改進的Apriori算法的入侵檢測系統研究
2012-12-09 00:55:00陳真
海南師范大學學報(自然科學版) 2012年1期
陳真
(韓山師范學院 潮州師范分院辦公室,廣東 潮州 521012)
改進的Apriori算法的入侵檢測系統研究
陳真
(韓山師范學院 潮州師范分院辦公室,廣東 潮州 521012)
綜述了數據挖掘技術在網絡入侵檢測中的應用,闡述了關聯規則分析在網絡入侵檢測中的應用原理和最新的研究與改進,并指出了目前存在的問題和未來研究的方向.改進由k階頻繁項集生成k+1階候選頻繁項集時的連接和剪枝策略;改進對事務的處理方式,當所有聯接完成時只掃描一遍Lk-1,減少Apriori算法中的模式匹配所需的時間開銷.實驗表明,該算法應用于此系統來提取用戶行為特征和入侵模式特征,提高了整個系統的性能.
關聯規則;頻繁項集;候選項集;Apriori算法;Apriori_ids算法;入侵檢測
入侵檢測系統(intrusion detection system,IDS)是通過掃描操作系統的審計數據或網絡數據包信息來檢測未經過授權或非法進入系統和網絡或者濫用系統和網絡的用戶行為的系統,該系統通過系統審計記錄、分析和檢測網絡流量等手段來識別系統中的存在非法入侵的行為,及時地判斷、記錄并報警,使系統管理人員及時采取有效的措施來彌補系統漏洞.美國哥倫比亞大學Wenke Lee最早[1]提出將數據挖掘技術應用于入侵檢測系統,在檢測中將審計記錄數據和網絡數據進行預處理及關聯規則挖掘分析,將產生的關聯規則添加到關聯規則庫中去,然后通過關聯規則庫中的規則匹配來判斷用戶行為是否入侵,從而達到提高檢測系統的可擴展性和自適應性,并有效減少漏報率和誤報率.
關聯規則[2]表示數據庫中某種關聯關系的一組對象之間的規則,其數學表達式:X→Y[c,s],X,Y表示數據庫中的記錄,C為確信度,S為支持度.挖掘關聯規則就是將產生支持度和可信度數值分別與預先給定的Min_support和Min_conf相比較,若項集滿足其最小支持度,則稱之為頻繁項集.本文以Snort入侵檢測系統為基礎,提出了利用改進的Apriori算法應用于入侵檢測系統,該算法能夠更為高效的提取用戶行為特征和入侵模式特征,優化了整個系統的性能.
1 相關工作
1.1 Apriori算法
最為經典的關聯規則挖掘Apriori算法,是一種挖掘單維、布爾關聯規則頻繁項目集的算法,由Rakesh Agrawal Rama和krishnan Skrikant于 1993年提出的[3],其算法思想:先掃描數據庫中所有事務,統計每個項集出現的頻繁項,剔除不滿足用戶設定的支持度的項集,得到頻繁1-項集;利用頻繁1-項集的連接,再生成候選2-項集.然后統計每個候選項集的支持計數,得到頻繁項集2-項集的集,如此重復下去,直到得到數據集中的所有頻繁項集.Apriori作為經典的頻繁項目集生成算法,在關聯規則挖掘中具有里程碑的意義,但是隨著研究的進一步深入,它的不足也暴露出來[4]:
1)每生成一個k-頻繁項集(k=1,2,…,k)都需要掃描一次數據庫,如此重復掃描數據庫的算法,對內存占用較大的I/O開銷過大.
2)連接程序中重復相同的項目步驟太多,算法效率有待進一步改進.
3)算法的剪枝步,?c∈C ,判斷Ck的k個(k-1)-子集是否都在Lk中,若存在一個(k-1)-子集不在Lk中,則剔除Ck.此步驟會多次掃描Lk,當Ck很大時,算法的效率明顯低下.
