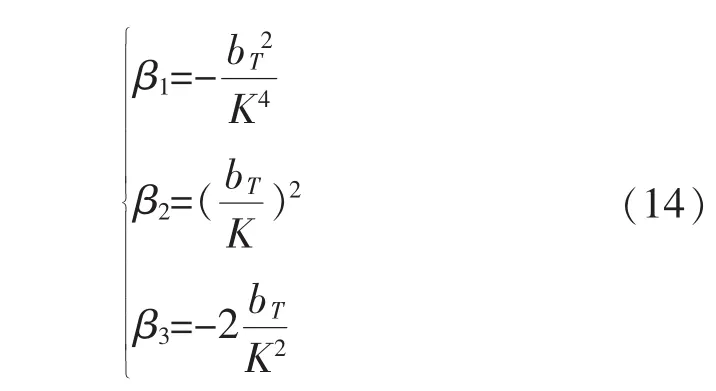
同樣在求得 β1、β2、β3以后,用最小二乘法就可以得到變壓器參數K、bT的估計值,求得K以后還要計算出K最接近的分接頭的變比。
4 討論
雖然基于劃分聚類分析的結果是全局最優的,但此劃分是根據量測量來劃分的,而文章所要求的是網絡參數值,所以最后用最小二乘法所求得的網絡參數值,可能前后兩個類之間的值相差比較大,特別是輸電線路的電阻值。在這種情況下,我們對前后兩個類之間所求得的值設定一個閥值,如果前后兩個類之間的參數值超出此閥值,就重新進行聚類的劃分,以保證前后兩個類之間的參數差值小于給定的閥值。
各個類的參數值計算都是采用離線計算,這就增加了此方法的實用性,可用于任何規模的電力網絡,不用考慮有些算法要實時計算時速率問題。
在計算得到網絡的各個參數值以后,最后還要對此方法進行驗證。驗證所用的數據可以從數據庫中提取三分之一左右。但不用每次計算時都要驗證,可采取隔幾天或者運行環境變化較大時才重新驗證。
