
基于流親戚關系分組的流量識別算法
2013-10-16 12:01:08關卿秦宏偉張文超
計算機與網絡 2013年2期
關鍵詞:信息
關卿,秦宏偉,張文超
(解放軍63886 部隊,河南洛陽471003)
1 引言
現在因特網上出現了許多新型的網絡應用程序,這些應用程序具有比傳統應用程序更加復雜的交互結構和流量模式。當前流量分析領域的一個困難是傳統的方法無法分析這些新興的應用所產生的流量,需要一個新的方法來分析這些新興的應用流量。本文在對當前的流量識別算法進行深入探究的基礎上結合網絡應用交互特征,提出了一種基于流親戚關系分組的面向應用的流量識別算法(FRRG 算法)。該算法的核心思想是根據各流之間的外在特性對流進行分組,同一個組中的各流可以認為是同一個應用所產生的。該算法并不對網絡數據包的有效載荷[1]進行檢測,而是關注于其外在特性,即其五元組信息。因此該算法獨立于應用層所使用的具體協議,也與應用層的數據是否加密無關,從而克服了有效載荷檢測算法的弊端。
2 相關研究
當前的流量識別算法主要有2 種:有效載荷和非有效載荷[1]流量識別方法。
有效載荷檢測算法的基本思想是在包的有效載荷中識別特征位串,這些特征位串含有具體應用層協議的獨特特征。網絡 上 流 行 的9個P2P 協 議(eDonkey,FastTrack,BitTorrent,OpenNap,W inM x,Gnutella,MP2P,Soulseek,Areas,Direct Connect)都是運行在非標準、用戶自定義的私有協議之上,所有對它們進行P2P 流量的有效載荷識別就需要按照每一個特定包格式進行識別。這種方法能夠高精度的識別流媒體和P2P所產生的流量,但是,利用該算法進行流量識別存在一些與數據相關或者來自P2P 協議本質特性方面的限制。因為要對有效載荷進行檢查,系統的有效載荷正比于被捕獲的數據包數量和大小,這就造成了一定量的系統額外開銷。另外,當控制會話的端口號變化[2][3]時,這種方法也就不再有效。當控制會話的數據被加密后,比如P2P 的KaZaA[4][5]應用程序,有效載荷檢查的方法也沒用了。用這種方法來識別因特網流量,需要知道所有應用層協議的所有細節,很明顯這是不可能的。
非有效載荷流量識別算法僅僅檢測包頭信息來識別P2P流,而根本不檢測用戶的有效載荷,它是基于觀察源IP 和目標IP 的連接模式來識別網絡流量。該算法使用TCP/UDP 啟發式和{IP,port}啟發式來進行流量識別。該算法存在有以下的局限性:識別結果粒度太粗,僅能將流量識別為P2P 流和非P2P流,不能提供更加精確的識別,比如識別為具體某個應用所產生的流量;使用的方法太細粒度,僅僅關注于一些P2P 協議中交互的細微特征來進行識別,一旦將來P2P 協議關于這些細微特征有了改變,該算法將毫無用處;利用P2PIP 列表會造成誤判,可擴展性較差。
3 基于流親戚關系分組的流量識別算法
3.1 算法主要思想
流親戚關系分組 (Flow Relative Relation Group,簡寫FRRG)的應用層流量識別方法,它的主要思想就是仔細探究同一個應用程序所產生各流的相關依賴性,然后根據所屬應用程序將流分組,同一組中的流可以認為是同一個應用程序產生的。該方法包括3個部分,如圖1 所示。在此方法中,并沒有對每個包進行有效載荷檢測,這是因為有效載荷檢測會使性能嚴重下降,而且在許多情況下還不適用。我們僅僅使用包頭信息,并將這些信息聚合成流。
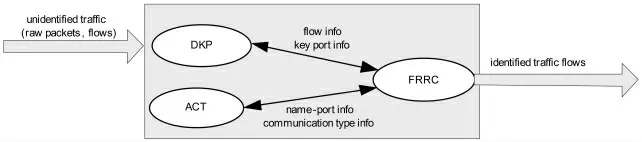
圖1 流量識別方法示意圖
第1 步是構建應用程序特征表(Application Characteristic Table,簡寫ACT),這可以通過離線使用多種包分析工具來完成。該表包括應用程序名稱、除去動態分配的端口外經常使用的端口、傳輸層的協議號、以及該應用程序的交互方式等。這些信息在第3 步流親戚關系計量中用來決定應用程序的名字。
第2 步是決定關鍵端口(Decide Key Port,簡寫DKP)。DKP的輸入是原始包或流數據,輸出流信息和關鍵端口信息。在這一步中,流信息是根據捕獲包的五元組信息得到的,這五元組分別是源IP 地址、源端口、目標IP 地址、目標端口、傳輸協議。從TCP 流信息中選擇出關鍵端口號,由于許多流的源端口和目的端口都超過1024,這一步并非很簡單。因此很有必要分清哪個是關鍵端口,這樣才能準確的定出相應的應用程序名字。
第3 步就是對DKP 輸出的流數據進行分析、整合,流親戚關系計量(Flow Relative Relation Computing,簡寫FRRC)根據各流之間的關系對流進行分組,并用相應的應用程序名字標識該流。絕大多數新興的網絡程序都使用多個會話與一個或多個節點進行交互,所以完全有可能揭示出同一個應用程序所產生的各流的關系。根據這種流與流間的依賴關系,可以將流分成一些組。比如說MSN messenger 所產生的流被FRRC分在同一個組中。分組之后,FRRC 就可以根據應用程序特征表ACT 來決定每個組的應用程序名字。
