基于循環(huán)策略和動態(tài)知識的deep Web數(shù)據獲取方法
2012-11-06 11:40:20鮮學豐崔志明趙朋朋梁穎紅方立剛
通信學報 2012年10期
鮮學豐,崔志明,趙朋朋,梁穎紅,方立剛
(1. 蘇州大學 智能信息處理及應用研究所,江蘇 蘇州 215006;
2. 江蘇省現(xiàn)代企業(yè)信息化應用支撐軟件工程技術研發(fā)中心,江蘇 蘇州 215104;
3. 蘇州市職業(yè)大學,江蘇 蘇州 215000)
1 引言
目前主流搜索引擎還只能搜索 Internet表面可索引的信息,在 Internet深處還隱含著大量通過主流搜索引擎少量或無法涉及的海量信息,這些信息稱之為深層網頁(deep Web,又稱為invisible Web 或hidden Web)[1]。Deep Web的信息一般存儲在服務器端的Web數(shù)據庫中,與靜態(tài)頁面相比通常信息量更大、主題更專一、信息質量和結構更好。為了方便用戶快捷高效地使用deep Web信息,國內外學者對deep Web數(shù)據集成進行了廣泛的研究[2~4]。Deep Web數(shù)據集成的一種方案是與構建傳統(tǒng)搜索引擎一樣,將deep Web數(shù)據庫中的內容爬取出來,存儲到本地數(shù)據庫中并建立索引,它能在最短時間內響應用戶的查詢要求[5]。目前,這種方案在許多特定領域已成為deep Web數(shù)據集成研究的主流。由于集成系統(tǒng)可能需要集成數(shù)十個甚至更多的deep Web數(shù)據源,因此,該方案中一個關鍵并十分有挑戰(zhàn)性問題是如何高效地獲取deep Web數(shù)據。
目前,deep Web數(shù)據集成的實現(xiàn)方法為:首先獨立窮盡獲取每一個待集成的deep Web數(shù)據源,然后通過數(shù)據清洗、實體識別、合并去重等步驟完成獲取數(shù)據的集成。這種實現(xiàn)方法在數(shù)據獲取方面主要存在2個缺陷:1) 每個數(shù)據源數(shù)據獲取的后期代價十分巨大,花費較大的代價僅僅獲取極少的新數(shù)據,同時數(shù)據集成時需要處理來自不同數(shù)據源的大量重復數(shù)據,數(shù)據集成的代價也非常巨大;2) 每個數(shù)據源的數(shù)據獲取獨立進行,爬蟲主要依據該數(shù)據源已獲取數(shù)據的統(tǒng)計信息進行查詢選擇[6~8],由于統(tǒng)計信息缺乏和查詢候選池有限,該方法存在查詢選擇的準確性較差、數(shù)據獲取覆蓋率較低等問題。
經研究發(fā)現(xiàn),集成系統(tǒng)中待集成的數(shù)據源之間并不是相互獨立的,而是相互關聯(lián)。數(shù)據源之間數(shù)據相互覆蓋,甚至一些數(shù)據源之間相互依賴,例如:現(xiàn)實世界一些商業(yè)數(shù)據源彼此分享數(shù)據。根據這種關聯(lián)關系,進一步研究發(fā)現(xiàn)同領域deep Web數(shù)據源之間具有2個重要特征。特征1:在集成環(huán)境中,從某一數(shù)據源獲取的數(shù)據,可能從另一個或一些待集成的數(shù)據源中獲取,因此從某一數(shù)據源數(shù)據獲取后期獲取的數(shù)據,可能出現(xiàn)在另一個或一些數(shù)據源數(shù)據獲取的前期或中期;特征 2:同領域的數(shù)據源之間具有相似的屬性值并且這些屬性值也具有相似的分布特征。基于上述發(fā)現(xiàn)本文提出一種基于循環(huán)策略和動態(tài)知識的數(shù)據獲取方法。該方法根據特征1提出使用循環(huán)策略分多次完成數(shù)據源的數(shù)據獲取,當獲取某一數(shù)據源的效率下降到某一閾值時,停止該數(shù)據源的數(shù)據獲取,爬蟲開始獲取下一個數(shù)據源的數(shù)據,依次類推直到把所有待集成數(shù)據源都獲取一遍;然后再重復上述過程,直到所有待集成數(shù)據源都已達到結束獲取條件。該方法使一部分應該從一些數(shù)據源數(shù)據獲取后期獲得的,從另一些數(shù)據源數(shù)據的前期或中期獲得。與傳統(tǒng)一次性窮盡數(shù)據獲取方法相比該方法能減少數(shù)據源后期的數(shù)據獲取,降低了數(shù)據獲取的代價,同時也能減少重復數(shù)據的獲取,降低了數(shù)據集成的代價。根據特征 2提出利用集成系統(tǒng)已獲取的數(shù)據動態(tài)構建知識,并設計基于集成系統(tǒng)動態(tài)知識的查詢選擇方法。該方法豐富了查詢選擇的知識,提高了查詢選擇的準確性,同時擴展了查詢候選池,提高了數(shù)據獲取的覆蓋率。結合循環(huán)策略和動態(tài)知識進行數(shù)據獲取時,對于每個數(shù)據源可以多次利用豐富后的集成系統(tǒng)動態(tài)知識進行查詢選擇能有效率提高查詢選擇的準確性,從而提高數(shù)據獲取的效率。
