井間示蹤測試組合解釋方法研究
2013-07-25 03:57:32劉同敬第五鵬祥姜寶益
中國礦業 2013年1期
關鍵詞:優化
劉同敬,第五鵬祥,姜寶益,劉 睿,孫 利,8
(1.中國石油大學 (北京)提高采收率研究院,北京 102249;2.中石油三次采油重點實驗室,北京 102249;3.北京市溫室氣體封存與資源化利用重點實驗室,北京 102249;4.中國石油大學 (北京)石油工程教育部重點實驗室,北京 102249;5.中國地質大學 (北京)能源學院,北京 100083;6.中國華電集團科學技術研究總院,北京 100035;7.中國石油大學 (北京),北京 102249;8.中國產業安全研究中心,北京 100044)
在建立的數學模型、求解方法的基礎上,確定了自變量,建立了目標函數,利用改進的遺傳算法,完成示蹤測試曲線的擬合和油藏參數解釋,形成了井間水相示蹤測試解釋流程[1-3]。由于井間示蹤測試解釋涉及的參數較多,過程較為復雜,因此,參數解釋過程利用最優化方法完成。
1 目標函數建立
首先,根據研究的問題確定了參數自變量。對于井間示蹤測試解釋,通過區塊所有曲線同時擬合直接得到的主要參數如下所示[4-8]。
1)不同井組示蹤劑產出通道的分布情況。人為設定高滲通道數目上限的情況下,由算法通過曲線擬合,確定具體的高滲通道數目及其垂向分布情況。
2)不同井組平面流線上示蹤劑突破的情況。平面流線的突破條數對濃度曲線的上升、下降情況影響大。
3)不同井組各個高滲通道不同流線上的厚度。高滲通道的厚度對產出濃度的峰值影響較大,同時會影響產出時間以及濃度曲線分布情況。
4)不同井組各個高滲通道不同流線上的滲透率。高滲通道的滲透率對見劑時間影響較大,同時會影響到產出濃度峰值和濃度曲線分布情況。
5)雙示蹤劑測試時,確定高滲通道剩余油飽和度的分布。
由于地下情況復雜、自變量較多,并且示蹤劑產出曲線擬合過程中人為調整的難度大,因此,構造目標函數,利用最優化方法完成。
確定目標函數式(1)。

式中,i為產出井編號;j為井組編號。
即利用區塊所有產出井計算濃度與實測濃度的差的平方和作為目標函數,按照一定的優化方法,當目標函數最小時,得到的地層參數即認為是最可能的參數分布。
2 大規模系統優化的遺傳算法
由于求解的問題自變量很多,以研究范圍內有兩個測試井組,每個測試井組有2口示蹤劑產出井,每口產出井垂向有2個高滲通道,每對井間有20條流線連接,每條流線上有2個參數計算,則有很多個參數可以調整,是典型的大規模參數系統。
雖然借助油藏工程分析判斷手段,可以消除或者確定部分參數,但是,需要擬合的自變量依然很多,常規的最優化方法已經證實適用性差,因此,最終篩選確定了利用組合最優化方法之一-遺傳算法進行改進,作為擬合的工具。
2.1 遺傳算法的實現原理
遺傳算法是模擬生物在自然環境中的遺傳和進化過程而形成的一種自適應全局優化概率搜索算法。隨著問題種類的不同,以及問題規模的擴大,要尋求到一種能以有限的代價來解決一些優化問題的通用方法仍是一個難題。遺傳算法卻為解決這類問題提供了一個有效途徑和通用框架[9-10]。
