改進(jìn)的PrefixSpan算法在客流計數(shù)中的應(yīng)用
2013-04-29 01:53:37王爭,李晉宏
計算機(jī)時代 2013年6期
關(guān)鍵詞:數(shù)據(jù)庫
王爭,李晉宏
摘 要: 序列模式挖掘是基于關(guān)聯(lián)規(guī)則的頻繁項集的挖掘,其實質(zhì)是在關(guān)聯(lián)模型中加入時間屬性。利用改進(jìn)的PrefixSpan算法對客流計數(shù)系統(tǒng)中不同時段的數(shù)據(jù)進(jìn)行挖掘分析,給出不同時段的客流高峰的頻繁序列模式,對于提高客流計數(shù)系統(tǒng)的精度,給管理決策者調(diào)配人力,物力,財力提供技術(shù)支持,對于最大限度地發(fā)掘購物中心的潛力,提高利潤,具有重要的經(jīng)濟(jì)意義。
關(guān)鍵詞: 序列模式挖掘; 關(guān)聯(lián)模型; PrefixSpan算法; 客流計數(shù)
中圖分類號:TP391 文獻(xiàn)標(biāo)志碼:A 文章編號:1006-8228(2013)06-50-03
Application of improved PrefixSpan algorithm in counting passenger flow
Wang Zheng, Li Jinhong
(North China University of Technology, Beijing 100144, China)
Abstract: Sequential pattern mining is a frequent item sets mining based on association rules, and its essence is to add the time attribute to the relation model. In this paper, data in different times of passenger flow counting system is mined and analyzed by the improved PrefixSpan algorithm. Frequent sequential patterns of the peak passenger flow in the different periods are given. It has important economical meaning for improving passenger flow counting system accuracy, providing technical support for the managers to allocate human, material and financial resources, maximizing the potential of the shopping center, and increasing profits.
Key words: sequential pattern mining; correlation model; PrefixSpan algorithm; passenger flow counting
0 引言
客流、物流、財流是購物中心、公園、娛樂場等成功的三大因素。其中客流是公認(rèn)的各個場所經(jīng)營管理重要的衡量工具。因為顧客、游客是貨幣的攜帶者,也是商品的潛在購買者,研究其流量的規(guī)律,可以增加銷售機(jī)會,將他們由觀察者轉(zhuǎn)變?yōu)橘徫镎撸梢宰畲笙薅鹊赝诰蛸徫镏行牡匿N售潛力,增加利潤。