事實上,不同領域的數(shù)據源之間也可能存在一定的關聯(lián)關系,對存在關聯(lián)關系的不同領域的數(shù)據源進行數(shù)據獲取時,仍可以使用本文提出的基于循環(huán)策略和動態(tài)知識的數(shù)據獲取方法提高數(shù)據獲取的效率。但是由于同領域數(shù)據源之間的關聯(lián)關系一般強于不同領域的數(shù)據源,所以同領域deep Web數(shù)據集成時使用本文提出方法的效率更高。
2 相關研究
在deep Web數(shù)據獲取方面,Barbosa L等人[6]第一次提出使用已獲取數(shù)據中最高詞頻關鍵詞作為下一個查詢詞的查詢選擇方法,然后,在實際中最高詞頻的查詢詞并不一直能返回更多的新記錄,并且由于這種方法產生的查詢詞具有較高的關鍵詞依賴,將會產生大量重復記錄,增加數(shù)據獲取的代價。Wu Ping等人[7]通過查詢選擇高效的爬取deep Web數(shù)據,將結構化Web數(shù)據庫看成一個屬性—值圖模型,將 Web數(shù)據庫爬行問題轉化為圖遍歷問題,以最少的查詢提交次數(shù)獲取盡量多的deep Web內容,其問題在于每一輪查詢結果都要擴充到屬性—值圖中用于產生下一輪待提交的查詢詞,這種做法代價非常高。Google也提出了一種多領域跨語言的deep Web數(shù)據獲取方法[9],將deep Web內容爬取出來Surface化,將爬取出來的內容放進Google索引中,這樣用戶就可以通過 Google搜索到部分deep Web內容。目前,Google每秒鐘可以爬取上千個deep Web動態(tài)頁面,其不足在于該方法不能應用到Post方法提交的表單上,并且只獲取URL而不進一步處理。Lu Jiang等人[10]提出一種基于強化學習的deep Web爬取框架,該框架爬蟲作為Agent,Web數(shù)據庫被作為環(huán)境。Agent感知當前狀態(tài),并根據Q-value選擇一個查詢提交到Web數(shù)據庫。最近,George V等人[11]針對不需要獲取查詢所有結果的特定應用,提出一種Rank-aware Hidden Web 爬取方法,該方法對所有潛在查詢僅僅下載 top-k個結果,從而避免了完全爬取巨大的deep Web數(shù)據。綜上所述,這些研究主要針對如何提高單個 deep Web的數(shù)據獲取效率,沒有考慮集成環(huán)境下進行數(shù)據獲取時,deep Web數(shù)據源之間的關聯(lián)關系對數(shù)據獲取的影響。
3 Deep Web數(shù)據獲取相關概念定義
Deep Web 數(shù)據獲取方式:結構化的Web數(shù)據庫可看作一張關系數(shù)據表DB,DB包含的數(shù)據記錄為 T={t1,t2,…,tn},每條記錄包含 m個屬性 A={a1,a2,…,am}。獲取deep Web中的數(shù)據只能通過從查詢接口上提交查詢,從返回結果頁面獲得 deep Web中包含該查詢的記錄集,對于一個潛在的查詢qi,R(qi)表示在DB上執(zhí)行查詢qi所返回的記錄集,即DB中所有包含qi的記錄集合(假設不考慮返回記錄限制的情況),R(qi)為T的一個子集。
Deep Web數(shù)據獲取代價模型:爬蟲在DB上執(zhí)行查詢qi和獲取qi所返回的記錄集都需要一定的代價,如時間、網絡帶寬等。對于一個查詢qi,使用Cost(qi, DB)表示爬蟲在DB上執(zhí)行查詢qi和獲取qi所返回記錄集的各種代價總和(即deep Web數(shù)據獲取代價)。對于結構化的Web數(shù)據庫,數(shù)據獲取的代價主要包括:爬蟲提交查詢到站點的查詢代價、爬蟲與Web服務器交互的代價、爬蟲下載結果頁面的代價。交互次數(shù)和查詢提交次數(shù)是不一樣的,每個結果頁面通常包含固定k個匹配的數(shù)據記錄,每次初始連接得到至多k個數(shù)據記錄。例如,在圖書數(shù)據庫中有 104個圖書記錄匹配屬性值“書名,Java”并且每個結果頁面顯示10(k=10)個數(shù)據記錄,則獲取所有結果記錄集的總交互次數(shù)為[104/10]=11次。即每獲取下一頁的數(shù)據記錄,都需要和Web服務器交互一次。
定義爬蟲提交一次查詢的代價為 Cq,爬蟲與Web服務器交互一次的代價為 Cm,爬蟲下載一個結果頁面數(shù)據記錄的代價為Cd。對于一個查詢qi,在DB上執(zhí)行查詢qi和獲取qi所返回記錄集的各種代價總和Cost(qi, DB)可表示為
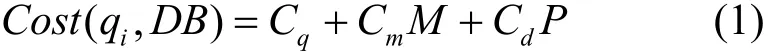
其中,Cq、Cm、Cd為常量,M為爬蟲與Web服務器交互次數(shù),P為爬蟲需下載的結果頁面數(shù)量。

其中,num(qi, DB)為DB中所有匹配qi的數(shù)據記錄數(shù),k為一個結果頁面最多可顯示記錄數(shù),如果DB存在最大返回記錄限制,則N為DB一次查詢的最大返回記錄數(shù)。爬蟲需下載的結果頁面數(shù)量P和爬蟲與Web服務器交互次數(shù)M相等。
