一種RFID閱讀器的列表式讀取方式研究
2012-07-19 05:49:10郭雨齊錢志鴻白曦源
哈爾濱工業(yè)大學學報 2012年11期
關(guān)鍵詞:系統(tǒng)
郭雨齊,錢志鴻,白曦源,劉 淼
(1.吉林大學通信工程學院,130012 長春;2.中國科學院科技政策與管理科學研究所,100190 北京)
一種RFID閱讀器的列表式讀取方式研究
郭雨齊1,2,錢志鴻1,白曦源1,劉 淼1
(1.吉林大學通信工程學院,130012 長春;2.中國科學院科技政策與管理科學研究所,100190 北京)
為了提高RFID系統(tǒng)中閱讀器的標簽讀取效率,提出了一種列表式讀取方式.通過將閱讀器內(nèi)既定標簽群體唯一識別號(UID)事先存儲于閱讀器地址列表中,按照一定規(guī)則對地址列表逐個鎖定式搜索,完成標簽識別.針對閱讀器尋呼次數(shù)、傳輸時延以及系統(tǒng)效率等三個重要性能指標,對本算法進行仿真,仿真實驗結(jié)果表明列表式讀取方式較傳統(tǒng)的二進制搜索算法性能更具優(yōu)越性.
RFID;列表式讀取方式;二次讀取模式;循環(huán)讀取模式
射頻識別技術(shù)(Radio Frequency Identification,RFID)是一種非接觸式的自動識別技術(shù),在生產(chǎn)、生活、衛(wèi)生醫(yī)療等各個領(lǐng)域發(fā)揮著越來越重要的作用.與傳統(tǒng)條形碼技術(shù)相比較,RFID技術(shù)具有使用壽命長、存儲容量大、讀取速度快、環(huán)境適應(yīng)能力強、抗干擾能力強、安全性高等優(yōu)點[1],而其最突出的特點即為多標簽識別.但閱讀器周圍可有多個標簽存在,當兩個或兩個以上標簽同時向閱讀器發(fā)送數(shù)據(jù)時將會產(chǎn)生數(shù)據(jù)沖突,防碰撞算法應(yīng)運而生.目前解決標簽碰撞的算法主要有基于二進制樹搜索的確定性防碰撞算法和基于ALOHA的不確定性防碰撞算法[2].閱讀器都需根據(jù)相應(yīng)碰撞規(guī)則對其識別范圍內(nèi)的標簽逐個讀取,當標簽數(shù)量增大時,該兩種算法都會產(chǎn)生明顯的系統(tǒng)開銷及時延[3-4].傳統(tǒng)的防碰撞思想采取標簽主動方式,即符合系統(tǒng)規(guī)范的標簽一進入閱讀器的工作區(qū)域就自動向閱讀器發(fā)送其自身ID,此時若多個標簽同時向閱讀器發(fā)送數(shù)據(jù),將會產(chǎn)生沖突,閱讀器需對碰撞標簽數(shù)據(jù)進行防碰撞操作.但是閱讀器只能依據(jù)算法中相應(yīng)的運算規(guī)則來決定讀取標簽的先后順序,并且防碰撞算法本身的復雜性也在很大程度上增加了系統(tǒng)開銷[5].針對防碰撞算法的不足,本文提出了列表式讀取方式,這是一種新的RFID閱讀器讀取方式,與傳統(tǒng)防碰撞算法不同之處在于列表式讀取方式跳過了防碰撞過程,識別標簽之前閱讀器存儲待讀標簽的地址信息,依照地址列表讀取標簽,讀取的主動權(quán)在于閱讀器.
1 列表式讀取方式
1.1 列表式讀取方式指令原理
讀取操作前,閱讀器內(nèi)部存儲器存儲所有標簽的唯一識別號(UID),形成待讀標簽地址列表.讀取時閱讀器按照地址列表順序?qū)⑺R別標簽的UID插入到REQUEST命令中發(fā)送出去,標簽在接收到閱讀器發(fā)送的REQUEST指令后,提取出命令中的UID信息與其自身UID信息進行比較,若異或運算結(jié)果為零則確定該標簽為閱讀器的目標標簽,標簽響應(yīng);否則,標簽對閱讀器命令不予理會.
1.2 列表式讀取方式的兩種讀取模式
當閱讀器對標簽進行讀取操作時,閱讀器列表式讀取方式采用兩種模式:二次讀取模式和循環(huán)讀取模式,也可通過將兩種模式混合使用形成嵌套讀取模式.
