嵌入式MPSoC的片上存儲器設計優化技術綜述
2013-09-21 10:09:10趙廣佩曾憲彬
中國科技信息 2013年3期
趙廣佩 曾憲彬
杭州電子科技大學通信工程學院,杭州 310018
引言
隨著半導體技術和集成電路產業的發展,嵌入式系統硬件的功能越來越強,支持的應用范圍也越來越廣,其核心處理器的頻率也是越來越高。雖然隨著處理器頻率的增高,系統性能也在提升;但是這也帶來了一系列的問題,比如:能耗、線干擾和線延遲等。而這些問題已嚴重影響了嵌入式系統性能的提高,因此,在嵌入式系統設計中使用多處理器片上系統(MPSoC: Multi-Processor System-on-Chip)已經成為未來的一種趨勢[1]。另外,由于嵌入式系統是“嵌入到對象體系中的專用計算機系統”,它強調的是面向具體應用的性能最優,而MPSoC的片上存儲器與其面積、能耗、性能等幾個關鍵因素直接相關,并且已經成為嵌入式系統性能提升的瓶頸[2]。因而,如何設計嵌入式MPSoC的片上存儲器,使得它對具體應用最優,已經成為一個亟待解決的關鍵問題。
1 片上存儲器的構成
片上存儲器是嵌入式存儲系統中一個至關重要的層次,它主要是為解決處理器和片外存儲器之間速度不匹配的問題而設計的。圖1給出了嵌入式存儲系統的層次結構。
從圖1中可以看出,沿著存儲層次自頂向下,存儲器的單位成本降低,存取時間增大,存取能耗增大,訪問頻度降低,容量增大。寄存器處在最頂層,位于處理器內核中,提供最快的存儲訪問速度。接下來一層仍然在芯片內部,主要包括SPM(Scratch-Pad Memory)和Cache兩種,這一層就是本文要重點研究的片上存儲器。再往下就是板級存儲器,可以分為主存和掉電非易失存儲器兩層。采用這種層次性結構,可以用低速、高能耗存儲器的平均價位得到高速、低能耗存儲器的性能,并能滿足系統對存儲器容量的要求。
從圖1中可以看出,嵌入式片上存儲器主要包括SPM和Cache兩種結構;其中,SPM由基本的SRAM構成,Cache是內部的高速緩存,它們在嵌入式系統的位置如圖2所示。
從圖2中可以看出,Cache位于處理器內核和主存之間,不占用獨立的地址空間。Cache從局部性原理考慮,保存最近一段時間內處理器訪問到的主存內容,這樣就可以減少外部低速存儲器的訪問,并且也能降低能耗。處理器在需要進行數據指令讀取操作時,總是從Cache中讀取,根據地址檢查是否命中。如果命中,則直接將數據或指令傳送給處理器;否則就先從主存儲器中把所需內容送入Cache,然后再送給處理器。

圖1 嵌入式存儲系統層次結構圖
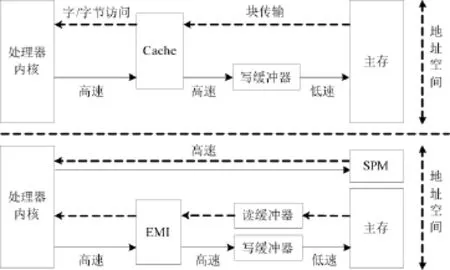
圖2 Cache和SPM在嵌入式系統中的位置

表1 Cache和SPM的比較
SPM通過片上高速總線和處理器直接連接,獨占一段地址空間,保存著部分指令和數據。當處理器需要進行指令數據讀取時,首先根據訪問地址判斷地址空間,選擇SPM或主存。前者可以直接操作,后者則需要通過外部存儲器接口模塊來訪問,并且需要時序上的等待和片外總線驅動等,極大地影響了速度并增加了能耗。Cache和SPM的比較如表1所示。
通過上表中的對比可以看出,Cache和SPM各有優缺點。Cache的控制和訪問是自動完成的,不需要通過軟件進行管理;但是其能耗和面積較大,并且在數據未命中時的訪問時間是不確定的。相反,SPM需要通過軟件進行管理;但是其能耗和面積較低,并且訪問時間確定。因此,在設計嵌入式MPSoC的片上存儲器時,為了取得更好的系統性能,可以對Cache和SPM進行綜合設計優化。
2 Cache設計優化技術
Cache即高速緩沖存儲器,它根據數據局部性和程序局部性,把正在執行的指令地址附近的一部分指令或數據從主存裝入Cache中,供處理器在一段時間內使用;這樣就可以減少對片外存儲器的訪問,進一步減少處理器的處理時間,提高系統性能。
對Cache的設計優化,首先可以優化它的結構參數。Cache的主要的參數有容量、行大小、寫策略、替換算法和映射方式。Milenkovic等人[3]基于ARM處理器的不同Cache參數配置,采用Mibench作為基準測試程序,對統一Cache和分離Cache進行直接映射和關聯映射下的參數配置,同時還更換替換算法(pLRU、LRU、FIFO和Random算法),以及改變Cache的容量大小,最終得到在不同應用下的不同優化結果,為Cache設計提供依據。
除了上面提到的設計優化一些Cache參數外,也可以從程序編譯信息方面出發來進行Cache的設計優化。[4,5]分別從指令和數據的角度出發,來降低Cache的丟失率。[4]需要首先將程序執行一遍,預先獲取程序執行流,然后根據這些執行軌跡避免Cache沖突,以降低Cache的丟失率。[5]在2008年提出了一種Cache對數據的動態管理方法,通過該方法可以減少了片外的訪問,提高了Cache的命中率。
另外,在優化Cache的硬件結構設計優化方面,在2009年,[6]基于降低Cache能耗的問題,提出了一種減少Tag位數的方法。另外,Alipour[7]在2011年通過探索設計Cache的空間大小,從而針對具體應用在系統上獲得了最佳的性能/能耗比。