購物中心與傳統(tǒng)的百貨業(yè)、廉價的超級市場和全天候服務(wù)的便利店的經(jīng)營管理模式都不盡相同。現(xiàn)代購物中心采用的是一種先進(jìn)的經(jīng)營管理模式,需要先進(jìn)的觀念配合科技和技巧方能成功。現(xiàn)代購物中心的設(shè)計、運作和管理突破了傳統(tǒng)的零售業(yè)的種種局限,成功依賴于理念、策略與科技。 購物廣場的開發(fā)目標(biāo)是追求物業(yè)升值最大化和店鋪租金持續(xù)升值最大化。越來越多的購物中心把自營部分和出租部分的比例相對調(diào)整了很多,更多的購物中心采取的經(jīng)營策略是只租不售,統(tǒng)一管理。零售業(yè)要想把利益最大化的經(jīng)營方式和理念逐步擴(kuò)展,逐步規(guī)范化,就必須關(guān)注客流、物流、財流三個關(guān)鍵因素。如何去獲取準(zhǔn)確的客流數(shù)據(jù),以及確定客流的高峰時段,深層挖掘,準(zhǔn)確反映客流量變化趨勢,為經(jīng)營管理提供準(zhǔn)確及時的數(shù)據(jù)參考依據(jù)來訂制營商策略,是一個有價值的研究課題。
1 序列模式挖掘
序列模式的概念最早是由Agrawal和Srikant提出的[1],是挖掘相對時間或其他模式出現(xiàn)頻率高的模式。給定一個由不同序列組成的集合,其中,每個序列由不同的元素按順序有序排列,每個元素由不同項目組成,同時給定一個用戶指定的最小支持度閾值,序列模式挖掘就是找出所有的頻繁子序列,即該子序列在序列集中的出現(xiàn)頻率不低于用戶指定的最小支持度閾值。
序列模式挖掘是指從序列數(shù)據(jù)庫中挖掘出頻繁序列模式,為此需要將數(shù)據(jù)庫轉(zhuǎn)換為序列數(shù)據(jù)庫。方法是把用戶ID相同的記錄合并,有時每個事務(wù)的發(fā)生時間可以忽略,僅保持事務(wù)間的偏序關(guān)系。
項集(Itemset)是所有在序列數(shù)據(jù)庫出現(xiàn)過的單項組成的集合。
元素(Element)可表示為(x1,x2…xm),xk(1<=k<=m)為不同的單項。元素內(nèi)的單項不考慮順序關(guān)系,一般默認(rèn)按照ID的字典序排列。
序列(Sequence)是不同元素(Element)的有序排列,序列s可以表示為s=
一個序列包含的所有單項的個數(shù)稱為序列的長度。長度為l的序列記為l-序列。
設(shè)序列α= 2 PrefixSpan算法 該算法的基本思想是:采用分治的思想,不斷產(chǎn)生序列數(shù)據(jù)庫的多個更小的投影數(shù)據(jù)庫,然后在各個投影數(shù)據(jù)庫上進(jìn)行挖掘。
基于該算法的相關(guān)定義如下。
⑴ 前綴:設(shè)每個元素中的所有項目按照字典序排列。給定序列α=
⑵ 投影:給定序列α和β,如果β是α的子序列,則α關(guān)于β的投影α'必須滿足:β是α'的前綴,α'是α的滿足上述條件的最大子序列。
⑶ 投影數(shù)據(jù)庫:設(shè)α為序列數(shù)據(jù)庫S中的一個序列模式,則α的投影數(shù)據(jù)庫為S中所有以α為前綴的序列相對于α的后綴,記為S|α。
⑷ 投影數(shù)據(jù)庫中的支持度:設(shè)α為序列數(shù)據(jù)庫S中的一個序列,序列β以α為前綴,則β在α的投影數(shù)據(jù)庫S|α中的支持度為S|α中滿足條件b?α.γ的序列γ的個數(shù)。
3 改進(jìn)的PrefixSpan算法[3]
在基本算法過程中,我們發(fā)現(xiàn)構(gòu)建投影數(shù)據(jù)的數(shù)量是先增加后減少的一個狀態(tài),而且投影數(shù)據(jù)庫的數(shù)量跟頻繁項的位置有很大關(guān)系,所以針對投影數(shù)據(jù)的縮減,我們使用如下幾種方法改進(jìn)算法,提升效率。
3.1 偽投影技術(shù)
所有的投影數(shù)據(jù)庫都以索引的形式給出,我們只給定一個初始的序列數(shù)據(jù)庫A,然后所有中間過程都記錄其下標(biāo)的位置,然后利用下標(biāo)去原始庫A中查找該字符序列。
3.2 PSD優(yōu)化算法