單個deep Web數(shù)據源的數(shù)據獲取:對于一個deep Web數(shù)據源DBk,deep Web數(shù)據獲取問題可形式化定義為:尋找一組查詢關鍵詞集合 Qk={q1,q2,…, qn}使得 P(q1∨q2∨…∨qn,DBk,)值最大,其約束條件是,其中,t為爬蟲獲取DBk中數(shù)據可使用的最大代價。對于一個給定的查詢qi,P(qi,DBk)表示在DBk上執(zhí)行查詢qi所返回的結果記錄數(shù)占DBk總記錄數(shù)的比例。
面向deep Web數(shù)據集成的數(shù)據獲取:對于一個集成系統(tǒng)I,S={DB1, DB2, …, DBn}為I待集成的所有deep Web數(shù)據源的集合,面向deep Web數(shù)據集成的數(shù)據獲取可形式化定義為:需找一組查詢關鍵詞集合 Q={Q1,Q2,…,Qn}使得 P(Q1∨Q2∨…∨Qn)最大,其約束條件是其中,T為集成系統(tǒng)I的可使用的最大代價,Qi為獲取第i個數(shù)據源所提交的查詢集合Qi={q1,q2,…,qn},P(Qi)為 P(q1∨q2∨…∨qn, DBi)。
4 Deep Web數(shù)據集成的數(shù)據循環(huán)獲取策略
4.1 數(shù)據循環(huán)獲取策略
對于一個集成系統(tǒng)I,S={DB1,DB2,…,DBn}為I待集成的所有deep Web數(shù)據源的集合。針對傳統(tǒng)的deep Web數(shù)據集成實現(xiàn)方法在數(shù)據獲取方面存在的缺陷,本文基于同領域數(shù)據源之間的關聯(lián)關系,提出使用循環(huán)策略分多次完成數(shù)據源的數(shù)據獲取,該策略主要思想為:首先對S中的數(shù)據源,根據其可能對集成系統(tǒng)I貢獻的效用大小進行排序,效用評價標準可以根據數(shù)據源的大小、數(shù)據源的數(shù)據質量等,或者由這些量組成的一個函數(shù)。然后從S中排在第一位的數(shù)據源開始進行數(shù)據獲取,數(shù)據獲取的策略是當正在進行數(shù)據獲取的當前數(shù)據源的特定特征達到閾值(特征和閾值將在停止條件進行詳細描述),則停止獲取該數(shù)據源,根據達到閾值的特征判斷該數(shù)據源是繼續(xù)保持在S中等待下一次獲取,還是從S中刪除該數(shù)據源,結束該數(shù)據源的獲取任務;然后爬蟲開始獲取下一個數(shù)據源的數(shù)據,依次類推把S中的所有數(shù)據源都獲取一遍;再重復上述過程,直到S為空,S中的數(shù)據源都達到獲取結束條件。循環(huán)獲取的具體算法如下。據源
T={t1,t2,…,tn}; // T為數(shù)據源的最大代價集合
θ; //θ為一個查詢獲取新數(shù)據的效率閾值
ω; //ω為獲取數(shù)據源的數(shù)據量閾值
α; //α 為常量
Begin:
Int U={u1,u2,…,un}; // uk統(tǒng)計DBk已被獲取的次數(shù)
L=SourceSort(S);//SourceSort()為數(shù)據源排序函數(shù)
While(L<>Null)
For every DBkin L by order
x=0; // x為計數(shù)器,統(tǒng)計對于DBk連續(xù)多少個查詢獲取新數(shù)據的效率都不大于θtk)
Dowload(R(qi));IF (qi從DBk獲取新數(shù)據的效率不大于θ)
x= x +1;
Else x=0; EndIF
L = L-DBk;//滿足結束條件,從L中刪除DBk
EndIF
uk= uk+1; // DBk被循環(huán)獲取次數(shù)加1
EndFor
Done
S中的數(shù)據源具有不同的特征,例如:數(shù)據源的大小、數(shù)據源的質量等;另外數(shù)據源之間的覆蓋率也各不相同,一些數(shù)據源之間覆蓋率較高,而另一些覆蓋率較低,甚至可能包含另一些。因此不同的數(shù)據源對集成系統(tǒng)的貢獻效用是有差異的。為了提高數(shù)據集成的效率,本文在開始數(shù)據獲取前首先利用排序算法 SourceSort()對 S中的數(shù)據源按它們可能對集成系統(tǒng) I貢獻的效用大小進行排序,SourceSort()是一種數(shù)據源排序方法[12],該方法主要依據數(shù)據源可能給集成系統(tǒng)貢獻的效用大小進行排序,這里的效用是指數(shù)據源能為集成系統(tǒng)新增新數(shù)據量與新數(shù)據質量(數(shù)據的完整性、一致性和冗余性等)的函數(shù)。