遺傳算法中,將n維決策向量X=[x1,x2,…,xn]T用n個記號Xi(i=1,2,…,n)所組成的符號串表示,見公式(2)。
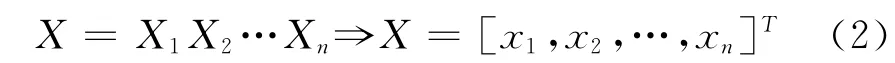
把每個Xi看作一個遺傳基因,它所有可能的取值稱為等位基因,這樣,X就看做是由n個遺傳基因組成的一個染色體。根據研究的問題,這里的等位基因是某一范圍內的實數值。這種編碼所形成的排列形式X是個體的基因型,與它相對應的X值是個體的表現型。染色體X也稱為個體X,對于每一個個體X,要按照一定的規則確定出其適應度。個體的適應度與其對應的個體表現型X的目標函數值相關聯,X越接近于目標函數的最優點,其適應度越大。
遺傳算法中,決策變量X組成了問題的解空間。對問題最優解的搜索是通過對染色體X的搜索過程來實現的,從而由所有的染色體X就組成了問題的搜索空間。
生物的進化是以集團為主體的。與此相對應,遺傳算法的運算對象是由M個個體所組成的集合,稱為群體。與生物的進化過程相類似,遺傳算法的運算過程也是一個反復迭代的過程,第t代群體記為P(t),經過一代遺傳和進化后,得到第t+1代群體,記為P(t+1)。這個群體不斷地經過遺傳和進化操作,并且每次都按照優勝劣汰的規則將適應度較高的個體更多地遺傳到下一代,這樣最終在群體中將會得到一個優良的個體X,它所對應的表現型X將達到或接近于問題的最優解。
生物進化的過程主要是通過染色體之間的交叉和染色體的變異來完成的。與此相對應,遺傳算法中最優解的搜索過程也模仿生物的進化過程,使用所謂的遺傳算子作用于群體P(t),進行下述遺傳操作,從而得到新一代群體P(t+1)。
1)選擇:根據各個個體的適應度,按照一定的規則或方法,從第t代群體P(t)中選擇出一些優良的個體遺傳到下一代群體P(t+1)中。
2)交叉:將群體P(t)內的各個個體隨機或者按照一定規則搭配成對,對每一對個體,以某個概率(交叉概率)交換他們之間的部分染色體。
3)變異:對群體P(t)中的每一個個體,以某一概率(變異概率)改變某一個或某一些基因座上的基因值為其它的等位基因。
基于上述三種遺傳算子的遺傳算法的主要運算流程如下所示。
步驟一:初始化。設置進化代數計數器t=0,設置最大進化代數T,隨機生成M個個體作為初始群體P(0)。
步驟二:個體評價。計算群體P(t)中各個個體的適應度。
步驟三:選擇運算。將選擇算子作用于群體。
步驟四:交叉運算。將交叉算子作用于群體。
步驟五:變異運算。將變異算子作用于群體。群體P(t)經過選擇、交叉、變異運算之后得到下一代群體P(t+1)。
步驟六:終止條件判斷。若t<T,則轉到步驟二;若t≥T,則以進化過程中所得到的具有最大適應度的個體作為最優解輸出,終止計算。
運算過程見圖1。
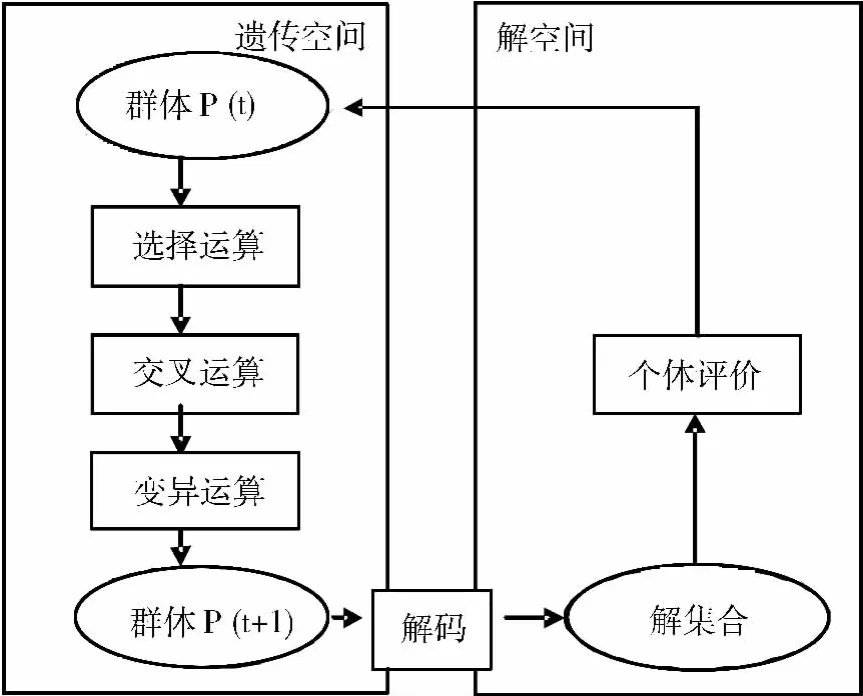
圖1 遺傳算法過程
遺傳算法與直接法、梯度法等的不同在于其有多個隨機產生初始點,搜索過程隨機,且有自己的交叉、變異和選擇遺傳操作。對于復雜的優化問題,遺傳算法具有優勢。
2.2 改進的浮點數編碼遺傳算法
