適用于新媒體事件聚類模型的混合算法研究
2013-07-03 00:45:02孫玲芳李金海
計算機工程與設計 2013年4期
孫玲芳,李金海
(江蘇科技大學 經濟管理學院,江蘇 鎮江 212003)
0 引 言
從2003年的SARS事件開始,新媒體事件逐步呈現在公眾的視野中,并在近幾年里爆發頻率不斷提高,使得人們認識到了新媒體事件的嚴重性,對新媒體事件的預警研究也成為網絡安全領域的熱點。對新媒體事件的預警就是在新的新媒體事件未爆發之前,依據某種策略對它進行分類,分在不同類中的新媒體事件有著不同的處理措施,確保新媒體事件的及時發現以及妥善的處理。
目前常用的聚類方法有:層次法、劃分法、網格法以及密度法。其中被學者廣泛認可的K_Means算法是一種基于劃分的聚類算法;而另一種啟發式全局尋優算法即遺傳算法(genetic algorithm,GA)近幾年也被大量學者研究。文獻[1]采用K_Means算法作為聚類模型的主要算法,提出了一種運算速度快,準確性高的數據挖掘方法[1];文獻[2]將遺傳算法和最近鄰算法動態結合,得到了一種更優秀的聚類算法[2];文獻[3]發現遺傳算法與蟻群算法的融合,較單獨的遺傳算法或蟻群算法,有著更好的聚類效果[3]。可見算法融合已經成為構建更為優秀的聚類算法的方法,為本文的研究提供了理論依據。
1 聚類分析的原理
聚類分析是將多個樣本對象組成的集合,按相似性分成多個簇,性質相近的歸為同一個簇,使得分在同一簇中的對象具有最大的同質性,而分在不同簇中的對象具有最大的異質性的過程。聚類分析的一般過程如圖1所示。
聚類算法的選擇需要依據聚類的目的以及樣本表示的數據類型來判斷,而且在有些聚類問題中單個算法已不能滿足算法的精度要求,這時就需要將兩個或兩個以上的算法相結合以達到更佳的效果。
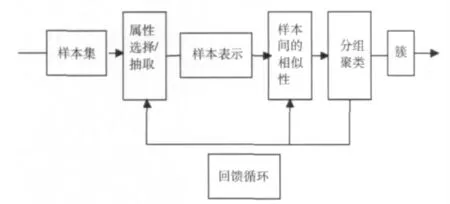
圖1 聚類分析的一般過程
1.1 K_Means的原理
聚類算法有動態與靜態之分,動態聚類算法與靜態聚類算法的主要區別在于通過不斷的迭代來完成聚類,且在迭代過程中允許樣本從一個簇中轉移到另一個簇中。K_Means算法就屬于動態聚類法,因此它也具有動態聚類法的迭代特點[4]。動態聚類法過程如圖2所示。

圖2 動態聚類法過程
K_Means算法是一種基于劃分的常見的聚類算法,一般采用誤差平方(均方差)作為標準測度函數。具體算法描述為:
Data[n],k;
(1)C[1]=data[1],c[2]=data[2]…c[k]=data[k];/隨機選取k個初始中心;
(2)對于data[1],data[2]…data[n],分 別 與c[1],c[2]…c[k]比較,若與c[i]差值最小,就標記為i;
(3)對于所有標記為i的樣本,重新計算c[i]={∑所有標記為i的data/標記為i的個數};
(4)重復(2)、(3),直到所有c[i]值的變化小于給定閥值。
標準測度函數為
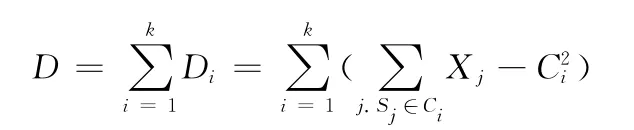
式中:Di——c[i]中的Xk與相應的聚類中心的度量即歐幾里德距離[5]。D——歐幾里德距離之和,聚類的目的是使得非相似性(或距離)指標的目標函數達到最小,即D最小。
雖然K_Means算法應用廣泛,但該算法也有一定的局限性,該方法最終結果受初始值影響較大,結果較易陷入局部最優,且對孤立點敏感。
1.2 遺傳算法的原理
