基于GPU加速的光線跟蹤渲染算法研究
2013-08-21 07:46:30江蘭帆
武夷學院學報 2013年2期
陳 昱 江蘭帆
(福州大學 數學與計算機科學學院,福建 福州 350108)
1 引言
光線跟蹤是一種基于物理的圖形渲染算法,相比于實時流水線光柵化算法,更方便實現真實環境中的反射、折射、透明、陰影等全局光照效果。光線跟蹤算法產生的畫面真實感強,被廣泛應用于電影后期制作等領域。
光線跟蹤算法需要跟蹤每一條光線,將其與場景中幾何對象執行相交測試,計算量很大。因此,目前光線跟蹤主要應用于離線渲染,在實時渲染中的應用還處于試驗階段。如果光線跟蹤算法的性能可以達到實時交互,必然可以極大地提高該算法的應用領域,對計算機圖形學相關應用(如游戲,電影等)將產生重大影響。
2 光線跟蹤算法加速分析
為了提高光線跟蹤算法的速度,一種思路是改進算法(如研究提高求交計算的效率,采用加速結構減少求交的次數等),另一種則是從硬件體系出發。光線跟蹤渲染中每條光線獨立計算,十分適合并行體系結構。近年來,集成大量處理核心的GPU(圖形處理器)在計算能力方面增長迅速,在特定類型計算中已遠超CPU[1]。光線跟蹤算法理論上可以利用GPU架構的數據并行性獲得較高的性能,利用GPU實現光線跟蹤的實時交互成為了一個新的思路。
本文采用NVIDIA公司的CUDA作為GPU編程平臺,采用BVH作為加速結構,對三角形網格模型進行渲染,針對CUDA體系結構進行了算法的重新設計與優化。實驗結果表明10萬三角形的場景在目前主流型號GPU上算法已可以達到實時交互的性能,與CPU實現相比加速比達到5倍以上;與采用Kd-tree作為加速結構的實現相比[2,3],在同等復雜度的場景下性能更好。
3 基于GPU的光線跟蹤渲染
3.1渲染算法流程
渲染算法的流程和階段如圖1所示。整個渲染分成兩個工作階段:
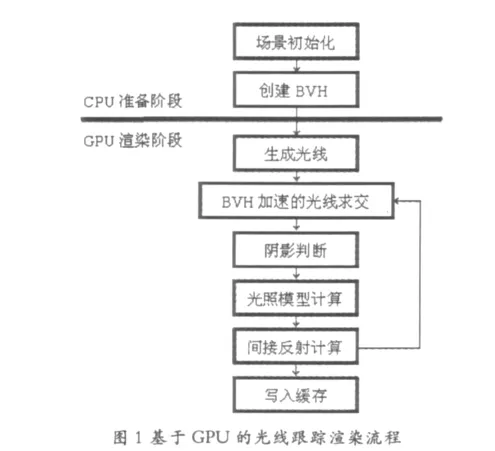
1、CPU準備階段是在CPU上運算完成的,負責讀取場景數據和創建BVH。在得到這些數據之后,將其復制到顯卡的顯存中,供GPU渲染時使用。
2、GPU渲染階段是通過CUDA的kernel函數實現光線跟蹤渲染算法,編譯后運行于GPU上。首先從視平面的像素點向場景空間中投射光線,獲取光線與場景中對象的最近碰撞點,利用BVH加速結構進行快速相交測試。接著判斷該碰撞點是否處在陰影區域,如果不在則利用光照模型計算該位置的直接光照強度。如果考慮間接反射情況,則應繼續跟蹤光線,計算碰撞點的間接光照強度。將直接光照和間接光照疊加起來,即可計算出視平面的像素點的顏色值。在GPU中每一個線程計算一條光線方向,計算出像素顏色后寫入OpenGL PBO緩存區域,最終顯示在窗口中。
3.2 場景初始化