完成對S中數(shù)據源的排序之后,算法開始進行數(shù)據獲取,一次查詢的數(shù)據獲取流程為:首先由SelectQuery()選擇一個查詢關鍵詞qi(SelectQuery()將在下一節(jié)詳細介紹),然后 Query(qi,DBk)在 DBk上執(zhí)行查詢qi,并返回結果頁面記錄集R(qi),接著Dowload(R(qi))實現(xiàn)從結果頁面下載數(shù)據記錄到本計入獲取DBk已耗費的總代價Cost(DBk)。數(shù)據獲取的過程為不斷重復該流程直到滿足循環(huán)停止條件。
4.2 數(shù)據獲取停止條件
對于該算法停止條件的設置非常重要,該算法的停止條件可以分為2類。第1類為暫時停止條件:對數(shù)據源DBk的數(shù)據獲取暫時停止,仍然保留在L中,等待下一次獲取;第2類為結束條件:結束數(shù)據源DBk的數(shù)據獲取,并將該數(shù)據源從L中刪除。
暫時停止條件設置:對于數(shù)據源 DBk,如果SelectQuery()連續(xù)選擇的 α個查詢的新數(shù)據獲取率都不大于θ,則說明SelectQuery()在目前的知識(查詢候選池和統(tǒng)計知識)下已經不能進行有效查詢選擇,繼續(xù)對DBk進行獲取,代價將非常高,需要暫時停止對DBk的數(shù)據獲取,等待下一次循環(huán)時再繼續(xù)獲取。在下一次獲取時則可利用豐富后的動態(tài)知識進行查詢選擇。
結束條件設置:當對數(shù)據源DBk進行數(shù)據獲取時,DBk的特征滿足以下3種結束條件之一,即可從L中刪除DBk,結束DBk的數(shù)據獲取。DBk估計大小的一定比例(例如:ω=95%),即大部分數(shù)據,剩下的少量數(shù)據對集成系統(tǒng)的影響較小,并且獲取這部分數(shù)據付出的代價也可能較高,所以可以結束DBk的數(shù)據獲取。
2) 如果集成系統(tǒng)I分配給DBk的數(shù)據獲取資源耗盡,即則結束DBk的數(shù)據獲取。
3) 如果DBk被循環(huán)獲取的次數(shù)uk達到閾值β,即uk≥β,則結束DBk的數(shù)據獲取。
對于數(shù)據源DBk經過了β次查詢候選池擴展和統(tǒng)計知識豐富的循環(huán)獲取后,從DBk中繼續(xù)獲取新數(shù)據的可能性也較小,同時獲取數(shù)據的代價隨著循環(huán)獲取的次數(shù)增加也不斷增大,因此可以結束DBk的數(shù)據獲取。
5 基于集成系統(tǒng)動態(tài)知識的查詢選擇
根據同領域數(shù)據源之間的相關性,S中數(shù)據源之間通常具有相似的屬性值并且這些屬性值也具有相似的分布特征,例如:在圖書領域不同圖書銷售網站(數(shù)據源)所銷售的圖書具有一定的相似性,并且圖書書名出現(xiàn)的頻率也是相似的。本文提出利用集成系統(tǒng)已獲取的數(shù)據構建動態(tài)知識,并設計基于集成系統(tǒng)動態(tài)知識的查詢選擇方法。與傳統(tǒng)方法比較,該方法使爬蟲獲得更廣泛的分類屬性值,擴展了查詢候選池,從而能避免信息孤島問題,提高數(shù)據獲取的覆蓋率;同時動態(tài)知識使爬蟲獲得了更全面和時新的統(tǒng)計知識,利用動態(tài)知識可提高查詢回報率估算的準確性,從而提高查詢選擇的效率。
5.1 動態(tài)知識構建
對于一個集成系統(tǒng)I,S={DB1,DB2,…,DBn}為I待集成的所有deep Web數(shù)據源的集合,在某一時刻取的數(shù)據,集成系統(tǒng)的動態(tài)知識(dynamic knowledge)DK可定義為:從SLocal中得到的候選查詢關鍵詞以及該查詢關鍵詞在 SLocal中出現(xiàn)的概率對的集合,即:qi代表候選查
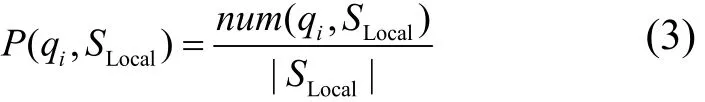
隨著數(shù)據獲取工作的進行,SLocal中的數(shù)據會動態(tài)變化,因此,DK也需要根據SLocal保持動態(tài)更新,以便為查詢選擇提供更時新和全局的知識。理論上集成系統(tǒng)每執(zhí)行一次查詢(數(shù)據獲取)都可能使例如:執(zhí)行一次查詢qk(數(shù)據獲取)都有可能改變的候選查詢關鍵詞,因此理論上每執(zhí)行一次查詢的數(shù)據獲取都需要更新DK。對于集成系統(tǒng)I和SLocal,當一個候選查詢 qk被選擇在數(shù)據源 DB上執(zhí)行Query(qk,DB),返回數(shù)據記錄集合為R(qk),更新DK主要有2個方面的工作。
1) 統(tǒng)計分析是否有新的候選查詢產生,如果有新的候選查詢qnew產生,則向DK添加候選查詢qnew現(xiàn)的概率更新可由以下式計算
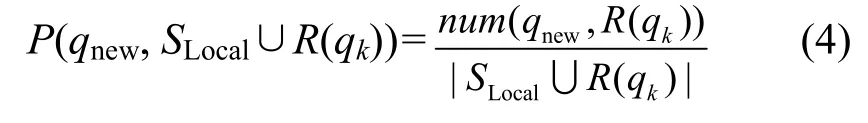
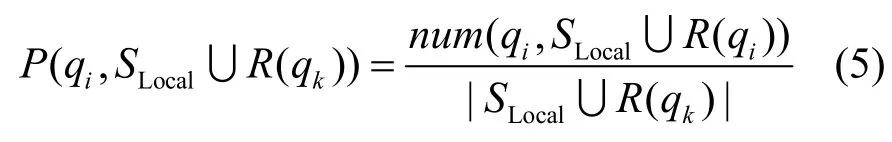