在預警系統中,新媒體信息來源廣泛、內容繁多,一般的聚類算法不能較好的處理,通過研習大量的文獻發現,遺傳算法適合新媒體事件的聚類分析。早在20世紀70年代就有人提出了遺傳算法,算法原理是模擬自然界生物的遺傳變異的進化過程,通過遺傳算子來體現遺傳算法的思想,是一種啟發式全局尋優算法[6]。遺傳算法的思想是基于遺傳規律與自然選擇。
遺傳算法處理的對象是染色體,每條染色體都是問題的一個解,算法的最終目的是選出最適應環境的染色體,即最優解。遺傳算法中的樣本組成了群體,個體對環境的適應程度稱為適應度。在執行遺傳算法前,需要進行編碼操作:把搜索空間中的數據轉換成遺傳空間中的染色體;在執行遺傳算法后,需要進行譯碼操作:把染色體轉換為問題原來的數據類型。
雖然遺傳算法具有很好的處理約束,能很好的跳出局部最優,最終得到全局最優解以及全局搜索能力強等諸多優點;但遺傳算法全局搜索的特點也使得算法時間復雜度較大,不符合新媒體事件預警系統的及時性。
2 聚類算法的改進
在分析K_Means與遺傳算法的基礎上,發現K _Means算法以及遺傳算法都較適用于新媒體事件的聚類模型構建,而它們各自存在的不足也正好被另一種算法所填補,若能將二者合理的結合,克服各自的劣勢,發揮各自的優勢,必是一個優秀的適應新媒體事件聚類的算法。基于此,本文提出了混合K均值遺傳算法(genetic algorithm with K_Means,GAWKM)的概念。此算法是基于K_Means算法和遺傳算法原理的設想,結合K-Means算法的局部搜索能力與遺傳算法的全局搜索能力,最終得到全局最優解,并且算法的時間復雜度在規定范圍之內。
2.1 混合K均值遺傳算法的原理
在混合K均值遺傳算法中,選擇過程通過輪盤賭算法實現,并采用最優保存策略保留上代中個體適應度達種群平均適應度1.5倍或以上(若種群規模較大,可適當增大倍數,可加快算法的收斂速度)的個體進入下一代的父代,缺少的子代則以隨機方式產生,最大程度保證了混合K均值遺傳算法的收斂[7]。交叉操作則采用單點交叉。通過仿真實驗發現,變異是遺傳算法能跳出局部最優的關鍵操作,而變異概率決定著變異的效果,因此,讓變異概率隨著群體的平均適應度不斷向最優個體的適應度接近時,就自適應地動態增大。
2.2 混合K均值遺傳算法的具體流程
混合K均值遺傳算法的具體流程如下:
設樣本總數為n;聚類簇即聚類中心數為k(2≤k≤n-1);交叉概率Pc,變異概率Pm,最大遺傳代數genmax,已迭代數gen,適應度閥值F。
(1)選擇編碼策略:在混合K均值遺傳聚類算法中,每一條染色體都必須表示所有個體應屬于哪類,所以染色體采用自然數編碼為佳[8];設染色體Y=(G1,G2,…,Gn),Y為1×n維向量,Gi為Y 上第i位的基因,其中:
RandomGi,
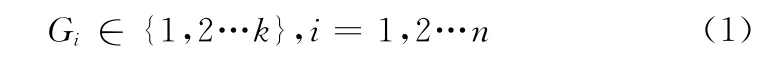
/基因Gi為k類中的某類
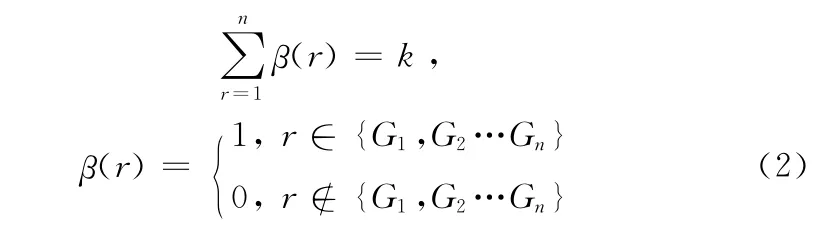
/基因的取值覆蓋所有聚類號,保證每條染色體都有效
在模型中,運用式(1)隨機產生Gi,運用式(2)循環判斷,若條件式(2)未滿足時,須重置Gi。
(2)定義適應度函數:適應度函數的好壞很大程度上影響遺傳算法的迭代次數與效果。本文采用“界限構造法”[9]
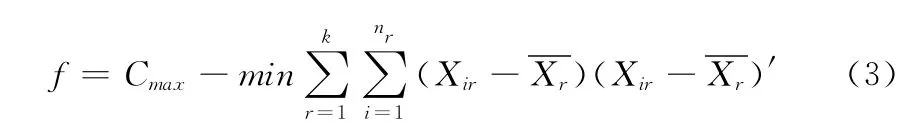
為適應度函數(fitness function);其中
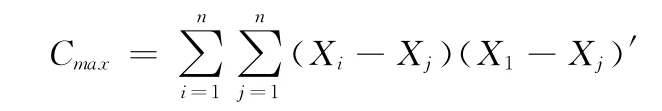