總的來說,Cache設計在嵌入式應用中的研究可以分為兩個方面:一方面是通過修改Cache的組織結構和工作機制,增強對應用程序的處理能力;另一方面是對軟件的編譯過程進行控制,使得優化后的目標程序,能夠提高Cache的利用效率。
3 SPM設計優化技術
相比于Cache,SPM由于在面積、能耗和實時性等各方面的優勢,使得它在嵌入式芯片中應用越來越廣泛,而合理有效的使用SPM也已經成為了嵌入式MPSoC片上存儲器設計與研究的熱點問題。而基于SPM進行性能和能耗優化的關鍵問題在于,對于有限的SPM空間,如何確定哪些內容存入其中,從而最大限度地提高軟件的運行速度。
3.1 SPM靜態設計優化技術
Sjodin[8]在1998年提出了通過靜態解析應用程序,分析各個全局數據變量的執行次數,將頻繁訪問的全局數據變量置入SPM的分配方法。該方法可以減少片外的訪問,提升系統性能,但由于文中只優化了全局變量并且采用的分配算法是簡單的首次適配算法,因此它在優化后并不能得到最高的SPM利用率。
Oren等人[9]在2001年提出了一套基于鏈接器使用0/1整數線性規劃算法的SPM優化技術。它根據程序運行記錄確定各全局數據變量和函數堆棧的讀寫次數,然后計算全局數據變量和函數堆棧中變量對性能的影響值,借助Matlab中0/1整數線性規劃算法工具挑選適當變量放入SPM,最后通過鏈接器直接生成可運行的程序。2003年,文獻[10]在他們研究的基礎之上,又加入了對大型數組進行劃分的策略。
Koc等人[11]在2007通過數據的重計算,提出了一種SPM空間優化策略,目的是減少片外存儲器的訪問次數。文中通過多個測試程序對提出的算法進行了實驗仿真;實驗表明,通過文中提出的算法對SPM進行空間優化,可以得到大約10.8%的系統性能提升。
除了上面這些軟件方面的優化,Angiolini等人[12]提出了一種SPM靜態布局優化技術的硬件架構。該技術在硬件架構上增加了一個指令譯碼器,以確定是從SPM中還是從Cache中取指令。該技術直接作用于包含符號表信息的二進制代碼,無需編譯器也無需源代碼。由于靜態方法對代碼的分配比較有效,所以文中僅針對代碼進行了分析,沒有對數據進行分析。
由于上述SPM設計技術中分配到SPM中的數據在程序運行過程中是不變化的,因此這種方法被稱之為靜態分配方法。近年來,隨著研究SPM動態設計優化技術的熱潮的興起,對SPM靜態設計優化技術的研究逐漸變少。
3.2 SPM動態設計優化技術
上一小節提到SPM靜態布局優化技術無論是采用程序分析還是借助編譯器驅動,分配到SPM中的數據在程序運行過程中都是不變的,都沒有考慮SPM中對象的時間有效性。這在很大程度上限制了SPM的使用率,特別是當SPM容量有限時,一部分高頻訪問的指令和數據將不得不被置于片外存儲器中。所以,近期的研究提出了一些SPM動態設計優化技術。
Steinke等人[13]在2002年提出了動態復制指令至SPM的能耗優化方法。該算法根據文中提出的兩個假設可以得到了可供優化的集合,然后再利用模型仿真確定最終的優化集合。該方法也有自己的缺陷:首先它的研究對象局限于循環指令代碼段,而沒有綜合考慮數據、變量等因素;其次它只考慮了循環,而沒有考慮其它影響執行頻度的因素,諸如無條件跳轉,條件分支等。針對以上缺陷,Verma等人[14]在2004年提出的優化策略中,分析了全局變量、局部變量、指令代碼段,但是沒有考慮到非連續對象之間跳轉對對象能耗和體積的影響。
由于利用編譯器很難對一些不規則的訪問進行優化,針對這個問題,文獻[15]在2008年提出了一種利用馬爾科夫鏈的基于數據訪問預測的SPM動態管理方法。該方法主要針對那些不易被編譯器優化的非規則的訪問,比如:指針訪問、索引數組訪問等。
另外,在2010年文獻[16]提出了一種在運行時把最佳的代碼段映射到SPM中的編譯器驅動方法。該算法基于一個貪婪的成本模型,使用編譯器識別程序中的熱點;并且利用DMA方式傳輸到SPM中,而不是通過處理器顯式裝載和存儲。但是該算法的優化只針對的是程序中的熱點,而沒有對數據進行優化。
Salamy[17]在2012年提出了一種綜合任務調度和SPM數據分配的優化算法。在嵌入式MPSoC中,多核間的任務調度和片上存儲器的數據分配是兩個關鍵問題,本文把這兩個問題結合起來對系統進行了優化,可以更好的提升SPM的利用率。
上述動態管理SPM的研究主要基于對算法和編譯器的優化,但在MPSoC的片上存儲器設計中,單純使用軟件方法所獲得的優化效果是有限的。因此,同時從硬件架構和軟件策略兩個方面對SPM進行優化是研究的趨勢。
Hyungmin[18]在2007年提出一種基于MMU的SPM動態管理機制,他們對數據、代碼和堆棧進行優化。但是文中對數據、代碼和堆棧分開考慮,未能對整個程序進行優化。另外,文中強調了數據和代碼的局部性,卻沒有考慮堆棧訪問的局部性。而這些都是可以進一步研究的問題。
Doosan等人[19]在2009年,針對多媒體應用,通過數據的可重用性提出了一種結合軟件(編譯器和操作系統)和硬件(數據訪問記錄表)技術的綜合優化算法。文中通過編譯器分析生成數據布局和跟蹤動態內存訪問的硬件組件,高速緩存的數據布局可以應用于一個輸入數據模式,該布局技術要在OS中高速緩存運行時的內存管理器幫助下完成。本文中運用的數據分配策略利用了動態應用程序,可以實現高效的高速緩存。
