基于匹配性的社會消費品零售總額數據質量評估研究
2012-10-20 08:52:24李庭輝許滌龍
統計與決策 2012年8期
李庭輝 ,許滌龍
(1.湖南大學 金融與統計學院,長沙 410079;2.湖南第一師范學院 經濟管理系,長沙 410205)
1 文獻述評
統計信息在行政決策和社會政策中的制定過程中具有非常重要的作用,而決策的科學性和政策的有效性更依賴于統計信息的質量。基于此,無論是國內還是國外都對數據質量十分重視,特別是發達國家統計機構十分重視數據質量的評價和管理,建立數據質量評價機制和管理體系,以改進和提高統計數據質量。從數據質量管理角度來劃分,大體分為兩類:一類是數據質量綜合管理體系,即在統計的組織框架下,對整個統計機構的數據進行全面的質量評價。如英國、加拿大、瑞典、荷蘭等國家統計機構建立了比較健全的數據質量評價和管理機制。另一類是單項統計數據質量管理機制,即對某一具體統計項目如國民核算、消費價格指數、國際收支、住戶調查等數據的質量情況進行評價和管理。比如,美國的波斯金(BOSKIN)學術委員會,專門對美國消費物價指數(CPI)數據質量進行評估,美國商務部分析局定期評估國民經濟核算數據質量,澳大利亞統計局的國際收支和住戶調查數據質量評估體系,英國零售物價指數質量認證標準體系等等。
目前國內對數據質量評估的研究圍繞這兩個方面展開。一方面,從數據質量綜合管理體系進行研究,該類研究以國際準則的評估框架為出發點進行研究,常寧(2004)介紹了國際貨幣基金組織(IMF)的數據質量評估框架上,分析IMF數據質量評估的內容。從數據質量管理角度討論還有一些文獻從現象出發,討論數據質量及其有關的體制和方法等問題。這些文獻討論了數據質量的內涵應該包括及時性、適應性、可比性、銜接性、可解釋性、可獲得性、有效性等特征,然后論述中國數據質量控制的制度和方法等問題。同時,統計數據質量從階段性來看,確實存在一定問題,這是市場化改革的階段性所造成的,故應該.改革現行的統計管理體制,消除體制弊端,加強理論研究和法制建設,增強和優化基層統計力量,以提高我國統計數據質量(顏日初、朱喜安,2003)。另一方面,是單項數據指標的評估研究,如GDP的數據質量評估。孟連和王小魯(2000)選取價格指數、工業產品產量增長率、貨物運輸/周轉總量和工業消費電量/工業消費綜合能源量增長率等理論上與GDP(或工業增加值)增長速度應保持高度正相關的指標,研究認為1991~1997年間GDP和工業增加值增長速度與上述指標的變化趨勢出現較大偏差,因而判定GDP增長數據存在統計誤差。劉洪、黃燕(2009)以經濟理論為基礎,以GDP為數據質量評估的實證對象,利用相關影響因素構造計量模型,在既定模型下,運用異常值的檢驗方法及統計診斷原理進行了數據質量的定量評估。
許多學者對數據質量的評估無論是從定性還是定量,無論是從理論還是從實踐都提出了許多有益的見解。但從已有的研究來看,以數據質量綜合管理和政策性研究較多,以技術性評價數據質量較少;單項指標評估以GDP的評估較多,而反映宏觀經濟運行的其他指標較少(如工業增加值、社會商品零售總額等);在使用方法上以靜態方法為主,而考慮系統動態較少;在研究視角上,考慮被評估指標自身較多,考慮和其他指標之間的匹配性較少。基于此,本文擬以社會消費品零售總額為研究對象,從匹配性入手,以動態系統的視角對其數據質量進行評估。
2 社會消費品零售總額數據質量匹配因素的理論分析