1.2 目前改進算法的研究
許多學者已經開始Apriori算法從不同的層面或不同的策略提出了各種優化算法,主要從減少生成候選項目集的數目及減少對數據庫的掃描次數方面進行優化,如在文獻[5]中作者把支持度低于Min_support對后面的頻繁項集不起作用的事務直接從數據庫中刪除,這樣提高了候選項集的計數速度,在一定程度上優化了算法的效率.文獻[6]中提到在對第K次數據庫掃描中優先適用于每個長度為l(l≥k)的事務來生成候選K-項集,從而減少對數據庫的掃描次數,以提高空間復雜度.王卉,屈強提出基于因子項集的并行化策略GP以發揮串行算法的剪枝功效[7]等,這些改進后的算法挖掘的效率和性能都明顯高于Apriori算法.
2 Apriori算法的改進
由于經典Apriori算法需要循環多次掃描事務數據庫,對生成的候選集Ck中的每個元素都必須通過k循環掃描數據庫來檢驗是否滿足Lk中,這樣占用了大量的的I/O負載.因此,減少兩個項集之間比較的項的個數和減少比較的項集個數,將直接影響后面減少連接的運算量,確保提高運行的效率的關鍵.
因此,本文在對生成的Lk及對支持度的計數中直接剔除不滿足條件的非頻繁項集,對事務數據進行事務壓縮,從而減少Apriori算法中的模式匹配和剪枝步驟,減小掃描事務數據庫的大小,從而提高算法的效率.
2.1 Apriori算法改進的思路
關聯規則挖掘Apriori算法改進的主要思路如下:
1)減少候選集Ck的生成.在掃描數據庫之后,如果事務t不包含Ck中任何一個項集或事務t是Ck中某一項集的子集但不滿足預先給定的min_sup?port,就直接過濾掉.
2)減少判斷次數.通過從Lk-1中提取元素來判斷是否滿足Ck中元素的子集,對Ck中數據項集的子集個數進行統計,從而減少該算法的運算量.
2.2 性質及相關推論
性質1 任何頻繁項集的一切非空子集為頻繁項集,則該項集的非頻繁項集的超集也是非頻繁項集[8].
證明 ?項集X,且X非頻繁項集,即P(X)<min_support,則項集X中的子集i,項集i?X也不是頻繁的,即P( )i?X <min_support,則 Apriori性質滿足反單調性.
性質2 如果頻繁k-1項集存在頻繁k項集,則頻繁k-1項目集的個數必大于等于k.
證明 由性質1可得,Lk生成頻繁k-1項集中必存在k個不同的k-1項子集,因此k-1項集的子集的個數必大于等于k,證畢.
推論1 若頻繁k-項目集還存在X為頻繁項目子集,則X生成的k個k-1維子集中,對?i∈X均存在.
證明 假設?X生成的k個k-1維子集中?i∈e,使 |LK-1(i)|< k-1 |,因為i∈e,則可得i∈X,而根據性質2證明可得知 |LK-1(i) |>k-1,這與假設相矛盾.
此推論在修剪頻繁項集階段應用將有效減少挖掘候選頻繁項集的時間開銷.
2.3 算法描述
根據以上性質和算法改進的思路,設計的改進算法如下:


2.4 算法的分析

1)算法Apriori_ids完成連接,只要對Lk-1進行1次掃描,對于Lk-1中存在元素e,判斷e是否為Ck中元素c的子集,對于小于k則剔除,反之,則對子集C進行計數.這樣避免了對事務的項目進行大量的重復掃描集合和模式匹配計算,在一定程度上提高了算法的時間效率.
2)算法采用的數據結構相對簡單,減少候選項集的迭代操作,避免了其他改進算法中構造復雜的數據結構花費太多的時間,也避免了對相應的數據結構復雜的算法操作,如文獻[5]對矩陣進行相乘運算就比較費時.
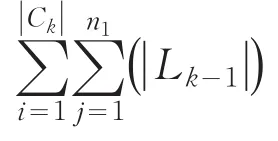
3 改進的算法在IDS中的應用
3.1 入侵檢測系統
根據入侵檢測系統和數據挖掘技術的特征,本文提出了一種基于關聯規則挖掘技術的入侵檢測系統,見圖1[10].