將求最小極值問題轉化為求最大極值問題,可以在選擇操作中直接使用輪盤賭算法。
/保留初始群體中適應度最大的個體
(3)用K_Means算法對每個個體進行優化gen++;
/每迭代一次,已迭代數gen加一操作
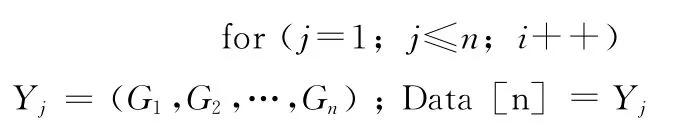
/Yj為第j條染色體
優化后,得到新的Yj=(G1,G2,…,Gn)。
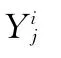
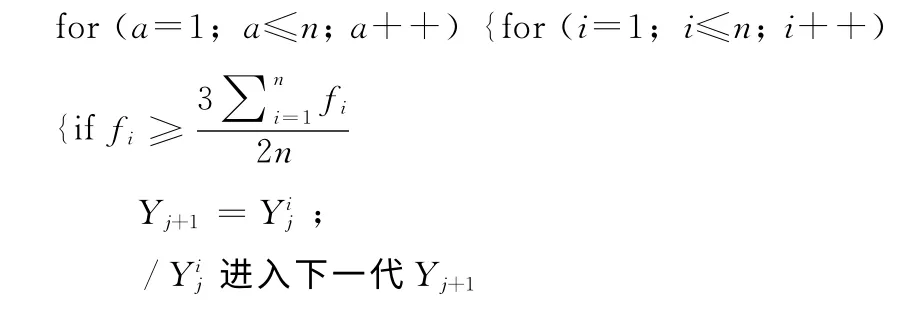
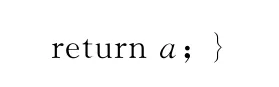
/a為采用最優保存策略保留的進入下代個體數}通過輪盤賭算法選擇剩下的父代:
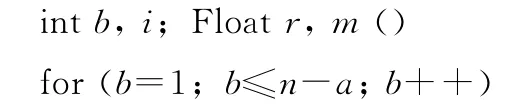
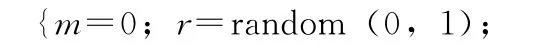
/r為0至1的隨機數
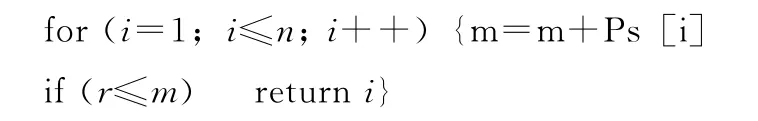
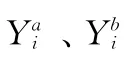
int c;c=random(1,n);
/在染色體中隨機選擇第c位的基因作為交叉點
在交叉操作中采用“基于最短距離基因匹配的算術交叉。”[10]
需要注意的是,在這個學習過程中,無論語言也好還是文學作品也好,其中都包含了很多來自西方國家的價值取向,包括價值觀、人生觀的不同觀念影響,學生在整體的學習過程中很容易將其混淆,形成一種盲目崇拜和向往的思想,進而影響到自己對于價值觀、人生觀、世界觀的基礎判斷。因此,在英美文化教學開展的過程中,融入對于思想政治教育的強調,使其引領英美文化教學進一步開展是極為必要的[2]。
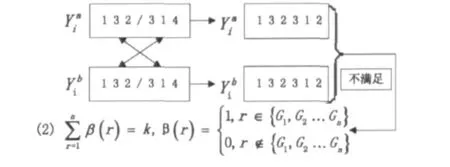
圖3 傳統交叉操作
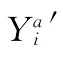
而基于最短距離基因匹配的算術交叉,就能夠彌補傳統交叉操作的這一不足。操作過程如下:
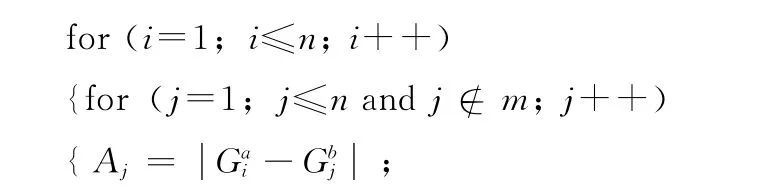
minAj;
/比較出最短距離,并記錄是最短距離的那位基因j
j∈m;
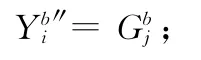
這種交叉方法能夠改進遺傳算法的收斂性,防止無意義個體的產生,加快聚類速度。
(6)變異操作(Mutation)
采用單點變異,變異概率Pm隨著群體的平均適應度不斷向最優個體的適應度接近時,就自適應地動態增大[11],設定
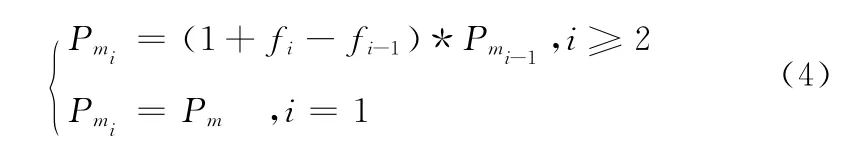
按新的變異概率Pmi,選擇染色體Yai,在Yai上隨機選擇一個基因位c,并按式(5)變異
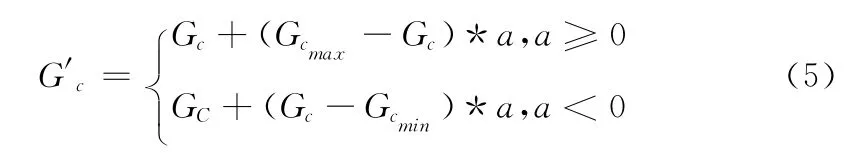
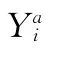
/保留新一代群體中適應度最大的個體
(7)判斷算法是否結束
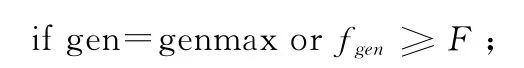
/達到最大代數或滿足適應度要求
to(8);
/執行步驟(8)
else continue(3);
/否則跳到步驟(3)
(8)用K_Means算法對最優個體優化