首先找出各個頻繁單項,產(chǎn)生每個頻繁項對應(yīng)的投影數(shù)據(jù)庫集合。因為非頻繁項出現(xiàn)次數(shù)已小于最小支持?jǐn)?shù)。在其后的挖掘中也不會成為頻繁項,故只保存掃描該投影數(shù)據(jù)庫時得到的頻繁項。然后對每個投影數(shù)據(jù)庫進(jìn)行單獨挖掘,之前先比較該投影數(shù)據(jù)庫所包含的序列數(shù)和最小支持?jǐn)?shù),若投影序列數(shù)小于最小支持?jǐn)?shù),將不會再有超過最小支持?jǐn)?shù)的頻繁項,則退出對該投影數(shù)據(jù)庫的進(jìn)一步挖掘。因為舍棄了非頻繁項,將大大減少保存投影數(shù)據(jù)庫所需內(nèi)存空間,也將減少其后挖掘中掃描不必要項的時間,提高了算法執(zhí)行效率。因為在對投影數(shù)據(jù)庫進(jìn)行挖掘前,先比較了其包含的序列數(shù)和最小支持?jǐn)?shù),放棄挖掘序列數(shù)已小于最小支持度的投影數(shù)據(jù)庫,減少了掃描不可能出現(xiàn)頻繁序列的投影數(shù)據(jù)庫的時間,提高了算法執(zhí)行效率。
3.3 IPMSP優(yōu)化算法
在構(gòu)建投影數(shù)據(jù)庫時,通過檢查序列數(shù)據(jù)庫關(guān)于前綴的前綴,避免對投影數(shù)據(jù)庫中同一頻繁前綴重復(fù)投影,減少投影的次數(shù)和數(shù)量,并且節(jié)省重復(fù)投影數(shù)據(jù)庫的構(gòu)造時間和在投影數(shù)據(jù)庫上挖掘模式浪費的時間。同時,在PrefixSpan算法執(zhí)行過程中,由于在投影序列數(shù)小于最小支持?jǐn)?shù)的投影數(shù)據(jù)庫中,將不會出現(xiàn)超過最小支持?jǐn)?shù)的頻繁項,因此在IPMSP算法中只保存掃描投影數(shù)據(jù)庫時得到的頻繁項,通過比較投影數(shù)據(jù)庫所包含的序列數(shù)和最小支持?jǐn)?shù),放棄挖掘序列數(shù)已小于最小支持?jǐn)?shù)的投影數(shù)據(jù)庫,提前退出對投影數(shù)據(jù)庫的進(jìn)一步挖掘,減少掃描不可能出現(xiàn)頻繁序列的投影數(shù)據(jù)庫的時間,從而提高算法執(zhí)行效率。
3.4 改進(jìn)PrefixSpan算法實現(xiàn)
⑴ 得到長度為l的序列模式。首先要掃描s,找出所有的頻繁項,每個頻繁項都是一個長度為I的序列模式,并將頻繁項按其支持度從大到小排序。
⑵ 根據(jù)頻繁項支持度的大小,依次對頻繁項進(jìn)行投影,通過構(gòu)建相應(yīng)的投影數(shù)據(jù)庫并遞歸地挖掘每一個來進(jìn)行挖掘。其中對每一個頻繁項,構(gòu)建相應(yīng)的投影數(shù)據(jù)庫,對投影數(shù)據(jù)庫掃描一次,得到其局部頻繁項。如果局部頻繁項與第1步得到的除當(dāng)前頻繁前綴記為α以外的頻繁項相同,記為β,對第l步中的投影數(shù)據(jù)庫作關(guān)于β前綴的投影,判斷是否可以減少β重復(fù)投影及其挖掘。如果條件滿足,則只挖掘β前綴的序列模式一次,即得到β為前綴的序列模式的同時可以得到α連接β列模式。在找到原投影數(shù)據(jù)中對應(yīng)于該頻繁項的所有后綴集合后,保存該頻繁項的投影數(shù)據(jù)庫,之后只保存在掃描原投影數(shù)據(jù)庫時得到的支持?jǐn)?shù)大于min_sup的項,若該頻繁項的投影數(shù)據(jù)庫所含序列數(shù)小于min_sup,則結(jié)束在投影數(shù)據(jù)庫中繼續(xù)挖掘。
4 挖掘的數(shù)據(jù)準(zhǔn)備
4.1 數(shù)據(jù)來源
挖掘所需的數(shù)據(jù)來源于某大型購物中心的客流自動統(tǒng)計系統(tǒng)。
4.2 挖掘的數(shù)據(jù)準(zhǔn)備
首先作數(shù)據(jù)預(yù)處理。數(shù)據(jù)預(yù)處理有多種方法:數(shù)據(jù)清理,數(shù)據(jù)集成,數(shù)據(jù)變換,數(shù)據(jù)歸約等。這些數(shù)據(jù)處理技術(shù)在數(shù)據(jù)挖掘之前使用,大大提高了數(shù)據(jù)挖掘模式的質(zhì)量,降低實際挖掘所需要的時間。
利用數(shù)據(jù)離散化算法將原始數(shù)據(jù)庫中的實時具體的數(shù)據(jù)轉(zhuǎn)化為所需的抽象的序列數(shù)據(jù),也是將事務(wù)數(shù)據(jù)庫轉(zhuǎn)化為挖掘所需的序列數(shù)據(jù)庫。
