基于MHBT的數據庫隔離與恢復模型
2013-10-17 06:09:08趙飛蘇忠丁小
網絡安全技術與應用 2013年10期
趙 飛 蘇 忠 丁 小
(1.空軍指揮學院 網絡中心 北京 100097 2.95865部隊 北京 100092)
0 引言
數據庫安全一直以來都是信息安全領域的熱點問題。隨著云計算、物聯網等新興技術的迅速發展,以及社交網絡、微博、推特等新型網絡應用的快速普及,包括銀行、鐵路、水電等基礎設施要害領域的信息系統的安全受到更加廣泛關注,而信息系統是否安全在很大程度上取決于數據庫的安全。傳統的數據庫安全機制側重于保護數據的保密性、完整性和可用性,但無法滿足數據庫可生存性要求,即數據庫在遭受到非人為系統故障、內部或外部攻擊時持續提供關鍵服務的能力。要實現數據庫可生存性,很關鍵的一點是必須能夠快速發現并隔離惡意事務和受污染數據,并且及時恢復相關事務和數據。隨著數據庫數據規模的急劇增大,事務提交異常頻繁,如何能夠在惡意事務檢測以后,在確保隔離精度的前提下,最大限度的減少隔離和恢復的時間就成為一個重要的研究方向,因為它直接關系著數據庫持續提供服務的能力。
1 相關研究
Merkle Hash Tree(MHT)最早被引入到驗證服務數據的真實性是在文獻[1]中,它解決了指定查詢服務結果可靠性的認證問題。Martel 等人在解決在線數據庫查詢安全認證問題時提出了檢索有向非循環圖(search directed acyclic graph)的驗證方法[2],并引入了MHT結構,提升了檢查的效率。Devanbu 等人提出一種基于MHT的驗證機制來解決第三方數據發布方的數據完整性和可靠性驗證問題[3],在機制中要求數據庫所有者為每一個數據表建立MHT,并將MHT根處的信息摘要直接發給用戶,以此來實現查詢結果的驗證。Ma 等人在文獻[3]基礎上作了修改[4],對單獨元組的屬性值建立MHT,從而在驗證時能夠精確到數據元組,提升了驗證精度和效率。Pang H 等人從查詢結果的完整性和可靠性兩個方面對文獻[3]中提出的方法作了實驗性驗證[5],內容涵蓋了查詢、查詢投影、多點查詢等數據庫常用服務功能,并從通信代價、數據庫升級代價等角度對模型進行了量化分析,具有很強的現實意義。
以上基于MHT的方法都是建立在第三方(外包)數據庫服務方靜態環境條件下(許多是基于理想化模型條件),解決的問題為數據庫查詢的正確性和完整性要求。Li 等人在文獻[2]的基礎上,提出了查詢事務及時性的驗證需求[6],并通過引入B+-tree設計驗證索引結構Merkle B-tree,建立驗證模型,同時還將設計方法拓展到動態數據庫服務中,提出Embedded Merkle B-tree的數據結構,合理的緩解了驗證結構存儲空間消耗問題。Jain 等人在文獻[6]基礎上提出了事務完整性的概念[7],設計的基于Merkle Hash B+-Tree(MHBT)模型不僅能夠實現驗證數據正確性和完整性的要求,還能夠通過建立事務執行與數據庫狀態結構MHBT之間的對應關系,驗證事務執行的完整性,并實現攻擊數據恢復操作。