首先通過數據挖掘相關模塊對收集到數據信息進行關聯挖掘,利用改進Apriori算法找出滿足min_support和min_conft的頻繁K-項集,不滿足頻繁項集的,過濾掉,反之生成相應的關聯規則,并利用特征構造算法為模式添加附加特征,送入分類器形成分類規則,通過規則的添加和合并處理,形成入侵規則庫和正常行為規則庫,最后,檢測引擎通過規則相似度和規則匹配比較來檢測入侵.

圖1 基于關聯規則挖掘的入侵檢測模型Fig.1 Model of intrusion detection based on the mining technique of association
3.2 算法仿真實驗分析
為了比較改進Apriori算法與原始Apriori算法之間的運算效率,本文進行了實驗,下面是實驗結果和分析.
試驗測試環境:主頻Intel3.0GHz,內存為2GB,Windows XP的操作系統上進行實驗.
實驗參考數據來源于KDDCup99入侵檢測經典數據集,KDDCup99共有4 898 345條數據記錄,其中正常數據972 780條,覆蓋4種類型的攻擊:Probing 41 102條、R2L90條、Dos 3 883 370條、U2R 1 003條.由于各方面復雜限制,我們這里選擇4個類型8種常見攻擊方式[11]進行實驗,見表1.

表1 實驗攻擊類型Tab.1 Attack date types of experiment
實驗主要基于原Apriori算法和改進Apriori算法在相同數據量不同支持度下的執行效率、以及相同支持度下不同數據量的執行效率.這里我們取最小支持度support=10%,confidence=50%(support(Xi→Yi)=|Xi∪Yi|,confidence(Xi→Yi)=|Xi∪Yi|/|Xi|,其中(Xi,Yi為事務集中同時包含Xi和Yi的事務數),實驗數據見圖2、圖3.
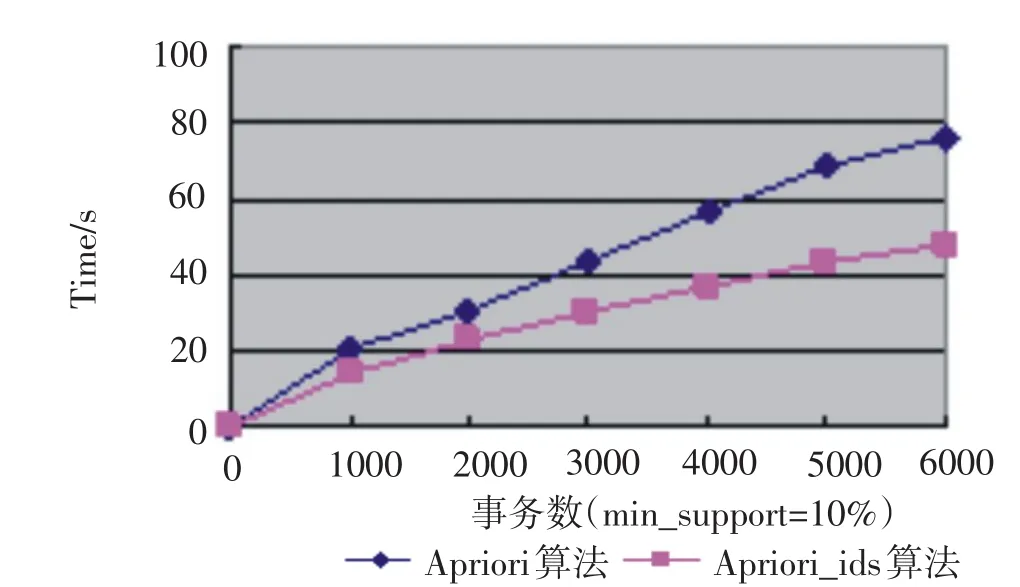
圖3 不同事務規模下算法執行的時間比較Fig.3 The analysis and comparison of the execution time of algorithms under different support degrees
由圖2可以看出,在相同支持度下Apriori_ids算法的時間曲線低于Apriori算法,即得到改進的Apriori_ids算法時間開銷小于Apriori算法,在支持度較小的情況下,效果更明顯.
