特征提取算法在KNN中的比較
2013-09-22 14:04:08丁瓊
赤峰學院學報·自然科學版 2013年7期
丁 瓊
(華東交通大學 軟件學院,江西 南昌 330013)
文本分類指將文本按照其內容含義劃分到不同的類型中去.自動分類的一般做法是,預先確定好文本的類別,并且對每個文本類別提供一批預先分好類的文本(稱為訓練文本集),分類系統通過訓練文本集學習分類知識,在實際分類時,再根據學習到的分類知識為需要分類的文本確定一個或者多個文檔類別.國外的自動分類研究大體上可以分為三個階段:第一階段(1958年-1964年)主要進行了自動分類可行性研究;第二階段(1965年-1974年),自動分類的實驗研究;第三階段(1975年-至今),自動分類的實用化階段.國內自動分類研究起步較晚,始于20世紀80年代初期.國內的研究基本上是在英文文本分類研究的基礎上采取相應策略,結合中文文本的特定知識,然后應用于中文之上,繼而形成中文文本自動分類研究體系.[1]
1 特征提取算法
在文本處理中,一些常用特征提取評估函數有文檔頻數(document frequency)、信息增益(information gain)、期望交叉熵(expected cross entropy)、互信息(mutual information)、χ2統計(CHI)、文本證據權(the weight of evidence for text)等.[2,3,4]
1.1 文檔頻數DF
它是最簡單的評估函數,值為訓練集合中該單詞發生的文本數.DF評估函數理論假設稀有單詞可能不包含有用信息,也可能太少而不足以對分類產生影響,也可能是噪音,因此可以刪去.顯然它在計算量上比其他評估函數小很多,但是實踐運用中它的效果卻很好.DF的缺點是稀有單詞可能在某一類文本中并不稀有,也可能包含著重要的判斷信息,錯誤的舍棄,可能影響分類器的精度.因此,在實際運用中一般并不直接使用DF.
1.2 信息增益(Information Gain)
信息增益表示文檔中包含某一特征值時文檔類的平均信息量.它定義為某一特征在文檔中出現前后的信息熵之差.
1.3 互信息(Mutual Information)[5]
MI是信息論中的概念,用于衡量一個消息中兩個信號之間的相互依賴程度.在特征選擇領域中,文檔類別c和特征f的互信息體現了特征和類別的相關程度,在某個類別中出現的概率高,而在其他類別中出現概率低的特征f將獲得較高的互信息.
1.4 χ2統計[6]
統計也是表征兩個變量間的相互關性,但是它比互信息更強,因為它同時考慮了特征存在和不存在時的情況.
1.5 交叉熵(Cross Entropy)[7]
交叉熵和信息增量相似,不同之處在于信息增量中同時考慮到了特征在文本中發生與不發生時的兩種情況,而交叉熵只考慮特征在文本中發生一種情況.
1.6 證據權值(Weight of Evidence)
證據權值反映的是類概率與在給定某一特征值下的類概率的差.
2 KNN分類方法簡介
KNN分類方法把文本表示為D(T1,W1;T2,W2;…TN,WN)形式的加權向量.對于測試文本,計算該文本向量和訓練樣本集中每個樣本的相似度,找出K個最相似的文本,在這K個近鄰中,依次計算每類的權重,最后把測試文本分到權重最大的類中.
3 特征提取在KNN中的性能比較
實驗目的:我們用KNN分類器比較常用的文本特征提取方法:IG、CE、MI、χ2、WE及 DF特征提取方法.訓練集樣本數為1882.我們采用開放性測試,即訓練數據不同的測試集進行測試,測試集樣本數為934.
實驗環境:分類算法KNN,特征預處理采用禁用詞表,權重計算公式TF*IDF,K值取35,特征數目從50到10000.為評價分類效果我們采用最通用的性能評價方法:準確率(Precision)來對各種提取方法進行比較.