程序首先完成場景數據(包括對象,光源和照相機)的初始化。其中場景中的對象使用三角形網格(Mesh)進行描述,實現了從模型文件中讀取頂點數據(坐標,顏色,法向量)和多邊形定義。光源可在程序中設定其初始位置,類型采用點光源。照相機默認采用透視投影。光源和照相機位置在程序執行過程中可以動態改變。這些場景數據的數據量比較大而且要能供所有線程訪問,因此只能通過CUDA API將其以數組的方式拷貝進GPU的全局內存或紋理內存,供GPU渲染程序使用。
3.3 生成光線
根據觀察方向和視平面分辨率,可以計算得到每個像素的坐標;結合照相機位置,就可以得到從投影中心到每個像素的主光線的參數方程。在GPU中,每個線程計算一條光線在場景中的反射光強度,即像素的顏色值。每個線程塊(Block)分配的光線數用以下公式計算:(SIZEX*SIZEY+THREADS_PER_BLOCK-1)/THREADS_PER_BLOCK。其中SIZEX和 SIZEY為屏幕窗口長寬方向上的像素數,THREADS_PER_BLOCK為CUDA中每個block的線程數。
3.4 BVH的構建與遍歷
在生成光線后,渲染程序需要將光線與場景進行相交檢測,獲取距離視點最近的物體交點。一種簡單的做法是將光線與場景中的所有幾何對象進行碰撞檢測,通過比較獲取最近的碰撞點。這種做法易于實現,但所需的計算量也是極為龐大,時間復雜性為O(N),N為場景中對象的數量,而使用BVH和Kd-tree等加速結構的時間復雜性為O(logN),判斷效率提高明顯[4]。
1、BVH 的構建
BVH(層次包圍盒)的基本思想是按照某一空間維度將原包圍盒分成兩部分,每部分再接著往下分,直到滿足結束條件,其過程與二叉樹類似。BVH中內部節點不包含三角形,但包含兩個子節點的索引,而葉子節點包含一個三角形列表。創建過程是一個遞歸地劃分包圍盒的過程,每次包圍盒劃分位置的確定將影響BVH的生成結果,并影響整個加速結構的遍歷性能。比較常用的方法是劃分時采用表面積啟發式(Surface Area Heuristic)代價模型,估算光線穿越包圍盒的期望代價,求得近似最優解。
基于SAH評估的BVH創建過程如下[4]:
(1)將當前節點包圍盒的最長軸的方向作為分割方向;
(2)將三角形列表按照包圍盒的中心點在分割方向上的位置N等分,產生N-1種備選劃分方式:左邊1份,右邊N-1份,…,左邊N-1份,右邊1份;
(3)對每種分割方式分別計算兩部分包圍盒的表面積,再應用SAH代價模型估算當前劃分方式的代價,選取代價最小的分割方式劃分當前節點;
(4)以同樣的方式遞歸生成孩子節點,一直到三角形數量小于設定的閾值為止,即可完成BVH的創建。
在CPU中完成BVH的構建后,將其數據結構拷貝到顯存中,供GPU渲染程序用于遍歷。
2、GPU中遍歷BVH進行相交測試的實現
BVH的遍歷是一個深度優先的遞歸過程。從根節點開始,光線與節點的包圍盒進行相交測試。如果沒有相交,返回。如果相交,將光線與該節點的兩個子節點進行相交測試;或者該節點是葉子節點,則與該節點的三角形列表逐一進行相交測試。
