Boosting算法對卵巢癌代謝組數據的應用研究*
2012-09-07 09:01:28武振宇賈慧珣
中國衛生統計 2012年6期
武振宇 賈慧珣 朱 驥△
Boosting算法對卵巢癌代謝組數據的應用研究*
武振宇1賈慧珣2朱 驥2△
目的 應用Boosting算法建立模型,對卵巢癌和非卵巢癌(卵巢囊腫和子宮肌瘤)患者的尿液代謝組數據進行分析,提取出具有生物學意義的代謝組分,為卵巢癌的早期診斷及疾病機理提供線索。方法 將決策樹與Boosting算法相結合,對患者的臨床樣品代謝組數據進行分析,并對代謝組分進行逐步篩選,得到鑒別卵巢癌患者的重要代謝組分。結果 由Boosting模型得到的排序靠前的10個差異代謝組分,能夠將卵巢癌與對照組患者進行較好的判別分類,其ROC曲線下面積達到了0.944。結論 Boosting模型可以有效地應用于卵巢癌代謝組數據,在保證較高的分類正確率的同時可以得到對分類起作用的重要的代謝組分。
代謝組學 Boosting 特征篩選
*:國家青年科學基金項目資助(81001286);“中央高校基本科研業務費專項資金”資助
1.復旦大學公共衛生學院衛生統計教研室(200032)
2.復旦大學附屬腫瘤醫院臨床資料統計室
△通訊作者:朱驥
卵巢癌是婦科常見的惡性腫瘤之一,大約有1.4%的女性會患病,其病死率很高,對婦女生命造成嚴重威脅,國內外臨床資料統計顯示其五年生存率僅25% ~30%。如果發現及時,90%的病人都能存活;若發現晚,癌細胞擴散到卵巢,存活率就低于30%。所以早期診斷治療對于卵巢癌患者提高5年生存率具有十分重要的意義。
代謝組學研究研究特點是采用高通量檢測技術,對生物體代謝情況進行整體的測量。圖1是一種代謝產物的總離子色譜圖和相應的量化表,上半部分是代謝組研究中檢測得到的代謝產物離子色譜圖,每一個峰代表某一保留時間上的一組代謝產物。下半部分是由色譜圖得到的代謝產物的量化結果。每一列代表一個觀測對象,每一行代表一個保留時間上測得的代謝產物。

圖1 代謝產物的總離子色譜圖和相應的量化表
利用代謝物(如尿液、血液)進行疾病的診斷,方法簡便、無創、患者易于接受。生物體的代謝物可能包含幾千甚至幾萬個生物特征的信息,但限于研究成本,樣本例數通常只有數十例。因此具有生物學意義的特征篩選對于高維代謝組學數據分析來說顯得尤為重要。Boosting方法作為集成算法中的一員,一直以其優異的性能吸引著廣大研究者。本研究的目的是對卵巢癌患者的代謝產物(尿液)的分析,其主要目的是篩選出能夠區分卵巢癌病人與非卵巢癌病人的生物標志物以及對樣本進行分類,通過比較正常和疾病狀態下代謝產物譜的差異,研究疾病的發生機理,為卵巢癌的臨床早期診斷、治療以及預后判斷提供重要依據和支持。
資料與方法
1.資料來源
本資料來源于2009年7月至2009年12月在哈爾濱醫科大學附屬腫瘤醫院收集37例首次發現并經病理確診為卵巢癌患者(病例組)的尿樣(10ml),同時收集患有卵巢囊腫和子宮肌瘤患者(對照組)共51例的尿樣。將所有尿樣(共88例)進行預處理后,應用高效液質聯用儀進行分析,得到23447個代謝組分。
2.研究目的和方法
(1)研究目的
①卵巢癌分類模型的建立,即采用機器學習的方法從已知的數據集中抽象出一個分類模型,使該模型能夠很好地擬合當前分類結果并能解釋其意義,對疾病的預測具有指導意義。② 對卵巢癌患者代謝產物的組分進行分析,即從患者尿液分離出的23447個代謝組分中篩選出對疾病分類起重要作用的重要組分,為卵巢癌的研究打下基礎,使模型能夠對臨床的診斷、治療及預后等實踐工作進行指導并具有解釋意義。
(2)研究方法—Boosting方法
