基于關聯數據的數字圖書館個性化信息推薦系統
2013-09-23 01:27:42付兵
圖書館學刊 2013年4期
付 兵
(湛江師范學院基礎教育學院圖書館,廣東 湛江 524037)
數字圖書館就是數字化的信息資源庫[1],其主要功能是為用戶提供信息服務。隨著Internet技術及信息技術的快速發展,信息資源內容豐富、形式多樣,但質量卻良莠不齊,信息的“爆炸”式增長使得信息的利用率反而降低,出現“信息超載”現象。如何從浩如煙海的信息海洋中快速找到自己所需的優質信息資源,是廣大信息用戶面臨的主要難題。隨著Lib2.0技術的出現和應用,個性化信息推薦服務逐漸成為數字圖書館新型服務模式的主流,其改變了傳統圖書館的被動服務方式,能根據用戶的興趣愛好主動為其推薦信息,從而提高了數字圖書館信息服務的質量。個性化推薦系統的主要算法有基于內容的推薦、基于協同過濾的推薦、基于關聯規則的推薦、基于用戶統計信息的推薦、基于知識的推薦等[2],個性化推薦在圖書館的研究應用主要是針對圖書的推薦,因此筆者設計了一個基于關聯規則數據挖掘技術的數字圖書館個性化信息推薦系統。
1 關聯規則數據挖掘
關聯規則是數據挖掘的主要技術之一[3]。所謂關聯規則,就是尋找描述數據庫中數據項(屬性、變量)之間存在或潛在的相關性。利用關聯規則的數據挖掘技術,可以找出大量數據之間未知的相互依賴關系[4]。由于關聯規則形式簡潔、易于解釋和理解并能有效捕捉數據間的重要關系,因此從大型數據庫中挖掘關聯規則已成為近年來數據挖掘領域的一個熱點。目前關聯規則數據挖掘技術已經廣泛應用于電子商務、人工智能、信息檢索、統計學、數據庫等眾多領域,并取得了一定的研究成果。
1.1 關聯規則的有關概念[5]
設I={i1,i2,…,im}是事務數據庫D中數據項的集合,則I稱為項集。含有k個數據項的項集稱為k-項集。事務T是項集I中的一些元素組成的集合,即T?I,在關系數據庫中相當于記錄。事務數據庫D是所有事務T的集合。關聯規則是形如 A?B 的蘊含式,其中,A?I,B?I,并且 A∩B=?。若規則A?B在事務集D中成立,則具有支持度(support)s和置信度(confidence)c,其中s是D中事務包含A∪B(即A和B二者)的百分比,c是D中包含A的事務同時也包含B的百分比。同時滿足最小支持度閾值(min_sup)和最小置信度閾值(min_conf)的規則稱作強規則,這些閾值可以由用戶或者專家設定。項集的出現頻率是包含項集的事務數,如果項集的出現頻率大于或等于min_sup與D中事務總數的乘積,則稱項集滿足最小支持度min_sup。如果項集滿足最小支持度,則稱它為頻繁項集。頻繁k-項集的集合通常記作Lk。
關聯規則數據挖掘可分為兩個步驟:第一步,找出數據庫中支持度大于最小支持閾值的所有頻繁項集;第二步,由這些頻繁項集中產生滿足最小置信度的強關聯規則。從兩個步驟中尋找所有頻繁項集是關鍵問題,它決定著關聯規則的整體性能。尋找頻繁項集的算法很多,下面我們介紹由Agrawa和Srikant提出的Apriori算法。
1.2 Apriori算法
Apriori算法是一種最有影響的挖掘關聯規則頻繁項集的算法,它的主要思想是利用逐層搜索的迭代方法,來尋找數據庫中的頻繁項集。算法描述如下:
算法 1(Apriori)[5]:使用逐層迭代找出頻繁項集
輸入:事務數據庫D;最小支持閾值min_sup。
輸出:D中的頻繁項集L。
方法:
①L1=find_frequent_1_itemsets(D);//找出頻繁 1-項集的集合L1;