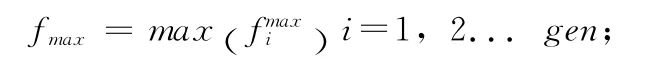
/找出每代最優個體中適應度最大個體
Y=(G1,G2,…,Gn),其中Data[n]=Y
/Y為fmax對應的染色體
優化后,得到新的Y=(G1,G2,…,Gn)
/得到的Y 即為最終的最優個體
(9)輸出結果:Y=(G1,G2,…,Gn)
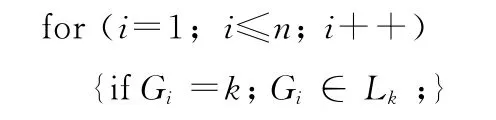
/將基因值譯碼成類的編號
3 仿真實驗
我們運用MATLAB7.0編譯混合K均值遺傳算法,實驗數據選取百度百科收錄的,近幾年(2009、2010、2011年)發生的新媒體事件50個,作為訓練樣本,并按時間順序從1-50進行標記。具體樣本文件信息如圖4所示。

圖4 樣本文件信息
經統計,上述50個新媒體事件的時間分布如表1所示。

表1 時間分布
通過對上述50個以及其它的新媒體事件的分析發現,新媒體事件大致分為以下四類:
(1)對社會的發展與穩定有利的事件;
(2)屬于廣大網民自娛自樂的事件;
(3)對社會的發展與穩定有一定負面影響的事件;
(4)嚴重影響社會的發展與穩定的事件。
因此本文設定聚類數K=4;樣本總數n=50;交叉概率Pc=0.7,變異概率Pm=0.01,最大遺傳代數genmax=200,已迭代數gen,適應度閥值F=0.05。
其中新媒體事件的文本信息通過向量空間模型轉換為計算機能夠識別形式[12],表示為:
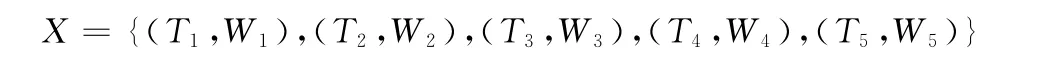
其中,X為新媒體事件的影響度值,Ti表示第i個特征項的值,Wi表示特征項Ti的向量權重,特征項為文本中重要的詞語,向量權重通過詞頻加權法計算得來,即某一特征項在文本中出現次數越多,Wi越大。向量空間模型經過特征降維降為5維,這5個特征項是文本中出現次數最多的5個詞,Ti的具體數值與它的語義強度直接相關。有關轉換向量空間模型的具體過程這里不再詳述。50個新媒體事件的影響度在坐標軸上的分布如圖5所示。
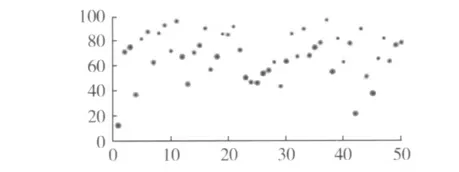
圖5 樣本分布
橫軸表示樣本的序號,縱軸表示樣本的影響度值。
將算法及樣本數據輸入MATLAB7.0,得到最優解Y=(1,3,3,1,4,4,3,4,4,3,4,3,2,3,3,4,2,3,4,4,4,3,2,2,2,2,2,3,2,3,4,3,4,3,3,3,4,2,4,3,3,1,4,2,1,3,4,3,3,3);
聚類之后的樣本分布圖如圖6所示。
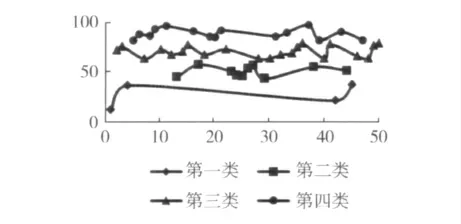
圖6 樣本聚類分布
具體聚類結果見表2。
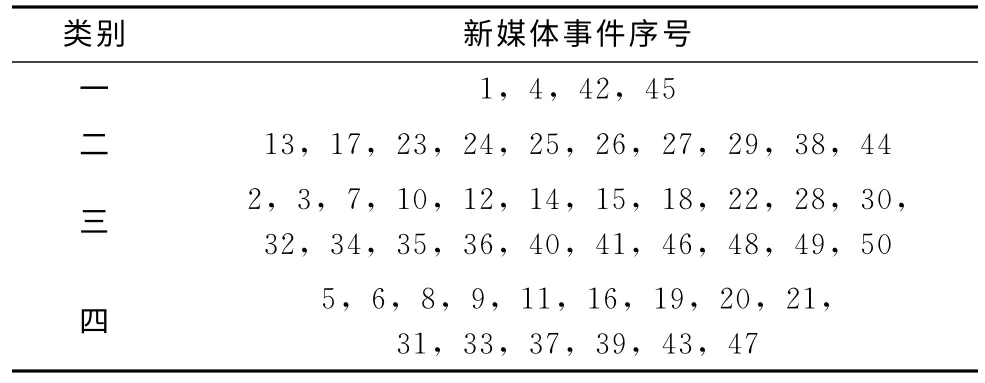
表2 聚類結果
通過對聚類結果進行分析,發現第6,23,31,36,40,50個新媒體事件的分類結果,與各大媒體最終對這些新媒體事件的評價有所不同。如分在第三類的40。郭美美事件,本身是一個炫富事件,應該說對社會的發展與穩定影響不大,但由于之后關聯了紅十字的一系列問題,使得國內一時陷入了慈善荒,最終使事件升級為第四類新媒體事件。經過試驗后的再次分析,發現這6個事件的誤判,是由于新媒體事件文本信息的不完善以及語義強度判斷算法還不夠精確所致。