3.2 應用程序特征表
為了從捕獲的流信息中決定應用程序的名字,需要對廣泛使用的應用程序之間的交互行為進行研究,并給出這些應用程序的名稱、使用的缺省端口號、傳輸協議以及交互類型。使用tcpdump 和ethereal 對這些應用程序所產生的流量進行分析,然后據此來構建ACT。這個ACT 實際上可看作是IANA端口列表的一個擴展,里面包含了更多的內容。對多個網絡上最流行的應用程序做上述實驗,即可構建一個ACT,表1 示意了其中的一小部分。

表1 應用程序特征表(部分)
3.3 決定關鍵端口
所謂關鍵端口是指在流量識別中起決定作用的端口號。一個正常TCP 的交互使用3 次握手機制在一個服務器和一個客戶端之間建立連接,互相發送FIN 數據包來結束這個連接。在TCP 會話中,服務器打開一個端口等待客戶發來連接請求。對于流量識別來說,服務器的監聽端口是個很重要的端口。那么如何從被捕獲的包中得到服務端的監聽端口呢?首先,利用3 次握手中使用的SYN 包和SYN- ACK 包。SYN 包的目標端口和SYN- ACK 包的源端口就是服務器的監聽端口,利用這個結論可以從所有的TCP 流中決定關鍵端口號。然而在實際的互聯網環境中,經常捕獲到SYN 包而沒有SYN- ACK 包,所以需要同時檢查SYN 包和SYN- ACK 包。在DKP 中一個很基本的步驟就是要檢查一個流是否有與之對應的相反流,因此可在決定關鍵端口時排除沒有對應相反流的流。為了提高DKP 算法的性能,可利用這樣一個事實:沒有系統使用低于1024 的端口號作為客戶端隨機端口號,系統隨機產生的端口號都大于1024。因此可在應用SYN/SYN- ACK 方法之前,通過檢查是否有小于1024 的端口號來決定關鍵端口。
在實際的環境中,還需考慮幾種情況。第一,在高速鏈路上可能無法捕獲DKP 所需的所有包,有時這是因為使用了采樣機制而有意的丟失一些包,有時則是因為不對稱路由和捕獲系統性能的限制而丟失一些包。第二,在那些維持時間很長的TCP 會話中,比如流媒體服務、Vo IP 服務、網絡游戲等,SYN 包和SYN- ACK 包僅出現在TCP 連接的開始,如果從這些連接的中間開始捕獲數據包,則很有可能無法得到這些流的關鍵端口。第三,還要考慮一些比如Cisco NetFlow 的流數據,它們作為DKP 模塊的輸入可以將該方法擴展到多個不同的環境中,在這種情況下,流信息可能不包括作為識別關鍵端口線索的TCP 標志信息(比如Cisco NetFlow V5 不包括這種信息)。為了在DKP 方法中解決這個問題,特提出公理集1 的5 條公理:
公理集1:
前三條公理是顯而易見的,后兩條公理在普通網絡上也都成立。利用DKP 算法和公理集1 的組合,可以識別因特網上幾乎所有的TCP 流,剩下的TCP 流可以看作是DoS/DDoS或蠕蟲病毒所產生的異常流量。對于UDP 流,因為它不像TCP 流那樣使用3 次握手機制,所以不能使用這種方法,但是可以用FRRC 算法直接組合UDP 流。
3.4 流親戚關系計量
FRRC 算法是基于這樣的一個事實:同一個應用程序所產生的各流之間存在相關依賴性,根據這種依賴性FRRC 將每個流歸入不同的集合中,屬于同一個集合的流是同一個應用程序所產生的。FRRC 算法包括2個連續的過程:外表關系分組 (Facet Relation Group,簡寫FRG) 和地理關系分組(Geography Relation Group,簡寫GRG)。
(1)外表關系分組
該算法根據每個流的屬性相關性對其進行分類。外表關系可定義為同一個應用程序所產生的2 條流在協議、端口號、IP 地址等方面的關系。公理集2 適用于TCP 流和UDP 流,可以用來進行外表關系分組。
公理集2:
FRG 算法的流程如下:第一在被捕獲的流中選擇一條流,第二再選擇該流所對應的相反流,第三選擇與已選擇的流在屬性源IP 地址、源端口、協議相同的流,第四選擇與已選擇的流在屬性目標IP 地址、目標端口、協議相同的流,第五對在第三步和第四步選擇的流重復從第二步到第四步的過程,這個遞歸的過程一直持續直到沒有新的流被選進來。結束了選擇的第一條流的組合過程,再從剩下的流中選擇另外一條流,繼續上述步驟直到沒有剩余的流。
可以將FRG 算法毫無修改的應用于UDP 流;然而對于TCP 流,還需要對FRG 算法進行些許修改,這是因為在TCP連接中,客戶端不能使用單個端口號建立多個連接,而服務器端卻可以使用單個端口號建立多個連接。為了提高FRG 算法的性能,可將該算法應用于DKP 算法的輸出流上,當然這些輸出流的關鍵端口已被確定。
(2)地理關系分組
