基于BP網絡的木刻藏文經書文字識別研究*
2012-07-25 03:19:00趙棟材
微處理機 2012年5期
關鍵詞:特征提取
趙棟材
(西藏大學藏文信息技術研究中心,拉薩850000)
1 引言
藏文自公元7世紀創制以來,迄今已有一千三百多年的歷史,目前仍是記錄書寫藏語的文字系統。無論作為傳承藏民族傳統文化的主要工具,還是作為我國藏族地區傳播現代科技知識的主要工具,有其獨特的人類文化價值,在藏族地區所發揮的巨大作用是不可估量的。千年來記載了各類歷史記載、佛教經典編譯,以及各種民間神話傳說等。浩如煙海的藏文文獻內容廣泛,是我國除漢文之外,歷史最悠久、文獻最豐富的語言文化遺產。正是由于這樣的原因,歷史文化遺產的數字化,迫在眉睫。通過手工錄入去保留這些文化遺產幾乎是不可能的,而文字識別技術正是最好的選擇。
大量的藏文經典主要以裝幀的形式,一般文獻呈現長條體,橫向是書的寬度,縱向是書的高度,書頁以活頁方式構成,如圖1所示。誦經閱讀時,縱向往上翻起。
木刻藏文經書是雕刻的文字,在不同模板上樣式相同,書寫規則與標準藏文字完全相同,書寫方向是從左向右,采用縱向疊加的輔音加上元音進行組合。但是木刻藏文經書大多為人工篆刻,人為因素干擾嚴重(見圖2),再通過特殊的藏紙印刷,加上油墨的干擾,導致木刻藏文經書文中出現字符間粘連、斷裂、遮擋現象,為識別帶來極大的困難。
由于木刻藏文經書的特殊性,僅依靠字符切分、特征提取等方法已不能滿足對木刻藏文經書的識別需要。通過研究發現,增加基于BP網絡的訓練方法,有助于提高木刻藏文經書的文字識別正確率。

圖1 木刻經文樣式

圖2 干擾嚴重的經文字
2 BP網絡算法描述
2.1 木刻經文文字識別的系統流程
木刻經文文字識別的整體設計流程為如圖3所示。

圖3 木刻藏文經書文字識別流程
整體識別中主要算法有二值化、去除噪音、切分、歸一化、特征提取、人工神經網絡算法。特征提取與人工神經網絡訓練相同,區別在于:
(1)當識別結果與用戶實際選擇的結果不同時,調用人工神經網絡算法,進行訓練,收斂結果,然后修正保存的數據,以實現下步識別再遇到這個經文單元時,能夠正確識別,提高識別率。
(2)識別處理采用一種加權誤差均衡距離,定義兩個特征矢量X,Y的距離函數為:

σ是方差,ε為10,α為8。序列中距離f最小的結果為最后識別出的結果字符。
2.2 BP網絡訓練
木刻經文樣式、種類繁多,在進行特征提取過程中會對同一個字在不同印版的經書中提取不同的樣本,這樣每個經文字就對應了不同的經文樣本,如圖4所示兩個一樣的經文字,但其樣式不同。

圖4 2個木刻藏文樣本字
在采用彈性網格特征提取后,每個樣本形成了308維的特征數據,共計308×2=616維數據,如果全部保存并參與運算,則會導致整體識別的運算效率大大降低,也不能真正應用到實際識別過程中。這樣就需要一套訓練算法對這些數據進行訓練,整合所有樣本,獲取多種樣本共性的數據,更好的提高系統的魯棒性。本項目通過研究各種參考資料,最后確定采用基于人工神經網絡的改進的BP算法對整個樣本進行訓練,以便得出魯棒性更強的、服務于識別的矢量數據。
人工神經網絡具有良好的容錯能力和自我學習能力,較傳統識別技術有一定的優勢,對于干擾復雜、識別難度大的經文識別系統,其應用會有效提高識別率和識別效率。
BP算法是神經網絡技術中的典型算法,即向前計算-誤差反向傳播算法,采用廣義的δ學習規則,是一種有導師的學習算法。其工作過程分兩個階段:
第一階段正向傳播階段,將樣本導入輸入層,計算權重,然后將信息傳到隱含層(可以多層)繼續計算輸出值和期望值,最后傳入輸出層。
第二階段反向傳播階段,將網絡的實際輸出與期望輸出相比較,如果誤差不滿足要求,將誤差向后傳播,即從輸出層到輸入層逐層求其誤差(實際上是等效誤差),然后相應地修改權值。
其算法的執行如下:
設 X1,X2,...,Xn是神經元的輸入,θi是 Xi的閥值,Wij是Xi的權系數;Yi是Xi的輸出,f是激發函數,e是誤差函數;
(1)輸入一個樣本集,并進行編碼,同時給定理想的輸出信號Ti;
(2)設定權系數Wij,對各層的權系數置一個較小的非零隨機數;
(3)計算各層的輸出;
對于任意節點j,輸出計算步驟為:

其中Uj是加權后的輸入與節點閾值的總和;θj是節點j的閾值;網絡中節點非線性的傳輸關系采用Sigmoid函數。
(4)求各層的學習誤差:

(5)誤差反向傳播,修正權值和閾值,從輸出節點開始逐步向前遞推,直到第一層,基于梯度下降法得:
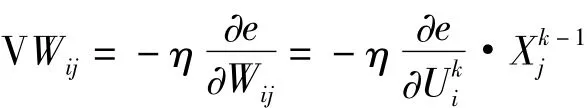
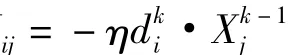
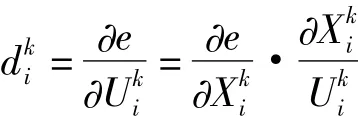

至此樣本計算完成。BP算法雖然可以很精確地實現函數的逼近和模式的分類,但是從本質上講,BP算法仍然是一種梯度算法,不可避免地存在一定問題,改變精度要求 ,將影響BP算法的計算次數,降低運算效率,不同樣本有的收斂快,有的運算量大,不同學習速率也會影響運算效率等,因此在處理過程中需要對算法進行改進。
2.2.1 隱層單元數的選擇
隱層單元數目k是應用BP算法的關鍵因素之一,k過小不能很好的收斂,過大則降低運算效率,也會產生多余特征,減低容錯率。經過試驗測試,BP算法隱層設定為兩個隱層,隱層單元數采用兩種數據處理,先取較大的k訓練,然后取較小k,比對后去掉不起作用的隱層單元,具體表達式為:

2.2.2 平滑更新權值

系統經過訓練之后,得到新的經文單元數據,數據格式為:

保存所有單元數據,用于為識別系統提供數據基礎。
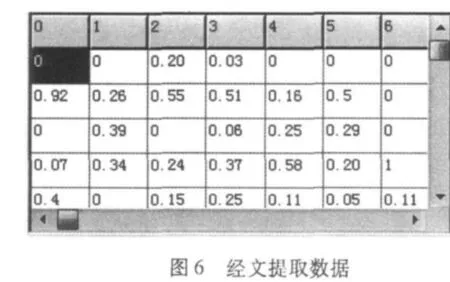
經文字的神經網絡訓練效果如圖5,其下方數據圖6為其對應藏經文字的特征提取數據中的288維網格數據。圖7為提取后與原數據進行神經網絡訓練后更新的288維網格數據。
3 實驗結果
木刻藏文經書文字識別界面如圖8所示。實驗共收集經書單個單元樣本1643個,訓練1643,通過批量樣本測試程序測試,正常干擾情況下識別率為92.45%,嚴重干擾情況下識別率71.23%。


4 結束語
在字符切分、特征提取等文字識別方法基礎上,提出基于BP網絡訓練方法的木刻藏文經書文字識別解決方案,基本實現了普通干擾情況下木刻經文識別率90%以上。當然,木刻經文由于干擾嚴重、印版斷裂、字符粘連等情況導致識別難度特別大,現有的國際國內相關產品和資料都沒有很好的方法予以解決,需要進一步的研究和試驗,以更好的提高木刻藏文經書的文字識別率。
[1] 范立南,韓曉微.圖像處理與模式識別[M].北京:科學出版社,2007.
[2] 吳佑壽,丁曉青.漢字識別-原理方法與實現[M].北京:高等教育出版社,1993.
[3] 李弼程,邵美珍,黃潔.模式識別原理與應用[M].西安:西安電子科技大學出版社,2008.
[4] 王勇,鄭輝,胡德文.圖像和視頻中的文字獲取技術[J].中國圖像圖形學報,2004,9(5):532-538.
[5] 馮宇平,戴明.一種基于角點特征的圖像拼接融合算法[J].微電子與計算機,2009,26(7):21-28.
[6] 普次仁.多種印刷字體藏文字符的特征提取方法研究[J].西藏大學學報,2008,23(1):25-28.
[7] 王維蘭.藏文基本字符識別算法研究[J].西北民族學院學報,1999,20(3):20-23.
[8] 王浩軍,趙南元,鄧鋼鐵.藏文識別的預處理[J].計算機工程,2001,27(9):93-96.
[9] 王維蘭,丁曉青,祁坤鈺.藏文識別中相似字丁的區分研究[J].中文信息學報,2002,16(4):60-65.
[10] 李永忠,王玉雷,劉真真.藏文印刷體字符識別技術研究[J].南京大學學報,2012,48(1):55-62.
[11] Ngodrup,ZHAO Dong cai.Research on wooden blocked Tibetan character segmentation based on drop penetration algorithm[C].CCPR 2010 Proceedings.IEEE Computer Society.2010:84-88.
[12] Ngodrup,ZHAO Dong cai,Putsren,Daluosanglangjie,LIU Fang,Bianbawangdui.Study on printed Tibetan character recognition[C].AICI 2010 Proceedings.IEEE Computer Society.2010:280-285.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