在遺傳算法中如何描述問題的可行解,即把一個問題的可行解從其解空間轉換到遺傳算法所能處理的搜索空間的轉換方法就稱為編碼。常用的編碼方法有二進制編碼法、格雷碼編碼法、浮點數編碼法、符號編碼法、多參數級聯編碼法和多參數交叉編碼法等。浮點數編碼方法是指個體的每個基因值用其某一范圍內的一個浮點數來表示,個體的編碼長度等于其決策變量的個數。因為這種方法使用的是決策變量的真實值,所以浮點數編碼方法也叫做真值編碼法。下面介紹基于浮點數編碼的遺傳算法實現過程。
2.2.1 初始化過程
隨機產生M個初始染色體。由于優化問題的復雜性,解析地產生可行的染色體是困難的。此時,采用下述方法作為初始化過程:①通過油藏工程分析,確定一個包含最優解的區域,即一個n維超立方體;②從這個超立方體中產生一個隨機點,并檢驗其可行性,如果可行,則作為一個染色體,否則,從超立方體中重新產生隨機點,直到得到可行解為止;③重復以上過程M次,得到初始可行的染色體組合。
2.2.2 評價函數
評價函數用來對種群中的每個染色體設定一個概率,以使該染色體被選中的可能性與其適應性成正比,在此,直接利用目標函數倒數的相對大小作為評價函數,不采用其它通用性的評價函數
2.2.3 選擇過程
由于要解決的問題具有一定優化方向,因此,不采用通用旋轉賭輪的方法進行選擇,而是直接根據評價函數進行排序,從好到差選擇M1個個體進入下面的優化程序。
2.2.4 交叉過程
由于要解決的問題中,評價函數僅從目標函數的角度對個體進行了評價,不能夠完全反映實際優化的程度,因此,交叉過程中,不再繼續依賴評價函數,而是采用完全隨機的操作方法。
1)生成兩個隨機數,從M1個個體中確定兩個個體X1和X2。
2) 生成一個隨機數c,利用選出的兩個個體,交叉操作,形成兩個新的后代個體
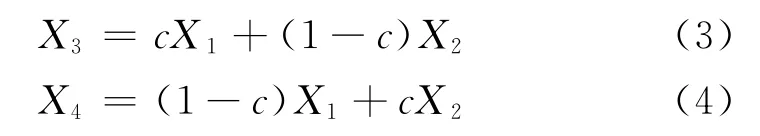
3)重復以上過程M2次,得到交叉形成的個體組合M2個,在該問題中,要求M2大于M1。
2.2.5 變異操作
根據研究的問題特征,認為變異操作在本組合優化中所占比例很大,因此,確定變異操作產生的個體數量M3大于M2與M1之和,且該變異為完全變異,即可以隨機產生個體作為變異個體,其產生方法與初始化過程相同。
2.2.6 個體數量
通過選擇、較差、變異得到的個體進入下一個循環,且要求M=M1+M2+M3。可見,改進的遺傳算法特點主要包括:①從油藏工程評價的角度,簡化了評價函數,直接用目標函數簡單處理作為評價函數,節省了不必要的計算,操作過程中,較為合理的處理了隨機和方向的關系,具有針對性;②在保留適應個體的前提下,著重強調了變異的作用,從數量上,變異個體數量大,從變異程度上,屬于完全變異,適應了多參數、范圍大的情況;③交叉操作在此實質上相當于一種變異作用的補充和較優個體主要特征的繼承,不再依賴于評價函數,是一種有優化方向的交叉操作。
2.3 組合優化控制算法實現過程
根據組合優化解釋的數學模型和示蹤劑產出濃度方程可知,目標函數中的自變量均具有一定的變化范圍,滿足一定的上下限約束。但是,依然存在自變量過多,優化困難的問題,因此,需要在改進的遺傳算法基礎上,根據研究的問題,進一步構造優化控制算法。
1)首先,從油藏工程和擬合實踐的角度,確定了參數的敏感性排序。最為敏感的參數為井間高滲通道垂向位置、主流線上高滲通道的厚度、滲透率;其次為其它流線上的厚度、滲透率;最后為剩余油飽和度分布。