2 基本概念介紹
2.1 單列哈希算法
單向哈希函數h()可以把一個變長的輸入值x通過函數計算輸出為一個定長值y,即:y=h(x),單向哈希函數h()具有單向性、唯一性等特點。單向性是指:給定一個哈希值y和函數h(),不可能找到一個值x,使得h(x)=y;唯一性是指:不可能找到兩個不同的值x、y,使得h(x)=h(y)。目前常用的單向哈希函數是SHA-256。
2.2 Merkle哈希樹
Merkle哈希樹,又被稱為哈希樹或Merkle樹,1979年由Ralph Merkle首先提出,主要用于對特定對象的認證。MHT是一棵完全二叉樹,在這棵樹中,葉節點為需認證的對象的哈希值,而中間節點則是其左右孩子節點的并置哈希值。圖1所示的是一棵Merkle哈希樹示意圖。
在圖1里,Merkle哈希樹共有四個葉節點{S1,S2,S3,S4},其值分別為需認證的對象{O1,O2,O3,O4}的哈希值,即Si=H(Oi)(i=1,2,3,4)(H()為單向哈希函數);非葉節點S34可表示為S34=H(S3||S4)。“||”表示并置操作。
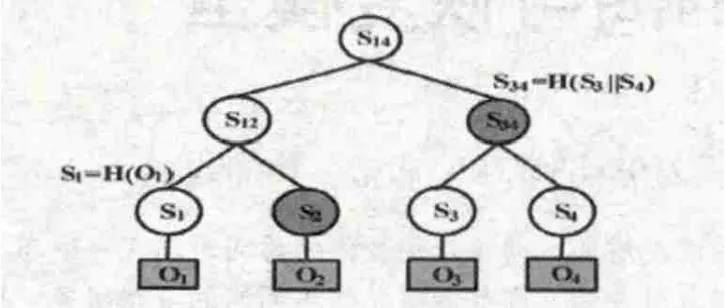
圖1 Merkle哈希樹
2.3 B+-tree
B+樹是平衡多叉樹。一棵m階B+樹的定義如下[8]:
樹中每個非葉節點最多有m棵子樹;
根節點(非葉節點) 至少有2棵子樹。除根節點外,其它的非葉節點至少有棵子樹;
若根節點同時又是葉節點,則節點格式同葉節點。
有n 棵子樹的節點有n個關鍵碼,對應的指向對象的地址指針也有n個;
所有非葉節點中包含下列信息數據( n,K1,P1,K2,P2,… ,Kn,Pn),其中: Ki(i=1,…,n)為關鍵碼,且Ki<Ki+1,Pi(i=0,…,n)為指向子樹根節點的指針,n為關鍵碼的個數;
所有的非葉子節點可以看成是索引部分,節點中僅含有其子樹(根節點)中的最小(或最大)關鍵碼;
每個葉節點中的子樹棵數可以多于m,可以少于m,視關鍵碼字節數及對象地址指針字節數而定。
所有葉節點都處于同一層次上,包含了全部關鍵碼及指向相應數據對象存放地址的指針,且葉節點本身按關鍵碼從小到大順序鏈接;
在B+樹中有兩個頭指針:一個指向B+樹的根節點,一個指向關鍵碼最小(或最大)的葉節點。圖2是一棵3階的B+樹示意圖[8]。
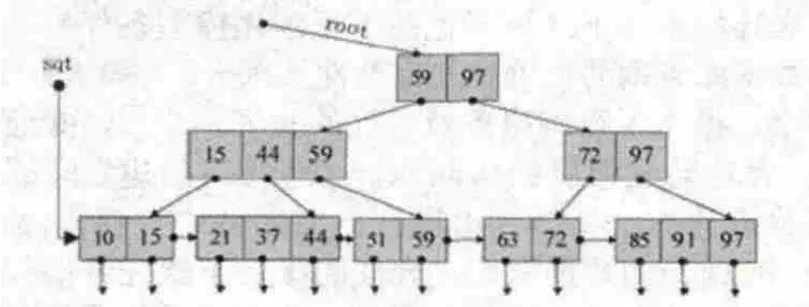
圖2 B+樹
2.4 Merkle哈希B+樹