1)二次讀取模式.若閱讀器存儲器內(nèi)部標簽地址列表中待讀標簽數(shù)量很大,識別標簽運用的算法需盡量減少識別時間.二次讀取模式巧妙避免了需反復讀取同一標簽所產(chǎn)生的時延,當?shù)刂妨斜碇械膫€別標簽暫時未能被成功讀取時,閱讀器將在內(nèi)存中建立1個子地址列表,將漏讀的標簽地址存放于其中.
當閱讀器完成對地址列表中的所有標簽一輪查詢后,將進行子地址列表的讀取,讀取操作模式如上所述.若此時仍不能成功讀取子地址列表內(nèi)全部標簽信息,則建立下一層子地址列表,重復上述過程逐層讀取.
2)循環(huán)讀取模式.對于循環(huán)讀取模式,如果標簽地址列表中出現(xiàn)個別標簽不能被正確識別,閱讀器將不再按照地址列表順序繼續(xù)向下讀取,而是對未成功識別標簽反復讀取直至成功識別,重復此操作至地址列表清空.
3)嵌套讀取模式.嵌套讀取模式是將循環(huán)讀取模式嵌入到二次讀取模式中,即對于二次讀取模式下形成的子地址列表,閱讀器采用多地址循環(huán)讀取模式對其進行識別.當閱讀器對地址列表中所有標簽地址完成一次讀取后,將未識別的地址提取出來建立子地址列表,對子地址列表閱讀器將從首地址到末地址采取循環(huán)讀取模式進行讀取,標簽成功識別后,將其地址從子地址列表中刪除,反復操作直至子地址列表清空.
2 算法分析
為了證明列表式讀取方式性能的優(yōu)越性,本文采用Matlab仿真軟件,針對閱讀器尋呼次數(shù)、傳輸時延及系統(tǒng)效率3個重要性能指標對本算法進行仿真分析,并與工作方式機理基本一致的二進制搜索算法做性能比較.
2.1 閱讀器尋呼次數(shù)分析
對于閱讀器列表式讀取方式,當需要讀取地址列表中單個標簽時,閱讀器只需發(fā)送1個插入該標簽 UID的 REQUEST(UID)命令即可,待識別標簽響應(yīng)并附帶自身的UID,其他標簽不作響應(yīng).
1)列表式讀取方式.在閱讀器列表式讀取方式中,閱讀器發(fā)送的尋呼命令次數(shù)與標簽數(shù)目無關(guān),尋呼次數(shù)TlN(N)應(yīng)始終為1,即

所以當閱讀器需要對自身工作區(qū)域內(nèi)所有N個標簽進行讀取時需要的尋呼命令次數(shù)TlN(N)為 N,即

該式為閱讀器讀取范圍內(nèi)標簽數(shù)目有限,且在時間允許范圍內(nèi)可對全部標簽成功識別的情況.當標簽數(shù)目很大,如對全國范圍內(nèi)的二代身份證進行識別,即標簽數(shù)目可達十幾億時,與本結(jié)論并不沖突.
2)二進制搜索算法.對于二進制搜索算法,閱讀器要識別其讀寫范圍內(nèi)N個標簽中某一個標簽所需發(fā)送的尋呼次數(shù)[6]為
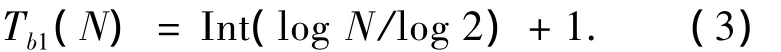
閱讀器對該標簽成功識別后,將會發(fā)送1個去活命令,標簽接收到命令后進入等待狀態(tài),對于閱讀器以后發(fā)來的命令不予響應(yīng),即該標簽將不會參與下一輪的防碰撞操作.當閱讀器需要對工作區(qū)域內(nèi)的全部N個標簽進行識別時,閱讀器所要發(fā)送的尋呼次數(shù)應(yīng)為
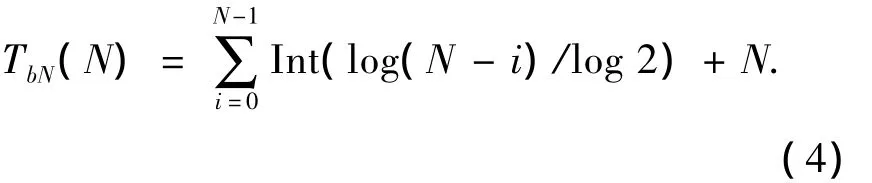
3)閱讀器尋呼命令數(shù)仿真分析.當閱讀器需要對其讀取范圍內(nèi)全部N個標簽中單個標簽進行讀取時,所需發(fā)送的尋呼命令次數(shù)仿真分析如圖1所示.