對于每次狀態估計所用的網絡參數值,通過所采集的數據來搜索所對應類的網絡參數實際值。但如整個網絡的拓樸沒有發生變化,而且線路的負荷水平變化也不大時,可以考慮得用前一次所得的參數值作為本次狀態估計用的值,這樣可以節省搜索的時間。因每條線路與變壓器都是單獨并列計算的,如變壓器分接頭發生動作時,而其它不變時,只搜索發生動作變壓器的類。
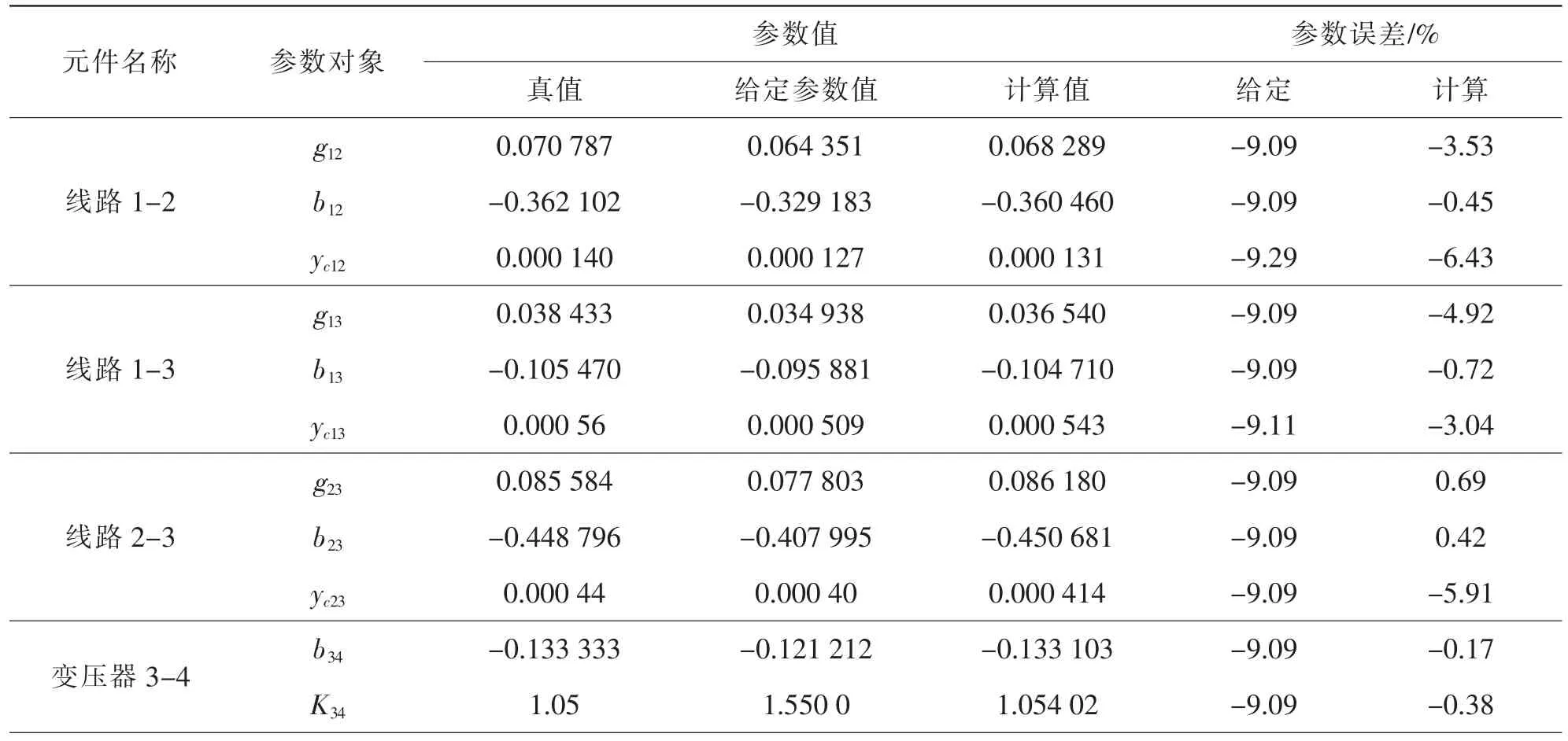
表1 30個樣本參數計算結果
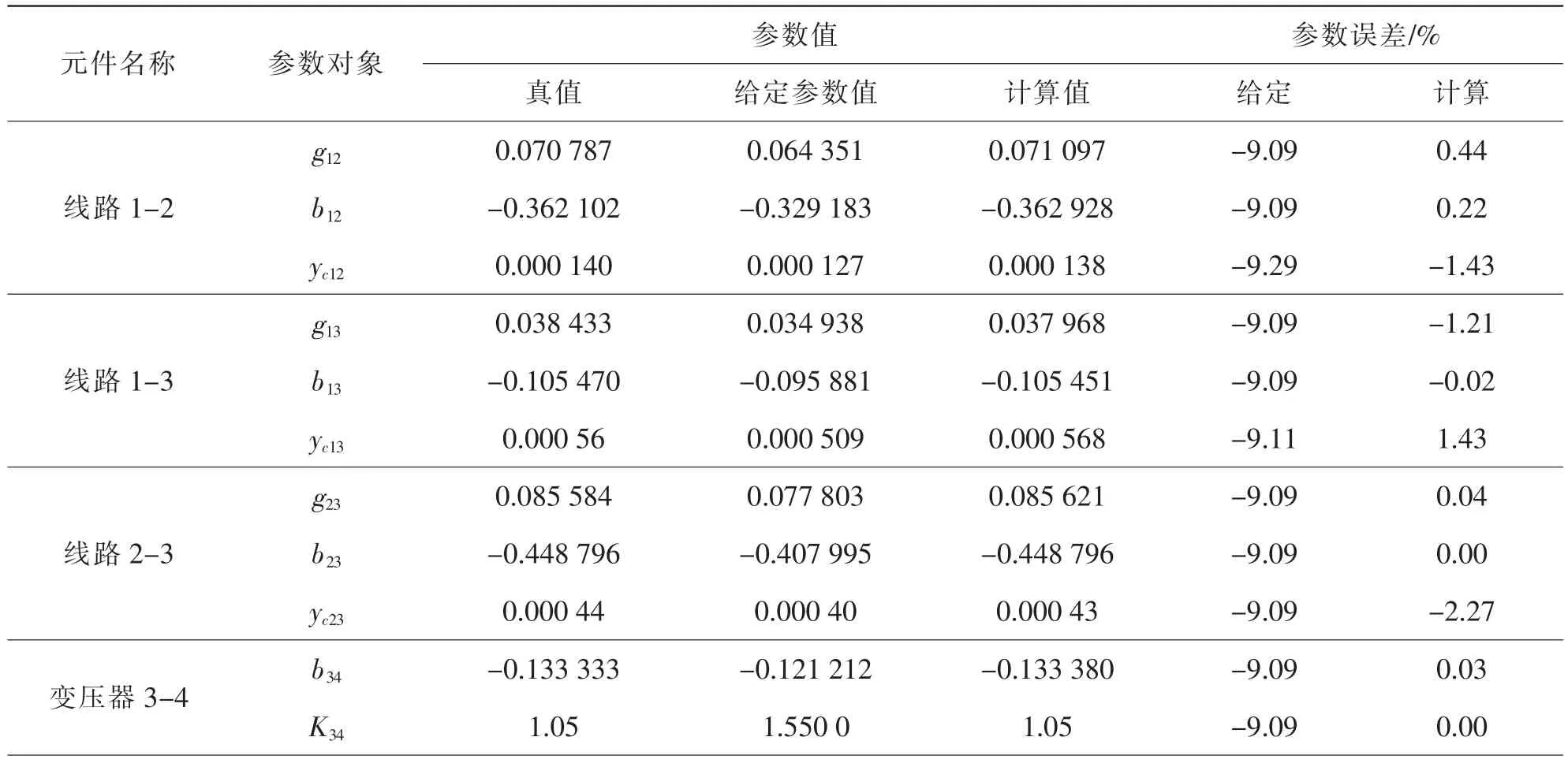
表2 100個樣本參數計算結果
5 算例分析
采用文獻[9]中的四節點系統來驗證此方法。因系統缺少實際運行所要采集的數據,所以所用的量測值也是在文獻已經計算的結果基礎上加一正態分布的隨機誤差來產生,從而不考慮其它一些如周圍環境,天氣溫度等因素。文章分別列舉了30與100次量測樣本的全部計算值(表1、表2)。同時為了對比說明本方法的效果,與文獻中用增廣矩陣所計算的參數估計值作了比較。
從表1、表2可以看出,當樣本數量達到一定數量以后,參數計算值與真值相差不多了。圖1說明了參數b13隨著樣本數量的逐漸增加,相對誤差越來越小,其他參數也具有同樣的性質。