Merkle哈希B+樹(Merkle Hash B+-Tree ,MHBT)就是將MHT中的樹結構拓展成為B+樹,如同構建MHT一樣,對B+樹采用分層哈希的模式。一個MHBT的數據結構有著與常規B+樹相同的節點構成,所不同的是在每個節點處擴充的加入了節點標記值,每個節點的標記值是孩子節點哈希值的并置哈希值,其計算方法如同MHT:非葉子節點的標記值通過計算子節點標記值的并置哈希值求得;葉子節點的標記值通過計算該節點所包含數據元組哈希值獲得。如圖3(a)所示,數據庫初始化時,對所有的數據元組進行哈希運算后,依據B+樹的構建方法,逐級構建此時的證據結構MHBT。具體詳細的節點示意圖如圖3(b)所示,其中kj為節點的關鍵碼值,pj為指針,hj為節點的標記值(其中hi…hk為該節點下屬孩子節點標記值的并置哈希值),節點i為非葉子節點,hi為該節點標記值,即節點所指向數據元組哈希值的并置哈希值。
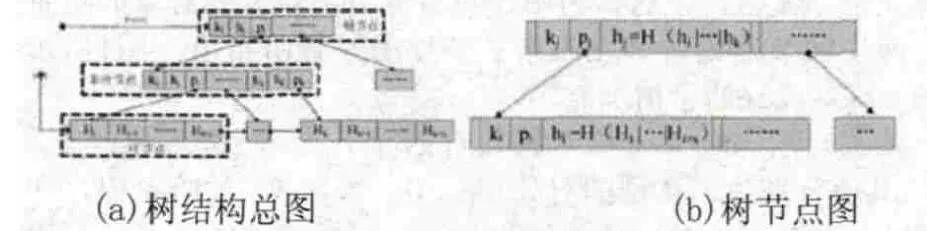
圖3 Merkle哈希B+樹
3 基于MHBT的隔離與恢復模型
3.1 假設條件
模型自身并不檢測惡意事務。本文設計模型本身并不檢測一個事務是否為惡意,惡意事務的檢測由入侵檢測系統完成,模型的主要功能是在惡意事務信息的基礎上,快速準確的隔離污染事務及相應的受損數據。
數據庫事務的提交是嚴格串行化的。為了能夠確保數據有最嚴格意義的準確性和完整性,這里我們假設數據庫事務的提交是嚴格串行化的,事務執行的完整性要求每一個事務在提交時數據庫必須處于一致的狀態,即之前所有的合法的提交事務都已全部有序的提交并修改完相應的數據元組,從而確保數據庫狀態變化的與事務提交之間的強相關性。
事務本身限定其具有可復制性。事務的可復制性是指事務具有確定性,即在數據庫穩定狀態上,事務的執行結果完全由讀取的數據庫值和外部輸入的參數值決定,撤銷重做執行結果相同。
3.2 系統模型
模型中采用“三方”機制運行,分別是數據庫服務端、數據庫客戶端和MHBT存儲端。其中,數據庫服務端與客戶端采用“一對多”模式,即一個數據庫服務端對應有多個數據庫客戶端,MHBT存儲端為一個。系統模型如圖4所示。
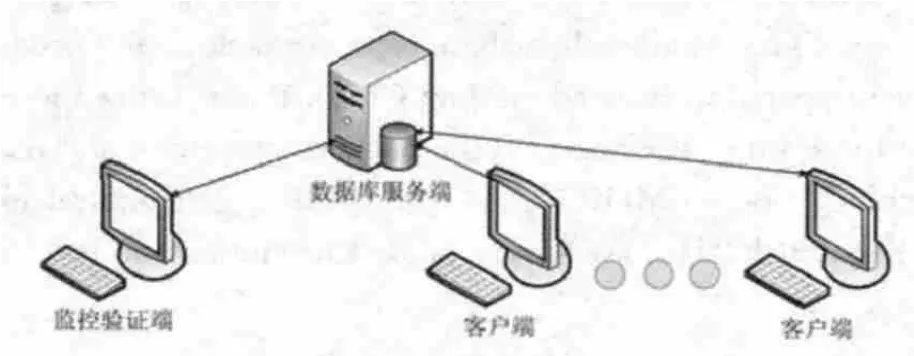
圖4 系統模型
3.3 模型描述
在以上假設條件基礎上,就可以設計模型使用MHBT來建立事務與數據庫狀態之間的關系模型:數據庫每一次狀態變化都可以通過更新MHBT的證據結構來記錄,而MHBT的更新又是建立在事務提交的基礎上,新的樹形結構是在之前樹結構應用事務執行結果后計算而來的,這樣就能夠通過MHBT建立數據庫狀態和事務提交之間的一一對應關系。
3.3.1 初始化
在數據庫開始向用戶提供服務前,首先構造數據庫初始狀態時的MHBT0。MHBT存儲端復制初始狀態時數據庫服務端的所有數據元組,根據2.4節中MHBT構建方法,對此時數據庫所擁有的所有數據表,建立初始狀態時各自的證據結構MHBT0,證據結構中所有節點的信息通過MHBT存儲端建立存儲表的形式存儲。此后數據庫服務端開始正常工作,接收用戶發來的請求事務。圖5為一個簡單的數據庫表1在初始化時的示例,為了便于演示,我們將每條數據記錄(數據元組)以t1,t2,t3…代號的形式表示,Hi為該條數據元組的哈希值。