由圖3可以看出,傳統的Apriori算法隨著頻繁項集數量以及掃描數據集次數增多,執行時間有突變性的增加,而改進的Apriori_ids算法有效地應用了性質2及推論1,過濾了不滿足條件的候選項集,減少了頻繁項集數量以及數據集掃描次數,實驗結果表明,Apriori_ids算法在性能優于Apriori算法,特別在支持度小和數據規模大時.
4 結束語
本文提出一種基于關聯規則挖掘的入侵檢測系統原型,利用改進的Apriori_ids算法,能從大量審計數據中快速提取出規律,有效提高算法的運行效率,解決入侵檢測海量數據挖掘,存儲優化工作,大大提高了入侵檢測系統的性能.隨著網絡的進一步發展,云計算即將成為未來網絡發展方向,而關聯規則的置信度和支持度模型在網絡動態實時化方面表現了不足,對入侵檢測在實時性要求方面較差,因此,如何發展關聯規則對并行計算或分布式計算的支持將是我們繼續努力的主要方面,也是未來發展的趨勢.
[1]Lee W K.A framework for constructing features and mod?els for intrusion detection systems[J].ACM Transactions on Inforrnation and System Security,2000,3(4):227-261.
[2]劉君強,孫曉瑩,潘云鶴.關聯規則挖掘技術研究的新進展[J].計算機科學,2004,31(1):110-113.
[3]Agrawa R,Imielinski T,Swami A.Mining Association Rules Between Sets ofItems in Large Databases[C].Wash?ington DC,USA In Proceedings of the ACM SIGMOD Conf.on Management ofData(SIGMOD’93).New York:ACM Press,1993:207-216.
[4]區玉明,張師超,徐章艷,等.一種提高Apriori算法效率的方法[J].計鋅機工程與設計,2004,25(5):846-848.
[5]Treinen J J,Thurimella R.A framework for the applica?tion of association rule mining in large intrusion detection infras tructures[C].you xiao ming.Recent Advance in In?trusion Detection May 2006.Berlin:Springer Verlag,2006:1-18.
[6]李清峰,楊路明,張曉峰,等.數據挖掘中關聯規則的一種高效的Apriori算法[J].計算機應用與軟件,2004,21(12):84-86.
[7]王卉,屈強.挖掘最大頻繁項集的并行化策略[J].微電子學與計算機,2007,24(9):123-125.
[8]黃進,尹治本.關聯規則挖掘的Apriori算法的改進[J].電子科技大學學報,2003,32(1):76-79.
[9]何海濤,呂士勇,田海燕.基于改進Apriori算法的護數據庫入侵檢測[J].計算機工程,2009,35(16):154-156.
[10]李家春,李之棠.神經模糊入侵檢測系統的研究[J].計算機工程與應用,2001,17:37-38.
[11]王勇,何倩,楊輝華,等.面向連接網絡入侵檢測實驗測試系統的研究[J].計算機應用,2006,26(增刊1):154-156.
Research on the Intrusion Detection Systems Based on the Improved Apriori Algorithm
CHEN Zhen
(Chaozhou Teacher's College,Hanshan Normal University,Chaozhou521012,China)
Main applications of data mining to network intrusion detection are reviewed,It describes the application theory of association rules analysis in network invasion monitoring and the latest research and improvements,and points out the existing problems and the direction for the future research.firstly,the strategy of the join step and the prune step was improved when candidate frequent(k+1)-itemsets were generated from frequent k-itemsets;secondly,the method of dealing with transaction was improved to reduce the time of pattern matching to be used in the Apriori algorithm;in the end,the method of dealing with data base was improved,which lead to only once scanning of frequent k-itemsets during the whole course of the algorithm.The experimental results of the improved algorithm show that the improved algorithm is more efficient than the original.
association rule;frequent itemsets;candidate item set;Apriori algorithm;Apriori_ids algorithm;intrusion detection system
TP 311.131
A
1674-4942(2012)01-0041-05
2011-11-29
黃 瀾
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
財經(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