實驗結果:
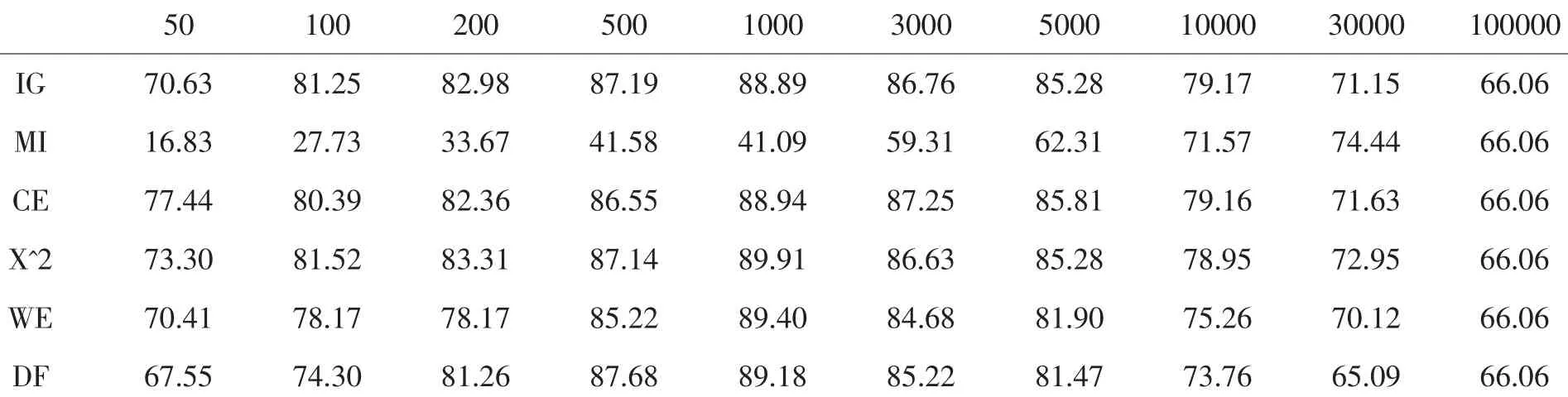
表1 特征提取方法在KNN中的比較
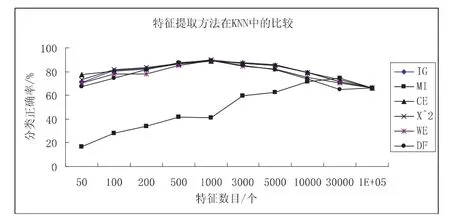
圖1 特征提取方法在KNN中的比較
用KNN分類器比較常用的文本特征提取方法,比較結果見表1和圖1.各種方法的分類準確率表現出隨特征數的增加先增加后降低的變化曲線.對于中文文本分類來說,特征向量空間過大或過小時,分類準確度都不高.選用的特征詞過少時,不能反映各個類別的特征,不能準確地區分各個類別的文檔;而選用的特征詞過多時,一些區分度很低的冗余詞匯也被加了進來,這樣那些區分度較高的詞在其中被“稀釋”了,不能有效地為區分文檔做貢獻.IG、CE、χ2、WE、DF五種特征提取方法在 KNN分類器中性能接近,并且在特征空間維度為1000時,分類正確率達到最大.互信息(MI)特征提取方法隨著特征數的提高分類性能提高得較快,當特征數目較小時分類性能極差.原因可能是互信息沒有考慮特征詞出現的頻度,導致互信息評價函數不選擇高頻的有用詞而有可能選擇稀有詞做文本的最佳特征.此外MI是基于類別信息的特征提取方法.當訓練語料庫未達一定規模時,特征空間中必然存在相當數量的出現頻率很低(如低于三次)的特征.而因它們較低的出現頻率,必然只屬于較少的類別.而使用類別信息的統計方法認為這些低頻詞攜帶較為強烈類別信息,從而對他們有不同程度的倚重.但是研究發現,這些低頻詞中只有不到20%的詞確實帶有較強的類別信息,大多數都是噪音詞,不應成為特征.當選擇較少數目的特征時,選取的大多是低頻詞,這些詞對分類并無很大作用,所以當特征數目較少時分類的正確率很低,隨著特征數目的增加性能一步一步的提高.最后因我們訓練集的文本都不太長,故當特征數目達到100000時,基本上所有特征都包含進去,故最后分類效果趨于相同.
〔1〕李榮陸.文本分類若干關鍵技術研究[D].上海:復旦大學,2005.20-25.
〔2〕龐劍鋒,卜東波,白碩.基于向量空間模型的文本自動分類系統的研究與實現[J].計算機應用研究,2001,21(9):23-26.
〔3〕朱華宇,孫正興,張福炎.一個基于向量空間模型的中文文本自動分類系統 [J].計算機工程,2001,27(2):36-40.
〔4〕孫健,等.基于K一最近距離的自動文本分類研究[J].北京郵電大學學報,2001,24(1):41-44.
〔5〕田文穎.文本特征提取方法研究.http://blog.csdn.net/tvetve/archive/2008/04/14/2292111.aspx.
〔6〕于瑞萍,張明.中文文本自動分類中特征詞選擇算法研究[J].硅谷,2009(12):61.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