但是如果每一次查詢執(zhí)行都動態(tài)維護 DK,那么代價將十分巨大,隨著系統(tǒng)集成數(shù)據規(guī)模的增加,維護DK的代價將變得無法接受。本文發(fā)現(xiàn)在實際應用中對于一個集成系統(tǒng)I,當I所集成的數(shù)據達到一定規(guī)模 M后(即 DK中知識達到一定規(guī)模后),一個查詢甚至若干個查詢的執(zhí)行對DK的更新結果對查詢選擇的影響非常小。基于上述發(fā)現(xiàn)本文使用一種優(yōu)化方式實現(xiàn)更新 DK。當集成系統(tǒng) I所集成的數(shù)據達到一定規(guī)模M之前,對每一次查詢都更新 DK。當集成系統(tǒng) I所集成的數(shù)據達到一定規(guī)模M之后,執(zhí)行K個查詢后再更新DK,K可以隨M的變化而變化,從而在不影響查詢選擇效率的前提下,盡可能減小更新DK的代價。
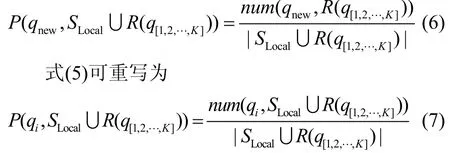
式(4)可重寫為其中,R(q[1,2,…,K])為{q1,q2,…,qk}在 DB 上執(zhí)行所返回結果的集合。
5.2 基于動態(tài)知識的查詢回報估算
DK是S中所有數(shù)據源已獲取的數(shù)據中得到的知識,因此爬蟲擁有了一個更大的查詢候選池和更全局、更時新的統(tǒng)計知識。對于正在進行數(shù)據獲取的當前數(shù)據源DB,DK中的候選查詢可分為2類:QDB和QDK。QDB為包含在DK中,且已出現(xiàn)在DBLocal中的候選查詢;QDK為包含在 DK中,但沒有在DBLocal中出現(xiàn)候選查詢。對于一個候選查詢qi是否能被選擇執(zhí)行,一個重要的因素是執(zhí)行qi能獲得的查詢回報,這里的查詢回報指查詢能夠獲取新數(shù)據的數(shù)量,下面將討論如何估計QDB和QDK這2類查詢的回報率。
1) QDB查詢回報估計:使用從集成系統(tǒng)的全局知識DK來估算qi∈QDB的回報率,查詢回報估算公式如下
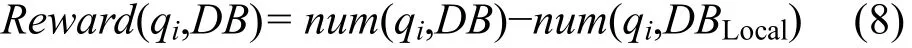
num(qi,DBLocal)是DBLocal中與qi匹配的數(shù)據記錄數(shù),num(qi,DB)是目標數(shù)據源 DB中與 qi匹配的記錄數(shù),num(qi,DB)在qi在DB上執(zhí)行之前是未知的。
下面討論如何估算num(qi,DB),基于S中數(shù)據源之間通常具有相似的屬性值并且這些屬性值也具有相似的分布特征,在不考慮偏差的情況下,假定qi出現(xiàn)在DB的概率等于它在全局數(shù)據上的概率P(qi,SLocal),P(qi,SLocal)能從DK中得到。基于這個假定,所有在DB上已提交的查詢q[1,2,…,m]出現(xiàn)在DB上的概率與全局數(shù)據上的概率也相同。因此使用如下式估算num(qi,DB)

2) QDK查詢回報估計:現(xiàn)在討論如何估算qi∈QDK的回報率(查詢qi未出現(xiàn)在DBLocal中),同上本文假設 P(qi,DB)等于 P(qi,SLocal)。因此Reward(qi,DB)的計算式如下:據量)。

5.3 查詢選擇
Deep Web數(shù)據集成爬蟲的目的是在一定資源約束下盡可能多地獲取數(shù)據。基于這個目的爬蟲進行查詢選擇時必須考慮以下2個因素:第一,候選查詢qi在DB上執(zhí)行的查詢回報率;第二,候選查詢qi獲取DB中數(shù)據需要花費的代價。例如:存在2個候選查詢qk和qj,如果它們獲取DB的數(shù)據時需要花費的代價相同,但是qk比qj的查詢回報率更高,qk應先于qj被選擇,同理,如果qk和qj具有相同的查詢回報率,但qk比qj花費更少的代價,qk已應先于qj被選擇。因此候選查詢qi的效率可由下式計算。
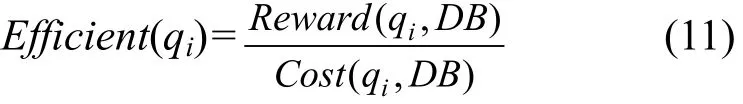
Reward(qi,DB)查詢 qi在 DB的查詢回報率,Cost(qi,DB)表示查詢qi獲取DB中數(shù)據需要花費的代價。
因此,Efficient(qi)估算單位代價情況下qi能返回多少新記錄。根據這個函數(shù)爬蟲能夠估計每一個候選查詢qi的效率,從而選擇一個最高效率的查詢首先執(zhí)行。查詢選擇算法采用貪婪方法每次都選擇具有最高潛在效率的查詢,具體算法如下:

6 實驗
6.1 數(shù)據準備
為了驗證本文方法的有效性,本文使用2類測試數(shù)據:一類是人工構建的模擬deep Web數(shù)據源,另一類是真實的deep Web數(shù)據源。人工構建專利領域的模擬deep Web數(shù)據源,使用項目組已從7個國家2個組織獲取的63.32萬條專利數(shù)據,構建5個專利領域的deep Web數(shù)據源。為了模擬真實世界的同領域數(shù)據源之間存在一定的相關性(相互覆蓋),又避免大量覆蓋導致的實驗代價過大的問題,設置每個數(shù)據源隨機從63.32萬條數(shù)據中抽取15萬~25萬條不等的數(shù)據記錄。同時,本文也在真實 deep Web數(shù)據源上驗證本文方法的有效性,從BrightPlanet公司的CompletePlanet網站的音樂領域中選取 5個 deep Web數(shù)據源(music.aol.com,www.chicagoreader.com,www.onlinemusicdatabase.com,www. sheetmusicplus.com, www.bestwebbuys.com)。對于這些數(shù)據源大小通過Arjun Dasgupta等人[13]提出的數(shù)據源大小估計方法進行估算。