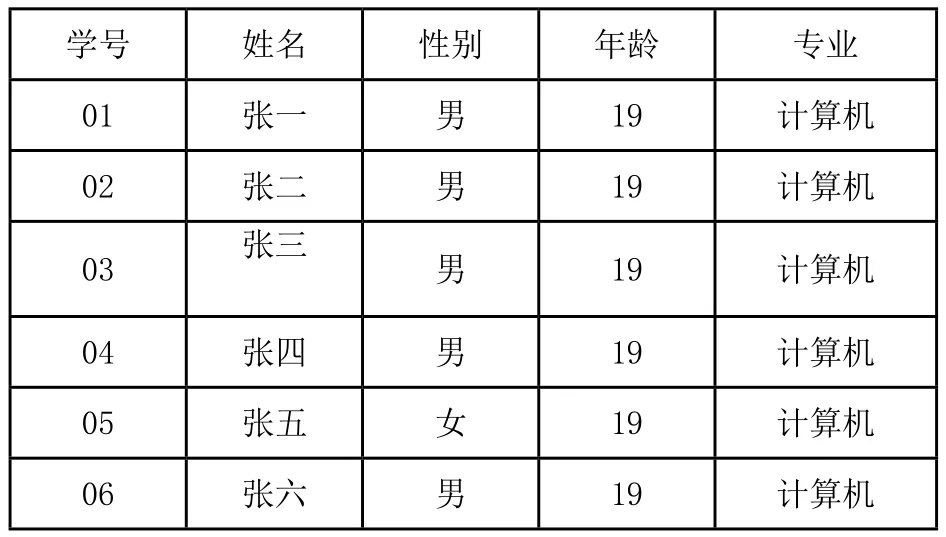
表1 數據庫初始化時數
07 張七 男 19 計算機…… …… …… …… ……18 張18 男 19 計算機…… …… …… …… ……26 張26 男 19 計算機27 張27 男 19 計算機

圖5 模型初始化MHBT0示例
3.3.2 事務執行
數據庫在執行事務時先記錄被修改數據元組的信息,如果事務提交成功,數據庫就將更新的數據元組和事務標識號(事務在數據庫服務端的標識信息)發送到MHBT存儲端,而后再將事務執行結果集返回給客戶端。MHBT存儲端根據事務標識號和修改的數據元組更新證據機構MHBT。具體如圖6所示,事務的提交是串行化的,如果i是做為本次提交事務的標識號,數據庫就將識別其為事務Ti,即第i個提交的事務,串行化隔離級別能夠確保事務Ti的執行是在DBi-1的狀態上(之前所有事務全部響應后的一致狀態),事務執行后數據庫進入下一個一致狀態DBi,數據庫服務端將修改的數據元組與相應的事務位置號Ti一并發送給MHBT存儲端,而后數據庫服務端向用戶發送響應信息:事務序列號(客戶端查證事務)、事務執行結果集。MHBT存儲端根據收到的事務標識號和所修改的數據元組計算相應的證據結構MHBTi(從之前的MHBTi-1基礎上計算當前的MHBTi:未修改元組直接讀取MHBTi-1中記錄的節點值,有改動數據元組計算哈希值并存入相應節點后與未修改數據元組節點一起生成新的證據機構MHBTi),做為當前事務執行后的數據庫狀態信息。

圖6 事務執行過程
3.3.3 事務與數據隔離
當入侵檢測系統檢測到惡意事務后,數據庫會根據事務標識號i調取惡意事務的證據結構MHBTi,因為數據庫是嚴格串行化隔離的,所以受影響的事務必定是在事務i提交之后的事務,MHBT通過比對事務i之后的所有證據結構能夠快速的確定受影響事務。
證據結構具體比對方法是:
(1)比較根節點的值。在證據結構歷史表中存儲有數據庫歷次更新后,各節點的變更信息,依據事務號及節點層級號能夠快速實施對根節點的比對:如果根節點值一樣,則根據MHBT樹結構的特點,可以判定該事務沒有修改任何數據元組,為只讀事務,不記錄到寫事務表中;如果根節點值不一樣,則能確定該事務對數據元組執行了修改操作,為寫事務,記錄到寫事務列表中,同時,依據證據結構歷史表中存儲的信息,比對出所有變化的葉結點信息,以此來鎖定所有被修改的數據元組。如圖7中所示,T(1),T(2),T(3),T(11)都執行了寫操作,在首次判定時都會被記錄到寫事務列表中,而T(12)僅讀取了數據,沒有修改數據,這里就不做記錄。