將原始數(shù)據(jù)提取出來后進(jìn)行分析處理,轉(zhuǎn)化為序列模式挖掘所需的數(shù)據(jù)格式,即轉(zhuǎn)化為序列數(shù)據(jù)。由于原始數(shù)據(jù)庫中存儲的數(shù)據(jù)是具體的實時數(shù)據(jù),需要轉(zhuǎn)為挖掘所需的抽象的序列數(shù)據(jù)庫。
對原始數(shù)據(jù)的處理辦法:首先對源數(shù)據(jù)進(jìn)行規(guī)范化,然后進(jìn)行離散化處理。
數(shù)據(jù)規(guī)范化:將提取的數(shù)據(jù)逐條分析,對于空值記錄執(zhí)行刪除操作。
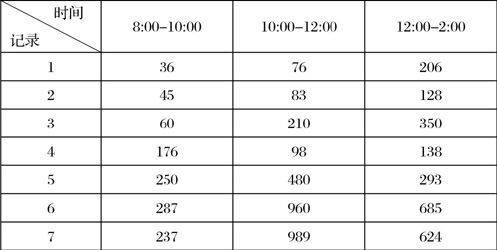
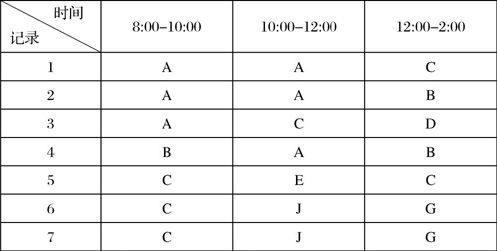
數(shù)據(jù)離散化:利用區(qū)間劃分法進(jìn)行離散化。所謂的區(qū)間劃分法:就是將數(shù)據(jù)的值域劃分為不同的區(qū)間,將具體的數(shù)據(jù)抽象為屬于某個區(qū)間,該區(qū)間用一個抽象的字母所表示,組成一個序列。例如:某個變量的值域為1-9,將其劃分為3個區(qū)間,1-3,4-6,7-9,所有屬于1-3區(qū)間的數(shù)值用A表示,所有屬于4-6區(qū)間的數(shù)值用B表示,所有屬于7-9區(qū)間的用C表示。而對于具體的值如2,2.5,3,4.1,5,6,7,8.5,9則可以分別表示為A,A,A,B,B,B,C,C,C。也就是說將具體的值分別劃分到不同的區(qū)間中去,進(jìn)而實現(xiàn)數(shù)據(jù)的離散化處理。區(qū)間劃分法進(jìn)行數(shù)據(jù)離散化處理可用下面的圖表示出來,劃分標(biāo)準(zhǔn)是0-100用A表示,101-200用B表示,201-300用C表示,301-400用D表示,以此類推。
表1和表2給出了部分原始數(shù)據(jù)及離散化結(jié)果。
表1 部分原始數(shù)據(jù)
5 挖掘結(jié)果及分析
給定支持度為2,根據(jù)表2的離散化數(shù)據(jù)挖掘出的頻繁模式為:AA,CJG,CJ,CG。
表2 離散化后的數(shù)據(jù)
通過實驗挖掘出的頻繁序列子模式可以分析某商場在周末的8:00到下午2:00的客流量都很大,而在周一,周二上午8:00到10:00客流都比較少,根據(jù)挖掘結(jié)果找到客流高峰時段的頻繁序列,用于預(yù)測購物中心客流的高峰時段,給管理人員提供調(diào)配人力,物力,財力等決策提供支持,以利于最大限度的挖掘購物中心的潛力,提高效率,增加經(jīng)濟(jì)效益。
參考文獻(xiàn):
[1] JiaWei Han, Micheline Kamber.數(shù)據(jù)挖掘概念與技術(shù)[M].機(jī)械工業(yè)
出版社,2001.
[2] 趙華,宋順林.改進(jìn)的序列模式挖掘算法在交叉營銷中的應(yīng)用[J].計
算機(jī)工程于設(shè)計,2007.3.
[3] 吳南,胡學(xué)剛.基于PrefixSpan序列模式挖掘的一種改進(jìn)算法[J].電
腦知識與技術(shù),2007.4.
[4] 汪林林,范軍.基于PrefixSpan的序列模式挖掘改進(jìn)算法[J].計算機(jī)
工程,2009.12.
猜你喜歡
財經(jīng)(2017年15期)2017-07-03 22:40:49
財經(jīng)(2017年2期)2017-03-10 14:35:35
華東師范大學(xué)學(xué)報(自然科學(xué)版)(2017年1期)2017-02-27 13:41:08
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
財經(jīng)(2015年3期)2015-06-09 17:41:31
財經(jīng)(2014年21期)2014-08-18 01:50:18
財經(jīng)(2014年6期)2014-03-12 08:28:19
財經(jīng)(2013年6期)2013-04-29 17:59:30