從圖可知,二進制搜索算法的閱讀器尋呼次數(shù)曲線呈正增長趨勢,閱讀器發(fā)送的尋呼命令次數(shù)會隨著標簽數(shù)量的增長而增長.然而閱讀器列表式讀取方式的尋呼次數(shù)恒定為1,不因標簽數(shù)變化而變化.
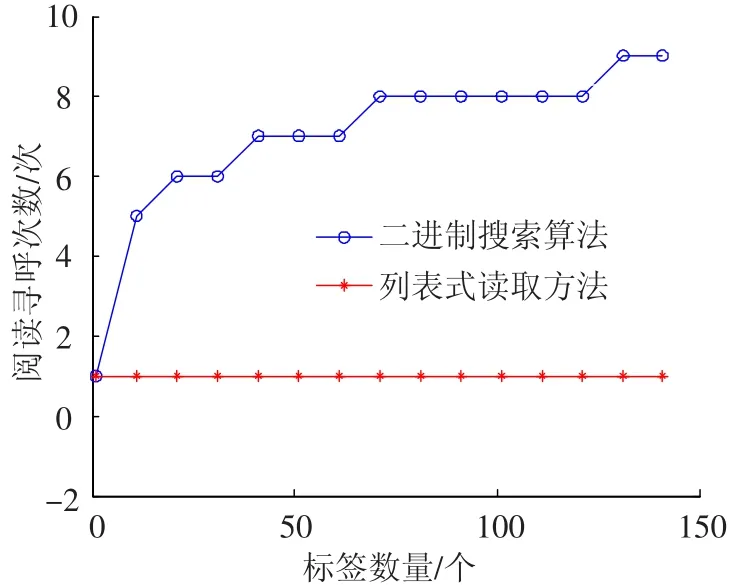
圖1 識別單個標簽時仿真結(jié)果對比
當閱讀器需要識別其工作范圍內(nèi)全部N個標簽時,所需發(fā)送的尋呼命令次數(shù)仿真分析如圖2所示.
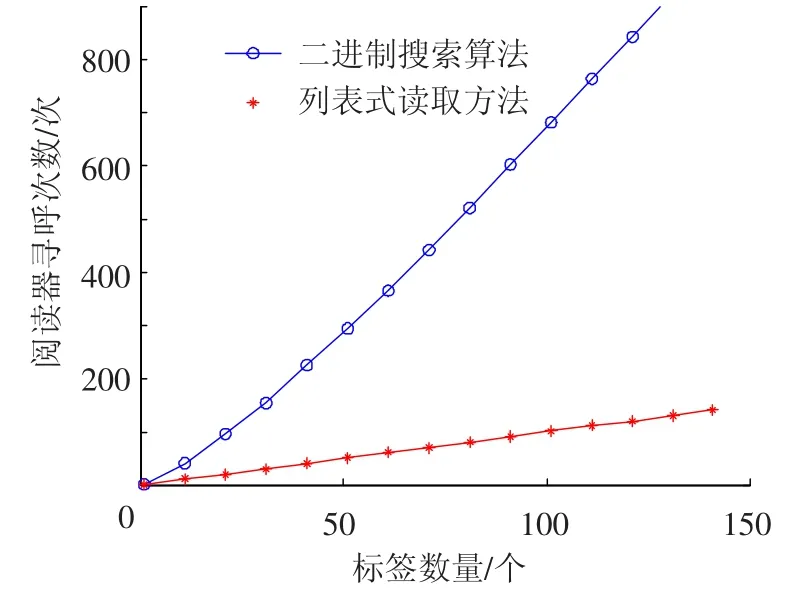
圖2 識別全部標簽時仿真結(jié)果對比
由圖可知,對于兩種算法雖然閱讀器發(fā)送尋呼命令次數(shù)都會隨著標簽數(shù)量增長呈現(xiàn)增長趨勢,但二進制搜索算法的增長趨勢更加顯著,因此列表式讀取方式優(yōu)越性更為明顯.