社會消費品零售總額指各種經濟類型的批發零售貿易業、餐飲業、制造業和其他行業對城鄉居民和社會集團的消費品零售額和農民對非農業居民零售額的總和。它反映通過各種商品流通渠道向居民和社會集團供應生活消費品來滿足他們生活需要的情況,是研究人民生活、社會消費品購買力、貨幣流通等問題的重要指標。數據質量從其內涵來看應該包括及時性、適應性、可比性、銜接性、可解釋性、有效性等特征,這些特征的表現在很大程度上表現為其與相關指標或者自身的匹配性。基于匹配性的數據質量評估包括許多方面:從實物量到價值量核算的匯總路徑來看,社會消費品零售總額的價值量與各行各業銷售消費品的實物量之間匹配性;從流通領域的發展運行來看,社會消費品零售額與居民等收入支配能力等相關變量存在的以來關系而形成的相關匹配性等;從核算工作來看,有各個地市匯總與國家社會消費品零售總額之間的匹配性,月報、季報和年報數據合理銜接而形成的匹配性,普查和常規統計之間數據銜接而形成的匹配性。而這些匹配性有些只是方法改進的問題,所以本文從社會消費品零售總額的數據可比性、銜接性、可解釋性、有效性等核心特征出發,從匹配性角度對社會消費品零售總額進行數據質量評估。而從匹配性與社會商品零售總額的數據質量內涵來看,其間的相互理論關系體現在兩個方面。
一方面,社會消費品零售總額數據質量的可比和銜接兩個特征主要從數據質量的時間維度上進行考察①數據質量的可比性包括國際不同主體的數據可比、統計口徑可比等許多方面內容,本文著眼于從匹配性角度評估社會消費品零售總額的數據質量,故只考察時間方面的可比性。,即社會消費品零售總額數據質量在時間前后應該可比和銜接,所以時間數據符合一定的模型形式。從全社會的消費情況來看,社會消費品零售總額發生在流通領域,其必要依賴于一定的流通環節而存在,這種流通環節包括一般情況下不會發生突然改變,所以這種變化只能是漸進性變化,即社會消費品零售總額符合特定的時間序列模式,與其自身前期數據有較強的相關性。基于此可以利用時間序列模型探索其中的自相關的特點,然后對社會消費品零售總額數據質量進行時間維度的匹配性進行質量評估。
另一方面,社會消費品零售總額數據質量的可解釋和有效主要從數據的指標之間的相互關聯性角度考察其質量。從消費品的市場來看,消費依賴于各個部門對消費品需求,而這種需求依賴于各個部門的可支配收入,所以社會消費品零售總額與可支配收入等指標將會呈現較強的相關關系,這種關系反映了消費品市場的內部結構匹配的關系。盡管消費品結構在經歷各種產品市場結構和其他等一系列因素的影響以后,可能會發生改變,但其改變過程是通過前后期的動態影響的,同時,一般在相對短期或者高頻的數據范圍內,這種影響非常小,所以可以通過期間的動態關系樣本,建立動態模型,考察其擬合程度來評估社會消費品零售總額數據質量。
由以上基本理論分析可知,從社會消費品零售總額數據質量內涵入手,基于匹配性的數據質量評估應著眼兩個基本假設:一是社會消費品零售總額在時間維度上自相關特點,所以可以利用時間序列的自回歸模型對其進行數據質量評估;二是社會消費品零售總額在國民經濟流通環節與可支配等指標具有系統匹配行,所以可以利用這種系統性進行評估。而可支配收入等指標對消費品領域的影響一般會滯后,所以結合兩個基本假設及其動態結構特點,可以采用自回歸動態滯后模型對社會消費品零售總額數據質量進行評估。
3 基于匹配性的社會消費品零售總額數據質量評估理論構建
3.1 數據及其特征的說明
對社會消費品零售總額進行數據質量評估建模,首先需要選取相關的數據用于模型訓練。根據前述理論分析及其基本假設,社會消費品零售總額的數據質量評估涉及到可支配收入和社會消費品零售總額兩個指標,其中社會消費品零售總額為被評估的對象,可支配收入是核心匹配指標,而可支配收入有不同的指標,根據數據的可獲取性原則,本文選取城鎮家庭當季人均可支配收入。
