基于改進ReliefF算法的特征加權FCM
2012-10-13 07:59:20張鴻
艦船電子對抗 2012年1期
張 鴻
(船舶重工集團公司723所,揚州225001)
0 引 言
聚類分析是多元統計分析的方法之一,是統計模式識別中非監督模式分類的一個重要分支[1]。分類模式識別常采用基于歐式距離的最近鄰分類器來實現。在一般歐式距離中,樣本在個體特征上的差異對總距離的貢獻是相同的,對樣本分類所起的作用也是相同的。但是對象間的距離表示對象的相近程度,而相似不僅依賴于對象間的相似程度,還依賴于對象內的性質,即對象中每個變量的重要性是不同的,對樣本分類所起的作用也有所不同。原則上,對每個模式知道的信息越多,聚類的效果應該越好。然而在實踐中并非如此。有些特征可能是噪音數據,這些噪音數據對聚類結果沒有貢獻甚至可能降低聚類效果。
模糊C均值聚類(FCM)分析就是一種有效的聚類分析方法,在非監督模式識別、模糊控制等領域有著極為廣泛的應用[2]。原始的FCM假定待分析樣本的各維特征對分類的貢獻均勻,不考慮各個特征對分類的不同作用。
利用特征權值對分類器的距離計算進行加權,對樣本分類越有利的特征權值越大,樣本在該特征維上即使出現微小的差異也會因較大的加權對歐式距離的計算產生較大的影響。因此,采用特征加權的歐式距離進行最近鄰分類可以取得更好的分類效果[3]。所以本文比較了基于不同的特征權值計算方法的加權FCM的聚類效果,并最終提出了一種改進的ReliefF算法加權FCM聚類算法。
1 特征權重計算方法
1.1 基于信息增益的特征權重計算方法
信息增益(IG)特征權重計算方法是最簡單的特征評價方法[3]。
令W為樣本實例的第n個特征,M為該樣本實例的類變量。在觀察到W前后,類變量M的墑為:
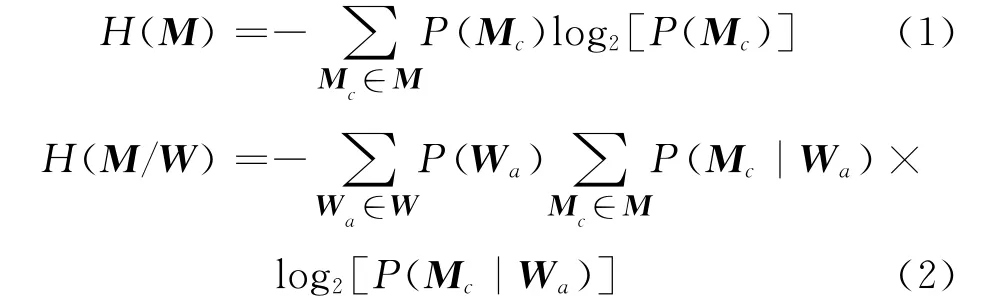
式中:a=1,2,…,n;c=1,2,…,C,C 為數據集所分成的類別。
在觀察到W 后,類變量M的墑的減少量反映了特征W 所承載的關于W 的信息量,即為信息增益[3]:
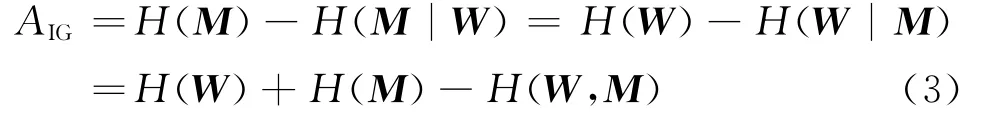
1.2 原始ReliefF算法
對于任意一個樣本實例xi,基本的ReliefF算法可以表示為:
首先找出k個與xi同類的最近鄰的樣本實例集合H。設diff_hit(A,x,H)是n×1矩陣,表示對象xi與H內各對象在樣本屬性特征A上的差異量化表示:
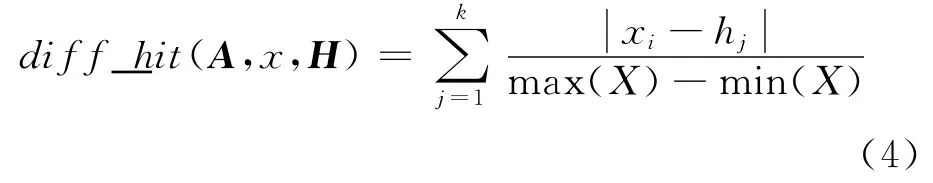
式中:j=1,2,3,…,k。
其次找出與xi不同類的樣本實例中k個最近鄰的樣本集合 M(c)。設 diff_miss[A,xi,M(c)]是n×1矩陣,為xi在與M(c)內各對象在樣本屬性特征A上的差異量化表示:
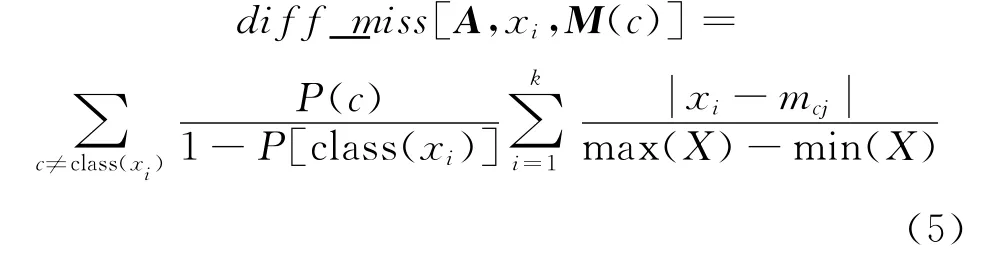
設輸入:訓練樣本集X,最近鄰樣本個數k,重復累積次數m;輸出:樣本特征權重值矩陣W。由上述描述可以得到基本的ReliefF算法基本步驟如下:
(1)設置所有的屬性權重值;(2)for i:=1to m;
(3)隨機選擇一個樣本實例;
(4)找到與樣本同類的k個最近鄰樣本集合H;
(5)for each class c≠class(xi);
(6)找到與樣本xi不同類的k個最近鄰樣本集合M(c);
(7)for A:=1to n;
(8)W[A]:= W[A]-diff_hit(A,xi,H)/(k·m)+diff_miss[A,xi,M(c)]/(k·m);
(9)end。
在上述偽代碼中,H表示與對象同類的k個最近鄰的對象集合,M(c)表示與對象不同類的k個最近鄰對象集合,diff_hit(A,xi,H)為對象xi與H內各對象在特征A 上的差異量化表示,diff_miss(A,xi,M)表示對象xi與M(c)內各對象在特征A上的差異量化表示,上述兩公式的計算方式見公式(4)、(5)。
1.3 改進的ReliefF算法
要對樣本屬性權重值做出最有效的評估,必須使選取的累積樣本盡量均勻地覆蓋于每個樣本類別的整個樣本數據集中。如果ReliefF算法不能確保選取的樣本均勻地覆蓋于每個樣本類別的整個樣本數據集中,必然會造成下列的一些問題:
首先基本ReliefF算法重復了m次從訓練樣本集中隨機挑選樣本xi的操作,m一般要遠小于樣本總數量。如果原始數據集的樣本集中在某幾個類別中,按照基本的ReliefF算法隨機選擇樣本數,必然會造成以下的缺點:屬性權重值向樣本數量多的類別傾斜。包含樣本數較多的類別其樣本點被隨機選中的概率較大,與該類別相關的屬性權重值累積就會較高。反之,一些樣本數較少的類別由于其樣本點被選中的幾率小,即使有對分類起明顯作用的屬性權重值也會因為累積少而被掩蓋[2]。
其次由于F次迭代使用的樣本都是隨機選擇的,即使是同一組訓練樣本集,每運行一次該算法,算法隨機選中的樣本點都不可能完全相同,這樣造成的累積的屬性權重值也有波動。
由于基本的ReliefF算法存在上述缺點,通過上述算法計算出來的屬性特征權值必然存在一定的偏差,所以本文提出了改進的ReliefF算法(IReliefF)。由于基本ReliefF算法的不足之處主要體現在樣本點的選擇上,本文采取下列措施來對樣本點選擇方法進行改進:為保證每類樣本均可參與權值計算,在選擇樣本時,從每類目標樣本分別各抽取m個樣本點用于屬性特征權重值的累積。改進的樣本點選擇步驟如下:
(1)計算每一類樣本的樣本中心點Xd;
(2)計算該類中樣本點與該樣本中心點的歐式距離;
(3)根據Xd大小,把該類樣本分成f組,每組間隔歐式距離大小為 Δd,Δd= [max(Xd)-min(Xd)]/f ;