Boosting算法〔2-3〕基于其他機器學習算法之上的用來提高算法精度和性能的方法。起初并不需要構造一個擬合精度高、預測能力好的算法,只要一個效果比隨機猜測略好的粗糙算法即可。通過不斷調用這個基算法來改變樣本分布和賦予判別模型不同的權重得以實現,最終獲得一個擬合和預測誤差都相當好的組合預測模型。
Boosting嚴格意義上不是一個具體的學習算法,它需要給定一個弱學習算法和一個訓練序列。初始化時給每個訓練例賦權重為1/N。然后用選定的弱學習算法進行第一次訓練,給訓練失敗的訓練例賦以更大的權重,也就意味著在后面的學習中集中對此類訓練例進行學習。經過T次訓練后得到一個訓練序列h1,h2,…,hT,其中hi有權重,預測效果好的預測函數權重較大,反之較小。最終的預測函數H采用有權重的投票方式產生。
Adaboost算法〔3-4〕
假定具有N個帶分類標簽的樣品序列<(x1,y1),…,(xn,yN)>,其中xi∈X,yi∈{-1,+1},N個樣品點權重的分布為D,基礎弱學習算法記為Weaklearner,迭代次數為T。
① 初始化:D1(i)=1/N,其中i=1,2,…,N,對t=1,…,T循環執行:
②用分布Dt訓練基礎學習器;
③得到弱分類器ht;
④計算ht訓練誤差εt,
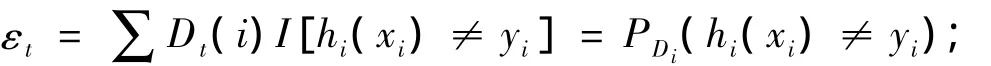

⑥重新計算樣品的權重:
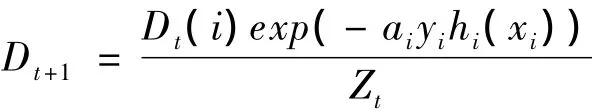
其中Zt=∑Dt(i)exp(-atyihi(xi))是歸一化因子(Dt+1為分布);
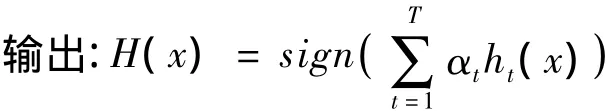
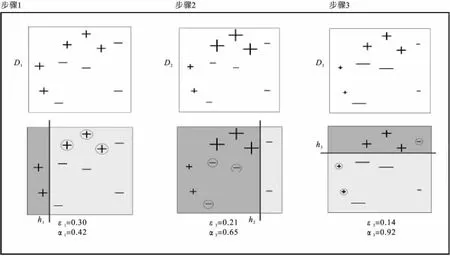
圖2 使用簡單的線性模型作為弱分類器的Boosting算法運算過程
Boosting算法進行變量重要性評價原理〔5-6〕
由于決策樹具有能預測變量的重要性的優點,可以對分類起作用的變量進行重要性評價,因此考慮使用決策樹作為基函數。對于Boosting算法,在給定訓練樣本和損失函數L(y,H)的前提下,其目的是找到一個決策樹模型的線性組合,使得該組合可以對損失函數進行極小化優化,即H(X)=argH(x)minEy,xL(y,H(x)),優化的過程一般沿著目標函數的梯度最速下降方向。最終得到的H(X)實際上是多個決策樹的線性組合。單個決策樹的變量重要性評分為由節點到分裂后的節點間誤差平方和的減少量,推廣到多個決策樹的問題上,即可以把每顆樹中該變量的重要性評分求均值。
模擬試驗
按代謝組數據的特點構造類似的數據,考察Boosting算法與決策樹結合后的判別分類模型對此類數據變量重要性度量的效果,設定5個對分類有作用的差異變量X1,X2,X3,X4,X5,兩組樣本含量設為n1=n2=30,兩類真實的區分度用ROC曲線下面積θ衡量,分別設置為θ=0.85,0.95,0.99。根據類間區分度來確定差異變量的均數,為簡單起見,方差均設為==1,其中X1與X2兩個變量的相關系數設為ρ=0.5。加入1000個無差異的正態變量作為干擾,產生混合樣本。應用Boosting方法構建的模型對變量重要性進行度量。重復上述步驟500次,表1給出的是預先設置的差異變量的頻數分布情況。結果顯示,θ=0.85在時獲得的結果不夠理想,而在兩種較高的區分度下,正確地將差異變量篩選到前10位的百分率分別達到了98.6%甚至于100.0%,結果令人滿意。

表1 設定的5個差異變量在變量重要性評價分析中的頻數分布
實例分析
病例入選標準,納入病例應為無代謝疾病(糖尿病、高血脂、甲亢、甲減等)的卵巢癌、良性卵巢囊腫和無癌癥及卵巢疾病的對照女性。