2.2 系統(tǒng)傳輸時延分析
對于閱讀器而言,其命令數(shù)據(jù)傳輸時間要遠大于相關(guān)命令處理時間,因此,將命令數(shù)據(jù)傳輸時間[7]作為分析RFID系統(tǒng)傳輸時延的主要因素.因系統(tǒng)數(shù)據(jù)傳輸速率恒定,所以傳輸時延取決于閱讀器發(fā)出尋呼的次數(shù)和每次發(fā)送尋呼的UID傳輸數(shù)據(jù)長度(以比特為單位).
對于兩種算法,閱讀器與標簽間的請求命令和應(yīng)答命令的數(shù)據(jù)幀首尾都要有1個5個比特位長度的空閑,分別命名為幀頭與幀尾.而且,閱讀器接收到標簽回傳UID的環(huán)節(jié)中,處理數(shù)據(jù)校驗位要花掉1個比特時間.而當目標標簽返回響應(yīng)時,閱讀器記錄其唯一識別號信息還需要2個比特時間.成功識別該標簽后會發(fā)送1個帶有該標簽UID的去活命令,使其進入等待狀態(tài).
若閱讀器工作范圍內(nèi)的標簽數(shù)量為N,標簽的唯一識別號(UID)長度為k比特.可知,閱讀器與標簽一次通信所要消耗的比特時間L0為
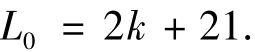
對列表式讀取方式而言,當閱讀器需要讀取其工作區(qū)域內(nèi)的單個標簽時,由式(1)可知,閱讀器發(fā)送尋呼命令次數(shù)為1,即系統(tǒng)內(nèi)閱讀器與標簽需發(fā)送的比特長度Ll1(N)為Ll1(N)=2k+23.
當需讀取全部N個標簽時,由式(2)可得閱讀器需要發(fā)出N次尋呼命令,即需要發(fā)送的比特長度LlN(N)為
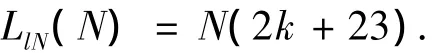
而二進制搜索算法中[8],當閱讀器需要對其工作區(qū)域內(nèi)某1個標簽進行讀取時,由式(3)可得,閱讀器發(fā)送的尋呼命令數(shù)為Tb1(N),則所要發(fā)送的比特長度Lb1(N)為
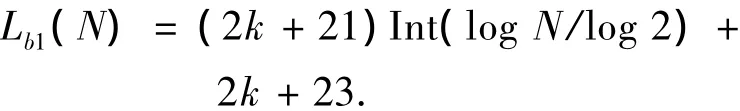
當需識別所有標簽時,由式(4)可知,閱讀器發(fā)送的尋呼命令數(shù)為TbN(N),則所要發(fā)送的比特長度LbN(N)為
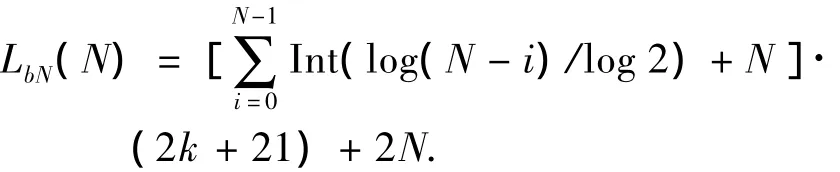
若所傳的比特位已知,系統(tǒng)的比特位數(shù)除以碼元速率即為傳輸時延.設(shè)閱讀器的碼元速率為v=50 kbit/s,標簽UID的長度k為64 bit,標簽數(shù)為N.