(4)在分出的F組的每一組,取中間的樣本做ReliefF分析。
結合基本的ReliefF算法和上述樣本點選擇辦法,得到了IReliefF算法的基本步驟如下:
(1)設置所有的屬性權重值;
(2)for each class,ci,i=1,2,…,T;
(3)計算該類中樣本點與該樣本中心點的歐式距離dij;
(4)根據dij大小,計算每組間隔歐式距離Δd;
(5)選擇距離組內的中間樣本xj;
(6)for each xj,j=1,2,3,…,f;
(7)找到與樣本xi同類的k個最近鄰樣本集合H;
(8)for each class c≠class(xi)do;
(9)找到與樣本xi不同類的k個最近鄰樣本集合 M(c);
(10)for A:= 1to n do,W[A]:=W[A]-diff_hit(A,xi,H)/(f·k·T)+diff_miss[A,xi,M(c)]/(f·k·T);
(11)end。
IReliefF算法可以計算樣本屬性權重值矩陣W。權重值的取值范圍在[-1,1]區間,值越高的特征對分類越有利,值為負的特征則不利于分類,并且可以得到穩定的W。
2 加權的模糊C均值聚類算法
原則上,對每個模式知道的信息越多,聚類的效果應該越好。然而在實踐中并非如此。有些特征可能是噪音數據,這些噪音數據對聚類結果沒有貢獻甚至可能降低聚類效果。參考文獻[3]提到學習屬性權值可以普遍提高聚類質量,學習屬性權值使無關屬性的影響盡量減小,甚至權值可以為零。所以本文提出用基于IG和改進的ReliefF算法來計算數據特征的權重值,提出加權的FCM(WFCM)來提高聚類質量,盡量減少噪音數據的影響。
在Dunn提出的C-MEANS距離算法的基礎上,Bezedk加以推廣[7],提出了模糊 C-均值聚類算法。FCM是一個典型的基于距離的聚類算法。該算法具有簡單、高效的特點,并能收斂于局部最優解。
FCM的目標是使價值函數J值達到最小,價值函數J的定義為:
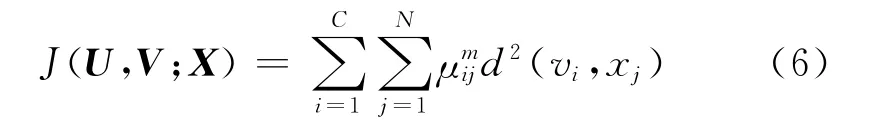
式中:m∈[1,+∞],為一個加權指數,隨著m的增大,聚類的模糊性增大;N為樣本數據集的個數;μij為第j個樣本點隸屬于第i類的概率值。
加權的歐式距離為:
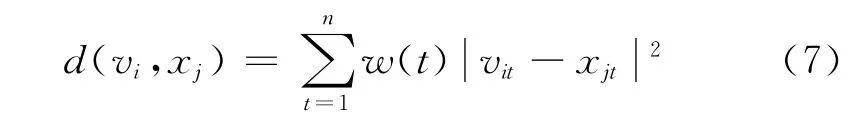
加權的FCM(WFCM)算法的目標函數為:
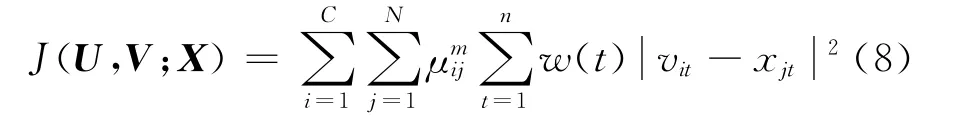
式中:w(t)為各個屬性的權重值。
WFCM算法實現基本步驟如下:
(1)設置隸屬度矩陣U 到[0,1];
(2)for i:=1to c do;
(3)找到聚類中心vi;
(4)end;
(5)for j:=1to maxiter;