由于SPM動態設計優化技術具有很好的動態性,可以很好的保持SPM的高效率,所以,近年來一直是SPM相關問題的研究熱點。另外,在近年來的一些研究中,也常常綜合考慮SPM動態設計技術和靜態設計技術來進一步提升嵌入式MPSoC的系統性能。
4 SPM和Cache共存時設計優化技術
雖然Cache的使用使得嵌入式MPSoC系統,特別是面向多媒體的應用系統,在速度上有了很大的提升,但它卻使得芯片消耗更多的能耗和面積,特別是在實時應用中Cache更是難以勝任。與Cache相比,SPM在能耗、面積和實時性上有所改善,但是需要程序員對代碼布局進行精心安排來優化SPM的作用。因此,在近期的研究中,一些研究人員已經開始在MPSoC中采用SPM和Cache協同工作的方式來優化嵌入式系統性能了。
在SPM和Cache共存的嵌入式MPSoC系統中,所面臨的問題是:某個嵌入式應用程序編譯后的程序數據可以安排在SPM中,也可以安排在片外存儲器中;而如何安排這些數據的位置,才能最大程度提高程序的性能,這便是SPM和Cache共存時的片上存儲器設計優化技術所要研究的問題。
Kandemir等人[20]在2001年提出了一種動態的SPM和Cache數據劃分的方法。該方法根據程序訪問成組數據的記錄信息,將成組數據劃分成塊,然后在指定時刻,再從存在競爭的數據塊集合中選擇一些復制到SPM中。
2005年,針對文獻[20]提出的方法,Abstar等人[21]建立了更為復雜的分析模型并提出了一套新的用于描間接索引方式成組數據的框架,用于在適當時刻將這類成組數據的關鍵部分復制到SPM中。為了減少代碼的修改,在文中的硬件框架中,SPM中的數據是通過DMA從片外存儲器中輸入。
在實際的使用中,充分發揮SPM和Cache共存架構的優勢的關鍵在于如何劃分代碼或數據,使得兩種片上存儲器更能發揮自己的優點,所以對程序的劃分算法顯得尤為重要,Verma[22]為此提出了一種分配算法,文中認為對Cache進行SPM輔助優化的首要問題是得知哪些代碼在運行時會產生Cache丟失;因此,文中在代碼運行時進行跟蹤,并通過生成沖突圖表來描述Cache的行為。
在SPM和Cache共存時,通常是采用以SPM優先優化代碼的布局,然后才考慮到Cache的作用。這是因為Cache對程序員而言是不可見的,在對Cache進行軟件優化時需要花費大量的工作,文獻[23]便是這種研究方式。該文獻在SPM和Cache共存的系統中提出了一種如何把程序和數據分配到SPM上的策略,文中通過直接分析應用的二進制代碼,然后在其中插入指令實現片外和片上的跳轉,提高了SPM的利用率,另外還可以針對具體應用獲得最佳的Cache容量。
現有的混合緩存雖然提供了Cache和SPM的靈活分區,但沒有考慮運行時緩存的自適應性;并且之前的緩存設置平衡技術要么能源利用率低要么需要串行tag和數據數組訪問。針對這個問題,Jason等人[24]于2011年提出了一種自適應混合Cache技術,該技術可以讓SPM塊動態地從高需求Cache區向低需求Cache區進行地址重映射。文中通過重新配置部分Cache作為軟件管理的SPM,使混合Cache可以實現同時處理未知的和可預測的內存訪問模式。
總之,合理選擇并設計片上存儲器架構,動態劃分Cache和SPM,并對其算法進行優化以減少內核訪問外存的次數,是嵌入式片上存儲器設計優化的關鍵,也是幾個重要的研究方向。因為,這些問題直接關系到嵌入式MPSoC的性能、成本和能耗。
5 結語
由于嵌入式MPSoC的片上存儲器與其面積、能耗、性能等幾個關鍵因素直接相關,并且已經成為系統性能提升的瓶頸。所以,如何設計嵌入式MPSoC的片上存儲器,已經成為一個亟待解決的關鍵問題。本文針對這個問題,詳細地介紹了近十幾年來嵌入式MPSoC片上存儲器設計優化技術的相關研究。文中,在介紹了嵌入式MPSoC的兩種片上存儲器SPM和Cache之后,首先對Cache的一些軟硬件設計優化技術進行了詳細的綜述;然后針對SPM,本文分別按照SPM靜態設計優化技術和SPM動態設計優化技術進行了綜述性的介紹;最后對SPM和Cache共存時的設計優化技術進行了介紹和總結。另外,本文還在綜述和介紹的基礎上討論了當前嵌入式MPSoC片上存儲器的研究熱點問題,并對未來的研究方向和發展趨勢進行了展望。
[1]Wayne Wolf. The Future of Multiprocessor Systems-on-Chips[C]. Proceedings of the 41st Annual Design Automation Conference,2004:681-685
[2]Ozturk O,Kandemir M, Irwin M J,et al. Multi-Level On-Chip Memory Hierarchy Design for Embedded Chip Multiprocessors[C]. 12th International Conference on Parallel and Distributed Systems,2006