利用FRG 算法,可以將TCP 流和UDP 流分在一些FRG組中,屬于同一組中的流可以認為是同一個應用程序所產生。但是,還不能保證同一個應用程序所產生的流被分在同一個FRG 組中。為了解決FRG 算法無法克服的問題,提出一種稱為地理關系分組(GRG)的算法。GRG 算法是在FRG 算法的基礎上,給出一種定量描述來衡量FRG 各組間的關系:求出每一對FRG 組之間的關系權重,如果這個權重超過一個指定的閾值,便可以將這2個FRG 組合并為一個單一的組。
4 實驗及算法對比
4.1 分析標準P2P 協議流量時,PE 算法和FRRG 算法的對比
關閉所有主機上的所有網絡軟件;運行Ethereal,設置混合模式,并開始捕獲包;然后同時在每臺主機上運行BitTorren 軟件,下載同一個文件;確保所采集到的流量都是BitTorent 軟件下載該文件的相關流量。文件下載完畢后,Ethereal 停止捕獲報文。將Ethereal 捕獲的流量蹤跡分別用基于流親戚關系的流量識別算法和有效載荷檢測算法進行分析,所得的結果如圖2 所示:

圖2 BitTorrent 流量的兩種識別算法對比
4.2 分析包括非標準P2P 協議流量時,PE 算法和FRRG 算法的對比
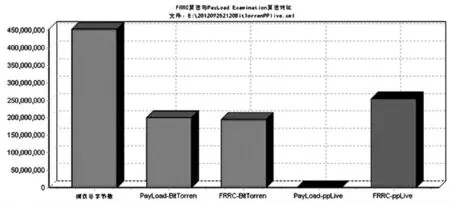
圖3 BitTorrent 和ppLive 流量的2 種識別算法對比
運行Ethereal,并開始捕獲包;同時在每臺主機上運行BitTorren 軟件,下載同一個文件;然后同時在每臺主機上運行ppLive 軟件,觀看同一部電影。所有主機的文件都下載完畢后,Ethereal 停止捕獲報文。將Ethereal 捕獲的流量蹤跡分別用基于流親戚關系的流量識別算法和有效載荷檢測算法進行分析,所得的結果如圖3 所示.
5 結束語
本文提出的FRRG 算法克服了有效載荷檢測算法的弊端,實驗結果表明該算法運行良好,在一定的條件下,進行流量識別的準確率較高,并且具有較強的可擴展性。FRRG 算法僅對IP 數據包的三層信息進行分析,由于特征信息較少,因此不可避免造成些許誤判,下一步將考慮如何從其它層中抽取特征信息,以及自動構建應用程序特征表等問題,來增強FRRG 算法效率和適用性。
[1]Remco Poortinga,Remco van de Meent,and Aiko Pras.Analysing Campus Traffic Using the meter- M IB[C].Proc.of the Passive and Active Measurement W orkshop(PAM 2002),Mar.25- 27,2002.
[2]Hun- Jeong Kang,Myung- Sup Kim,and James Won- Ki Hong.A Method on Multimedia Service Traffic Monitoring and Analysis[C].Lecture Notes in Computer Science 2867,Edited by Marcus Brunner,Alexander Keller,14th IFIP/IEEE Int’l W orkshop on Distributed Systems:Operations and Management(DSOM 2003), Heidelberg,Germany,Oct.2003:93- 105.
[3]Hun- Jeong Kang,Hong- Taek Ju,M yung- Sup Kim,and James W.Hong.Towards Stream ing Media Traffic Monitoring and Analysis[C].Proc.of 2002 Asia- Pacific Network Operations and Management Symp.(APNOMS 2002),Jeju,Korea,Sept.25- 27,2002:503- 504.
[4]Nathaniel Leibow itz,Matei Ripeanu,and Adam W ierzbicki.Deconstructing the KaZaA Network[C].3rd IEEE W orkshop on Internet Applications(W IAPP'03),June 2003.
[5]Nathaniel Leibow itz,Aviv Bergman,Roy Ben- Shaul,and Aviv Shavit.Are File Swapping Networks Cacheable[C].7th Int’l W orkshop on WebContent Caching and Distribution(WCW),Boulder,Colorado,Aug.14- 4,2002.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