(6)計算目標函數值J;
(7)如果2次循環的目標函數值差值小于設定值;
(8)break;
(9)更新隸屬度矩陣U;
(10)end。
3 實驗與分析
3.1 實驗數據
實際試驗數據選用UCI機器學習數據庫,該數據庫是由加州大學提供,從中選擇Iris、Disbetes等2個數據集,如表1所示。

表1 實驗數據集
3.2 實驗分析
本實驗從分類正確率和分類標準差指標方面,在本實驗數據集上對 ReliefF-WFCM、IReliefFWFCM、IG-WFCM以及原始FCM等4種聚類方法的性能進行比較。
ReliefF-WFCM表示使用原始的ReliefF算法進行加權的FCM,IReliefF-WFCM表示使用改進的ReliefF算法進行加權的FCM,IG-WFCM表示利用信息增益算法進行進行加權的FCM,FCM表示使用原始的模糊C均值聚類。
對于基本的ReliefF算法,本實驗選擇從訓練樣本集合中隨機抽取的用于特征累積的樣本數量m占到樣本數據集總樣本數的20%,樣本最近鄰數k=10,基本的ReliefF算法每次的結果不同,本實驗選取10次結果的平均值作為最終的平均值。對于IReliefF算法,每類抽取的樣本點數為m/c,從而保證2種算法的抽取樣本點數一致。樣本最近鄰數k=10,m為基本ReliefF算法抽取的樣本點數,c為樣本數據集的類別數。
為了使實驗結果更加可靠,本實驗采取5折交叉驗證的方式。n折交叉驗證原理:n就是要拆成幾組。對于k個子集,每個子集均做一次測試集,其余的作為訓練集。交叉驗證重復k次,每次選擇一個子集作為測試集,并將k次的平均交叉驗證正確率作為結果。
由表2、表3可得,IG-WFCM、ReliefF-WFCM和IReliefF-WFCM最終得到的誤分率指標和標準差指標都要優于原始的FCM聚類算法,從而可驗證學習屬性權值確實可以普遍提高聚類質量。
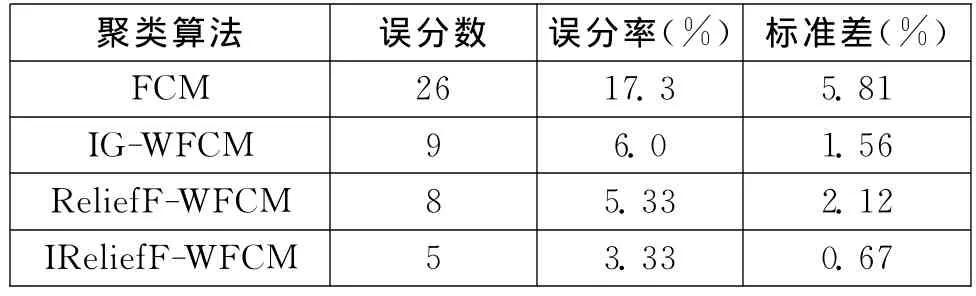
表2 數據集Iris聚類結果分析
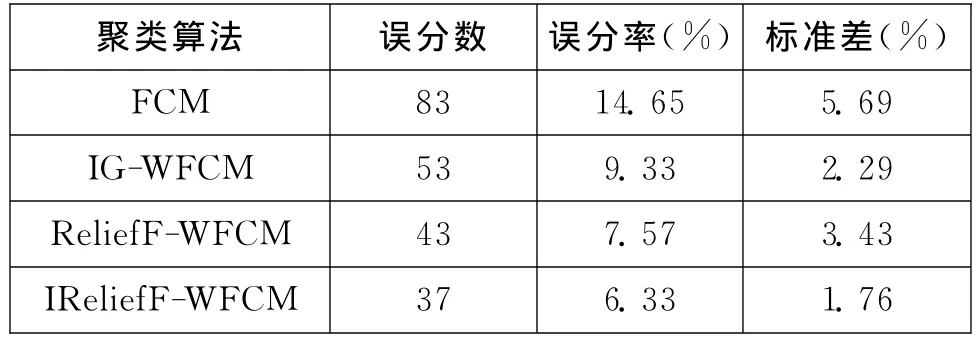
表3 數據集Disbetes聚類結果分析
通過對IG-WFCM、ReliefF-WFCM、IReliefFWFCM聚類結果的比較可以看出:在誤分率指標方面,ReliefF-WFCM、IReliefF-WFCM 聚類效果要比IG-WFCM的聚類效果好;但是在標準差指標方面,IG-WFCM的聚類效果要優于ReliefF-WFCM,仍然劣于IReliefF-WFCM的聚類效果。從而驗證了基本ReliefF算法的缺點:得到的屬性權重值不穩定,從而造成加權FCM結果不穩定。