②for(k=2;Lk-1≠?;k++){;
③Ck=apriori-gen(Lk-1,min_sup);//用 Lk-1產生候選 Ck;
④for each transition t∈D{//找出事務中是候選的所有子集,并對每個這樣的候選累加計數;
⑤Ct=Subset(Ck,t);
⑥for each candidate c∈Ct;
⑦c.count++;
⑧};
⑨Lk={c∈Ck|c.count>=min_sup};
⑩};
?return L={所有的 Lk}。
2 個性化信息推薦系統設計
2.1 設計思路
數字圖書館個性化信息推薦系統構建的最終目的是能夠在實際中得以應用,因此在設計時應當遵循易操作性、完整性、可更新性、可擴展性以及針對性的原則[6]。
首先,對數字圖書館中的各種信息資源數據庫進行分析,統計出信息資源的使用情況。同時,不同用戶群具有不同的特點和喜好,因此可以通過對信息資源的聚類分析,找到不同用戶群所需的信息資源,為個性化信息推薦提供參考。
其次,對用戶進行聚類分析。在數字圖書館的用戶中,由于專業背景、從事行業、興趣愛好等的不同,所需信息也不盡相同。因此,可以把具有相似專業背景、工作行業、興趣愛好等特點的用戶聚在一起,為同一類用戶推薦相似的信息。通過對用戶的聚類分析,可以了解用戶對數字圖書館信息資源的使用程度,為不同的用戶提供針對性的服務。
最后,分析信息資源之間的關聯性。例如,大多數對資源A感興趣的用戶對資源B也感興趣,當用戶在使用資源A的時候,可以將資源B推薦給他。也可以根據用戶的信息資源使用情況,將相關的資源推薦給用戶。
2.2 系統結構
個性化信息推薦系統主要包含3個層次,即數據存儲層、數據挖掘層和用戶界面層,如圖1。
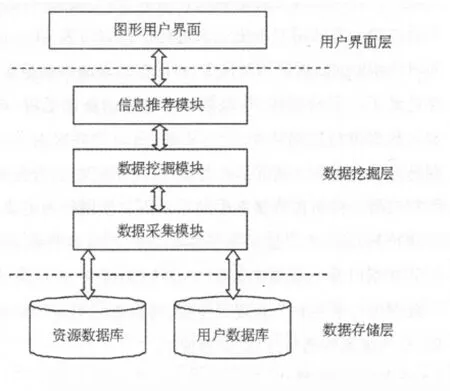
圖1 個性化信息推薦系統結構
2.2.1 數據存儲層
數據庫是數據挖掘的基礎,數據存儲層就是數字圖書館的各種數據庫,包括資源數據庫(館藏書目數據庫、電子資源數據庫)、用戶數據庫等。
2.2.2 數據挖掘層
數據挖掘層是個性化信息推薦系統的核心,主要是對數據進行處理,利用數據挖掘技術對信息資源和用戶信息進行采集和挖掘,對挖掘結果歸納分析后,針對不同用戶推薦其感興趣的信息。該層的主要功能模塊包括數據采集模塊、數據挖掘模塊以及信息推薦模塊。
2.2.3 用戶界面層
用戶界面層主要提供系統和用戶之間交流的平臺界面,是個性化信息推薦系統的輸入輸出層。用戶可通過該界面進行注冊、登錄,輸入各種個人信息、個性化信息要求、評價反饋信息等;系統可通過此界面展示數字圖書館信息資源,向用戶輸出個性化信息推薦結果。
2.3 系統功能模塊
2.3.1 數據采集模塊
該模塊包含信息資源采集模塊和用戶信息采集模塊。信息資源采集模塊從數字圖書館信息資源數據庫中獲取資源數據,為用戶提供各種信息資源的詳細信息(如資源的題名、作者、來源等)。用戶信息采集模塊收集用戶個人注冊以及興趣愛好等信息,并將用戶的歷史使用行為記錄、評價反饋等錄入用戶信息數據庫。
2.3.2 數據挖掘模塊