[3]Milenkovic A,Milenkovic M,Barnes N. A Performance Evaluation of Memory Hierarchy in Embedded Systems[J]. Proceedings of the 35th Southeastern Symposium on System Theory,2003:427-431
[4]Pararneswaran S,Henkel J. Instruction Code Mapping for Performance Increase and Energy Reduction in Embedded Computer Systems[J]. IEEE Transactions on Very Large Scale Integration Systems.2005,13(4):498-502
[5]Molnos A M. Heijligers M J M,Cotofana S D. Compositional, Dynamic Cache Management for Embedded Chip Multiprocessors[C]. Design,Automation and Test in Europe,2008:991-996
[6]Ji Gu,Hui Guo,Li P. ROBTIC:An On-chip Instruction Cache Design for Low Power Embedded Systems[C]. 15th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications,2009:419-424
[7]Alipour M,Moshari K,Bagheri M R. Performance per Power Optimum Cache Architecture for Embedded Applications,A design Space Exploration[C]. 2011 IEEE 2nd International Conference on Networked Embedded Systems for Enterprise Applications,2011:1-6
[8]Sjodin J,Froderberg B,Lindgren T. Allocation of Global Data Objects in On-Chip RAM. Compiler and Architecture Support for Embedded Computing Systems,1998
[9]Avissar O,Barua R,Stewart D. Heterogeneous Memory Management for Embedded Systems[C]. In the Proceedings of the 2001 intemational conference on Compilers,architecture and synthesis for embedded systems,2001:34-43
[10]Verma M,Steinke S,Marwedel P. Data Partitioning for Maximal Scratchpad Usage[C]. In Proceedings of the Asia and South Pacific Design Automation Conference,2003:77-83
[11]Koc H,Kandemir M,Ercanli E,et al.Reducing Off-Chip Memory Access Costs Using Data Recomputation in Embedded Chip Multi-processors[C].44th ACM/IEEE Design Automation Conference,2007:224-229
[12]Angiolini F,Menichelli F. A Post-Compiler Approach to Scratchpad Mapping of Code[C]. CASES 2004
[13]Steinke S,Gmnwald N, Wehmeyer L. Reducing energy consumption by dynamic copying of instructions onto onchip memory[C]. In proceedings of the 15th International Symposium on System Synthesis,2002:213-218
[14]Verma M,Wehmeyer L,Marwedel P.Dynamic Oveday of Scratchpad Memory for Energy Minimization[C]. In the Proceedings of the 2nd IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis. 2004:104-109