(2)依次比對寫事務列表。依據寫事務列表所對應的MHBT樹結構,比對出后一事務在之前事務基礎上做的數據修改,記錄相應改變的數據元組。如果改變數據元組中包含有受損數據元組或污染數據元組,則定義該事務為強相關事務,記錄到待恢復事務列表中,所有修改元組記錄為污染數據;如果不包含受損數據元組或污染數據元組,則記錄為嫌疑事務,進入到下層比對模型。如7圖中所示,事務T(1),T(2)對應的證據結構中,比對出的修改元組包含有受損數據X,因為事務T(1) ,T(2)對X執行了寫操作,會被判定為強相關事務,記錄到待恢復列表中,數據Y記錄為污染數據;事務T(3),T(11)與其之前證據結構比對出的修改數據元組不包含有受損數據X及污染數據Y,判定為嫌疑事務,進入到下層比對模型中。
(3)嫌疑事務判定。對2記錄的嫌疑事務,MHBT存儲端會通過其事務標識號讀取數據庫服務端事務日志記錄中的事務操作信息,如果該事務有讀取受損數據或污染數據的操作,則判定為污染事務,記錄到待恢復事務列表中;如果該事務沒有讀取受損數據的操作,則可以判定為正常事務,釋放相關的加鎖數據元組。如圖7中所示,事務T(3)有執行讀取數據X的操作,被判定為污染事務,記錄到待恢復事務列表中;事務T(11)沒有執行數據X的讀操作,雖然有修改數據庫中數據,但仍就判定為正常事務,釋放對數據U的鎖定操作。
圖8為具體事務的比對流程。
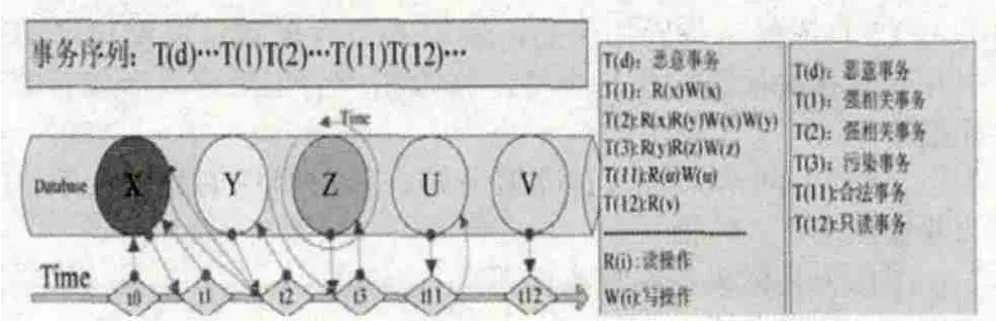
圖7 數據庫事務分類圖
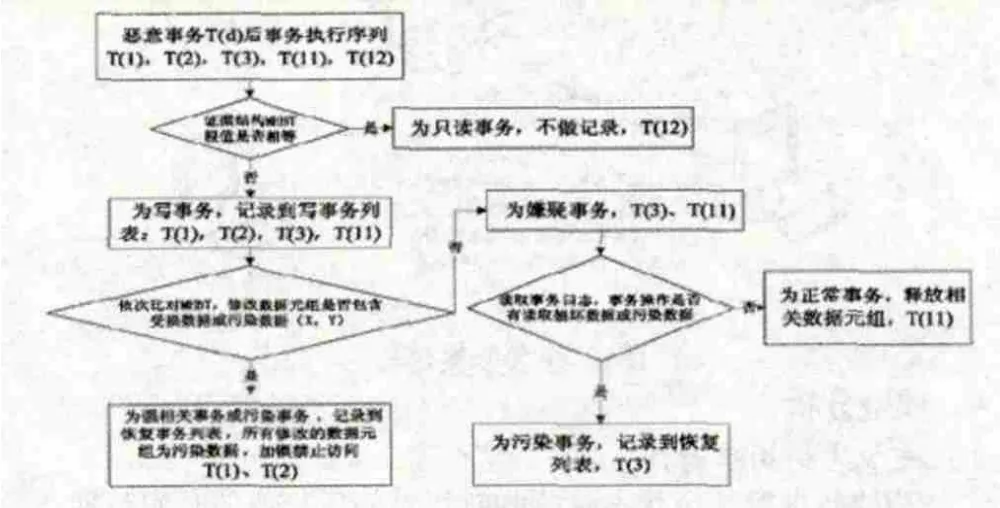
圖8 事務比對流程
可生存性保證:MHBT存儲端將事務隔離確定的受損數據和污染數據以事務請求方式在數據庫服務端加鎖(利用數據庫中的排他鎖,對相關數據實施加鎖操作),新事務請求中如果有訪問到這兩種數據則推遲執行,等待訪問數據的恢復操作;如果沒有則正常提交事務,按要求生成新的數據庫證據結構記錄到MHBT存儲端相關的數據表中。這樣就將正確數據與錯誤數據合理分割,區別對待,在確保數據庫持續提供服務的同時執行受損數據的逐個恢復,最大限度的保證用戶的服務請求,如圖9所示。
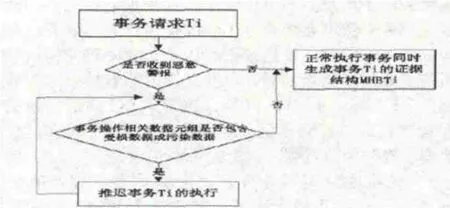
圖9 數據庫服務端事務執行流程圖
3.3.4 數據修復
在數據庫服務端的歷次更新中,模型運行機的歷史表中記錄了所有變化的元組值,當需要修復時,MHBT存儲端能夠通過事務號查到在執行本次事務時,數據庫修改元組和節點值時所參照的上一數據庫服務端的狀態結構信息(參照的相關元組值);待修列表中事務按提交號順序排列,通過讀取事務日志信息,執行事務的重做操作,恢復數據服務端到正確狀態。
在數據庫服務端的歷次更新中,MHBT存儲端的數據元組歷史表中記錄了歷次修改的數據元組值,當需要修復時,MHBT存儲端能夠通過事務號查詢到在執行本次事務時,數據庫修改數據元組和節點值時所參照的上一數據庫服務端的狀態結構信息;待修列表中事務按標識號順序排列,通過讀取事務日志信息,執行事務的重做操作,恢復數據服務端到正確狀態。具體恢復恢復方法是:
(1)將隔離模型中所確定待修復事務按標識號順序排列,標識號在數據庫服務端是按事務提交順序依次遞增排列的,順序排列修復事務,能夠有效提高讀取數據庫服務端事務日志記錄的效率。
(2)讀取數據庫服務端事務日志,索取事務具體的操作序列。
(3)依據事務操作信息,讀取MHBT存儲端證據結構MHBT中存儲的相關信息,執行事務,修改相應的記錄值,形成新的證據結構。
(4)返回結果給數據庫服務端,修改對應的數據元組,解除加鎖操作。
圖10為具體事務恢復流程圖。
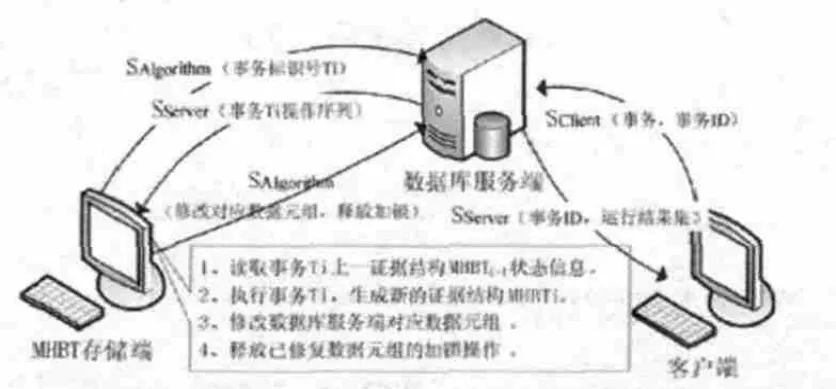
圖10 事務修復過程
4 模型分析
4.1 狀態結構構建時間
構建數據庫某個狀態時的MHBT樹結構所耗費的時間包括計算每個數據元組的哈希值以及樹中每個節點哈希值,另外還有將這些節點信息寫入磁盤的時間。
一個數據庫擁有n個元組,扇出(fanout,非葉結點平均擁有的孩子節點數)為,如果構建MHBT樹的高度為d,那么樹中構建的節點為:

則構建樹的時間為:

其中,Sn樹節點占用存儲塊大小,St數據元組占有存儲塊大小,Ch為計算一個哈希值所需要的時間,CIO為一個數據塊的IO時間消耗。構建證據樹MHBT的時間復雜度為,正比于數據庫的存儲容量。
4.2 狀態結構存儲空間分析
所提出的模型模型需要存儲數據更新歷史中的所有元組和節點的值及更新后的元組和節點值,所以這里所需的存儲空間相當于MHBT樹的兩倍,所以在k次更新后,模型所需要的存儲空間為:

模型的空間復雜度為O(n+klog(n)),正比于數據庫容量和數據更新次數。
4.3 數據庫更新延遲分析
在MHBT樹中插入或刪除一個元組,相應的從葉子節點到根節點的路徑信息都需要更新,并且更新后的結果值還要寫入到歷史記錄表中,所以更新數據所需的時間為:

其時間復雜度為O(logn)
4.4 模型運行效率分析
隔離模型的模型核心是對MHBT樹的比對,而MHBT樹又以元組的形式記錄在數據庫表中,故模型相當于是在數據庫表中查詢和比對相應元組值是否相等,查詢時間復雜度為:

5 結束語
傳統基于檢查點的數據庫恢復技術,不論是物理恢復還是邏輯恢復,都需要停止數據庫服務,而且要花費相當長的時間(將檢查點之后的所有數據重新操作一遍)來恢復,本文提出的模型機制能夠在確定惡意事務的前提下,通過比對MHBT中數據元組值的變化情況,并結合日志記錄中事務的操作信息,實現對污染數據的精確隔離;同時,通過數據與事務之間的依賴關系,從日志記錄中篩選出污染事務,實施精確修復,減少了數據修復時間,提升數據庫恢復的效率,最大限度的保證了數據庫的可生存性。模型機制的優點是與數據庫日志系統相結合,但又不完全依賴于日志系統。在不停止數據庫服務的前提下,充分發揮MHBT樹的數據結構特點,提升數據庫隔離的精度和速度,提高數據恢復的效率。文章最后通過數學分析評估了模型的性能,在下一步的工作中,將針對論文中提出的分析評價參數,展開算法模型的設計與實驗性驗證,以在實際應用中分析模型的可行性和高效性。