1)閱讀器列表式讀取方式.若閱讀器讀取范圍內(nèi)存在N個標簽,列表式讀取方式讀取單個標簽進行識別時的系統(tǒng)傳輸時延τl1為
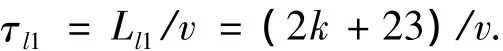
對全部標簽進行讀取時的系統(tǒng)傳輸時延τlN為
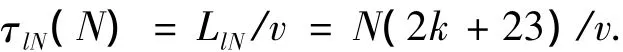
2)二進制搜索算法.對于二進制搜索算法,當閱讀器需要對其閱讀范圍內(nèi)N個標簽中的某一個標簽進行讀取時,系統(tǒng)傳輸時延τb1為
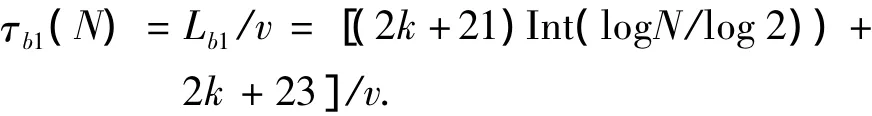
對于二進制搜索算法,當閱讀器需要對其讀取范圍內(nèi)全部N個標簽進行識別時,系統(tǒng)傳輸時延 τbN為
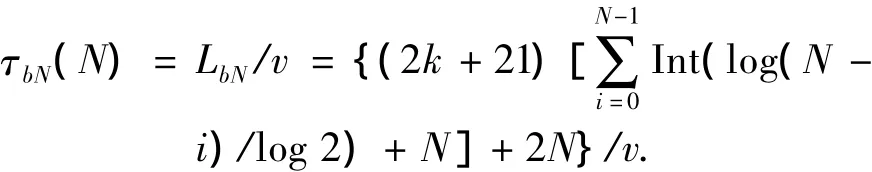
3)系統(tǒng)傳輸時延仿真分析.假設(shè)閱讀器讀取范圍內(nèi)存在N個標簽,讀取單個標簽時兩種算法的系統(tǒng)傳輸時延的仿真分析比較如圖3所示.
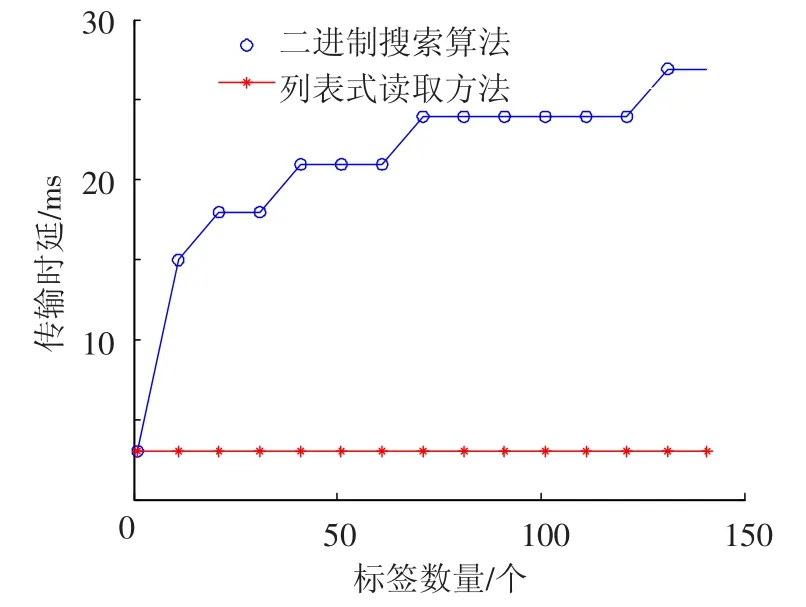
圖3 識別單個標簽仿真結(jié)果對比
從圖3可以看出,提出的讀取方式系統(tǒng)傳輸時延為定值3 ms,即識別單個標簽的傳輸時延與閱讀器工作范圍內(nèi)標簽數(shù)量無關(guān).而二進制搜索算法的傳輸時延隨著橫軸標簽數(shù)量的增長而增長,在標簽數(shù)目為0~10的范圍內(nèi),增長幅度最為明顯,以后呈平緩增長趨勢.
對讀取范圍內(nèi)全部N個標簽進行識別時,兩種算法的系統(tǒng)傳輸時延仿真分析比較如圖4所示.