為了更好驗證基于動態(tài)知識的查詢選擇方法QuerySelect-DK的效率,本文對QuerySelect-DK進行適當簡化得到QuerySelect-T,兩者查詢選擇策略一樣,兩者的區(qū)別為:QuerySelect-DK可利用集成系統(tǒng)已獲取所有數(shù)據的動態(tài)知識進行查詢選擇,而QuerySelect-T僅能利用當前數(shù)據源已獲取的有限知識進行查詢選擇。
本文主要從以下幾個方面驗證本文提出的方法的性能:①基于循環(huán)策略與動態(tài)知識的數(shù)據獲取方法(Cycle-A)與基于 QuerySelect-T、圖遍歷Graph-Based[7]和高詞頻 High-frequency[6]查詢選擇方法的獨立數(shù)據獲取方法性能比較;這里的獨立數(shù)據獲取方法是指利用上述查詢選擇方法獨立窮盡獲取每一個待集成的deep Web數(shù)據源,然后合并從各個數(shù)據源獲取的數(shù)據,完成所有待集成數(shù)據源的數(shù)據集成。獨立數(shù)據獲取策略不考慮待集成的deep Web數(shù)據源之間的關聯(lián)關系;②基于動態(tài)知識的查詢選擇方法(QuerySelect-DK)與基于QuerySelect-T、圖遍歷 Graph-Based[7]和高詞頻High-frequency[6]查詢選擇方法性能比較;③更新DK的查詢間隔次數(shù)K對查詢選擇效率的影響。
6.2 實驗結果
6.2.1 基于循環(huán)策略與動態(tài)知識的數(shù)據獲取方法與獨立數(shù)據獲取方法的性能比較
為了比較本文提出的基于循環(huán)策略與動態(tài)知識的數(shù)據獲取方法(Cycle-A)和采用基于QuerySelect-T、圖遍歷Graph-Based和高詞頻High-Frequency查詢選擇方法的獨立數(shù)據獲取方法(Separate-A)的性能,集成系統(tǒng)分別使用2種方法集成專利和音樂領域的所有數(shù)據源,根據deep Web數(shù)據獲取代價模型,2種方法獲取相同覆蓋率的查詢提交次數(shù)越少,deep Web數(shù)據獲取的代價也越小。因此實驗時不考慮數(shù)據獲取的代價因素,實驗通過比較2種方法數(shù)據獲取時的數(shù)據源覆蓋率與查詢提交次數(shù)的關系,測試基于循環(huán)策略與動態(tài)知識的數(shù)據獲取方法的效率。實驗中設置暫時停止條件為α=5,結束條件ω=95%,β=4,數(shù)據獲取時代價條件不受限制。
圖1給出了2種數(shù)據獲取方法的效率對比,從圖1可見,在專利領域Cycle-A的數(shù)據獲取效率明顯優(yōu)于采用 3種查詢選擇方法的 Separate-A(Separate-A-QST、Separate-A-GB和 Separate-AHF)。隨著查詢提交次數(shù)的增加,Cycle-A的效率優(yōu)勢越來越明顯,當覆蓋率達到 80%時,Separate-A-QST策略的查詢提交次數(shù)幾乎為 Cycle-A策略的5倍,當覆蓋率達到95%時,Cycle-A策略的查詢提交次數(shù)約為4 900次而Separate-A-QST策略達到了13 000次左右,從音樂領域已得到類似的結果。這是因為Cycle-A能在較大程度上避免Separate-AQST在每個數(shù)據源數(shù)據獲取后期效率迅速降低的情況,同時也得益于基于集成系統(tǒng)動態(tài)知識的查詢選擇方法。同樣 Cycle-A性能與 Separate-A-GB和Separate-A-HF相比已具有較大的優(yōu)勢。
6.2.2 QuerySelect-DK與現(xiàn)有主要查詢選擇方法的性能比較
集成系統(tǒng)已獲取了某領域n-1個數(shù)據源的數(shù)據,通過比較分別使用基于動態(tài)知識的查詢選擇方法QuerySelect-DK與基于 QuerySelect-T、圖遍歷Graph-Based和高詞頻High-frequency的查詢選擇方法獲取第n個數(shù)據源的數(shù)據的效率,測試本文提出的基于動態(tài)知識的查詢選擇方法QuerySelect-DK的效率。
