基于最小合成單元的維吾爾音庫設計
2012-10-27 06:35:08卡斯木江卡迪爾古麗娜爾艾力艾斯卡爾艾木都拉
通信技術 2012年4期
關鍵詞:文本
卡斯木江·卡迪爾, 古麗娜爾·艾力, 艾斯卡爾·艾木都拉
(新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
0 引言
語音合成是語音處理技術中的一個重要方向,國內外對此進行了大量的研究并取得了豐碩的成果[1]。隨著語音合成的發展,語料庫及語料庫方法在國內外均有長足的進步,目前大型語料庫的建立以及基于語料庫的研究是國內外語言學研究的熱點。
語料庫(Corpus)是指一個由大量的語言實際使用的信息組成的,專供語言研究、分析和描述的語言資料庫[2]。近十多年來,中國在語料庫和信息技術方面取得了令人矚目的進步。在語料庫建設方面,中國已建成了第一個大型的中文計算機語料庫,即含7000萬字的現代漢語語料庫。語料庫的建設過程包括語料錄入、核對、語料自動分詞,自動標注,語料文本分割、合并、標記處理等[3]。近年來維吾爾語語音合成技術也經歷了不同的發展階段,不同的合成技術擁有自己的優缺點。比如小樣本音素拼接語音合成系統中,拼接單元是音素,因為拼接單元小,音庫容量也小。但是這種合成方法很難提高合成自然度。再如不定長單元的大語料庫波形拼接合成系統中,拼接單元是音節、單詞、句子等不同的合成基元。這種方法的特點是合成單元大,拼接點數小,保持了原始發音人的音質,合成自然度好,缺點是合成語音的效果不穩定,建立語料庫周期太長。目前的語音合成系統在合成語音的可懂度和自然度方面還存在一些缺陷[4]。
為了改善以上合成方法的欠缺,采取了一些新的方法。把音節作為主要合成單元,因為維吾爾語中音節的數量很大,語料庫中不能完全包括所有的音節,為了實現音庫中不存在的音節的合成,又建立了音素庫,并且在合成系統中有效的結合這兩種拼接單元的合成方法,從而達到了預期的目標。
1 語音語料的設計
在語料庫的建設中,語音語料庫的完備性和科學性十分重要[5]。語音語料庫的建立主要包括以下4個主要過程:文本語料的設計,文本語料的錄音,聲音語料的標注,語音庫建設。
1.1 文本語料設計
如何選取語料,是語料庫建庫工作的關鍵。為了保證建庫工作的有序有效,保證語料庫的質量,在語料庫建庫之前,首先要研究制定好語料的選擇原則[6]。收集語料時考慮維吾爾語的韻律特點,音變現象,音素組合規則,音節類型等多個因素。文本取自新聞報道、小說、即新疆日報維文版。將各個領域搜集的文本作為原始文本語料集、對其進行斷句、去除不合適的語句。然后通過“維吾爾文字校對系統”對句子中的單詞進行校對。在句子結構上存在一些問題,要進行手工校對,并在句子中出現的數字、縮寫詞和外文符號改寫成標準維吾爾字。