聚類結果無論是在誤分率指標還是在標準差指標上,IReliefF-WFCM算法的誤分率和標準差都比較小,數值變化幅度也比較小,從而說明該算法的性能比較穩定。IReliefF-WFCM驗證了較高的聚類精度。基于改進ReliefF算法的加權FCM的聚類效果要優于基于基本ReliefF算法的加權FCM。
4 結束語
本文提出了一種基于改進的ReliefF算法的加權FCM(IReliefF-WFCM)聚類方法,對基本 ReliefF算法樣本選擇方法實現了改進。實驗結果表明,該算法減少了基本FCM聚類結果的誤分率和標準差,提高了FCM聚類結果的精度和穩定性,為以后該算法用于實際數據處理打下了堅實基礎。
[1]何清.模糊聚類分析理論與應用研究進展[J].模糊系統與數學,1998,12(2):89-94.
[2]李潔,高新波,焦李成.基于特征加權的模糊聚類新算法[J].電子學報,2006,34(1):89-92.
[3]高瀅,劉大有,徐益.一種特征加權的聚類算法框架[J].計算機科學,2008,35(10):152-154.
[4]Liu Chengjun.Gabor-based kernel PCA with fractional power polynomial models for face regcognition[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2004(5):572-581.
[5]Kononenko I.Estimating attributes:analysis and extensions of ReliefF[A].The Proceedings of The European Conference on Machine Learning on Machine Learning[C].Italy,Catania:Springer-Verlag New York,Inc.,1994:171-182.
[6]Kira K,Rendell L A.A practical approach to feature selection[A].The Proceedings of The Ninth International Workshop on Machine Learning[C].United Kingdom,Aberdeen,Scotland:Morgan Kaufmann Publishers Inc.,1992:249-256.
[7]Bezdek J C,Ehrlich R,Full W.FCM:the fuzzy c-means clustering algorithms[J].Computers & Geosciences,1984,10(2):191-203.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