實驗具體設置為:對于專利和音樂領域,系統(tǒng)已分別集成了各領域 3個數(shù)據源,現(xiàn)在分別使用上述4種查詢選擇方法獲取第4個數(shù)據源的數(shù)據,對于QuerySelect-DK方法,動態(tài)知識DK根據集成系統(tǒng)已獲取的前3個數(shù)據源的數(shù)據構建。圖2給出了4種查詢選擇方法獲取專利和音樂領域第 4個數(shù)據源的效率。從圖2可見,在音樂領域,QuerySelect-DK方法提交大約1 200次查詢已獲取數(shù)據源大約95%的數(shù)據,而QuerySelect-T方法相同查詢提交次數(shù)僅僅獲得大約 70%的數(shù)據。QuerySelect-DK方法提交大約400次查詢時可獲得大約80%的覆蓋率,從獲得相同覆蓋率需要提交查詢次數(shù)方面比較,QuerySelect-DK方法的效率也明顯優(yōu)于QuerySelect-T方法。QuerySelect-DB方法的效率略優(yōu)于QuerySelect-T,但與QuerySelect-DK的性能仍有較大差距,而QuerySelect-HF的效率最差。專利領域的實驗結果與音樂領域類似。因此實驗說明在不考慮代價的前提下,QuerySelect-DK方法的效率高于具有相同查詢選擇策略的 QuerySelect-T。同時基于QuerySelect-DK方法的效率也明顯高于現(xiàn)有主流的圖遍歷Graph-Based和高詞頻High- frequency的查詢選擇方法。
6.2.3 更新DK的查詢間隔次數(shù)K對查詢選擇效率的影響
為了評估更新DK的查詢間隔次數(shù)K對查詢選擇效率的影響,實驗在DK為空和DK較豐富的這2種情況進行,比較不同情況下更新DK的查詢間隔次數(shù)K對查詢選擇效率的影響。第1種情況,初始DK為空,從專利領域的第一數(shù)據源開始數(shù)據獲取;第2種情況,系統(tǒng)已獲取專利領域的前2個數(shù)據源的數(shù)據并構建了DK,開始獲取第2個數(shù)據源的數(shù)據。實驗分別比較K為1,10,30時查詢選擇的效率,實驗結果如圖3和圖4所示。

圖3 當DK較小時K對查詢選擇效率的影響
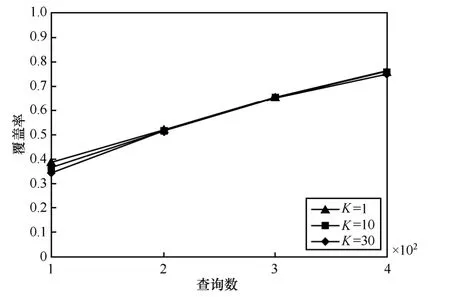
圖4 當DK較豐富時K對查詢選擇效率的影響
從圖3中可見,在初始階段K=1的效率明顯高于其他3種情況,并且數(shù)據獲取效率按照K值遞增而遞減。在大約400次查詢提交之前,隨著查詢提交次數(shù)的增加3種情況的數(shù)據獲取效率差距逐步擴大,但擴大幅度越來越小;在大約400次查詢后3種K值數(shù)據獲取效率差距已基本穩(wěn)定,不再擴大,說明在此之后這3種K值的查詢選擇效率已基本相當。該實驗說明在DK較小時,為了高效的數(shù)據獲取需要使用較小的K值,雖然這樣更新頻率較高,但是由于此時DK較小,更新DK的代價也能接受。當隨著DK的不斷豐富,K的大小對查詢選擇效率的影響逐步減小。從圖4中可見,第2種情況下3種K的數(shù)據獲取效率基本相同,說明在此時這3種不同K對查詢選擇效率的影響基本相同。因此,通過本實驗可得出隨著數(shù)據獲取的進行,可以逐步調整K值,使集成系統(tǒng)在不太影響數(shù)據獲取效率的前提下,盡量降低更新DK的代價。
7 結束語
針對集成環(huán)境下的deep Web數(shù)據獲取問題,本文提出了一種新的數(shù)據獲取方法。該方法根據同領域數(shù)據源之間關聯(lián)性,使用循環(huán)獲取策略減少了數(shù)據源后期數(shù)據的獲取,較大程度上避免了傳統(tǒng)方法數(shù)據獲取后期代價巨大的問題;利用集成系統(tǒng)的動態(tài)知識進行查詢選擇,擴展了查詢候選池、豐富了查詢選擇的知識,從而提高了數(shù)據獲取的覆蓋率和查詢選擇的準確性。實驗表明,提出的基于循環(huán)策略和動態(tài)知識的deep Web數(shù)據獲取方法能夠很好地滿足deep Web數(shù)據集成的需要,與傳統(tǒng)方法比較,具有較高的數(shù)據獲取效率。
[1] MICHAEL K B. The deep Web: surfacing hidden value[J]. Journal of Electronic Publishing, 2001 7(1):1174-1175.
[2] HE B, PATEL M, ZHANG Z, CHANG K C C. Accessing the deep Web: a survey[J]. Communications of the ACM, 2007,50(5):94-101.
[3] 劉偉, 孟小峰, 孟衛(wèi)一. deep Web 數(shù)據集成研究綜述[J]. 計算機學報, 2007,30(9):1475-1489.LIU W MENG X F, MENG W Y. A survey of deep Web data integration[J], Chinese Journal of Computers, 2007,30(9):1475-1489.