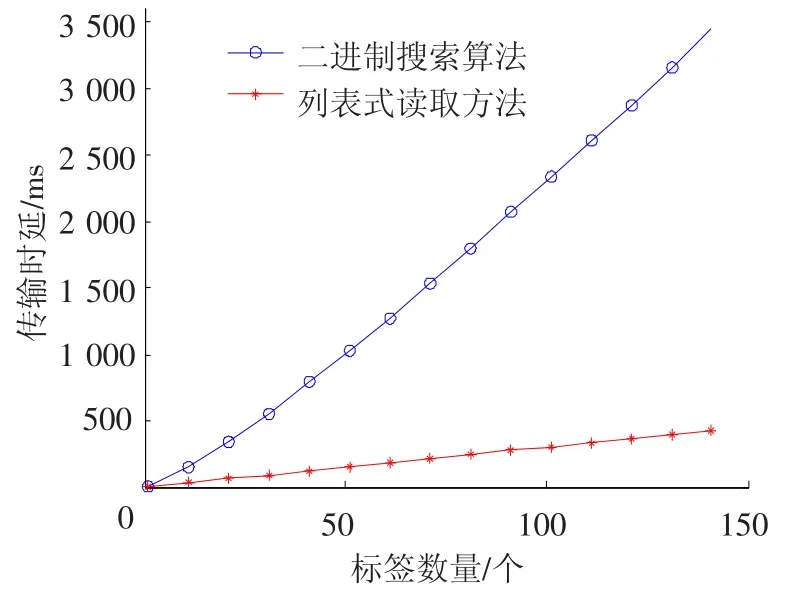
圖4 識別全部N個標簽仿真結(jié)果對比
由圖4可知,無論二進制搜索算法還是閱讀器列表式讀取方式,其系統(tǒng)傳輸時延都會隨著閱讀器讀取范圍內(nèi)標簽數(shù)量的增加而有所增加,但顯然列表式讀取方式較二進制搜索算法上升幅度遲緩,在標簽數(shù)目為150個時,列表式讀取方式系統(tǒng)傳輸時延為500 ms,而二進制搜索算法達到2 000 ms,時延為列表式的4倍.可見標簽數(shù)量增大時,閱讀器列表式讀取方式優(yōu)勢性更為明顯.
2.3 系統(tǒng)效率分析
由閱讀器發(fā)送尋呼命令次數(shù)的仿真圖可知,閱讀器發(fā)送尋呼命令的次數(shù)會隨其讀取范圍內(nèi)標簽數(shù)量的增長而增長,即閱讀器成功識別標簽效率下降.列表式讀取方式與二進制搜索算法的系統(tǒng)效率[9]分析比較如下.
1)列表式讀取方式.對于列表式讀取方式,閱讀器要對其讀取范圍內(nèi)N個標簽中的某一個進行識別時,系統(tǒng)效率El1可以表示為
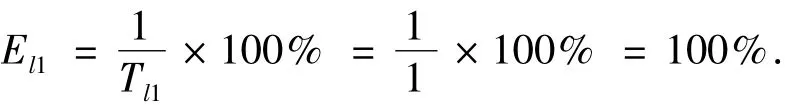
當需識別全部N個標簽時,列表式讀取方式的系統(tǒng)效率ElN為
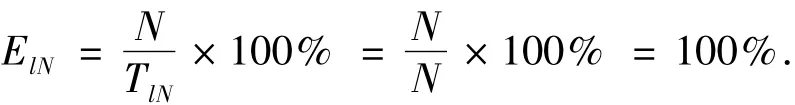
2)二進制搜索算法.若閱讀器讀取范圍內(nèi)存在N個標簽,當需識別單個標簽時,二進制搜索算法系統(tǒng)效率Eb1可以表示為
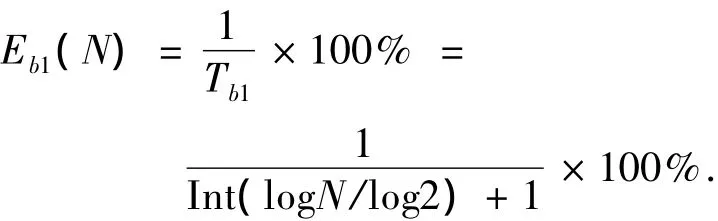
當需識別其讀取范圍內(nèi)的全部N個標簽時,二進制搜索算法的系統(tǒng)效率EbN為
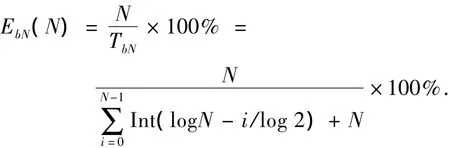
3)系統(tǒng)效率仿真分析.若閱讀器工作區(qū)域內(nèi)標簽數(shù)目為N個,當閱讀器需要對其中某一個進行讀取時,系統(tǒng)效率的仿真如圖5所示.