由于收集的文本中存在大量的冗余信息,還多次出現相同的自然語言現象和上下文相關模型。利用貪婪(Greedy)算法,就是用于從大的句子庫中自動選取最佳覆蓋的句子子集的算法[7]。通過文本選取算法選取了8989個句子。
1.2 文本語料的錄音
對挑選出來的8989個句子文本語料進行了高質量錄音。錄音時對文本進行分段式錄音,并對錄制的句子進行即時地檢查,有問題的地方進行補錄。具體錄音規則如下:
1)聲音文件格式是:*.wav,16 kHz,16 bit,單聲道。
2)語速要一致,一般在4音節/秒或者80單詞/分鐘左右。
3)按照自然語流的方式朗讀,注意停頓的地方,不要加情感。
4)隔離所有的噪音,尤其是靜音和停頓的地方。
1.3 聲音語料的標注
語音語料庫標注的目的是從語音語料中切分出一個個合成單元。語音切分是指根據語音標注序列,將語音信號切分成時序相鄰的一系列與語音學標注單元(如音素,音節,單詞等)相應的音段,并將相應的時問信息添加到標注文件里。基元切分標注是根據實驗語音學方面的知識,以語音在語譜圖上的特征為主,聽覺和時域圖為輔進行切分標注。聲音標注層次有音素、音節、單詞、韻律詞、韻律短語、語調短語和句子7個層次。
為了減少工作切分工作量,采取了半自動方法,即先進行自動切分,通過HMM 單音素模型實現語料庫音素層的自動標注,準確一致的切分除了音素邊界[8],然后再經過人工調整。在此基礎上結合維吾爾語的音節劃分和單詞劃分規則就可以得到音節,單詞和句子的自動標注信息,自動切分標注時還出現某些音位有變音、增音、脫落、弱化、清化、濁化、同化等現象,將進行手工修改。還對長短靜音(sp)邊界進行調整、添加或者刪除。其他3個韻律層次以發音人員的聲音為主,結合收集的劃分規則進行手工標注。維吾爾語語音標注結果(一個句子為例)如圖1,圖2和表1所示。

圖1 維吾爾語標注文件的波形

圖2 維吾爾語標注文件的頻譜

表1 標注文件層次及時長
2 語音庫建設
2.1 音節庫
維吾爾語中最小發聲單元是音節,1個音節是由元音和零至3個輔音構成的。用字母“V”代表元音,用字母“C”代表輔音,根據維吾爾語音節的構成規則,維吾爾語中有6種常用的音節格式:即V,VC,CV,CVC,VCC,CVCC,除了以上的音節格式以外還有一些從其他語言中引進的音節格式:CCV,CVV,CCVC,CVVC,CCVCC 等。
建立音節庫時,首先提取標注數據中所有音節樣本的特征參數,拼接所有的聲音文件。提取的音節特征有音節包含的元音、在韻律短語中的位置、時長、前接音素、后接音素、音高向量、音高高點、音高低點、音節在音庫中的開始和結束時間等特征。特征提取由Praat軟件、matlab和VC++ 6.0編程環境中實現。
最后得到的是拼接所有聲音文件數據的文件,同時形成所有音節信息的索引文件,每個音節在索引文件中的編號文件和每個音節在編號文件中的開始位置和結束位文件等4個文件。在數據庫共有8989個句子,音節庫總共包含3456個音節,維吾爾語的固有音節類型具體的分布情況如表2 所示。