第一類新媒體事件屬于對社會的發展與穩定有利的事件,此類事件不需要有關部門的刻意引導,適當的褒獎可以弘揚社會風氣;第二類新媒體事件屬于廣大網民自娛自樂的事件,一般此類事件不需要特別的關注,它們會隨著時間的流逝,讓公眾逐漸淡忘;第三類新媒體事件屬于對社會的發展與穩定有一定負面影響,這類事件就需要有關部門及時做出正確的引導,防止發展成為第四類事件;而第四類新媒體事件的爆發則會嚴重影響社會的發展與穩定,輕則擾亂社會治安,重則造成人員傷亡,對于這類事件,及時正確的官方引導是重點,而給予那些惡意煽動民意的幕后黑手相應的處罰則是輔助措施。經過對四類新媒體事件的分析,我們發現某個事件的從屬關系,并不是一成不變的,有關部門及時正確的引導能夠讓事件走向良性的發展方向,反之亦然。
本次仿真試驗的結果正確率約為88%,應該說還較為理想。而導致誤差的大部分原因將在今后的研究中不斷完善。
4 結束語
通過將遺傳算法與K_Means算法有效結合,提出了混合K均值遺傳算法,并合理運用界限構造法、最優保存策略、基于最短距離基因匹配的算術交叉以及變異概率的自適應改變等方法,在一定程度上解決了遺傳算法的收斂較慢、不適于處理復雜數據,以及K_Means算法易于陷入局部最優解、對孤立點敏感的不足。通過仿真試驗,發現試驗結果正確率較為理想,說明混合K均值遺傳算法適用于新媒體事件的聚類模型構建,但此算法在前期的數據收集以及文本信息向計算機能識別的數據轉換精確度方面還不夠完善,在后期的研究中還有待改善。
[1]ZHOU Lijuan,SHI Qian,GE Xuebin,et al.Cluster-based evaluation in fuzzy-genetic data mining[J].Computer Engineering and Applications,2010,46(13):118-121(in Chinese).[周麗娟,石倩,葛學彬,等.基于聚類的模糊遺傳挖掘算法的研究[J].計算機工程與應用,2010,46(13):118-121.]
[2]LU Linhua.A novel dynamic clustering algorithm based on genetic algorithm[J].Computer Simulation,2009,26(7):122-125(in Chinese).[陸林花.一種新的基于遺傳算法的動態聚類算法[J].計算機仿真,2009,26(7):122-125.]
[3]ZHU Feng,CHEN Li.Research on clustering algorithm based on fusion of ant colony and genetic algorithm[J].Journal of Northwest University(Natural Science Edition),2009,39(5):745-749(in Chinese).[朱峰,陳莉.蟻群與遺傳算法融合的聚類算法研究[J].西北大學學報(自然科學版),2009,39(5):745-749.]
[4]Nazim Dugan,Sakir Erkoc.Genetic algorithm application to the structural properties of si-ge mixed clusters[J].Materials and Manufacturing Processes,2009,24(3):250-254.