確定匹配指標以后,需要確定研究指標頻率和時間。根據公布的數據資料,本文選取的數據頻率為2002年第一季度至2011年第二季度共37個樣本數據。評估數據質量與數據頻率有非常大的關系,從公布的數據頻率來看,有月度、季度和年度不同頻率的數據。數據頻率越高,反映消費環節運行情況的靈敏度越高,其質量也更為關鍵;同時,高頻率數據也是低頻率數據獲取的基礎,基于此,按照數據的可得性本文選取社會消費品零售總額季度數據進行數據質量評估。數據評估空間維度限制在全國范圍內。
理論模型特別是時間序列模型的建立都是基于數據的基本特征之上的,所以,先有必要對數據的基本特征進行考察。將當季的社會消費品零售總額和當季城鎮居民可支配收入數據繪制成曲線圖如圖1、2所示。
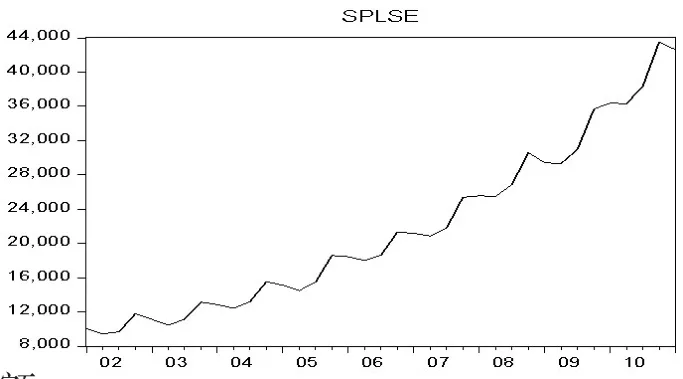
圖1 2002年一季度至2011年一季度社會消費品零售總額時間序列圖

圖2 2002年一季度至2011年一季度城鎮居民人均可支配收入時間序列圖
由圖1和圖2可以看出,兩個時間序列圖均具有明顯的季節效應,在比較X11、移動平均季節乘法、移動平均季節加法各種方法以后,發現利用移動平均季節乘法剔除季節效應的效果最好,故采用該方法剔除季節效應,在實驗過程中,得到的各個季度的季節指數如表1所示。由表1可以看出,社會消費品零售總額在每年的第第四季度最高,每年的第二季度最低;而城鎮居民家庭人均可支配收入在每年第一季度最高,每年第二季度月最低。在從其中內部看,季節效應的高點兩指標均比較顯著,但低點顯著性不夠,這充分反映出兩個指標在中國的春節前后的季節效應。進一步考察,可以發現兩個季節效應大小的改變呈現大致相同的特征,這為消費對收入滯后效應表現。
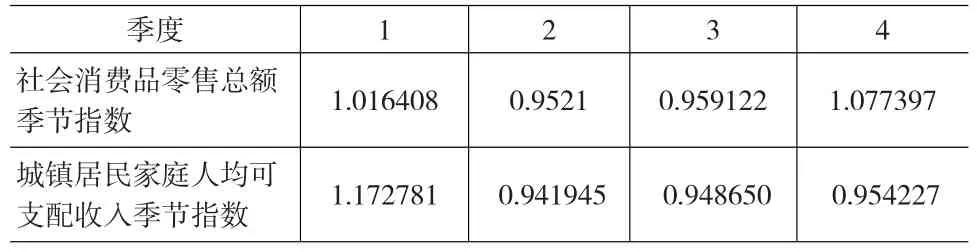
表1 各季度的季節指數表
3.2 基本理論模型的設定
由上述相關分析可知,社會消費品零售總額和城鎮居民家庭人均可支配收入都具有季節效應,所以在進行匹配性建模中,首先剔除季節因素以后在利用其中的長期趨勢進行建模分析。而從社會消費品零售總額的影響匹配因素來看,核心的匹配因素為基于序列本身特征和與城鎮居民家庭人均可支配收入關聯性特征。基于時間序列特征匹配可以利用自回歸建模進行模型刻畫,而關聯性特征可以用變量間的回歸進行模型刻畫,而可支配收入與對社會消費品零售總額影響的滯后效應。基于以上分析,利用自回歸滯后模型對社會消費品零售總額進行評估較為合適。
(P,Q)階自回歸分布滯后模型的基本表達式為:

其中,y為剔除季節因素以后的社會消費品零售總額,x為剔除季節因素以后的城鎮居民家庭人均可支配收入。P和Q階數在模型擬合過程中根據最小信息量等模型選擇原則進行確定。
該動態計量經濟模型建立過程中,通常從一個結構比較復雜的模型開始,經過對參數的線性或者非線性條件約束,去掉不顯著的一些變量,最終得到一個具有良好性質的表達簡練模型,用于刻畫其中的匹配性關系,進而對社會消費品零售額進行數據質量評估。
4 基于匹配性的社會消費品零售總額數據質量評估的實證分析
按照從一般到簡練的原則進行數據實驗,最終發現社會消費品零售總額自回歸階數為1階時最為顯著,城鎮居民家庭人均可支配收入的滯后階數是0階顯著影響,進而對模型進行參數估計,得到的相關結果如表2所示。

表2 自回歸分布滯后模型參數估計結果表
從表2可以看出,模型估計的總體效果較好,各個參數均通過了顯著性檢驗,可以利用該模型對社會消費品零售總額進行數據質量評估。對社會消費品零售總額數據是否可疑,還需要給定判斷標準,在此構造社會消費品零售總額相對誤差系數指標作為判斷標準。相對誤差系數δt用來測量第t期實際觀測到的社會消費品零售總額數據與社會消費品零售總額估計數據的相對誤差,如果相對誤差超過某一標準時,則可認為該期社會消費品零售總額的數據質量可疑。其中相對誤差系數δt的計算公式為:如果第t期的社會消費品零售總額統計數據相對誤差系數的絕對值滿足則認為該期社會消費品零售總額估計的相對誤差較大,說明該期的社會消費品零售總額統計數據統計數據質量可疑。