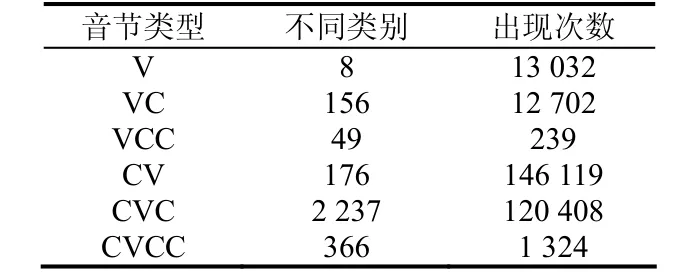
表2 “維吾爾語音節庫”常用音節分布情況
2.2 音素庫
維吾爾語中音素是最小的語音單位,音素有元音和輔音兩大類。在32個字母中有8個元音字母,24個輔音字母。建立音素庫時所做的提取參數,建立索引工作跟建立音節庫的工作相仿。主要區別是這部分工作針對標注數據中的音素層次進行參數提取。提取的參數不一樣,但參數提取方法、產生的文件類型和開發環境都一樣。
在數據庫中存在的8989個句子中,就有32個不同音素,其分布情況如表3所示。
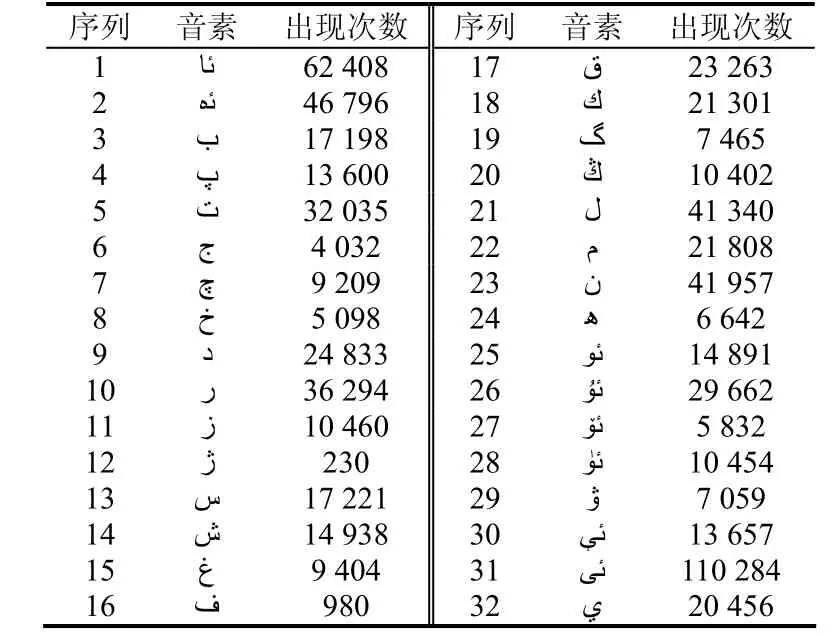
表3 “維吾爾語音素庫”中的音素分布情況
3 結語
近幾年來,隨著語音學和計算機技術的發展,維吾爾語語音合成技術取得了巨大的進步。目前,以波形合成為基礎的語音合成技術已經可以合成清晰度,可懂度較好的語音,然而在合成語音的自然度方面仍需進一步提高。進一步的提高了語音合成的自然度從維吾爾語的語音特點出發[9-10],對維吾爾語音節,音素進行研究,建立了音節庫和音素庫。由于語料標注工作需要細心、花費時間周期較長,所以其標注準確率和一致性方面存在一些問題,需要進一步提高。
[1]段凱宇,俞一彪,石汝杰.基于基音同步幀疊接的吳語語音合成[J].通信技術,2002(03):1-3.
[2]譚鍵.語料庫及語料庫語言學的發展與應用[J].西北工業大學學報:社會科學版,25(01):61-63.
[3]劉連元.現代漢語語料庫研制[J].語言文字應用,1996(03):2-8.
[4]俞一彪,段凱宇,石汝杰.吳語文語轉換中的語音韻律控制[J].通信技術,2002(10):1-3,9.
[5]蔡蓮紅,蔡銳,吳志勇,等.語音合成語料庫的設計與聲學特征分析[C]//2002年全國聲學學術會議.桂林:中國聲學學會,2002:375-376.
[6]陳小瑩,陳展,華侃,等.語音語料庫的設計研究[J].科技信息,2008(36):5-6.
[7]姑麗加瑪麗·麥麥提艾力,艾斯卡爾·肉孜,艾斯卡爾·艾木都拉.三音素模型的維吾爾語最佳文本選取算法[J].計算機工程與應用,2009,45(18):242-244.
[8]阿依木尼薩·胡甫爾,艾斯卡爾·艾木都拉.面向語音合成的維吾爾語音素自動切分算法研究[J].計算機應用與軟件,2011,28(09):18-21.
[9]胡曉荷.周光召和柳傳志對“語音云”寄予厚望——移動互聯網步入“語音云”時代[J].信息安全與通信保密,2011(12):39-41.
[10]龐雄昌,王喆.基于 GDTW+SVM的語音識別[J].信息安全與通信保密,2011(12):39-41.
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