由于在Windows操作系統下,使用R語言構建BTS對變量的個數有一定的限制,因此首先應用單變量分析方法(SAM)做預處理后,然后再用BTS模型進行分析。經過SAM方法分析后,選取SAM得分排在前2000的代謝組分進行分析,應用Boosting組合模型對經過預處理的卵巢癌代謝組數據進行了分析,利用無放回的隨機抽樣方法,將樣本分成兩部分,其中2/3為訓練樣本,1/3為測試樣本,按此方法隨機組成1000個訓練樣本和1000個測試樣本,建立組合分類器,最后綜合評價分類效果。評價采用靈敏度(Se)、特異度(Sp)、和ROC曲線下面積(AUC)三種指標,其中AUC值為主要評價指標。
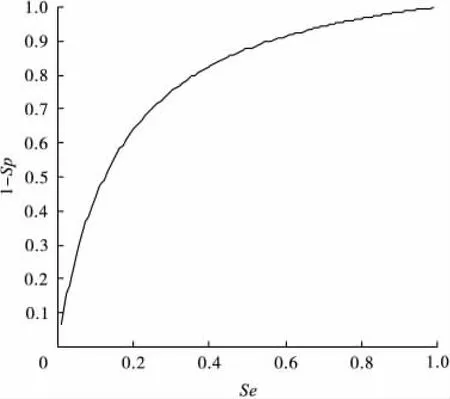
圖3 在保留了2000個代謝組分的情況下Boosting模型對卵巢癌數據分類的ROC曲線
預測效果的ROC曲線見圖3。可以看出,在保留了2000個代謝組分的情況下,對外部測試集獲得了較為理想的判別分類結果,其靈敏度(Se)和特異度(Sp)分別為0.733和0.724,而ROC曲線下面積(AUC)則達到0.801。判別分類效果不甚理想,可能是由于噪聲變量(或對分類無作用的代謝組分)太多引起的。
應用Boosting模型進行分類的同時,篩選出排序靠前的對分類起作用的變量。篩選標準是將1000次分類中篩選進來的變量出現的概率≥80% 的變量提取出來,共提出30個變量。將篩選出的這30個變量對卵巢癌數據的外部驗證集進行1000次分類判別,得到的分類結果(AUC值)的頻數圖如下,由圖4可以看出分類能力顯著提高。可見這30個變量中一定存在對分類起作用的信息。
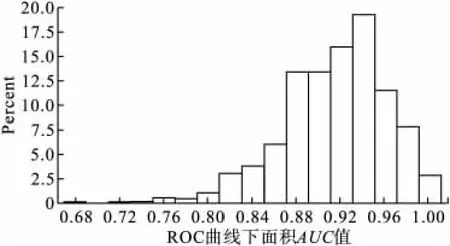
圖4 應用篩選出的30個變量進行1000次分類得到的AUC值的頻數圖
為了篩選出最佳對分類起作用的變量,進行了進一步的變量提取工作。將30個變量按照變量重要性評分逐漸遞減,并用分類結果作驗證。從表2和圖5可以看出,當截取到10個變量的時候,分類判別能力達到理想的效果。可見這10個代謝組分可能是區分卵巢癌患者與對照組患者的重要標志物。
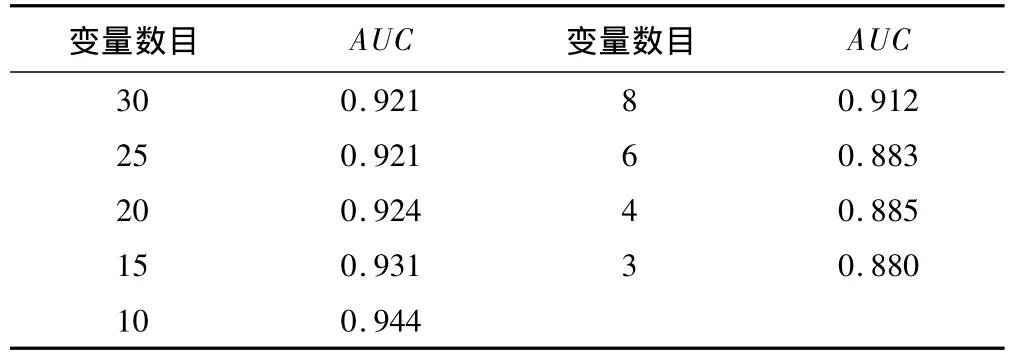
表2 隨著變量數目的減少分類結果AUC值的變化
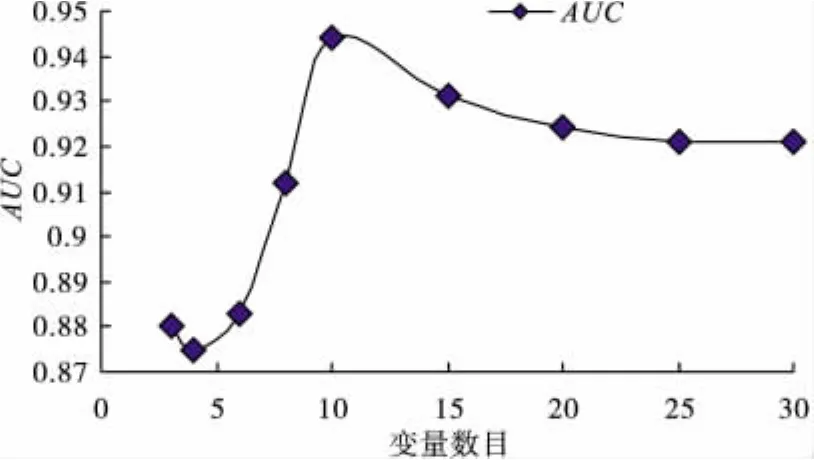
圖5 隨著變量數目的減少分類結果AUC值的變化
討 論
1.卵巢癌的早期診斷與早期治療是改善預后的關鍵。在疾病早期腫瘤僅局限于卵巢時難以診斷,所以尋找有實用價值的診斷方法成了近年來的研究熱點。代謝組學的研究近年來蓬勃發展,如果我們僅通過患者的代謝物(血液或尿液)即能夠做出正確的診斷,不僅給臨床的診斷工作帶來極大的便利,也為患者減輕做病理所帶來的痛苦。所以運用代謝物來鑒別腫瘤的良惡性將是一件很有意義的工作。
2.本研究采用分類決策樹作為基礎算法,應用Boosting方法建模,在模擬數據和實際數據的應用中均取得了理想的結果。在對卵巢癌代謝組實際數據的分析中,該模型能夠在分類的同時給出差異表達代謝組分的變量重要性評分,并由進一步的分類驗證可以看出,該模型預測的準確性也能夠令人滿意,為臨床上對卵巢癌患者的診斷和治療提供了一定的依據。
3.此方法篩選出的10個代謝組分,通過HMDB數據庫的查詢,多數可能為磷脂類的物質,但由于大量同分異構體的存在,為了確保究竟是何種代謝組分,應該將物質打碎進一步做二級質譜以確定是何種代謝組分,這部分試驗尚在進行之中。
1.Jerome F,Trevor H,Robert T.Additive logistic regression:a statistical view of Boosting.The annals of Statistics,2000,28:337-407.