通過對此系統的成功測試,將此方法應用于一個實際系統中,來求取此系統在各個情況下的參數值,以供狀態估計及其它能量管理系統(EMS)中的程序所用。并且通過計算出系統的實際值,為用戶創造了較大的經濟效益。直接采用數據庫中所給的數據,在有些情況下運行人員認為線路的輸電能力沒有達到負荷極限,但其實已經達到了負荷極限,從而使得線路長時間處于過負荷運行,可能造成線路的斷裂;或者認為線路的輸電能力已經達到了極限,其實還沒有,特別是在缺電的情況下,從而也造成一些不必要的損失。
由于方法采用離線的計算,所以在計算速度方面沒有太大的要求。為了能夠求得在各種情況下網絡參數的真值,數據容量為一年各個時間段的數據。通過對所用的數據進行聚類分析,得到各個類,溫度和負荷水平是分類的主要判據。把各個類中的數據代入公式,發現計算出來的參數值前后相差有時較大。表3列出了計算所得的各個參數值與所給定的參數值之間的統計表。
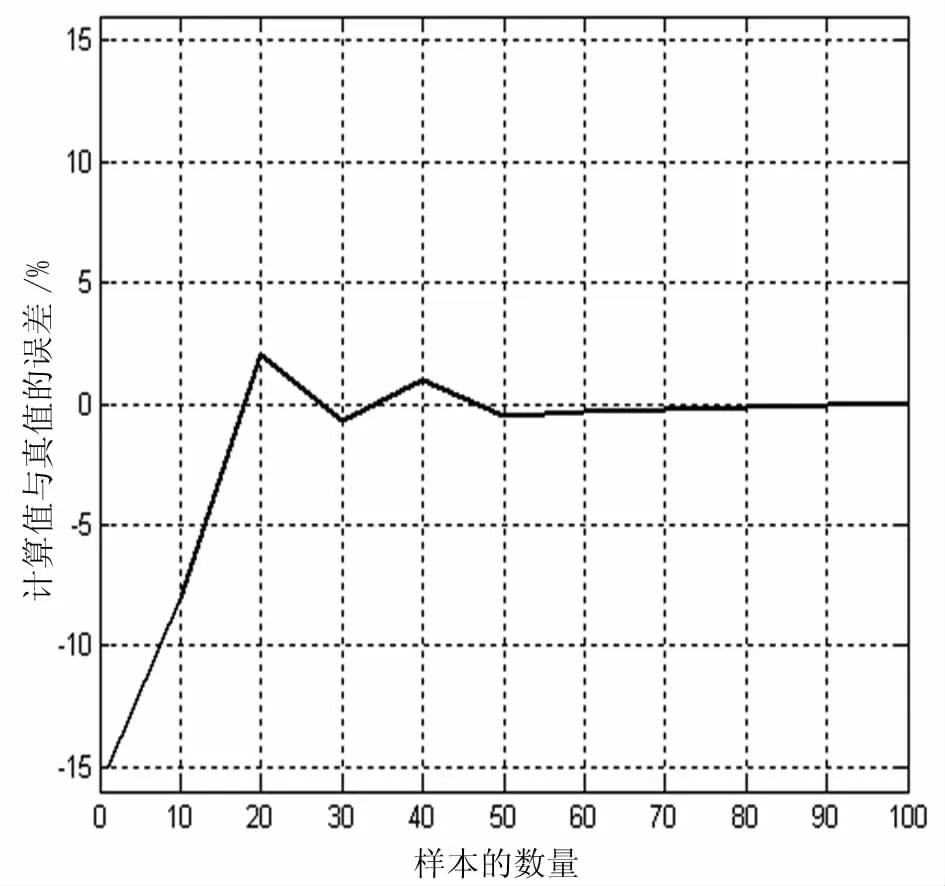
圖1 不同樣本容量和計算誤差之間的關系
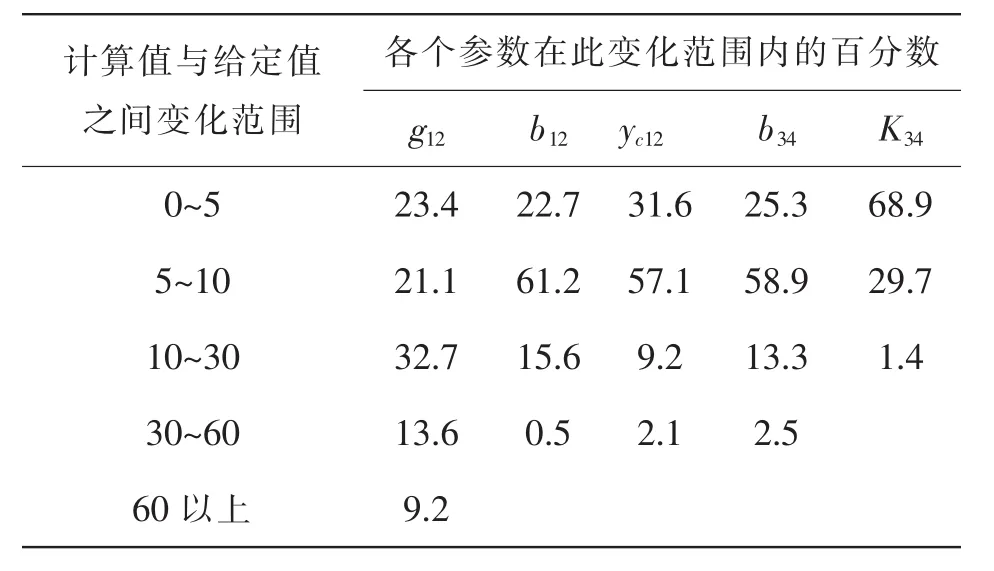
表3 計算值同給定值的關系
6 結論
正確的網絡參數值對于電力系統分析越來越重要,但如果參數值錯誤的話,會對狀態估計、優化運行,安全分析等的結果產生較大的影響,特別是實施電力市場以后,對參數值正確性的要求越來越高。
針對得要到一個正確反映網絡在各種情況下的參數值比較困難的問題,文章提出了一種基于對大量歷史數據進行挖掘計算參數值的方法,能過聚類分析,把歷史數據分成各個類。因每個類都有大量的歷史數據來反映網絡情況,所以最后的網絡參數值能夠代表各種情況下的正確值。
最后的兩個算例表明所提出的基于數據挖掘技術的網絡參數估計正確性比較高,實用性比較強,可靠性比較高。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
通信電源技術(2018年3期)2018-06-26 06:33:30
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
信息通信技術(2015年6期)2015-12-26 01:16:46
電測與儀表(2014年12期)2014-04-04 12:10:16
河南科技(2014年23期)2014-02-27 14:18:43