在CUDA平臺上實現BVH遍歷的問題是,CUDA前期的架構版本(G80/GT200)是不支持遞歸函數調用的,所以為了實現更好的GPU兼容性,需將BVH遍歷修改為非遞歸算法,將原本指向節點的指針用節點索引替代,并引入堆棧保存節點列表。算法如下:
初始化節點列表為空,將根節點添加到節點列表中
初始化當前相交的最近距離為無限遠:min_t=INEnd While

3.5 陰影計算
當確定光線和場景中三角形的最近交點后,下一步需計算交點處的反射光強度(即顏色值)。首先要判斷的就是在交點和光源之間是否有物體遮擋,如有遮擋則光源對該像素點的顏色無直接貢獻;否則在計算像素顏色時需要考慮該光源的貢獻。當確定光線和場景中三角形的最近交點后,可以在光源與交點之間生成陰影檢測光線,并利用3.4節中基于BVH的相交測試算法進行遮擋測試。
3.6 光照模型計算
為了計算光線所對應的像素顏色(即交點處反射向視點的光線顏色),在交點處可以使用常用的Blinn-Phong光照模型公式[5]計算其在每個光源下的反射光顏色并疊加:
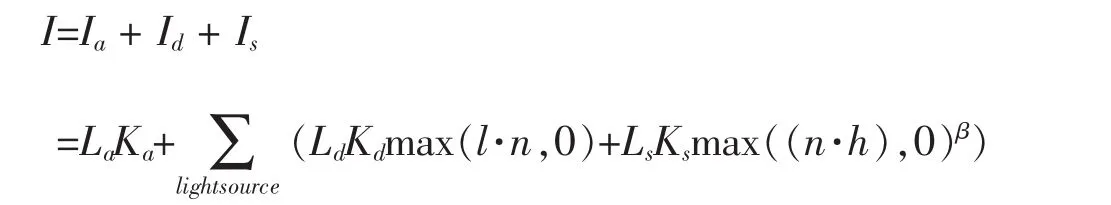
CUDA支持float4數據類型,十分方便進行上述公式中向量的計算。其中鏡面反射分量計算時需要交點處的法向量n,通過三角形三個頂點處的法向量(從模型文件中讀取)結合交點處的質心坐標(Barycentric Coordinates)插值計算得到,實現Phong插值著色,這樣計算得到的物體表面的反射光顏色過渡較為自然。
3.7 間接反射計算
在光線跟蹤渲染中,光線與場景第一次相交后通常還需計算間接反射情況。像素的顏色除了包含光源的反射光顏色之外,還需其他表面產生的間接反射光顏色。光線每反射一次便需計算一次交點處的顏色值,這樣經過多次反射后,像素點最終色彩便是多個間接反射顏色的累加。
上述間接反射過程是一個遞歸的計算,實現中為了函數在有限時間內返回,需定義遞歸的深度(即跟蹤的反射次數),可以表示成以下的偽代碼:

//利用傳入的光線參數查找最近相交點intersec-

上述光線跟蹤的遞歸算法十分簡潔,但為了在CUDA上實現上述算法,必須進行非遞歸模式的改寫。由于RayTrace函數中變量眾多,如果用3.4節中添加堆棧的方式改寫該算法,代碼的改寫量大、改寫后可讀性差。因此,本文利用C++的模板元編程(Template Meta Programming,TMP)技術解決這個問題。所謂模板元編程,是C++將計算從運行期轉移至編譯期、由編譯器在編譯期執行部分計算的技術統稱[6],利用其中的“遞歸模板實例化”技術可以實現編譯期遞歸結構。
在原遞歸函數聲明前加上template
template
Color RayTrace(Vector3 ray,Vector3 origin,...){
....
//利用傳入的光線參數查找最近相交點intersectionPoint
//計算交點處光照模型下的顏色值.phongColor
//計算反射光線reflectionRay
...