2.Schwenk H,Bengio Y.Boosting networks and neural computation,2000,12(8):1869-1887.
3.Servane Gey,Jean-Michel Poggi.Boosting and instability for regression trees.Computational Statistics& Data Analysis,2006,50:533-550.
4.Freund Y,Schapire R.Decision theoretic generalization of on-line learning and an application to boosting.Journal of Computer and System Science,1995,55(1):119-139.
5.李霞,何麗云,劉超.Boosting算法及其在中醫亞健康數據分類中的應用.中國衛生統計,2008,25(2):158-161.
6.Dao Li-li,Hu ke-yun,Lu Yu-chang.Improved stumps combined by boosting for text categorization.Journal of Software,2002,13(8):1361-1367.
The Study of Boosting Algorithm Applied to Ovarian Cancer Metabonomics Data
Wu Zhenyu,Jia Huixun,Zhu Ji.Department of Biostatistics,Fudan University(200032),Shanghai
ObjectiveBoosting model was built to analyze the metabonomics data from ovarian cancer and ovarian cyst patients urine.Some biological metabolites were also extracted from the data,which would provide some clues to the early diagnosis.MethodsBoosting and decision tress were combined to analyze the metabnomics data and the important metabolites were achieved according to their importance scores.ResultsThe top ten metabolites were extracted and the area under ROC curve was 0.944,which provided a better classification results than the original dataset.ConclusionBoosting could be effectively applied to the classification of ovarian cancer metabnomics data,important features could also be extracted at the same time.
Metabnomics data;Boosting;Feature selection
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