此模塊對信息資源和用戶信息進行挖掘,找出強關聯規則,建立規則庫,并對用戶進行聚類分析(可根據用戶所學專業、從事職業等聚類),找到各類用戶群。由于需要處理的數據量很大,非常耗時,所以該模塊主要是采用離線處理的工作模式。離線處理不會影響推薦結果,因為強關聯規則結果是通過對大量的用戶歷史記錄進行挖掘的結果,在一定的時間段內新增的數據量相對較少,對挖掘結果的影響是很小的,等達到了一定的時間,并積累了一定量的新記錄后,再重新加入數據進行挖掘計算,定時更新,所以關聯規則的離線發現是科學合理的。離線數據挖掘的工作流程是:首先把挖掘所需的所有存儲在數據庫中的用戶歷史使用行為記錄導出;其次把導出的原始數據按照挖掘規則刪除各種噪聲數據、空值數據以及不需要的數據,合并同類數據;最后將清理過的數據進行聚類和關聯規則挖掘,將挖掘結果進行結構化存儲,寫入規則數據庫,以供推薦使用。
2.3.3 信息推薦模塊
通過用戶登錄獲取其專業背景、興趣愛好、歷史使用行為以及正在瀏覽的信息,將這些信息與規則數據庫中的規則進行匹配,最終得到針對性很強的推薦結果,并將結果推薦給用戶。
3 個性化信息推薦過程
3.1 獲取信息
系統通過顯式和隱式兩種方式獲取用戶信息。對用戶的基本信息,如性別、年齡、學歷、專業、職業、興趣愛好等,采用顯式方式獲取,在用戶注冊時,要求用戶填寫。用戶的歷史瀏覽、借閱、下載、評價反饋等信息,系統隱式地記錄下來。系統將對獲取的用戶信息進行加工處理,提取用戶個體特征描述詞,動態地更新到用戶信息數據庫中。用戶信息的準確性和完整性將直接影響到信息推薦結果的質量。
3.2 匹配信息
用戶登錄系統后,系統將描述用戶的特征詞與規則數據庫中的規則進行匹配,將符合用戶個性化信息需求的信息資源檢索出來,并按照匹配度降序排列,將“TOP-N”個資源作為推薦結果。
3.3 推薦信息
系統可以通過網上實時推薦、電子郵件或手機短信等友好的方式,將推薦結果主動推送給用戶。用戶可以對推薦結果提出評價意見,系統根據用戶反饋的意見調整推薦結果,以更好地滿足用戶的個性化信息需求。
4 結語
個性化信息推薦系統涉及數據獲取、數據處理、算法選擇、參數優化、反饋信息收集、效果測試和改進等,不僅僅是一個或幾個推薦服務新的功能開發,還需要長期維護和改進,需要專業的團隊和持續的投入才能完成[7]。筆者采用關聯規則的數據挖掘技術,對數字圖書館的信息資源和用戶數據進行挖掘,并以此設計了個性化信息推薦系統。圖書館利用此系統,可以有效獲取用戶的個性化信息需求,變被動服務為主動推送服務,最大限度地提高信息資源的利用率。另外,數據挖掘結果還可為圖書館建立科學、合理的館藏資源結構提供重要的參考依據。
[1] 徐文伯.關于數字圖書館的幾點認識[J].情報資料工作,2001(3):16-17.
[2]劉飛飛.基于多目標優化雙聚類的數字圖書館協同過濾推薦系統[J].圖書情報工作,2011(7):111-113.
[3]Mehmed Kantardzic;閃四清,等譯.數據挖掘:概念、模型、方法和算法[M].北京:清華大學出版社,2003.
[4] 蔡會霞,朱潔,蔡瑞英.關聯規則的數據挖掘在高校圖書館系統中的應用[J].南京工業大學學報,2005(1):85-88.
[5]JiaweiHan,Micheline Kamber;范明,等譯.數據挖掘——概念與技術[M].北京:機械工業出版社,2001.
[6] 楊靜.電子商務中個性化推薦模型的研究[D].天津:天津師范大學,2006.
[7] gary.推薦系統五大問題[EB/OL].[2012-10-26].http://www.resyschina.com/2010/03/five_problems_of_resys.html.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