[15]Yemliha T,Srikantaiah S,Kandemir M,et al.SPM management using Markov chain based data access prediction[C]. 2008. IEEE/ACM International Conference on Computer-Aided Design,2008:565-569
[16]Hongmei Wang,Lei Shi,Tiejun Zhang,et al.Dynamic Management of Scratchpad Memory Based on Compiler Driven Approach[C]. 2010 3rd IEEE International Conference on Computer Science and Information Technology,2010:668-672
[17]Salamy H,Ramanujam J. An Effective Solution to Task Scheduling and Memory Partitioning for Multiprocessor System-on-Chip[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2012,31(5):717-725
[18]Hyungmin Cho,Bernhard Egger, Jaejin Lee,et al,Dynamic Data Scratchpad Memory Management for a Memory Subsystem with an MMU. LCTES'07,2007
[19]Doosan Cho,Pasricha S.,Issenin I.,et al.Adaptive Scratch Pad Memory Management for Dynamic Behavior of Multimedia Applications[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2009:554-567
[20]Kandemir M,Ramanujam J,Irwin M.J,et al. Dynamic management of scratch-pad memory space[C]. In Design Automation Conference,2001:690-695
[21]Absar M J,Catthoor F. Compiler-Based Approach for Exploiting Scratch-Pad in Presence of Irregular Array Access[C]. In Proceedings Design,Automation and Test in Europe,2005:1162-1167
[22]Verma M,Wehmeyer L,Marwedel P,et al.Cache-Aware Scratchpad Allocation Algorithm[J]. IEEE Transactions on Computer-Aided Design of Integrate Circuits and System,25(10),2006: 2035-2051
[23]Ling Ming,Zhang Yu,Shen Lin. An Alternative Choice of Scratch-Pad Memory for Energy Optimization in Embedded System[C]. IEEE International Conference on networking, Sensing and Control,2008:1641-1647
[24]Cong J,Gururaj K,Hui Huang,et al. An energy-efficient adaptive hybrid cache[C]. 2011 International Symposium on Low Power Electronics and Design,2011:67-72
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
藝術啟蒙(2018年7期)2018-08-23 09:14:18
鐵道通信信號(2018年2期)2018-04-18 12:18:23
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電鍍與環保(2016年3期)2017-01-20 08:15:32
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