[4] NAN Z, GAUTAM D. Exploration of deep Web repositories[A]. Proceedings of the 37th International Conference on Very Large Data Bases[C]. Tutorial, Westin, Seattle, WA, 2011.
[5] JAYANT M, SHAWN J, SHIRLEY C, et al. Web-scale data integration: you can afford to pay as you go[A]. Proceedings of 3rd International Conference Innovative Data Systems Research[C]. Asilomar,CA, 2007. 342-350.
[6] LUCIANO B, JULIANA F. Siphoning hidden-Web data through keyword-based interfaces[A]. Proceedings of the 19th Brazilian Symposium on Database[C]. Brasilia, Brazil, 2004.309-321.
[7] WU P, WEN J R, LIU H, et al. Query selection techniques for efficient crawling of structured Web sources[A]. Proceedings of the 22th International Conference on Data Engineering[C]. Atlanta,GA,USA,2006.47-56.
[8] NTOULAS A, ZERFOS P, CHO J H. Downloading textual hidden web content by keyword queries[A]. Proceedings of the Joint Conference on Digital Libraries[C]. Denver, Colorado, USA, 2005. 100-109.
[9] JAYANT M, DAVID K, LUCJA K, et al. Google's deep-Web crawl[A]. Proceedings of 34th International Conference on Very Large Data Bases[C]. Auckland, New Zealand, Springer,2008.1241-1252.
[10] JIANG L, WU Z H, FENG Q, et al. Efficient deep Web crawling Using reinforcement learning[A]. Proceedings of the 14th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining[C]. Hyderabad, India, Springer, 2010. 428-439.
[11] GEORGE V, ALEXANDROS N, DIMITRIOS G. Rank-aware crawling of hidden Web sites[A]. Proceedings of the International Workshop on the Web and Databases[C]. Athens, Greece, 2011.
[12] XIAN X F, ZHAO P P, YANG Y F, et al. Efficient selection and integration of hidden Web database[J]. Journal of Computers, 2010,5(3): 500-507.
[13] ARJUN D, Xin J, BRADLEY J, et al. Unbiased estimation of size and other aggregates over hidden Web databases[A]. Proceedings of the ACM SIGMOD International Conference on Management of Data,Indianapolis[C]. Indiana, USA, ACM Press, 2010. 855-866.
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數(shù)理化(高中版.高考數(shù)學)(2020年5期)2020-06-02 09:19:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商周刊(2017年9期)2017-08-22 02:57:49
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛(wèi)生(2014年11期)2014-11-12 13:11:32