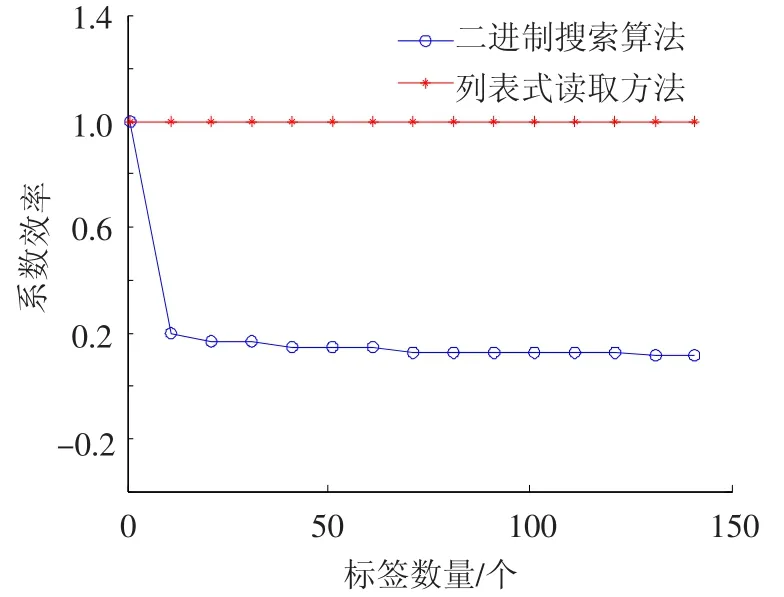
圖5 識別單個標簽仿真結(jié)果對比
由圖5可知,識別閱讀器讀取范圍內(nèi)單個標簽時二進制搜索算法的系統(tǒng)效率呈現(xiàn)整體下降趨勢.標簽數(shù)量在0~10范圍內(nèi),系統(tǒng)效率直線下降,隨著標簽數(shù)量逐漸增多,下降幅度將有所緩解,但仍一直呈下降趨勢.而對于列表式讀取方式,系統(tǒng)效率始終為100%.
當閱讀器需要識別所有標簽時,系統(tǒng)的效率仿真分析如圖6所示.從圖可知,二進制搜索算法的系統(tǒng)效率與標簽數(shù)目成負相關(guān),即標簽數(shù)量上升,系統(tǒng)效率隨之下降,而列表式讀取方式的系統(tǒng)效率恒定為100%.因此,系統(tǒng)效率方面列表式讀取方式優(yōu)于二進制搜索算法.
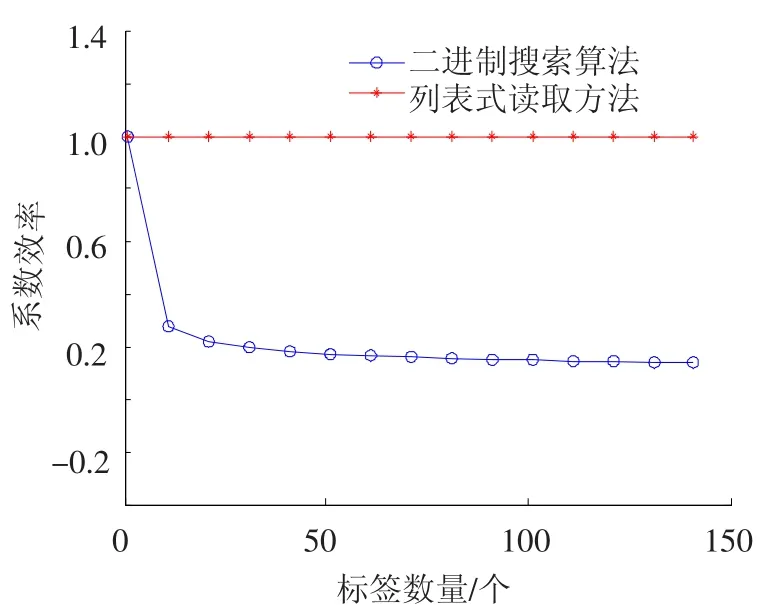
圖6 識別全部N個標簽仿真結(jié)果對比
3 結(jié)論
列表式讀取方式省去了傳統(tǒng)防碰撞算法中復雜的防碰撞過程,利用二次讀取方式、循環(huán)讀取方式或嵌套讀取方式對標簽進行識別,通過仿真實驗分析得出本算法在閱讀器尋呼次數(shù)、系統(tǒng)傳輸時延以及系統(tǒng)效率3個重要的性能指標上都明顯優(yōu)于二進制搜索算法.尤其是在圖書館開放式書架管理以及倉儲管理等需查詢某一特定標簽的特殊應(yīng)用環(huán)境下凸顯其靈活便捷性[10-11].但對于閱讀器列表式讀取方式,一方面因其跳過防碰撞算法,不能靈活應(yīng)對閱讀器讀取范圍內(nèi)多個標簽同時與閱讀器通信的狀況;另一方面因其識別主動權(quán)不在標簽,而在閱讀器,只有地址信息存放于閱讀器內(nèi)部存儲器的標簽才能被識別,所以相應(yīng)的其應(yīng)用范圍也將受到一定的限制.因此列表式讀取方式并不能完全地取代傳統(tǒng)的讀取方式,在實際中應(yīng)該將兩種不同思想的讀取方式結(jié)合起來,使應(yīng)用更加靈活高效.