模型預測值是剔除季節因素的值,而建模剔除了長期趨勢,但相對誤差的計算公式表明,在計算相對誤差系數時,是否通過季節因素還原并不改變相對誤差系數值的大小,故此處直接使用剔除季節因素的預測值進行數據質量評估,評估的結果如圖3所示。
從圖3可以看出,中國社會消費品零售總額的數據基本上在誤差范圍之內沒有超過5%的警戒線。
盡管社會消費品零售總額數據質量總體狀況良好,但從誤差變動來看,近期誤差波動范圍有擴大的趨勢。為了深入分析,本文通過計算移動方差,即利用移動平均的原理,計算3項移動方差②移動方差的計算是逐步計算各個季度的方差,可以對時間序列波動程度進行定量考察。例如,2002年第一季度到第三季度共計三個樣本數據,計算該三個數據方差;接著計算2002年第二季度至第四季度的方差,如此移動計算,可以達到移動方差的序列。,具體結果顯示如圖4所示。從圖4可以看出,近期的相對誤差變動程度增加,為擴大趨勢。
圖3 基于匹配性的社會消費品零售總額數據質量評估結果

圖4 社會消費品零售總額數據質量評估相對誤差的變動程度(移動方差)
5 基本結論與對策
5.1 中國社會消費品零售總額數據質量基本上在誤差允許范圍之內
基于匹配性理論,利用自回歸滯后分布模型,發現中國社會消費品零售總額總體數據在允許的誤差范圍之內。從評估結果來看,長期以來,國內貿易統計工作一直圍繞社會消費品零售總額這一指標來進行,包括制度的設計、調查的組織實施和數據的加工使用等,對數據質量保證起到了重要作用,其能夠比較準確反映國內市場運行和消費方面情況。
5.2 社會消費品零售總額指標誤差近期在逐步擴大
從社會消費品零售總額的變動情況來看,近期誤差有擴大的趨勢。相對誤差范圍的擴大,一方面與經濟形式的改變有很大關系,另一方面說明社會消費品零售總額在反映貿易和流通環節的實質運行質量有所下降。事實上,隨著我國市場經濟的快速發展和流通體制改革的不斷深入,單一的社會消費品零售總額指標已不能滿足GDP核算、多角度觀察經濟運行情況的需要(主要是缺少健全的行業統計指標);而且隨著調查對象數量的快速增長和構成的日趨復雜,加之被調查對象并無這方面的核算指標,致使數據采集難度急劇增加。
5.3 建立適應市場經濟體制的貿易統計體系
社會消費品零售總額在反映貿易領域情況是我國獨有的,與國際不接軌。因此,為適應新形勢、新任務的要求,進一步改革國內貿易統計很有必要。國家統計局局長馬建堂2009年提出“加快研究與社會主義市場經濟體制相適應的貿易統計制度”要求,從2010開始,力爭用兩到三年時間,本著“在建立健全批發和零售業、住宿和餐飲業行業統計的基礎上,以直接調查統計數據為主體、輔之以科學推估數據為補充的方法,加工計算社會消費品零售總額指標”的改革思路,最終達到“反映市場、消費、流通的指標更加豐富,數據的采集生產過程更加可控,基層負擔有所減輕”的目標。基于此,盡管總體數據質量較好,但隨著貿易經濟的發展,需要進一步完善相關的統計體系。
[1]余芳東.國外統計數據質量評價和管理方法及經驗[J].北京統計,2003,(7).
[2]顏日初,朱喜安.我國GDP數據的質量及其改進措施[J].中南財經政法大學學報,2003,(2).
[3]孟連,王小魯.對中國經濟增長統計數據可信度的估計[J].經濟研究,2000,(10).
[4]劉洪,黃燕.基于經典計量模型的統計數據質量評估方法[J].統計研究,2009,(3).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