return color+RayTrace
再定義如下形式的完全特化(Specialization)后的模板函數,其中的遞歸深度被預先定義的常量MAX_DEPTH(比如4)特化了,從而得到遞歸結束時的函數如下:
template<>
Color RayTrace
return BLACK;//這里結束了遞歸
在編譯過程中,編譯器會分析depth在執行過程中可能的值的情況,根據函數模板生成depth值不同時的函數版本,即生成從RayTrace<0>(這是主光線時的情況)到RayTrace
從上述代碼片段可以發現其對原算法的代碼改變是很小的,并且克服了CUDA無法編寫遞歸函數的問題。當然,元編程也有其缺點,比如編譯時間變長,執行文件變大,不宜調試等。
4 實驗結果及分析
實驗采用不同頂點數和多邊形數的場景對上述渲染算法的GPU和CPU實現進行性能測試,測試過程中設定一個點光源,視點位置繞固定軸旋轉一周,記錄下渲染360幀(即旋轉360度)所需時間后求每秒平均幀數(FPS)。測試平臺軟硬件配置如下:
*CPU:AMD Athlon II X2 255 3.1GH,雙核心
*GPU:NVIDIA GeForce GTS 450,192 個流處理單元
*CUDA Toolkit:版本 4.2.9
測試場景分別為兩個3DS模型文件 (Chess和Gundam),兩個Stanford提供的PLY模型 (Horse和Armadillo),渲染結果如下:

4.1 GPU線程配置測試
在CUDA中,kernel函數執行的性能受到底層硬件配置和軟件配置的影響,從軟件層面的優化來說,很主要的是合理配置其線程參數,以便達到較好的處理器利用率。CUDA中的線程以兩層結構的形式組織管理,即網格(Grid)包含多個線程塊(Block),線程塊包含多個線程(Thread)。如果每個塊的線程數太少,無法充分利用多核心的處理能力,也無法通過調度隱藏訪問顯存的延時。如果一個塊的線程數太多,由于在一個多核流處理器 (Streaming Multiprocessor,SM)上同時執行的線程數受到寄存器數量、共享內存數量等硬件資源限制,又會使得許多線程處于等待狀態,無法并行執行[7]。
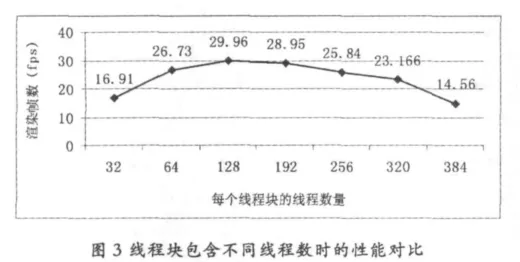
對線程塊包含不同線程數時的Chess場景渲染測試的結果如圖3所示:
圖3測試結果表明,對上述光線跟蹤算法GPU實現在測試平臺上的最佳數配置是每個線程塊包含128個線程。這與光線跟蹤的kernel函數需要的寄存器數量比較多有關系,更多的并發線程所需的寄存器數量無法在硬件上得到滿足。
4.2 GPU和CPU渲染對比測試
對上述光線跟蹤渲染器的GPU和CPU實現進行性能測試,其中GPU測試采用每塊128線程配置下的測試結果;CPU也是用BVH加速結構,并且采用OpenMP實現多線程并行計算,以利用CPU的多個核心。測試結果見表1。