2)在敏感性排序的基礎上,采用空間和參數控制的輪換優化方法。①空間控制的輪換優化方法:即一次優化一個井組,依次進行;②參數控制的輪換優化方法:即首先優化最敏感的參數,然后優化次敏感的參數,最后優化不敏感的參數,一輪優化完畢后,重復參數控制的優化過程;③每一次優化均調用改進的遺傳算法優化過程,優化完畢后,修改關聯參數,循環①-②直至優化結果收斂。擬合實踐證明,這種控制非常有效。
3 結論
在建立的數學模型、求解方法的基礎上,確定了油藏自變量,建立了目標函數,改進了遺傳算法,完成示蹤測試曲線的組合自動優化解釋,形成了井間水相示蹤測試解釋流程。
[1]姜漢橋,劉同敬.示蹤劑測試解釋原理與礦場實踐[M].東營:石油大學出版社,2001.
[2]李淑霞,陳月明,馮其紅,等.利用井間示蹤劑確定剩余油飽和度的方法[J].石油勘探與開發,2001,28(2):73-75.
[3]姜瑞忠,姜漢橋,楊雙虎.多種示蹤劑井間分析技術[J].石油學報,1996,17(3):85-91.
[4]常學軍,郝建明,鄭家朋,等.平面非均質邊水驅油藏來水方向診斷和調整[J].石油學報,2004,25(4):58-61.
[5]陳月明,姜漢橋,李淑霞.井間示蹤劑監測技術在油藏非均質性描述中的應用[J].石油大學學報:自然科學版,1994,18(zk):1-7.
[6]Yuen,.D.L.,Brigham,W.E.and Cindo-Ley,H.Analysis of Five-Spot Tracer Test to Determine Reservoir Layering .DOE Report SAW 12658.Feb.1979.
[7]Maghsood Abbasazadeh-Dehaghani and William E.Brigham:Analysis of Well Tracer Flow to Determine Reservoir Layering.JPT.Oct.1984.
[8]Allison,S.B.,Pope,G.A.and Sepehrnoori,K.Analysis of Field Tracer for Reservoir Description.J.of Petroleum Science and Engineering.1991,5(2):173-186.
[9]Akhil Datta Gupta,L.W.Laka and G.A.Pope and M.J.King.Type-Curve Approach to Analyzing Two-Well Tracer Tests.SPE/DOE 24139.
[10]S.G.Ghori,J.P.Heller.Use of Well-Well Tracer Tests to Determine Geostatistical Parameters of Permeability.SPE/DOE 24138.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