[1]FINKENZELLER K.RFID-handbook fundamentals and applications in contactless smart cards and identification[M].2nd Ed.New York:John Wiley & Sons Ltd,2003:7-8.
[2]KLAIR K D,CHIN K W,RAAD R.A survey and tutorial of RFID anti-collision protocols[J].IEEE Communications Surveys & Tutorials,2010,12(3):400 -421.
[3]王雪,錢志鴻,胡正超,等.基于二叉樹的RFID防碰撞算法的研究[J].通信學報,2010,31(6):49 -57.
[4]李萌,錢志鴻,張旭,等.基于時隙預測的RFID防碰撞 ALOHA 算法[J].通信學報,2011,32(12):43 -50.
[5]JIA Xiaolin,F(xiàn)ENG Quanyuan,MA Chengzhen.An efficient anti-collision protocol for RFID tag identification[J].IEEE Communications Letters,2010,14(11):1014-1016.
[6]胡正超.基于二進制樹的RFID防碰撞算法的研究[D].長春:吉林大學,2009:26 -27.
[7]LAI Y C,HSIAO L Y.General binary tree protocol for coping with the capture effect in RFID tag identification[J].IEEE Communications Letters,2010,14(3):208-210.
[8]THOMAS F.L,GAIA M,CHIRARA P.Anti-collision protocols for single-reader RFID system temporal analysis and optimization[J].IEEE Transactions on mobile computing,2010,10(2):267 -279.
[9]KIM J H,LEE W,YU J,MYUNG J.Effect of localized optimal clustering for reader anti-collision in RFID networks:fairness aspects to the readers[C]//Proceedings of the 14th International Conference on Computer Communications and Networks(IEEE ICCCN 2005).San Diego:IEEE Comsoc,2005:497 -502.
[10]Wang L.RFID-based technology intelligence in libraries[J].International Journal of Technology Intelligence and Planning,2010,6(1):32-41.
[11]LIU Weining,ZHENG Linjiang,SUN Dihua.A data processing model for improving RFID application reliability in logistics tracking system[C]//2010 International Conference on Logistics Systems and Intelligent Management(ICLSIM 2010).Harbin:STD,2010:1643-1647.
UID-listed reading mode of RFID reader
GUO Yu-qi1,2,QIAN Zhi-hong1,BAI Xi-yuan1,LIU Miao1
(1.School of Communication Engineering,Jilin University,130025 Changchun,China;2.Institute of Policy and Management,Chinese Academy of Sciences,100190 Beijing,China)
In order to improve the RFID system read efficiency,a reading mode named UID-Listed Reading Mode is proposed.With putting the UID of tags to be identified into the address list of a RFID reader,which was formed in advance,the address list would be tracked and searched until all of the tags were identified one by one,according to certain rules.To prove the strong points of the UID-Listed reading mode proposed,query times,transmission delay and system efficiency were simulated,and then contrasted with the Binary Search Algorithm,which had similar operation principle with proposed reading mode.The consequences of simulation indicate that the UID-Listed reading mode turns out to be better than the classical binary search algorithm.
RFID;UID-Listed reading mode;second read mode;circulation read mode
TN92
A
0367-6234(2012)11-0096-05
2012-04-18.
國家自然科學基金(60940010,61071073)和教育部高等學校博士學科點專項科研基金(20090061110043)資助課題.
郭雨齊(1979—),女,博士研究生;
錢志鴻(1957—),男,教授,博士生導師.
錢志鴻,dr.qzh@163.com.
(編輯 張 宏)
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
制造技術(shù)與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
知識經(jīng)濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(shù)(2016年6期)2016-04-20 06:21:32