從表1可以看出,GPU實現的渲染引擎可以在512x512分辨率下對10萬個三角形以內的場景實現大于15 fps的渲染速度,相比CPU的實現 (使用OpenMP優化)有5倍以上的性能提升。渲染速度與場景的構成(頂點數量,三角形數量)、模型表面多反射的發生數量以及渲染的視角都有關系。總的來說,頂點數量和三角形數量少的場景渲染速度較快,物體表面相互反射較少時速度較快,物體占據畫面的面積較小時速度較快 (空白背景的像素光線直接穿越,BVH可以快速判斷此情況)。
5 總結
本文在基于BVH加速結構的光線跟蹤算法基礎上,根據CUDA平臺的特點重新對渲染算法進行了設計與優化,在GPU上實現了具有實時性的光線跟蹤算法。測試結果表明,主流GPU在512x512分辨率下,10萬個三角形以內的場景可以達到超過15 fps的渲染速度,可實現實時交互;與采用Kd-tree作為加速結構的實現相比[2,3],在同等復雜度的場景下性能更好。
經過實驗,也發現GPU在實現光線跟蹤渲染上的不足之處。由于光線跟蹤渲染算法代碼復雜,編譯后線程所需的寄存器數量較多,限制了可同時并發的線程數量[8];雖然程序使用了CUDA手冊中的多種優化技巧,但渲染更高的分辨率和更復雜的場景仍需要性能更強大的GPU才有希望實現實時性。
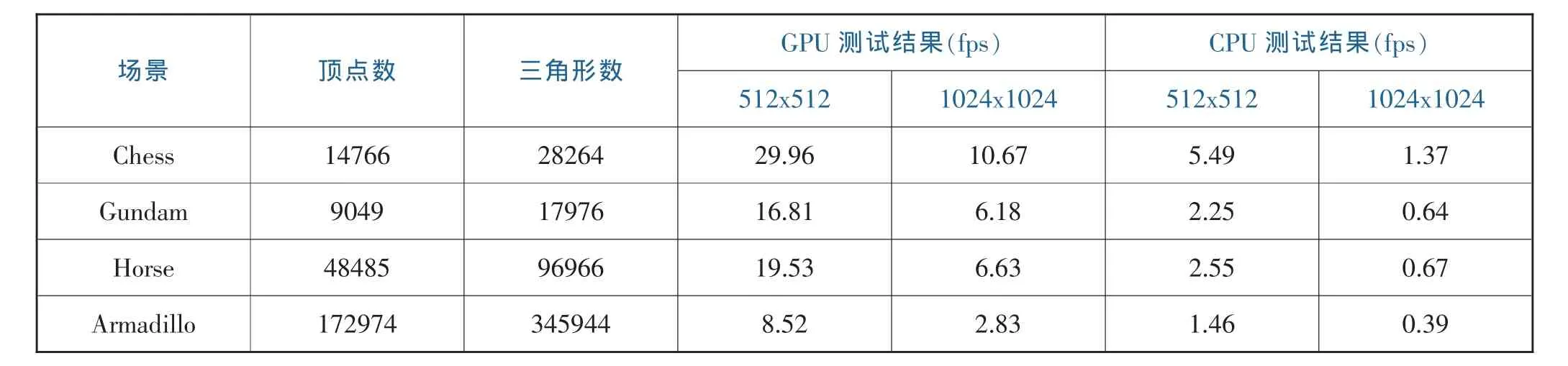
表1各場景在不同分辨率下的渲染性能測試結果
[1] 吳恩華,柳有權.基于圖形處理器(GPU)的通用計算[J].計算機輔助設計與圖形學學報,2004,16(5):601-612.
[2] 陸建勇,曹雪虹,焦良葆等.基于GPU交互式光線跟蹤算法的設計與實現[J].南京工程學院學報(自然科學版),2009,7(3):61-67.
[3] 曹家音.基于KD-Tree遍歷的并行光線跟蹤加速算法[J].科技傳播,2010,(17):233-233,224.
[4] Matt Pharr,Greg Humphreys.Physically Based Rendering,Second Edition:From Theory To Implementation[M].Morgan Kaufmann,2010.217-222.
[5] Edward Angel著,張榮華等譯.交互式計算機圖形學—基于OpenGL的自頂向下方法(第五版)[M].北京:電子工業出版社,2009.222-226.
[6] David Abrahams,Aleksey Gurtovoy著,榮耀譯.C++模板元編程[M].北京:機械工業出版社,2010.
[7] David B.Kirk,Web-mei W.Hwu著,陳曙暉等譯.大規模并行處理器編程實踐[M].北京:清華大學出版社,2010.59-60.
[8] NVIDIA.CUDA C BEST PRACTICES GUIDE v4.2[Z].NVIDIA Corporation,2012.48-53.