[1]Merkle R C.A certified digital signature[C]//Advances in Cryptology—CRYPTO’89 Proceedings.Springer New York,1990: 218-238.
[2]Martel C,Nuckolls G,Devanbu P,et al.A general model for authenticated data structures[J].Algorithmica,2004,39(1): 21-41.
[3]Devanbu P,Gertz M,Martel C,et al.Authentic data publication over the internet[J].Journal of Computer Security,2003,11(3):291-314.
[4]Ma D,Deng R,and Pang H.Authenticating Query Results From Untrusted Servers Over Open Networks.In Submitted for Publication,2004.
[5]Pang H H,Jain A,Ramamritham K,et al.Verifying completeness of relational query results in data publishing[C]//Proceedings of the 2005 ACM SIGMOD international conference on Management of data.ACM,2005: 407-418.
[6]Li F,Hadjieleftheriou M,Kollios G,et al.Dynamic authenticated index structures for outsourced databases[C]//Proceedings of the 2006 ACM SIGMOD international conference on Management of data.ACM,2006: 121-132.
[7]Jain R,Prabhakar S.Trustworthy Data from Untrusted Databases[C].ICDE,2013.
[8]嚴蔚敏,吳偉民.數據結構(C語言版)[M].清華大學出版社,2011.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
核科學與工程(2015年4期)2015-09-26 11:59:03