[5]LIU Hailin.Research of web user clustering model based on genetic algorithm[D].Tianjin:Tianjin University of Technology,2007:7-14(in Chinese).[劉海琳.基于遺傳算法的Web用戶聚類模型的研究[D].天津:天津理工大學,2007:7-14.]
[6]QIN Junhua,ZHANG Hongwei,ZHAO Shizheng.Fuzzy clustering analysis based on genetic algorithm and its application[J].Computer Applications,2007,27(1):52-55(in Chinese).[覃俊華,張洪偉,趙世政.基于遺傳算法的模糊聚類研究及其應用[J].計算機應用,2007,27(1):52-55.]
[7]SU Liangyu,SU Liangbi.Cluster analysis based on genetic algorithm[J].Computer Development and Application,2011,24(2):7-9(in Chinese).[蘇良昱,蘇良碧.基于遺傳算法的聚類分析[J].電腦開發與應用,2011,24(2):7-9.]
[8]SHENG Weiguo,Allan Tucker,LIU Xiaohui.A niching genetic k-means algorithm and its applications to gene expression data[J].Soft Computer,2010,14(11):9-19.
[9]LOU Yuansheng,TAO Zhenhong.Web service composition algorithm for QoS global optimization[J].Computer Engineering and Applications,2011,47(8):207-210(in Chinese).[婁淵勝,陶振宏.Web服務組合QoS全局優化算法[J].計算機工程與應用,2011,47(8):207-210.]
[10]LI Long1ong,WANG Mei1i.Research on an adaptive genetic algorithm based on weighted binary tree[J].Computer Technology and Development,2010,20(11):95-99(in Chinese).[李龍龍,王美麗.基于加權二叉樹的自適應遺傳算法研究[J].計算機技術與發展,2010,20(11):95-99.]
[11]ZHENG Yu,CHEN Zhuangzhuang,LI Yajuan,et al.New automatic alignment technology for single mode fiberwaveguide based on improved genetic algorithm[J].Optoelectronics Letters,2009,5(3):165-168.
[12]JING Liping,Michael K Ng,Joshua Z Huang.Knowledgebased vector space model for text clustering[J].Knowledge and Information Systems,2010,25(1):35-55.
