有限存儲分布式社交網絡中數據的動態劃分和復制
2013-10-20 08:36:20鄧倩妮
微型電腦應用 2013年12期
關鍵詞:用戶
呂 品,鄧倩妮
0 引言
隨著 Facebook的誕生,社交網絡經歷了幾何式的爆炸增長。由于規模龐大,社交網絡的存儲系統大多分布在服務器集群而非單一服務器上,用戶數據以多份拷貝的形式保存在不同節點,我們把原始數據稱為主本,為了保持冗余性而創建的拷貝稱為副本。
讀操作和寫操作是社交網絡中最常見的兩種操作,讀操作可以發生在主本和副本之間,寫操作只能發生在兩個主本之間,隨后將信息傳遞給相應的副本。讀寫操作對應的數據不在同一存儲節點就會產生跨節點的遠程訪問,大量的遠程訪問會導致通信網絡的擁塞,延遲訪問時間,降低用戶體驗。以上問題的直觀解決辦法就是將經常交互的用戶的數據放在同一存儲節點,通過避免遠程訪問來減少節點間通信。
1 分布式儲存系統
目前已有的一些分布式存儲系統,如 Cassandra[1]、Dynamo等[2],僅采用了隨機分配復制策略,產生大量的遠程訪問,難以適應規模龐大的社交網絡。還有一些算法開始考慮社團結構[3],如SPAR[4]等,但仍然忽略了存儲容量的限制,難以運用在實際系統中。針對社團結構和存儲容量問題,本文提出動態劃分復制算法。說明本文的基本思想,如圖1所示:
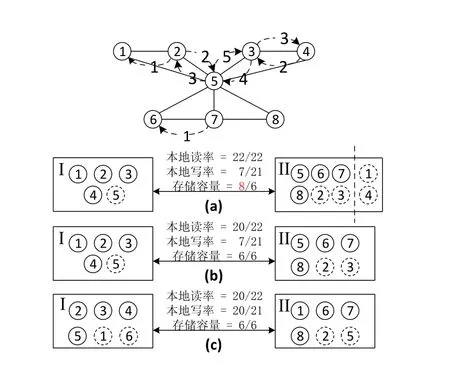
圖1 一個簡單社交網絡
圖1是包含8個用戶的簡單社交網絡,實線圓圈表示用戶的主本,虛線圓圈表示副本,實線為用戶關系,虛線為交互行為,數字為交互次數。圖1(a)所示的方法是:在保證主本負載平衡的情況下,對關系圖進行劃分并復制相應的副本。該方法保證了 100%的本地讀率,但沒有對副本數量加以約束,并且忽略了同樣重要的寫操作。如果服務器節點容量限制為6份拷貝信息,那么節點II就必須刪除超出限制的兩份信息,成為圖1(b)。本文的算法如圖(c)所示,經過調整后充分利用了存儲容量, 在保持高本地讀率的情況下,大大提高了本地寫率。
如上例所述,本文提出一種基于用戶交互行為的社交網絡動態劃分復制算法:在系統存儲容量受限的情況下,依據社交網絡中用戶的交互行為動態調整主本的位置,并根據用戶間的關系周期性復制副本,盡可能使相關用戶的數據分配在同一服務器節點,最終達到減少網絡通信,提升用戶體驗的目的。基于人人數據集,本文與 METIS[5](靜態圖劃分工具)和隨機算法進行了比較,通過多種指標證明本文算法能夠提高社交網絡的劃分效果,適用于實際系統。
本文的主要貢獻如下:
我們注意到,對于分布式社交網絡系統,存儲容量是一個限制條件。據我們所知,在相關的研究中,沒有對存儲容量進行限制。
本文提出一種針對社交網絡結構的動態劃分復制算法,通過提高本地讀寫率減少網絡通信。
基于真實數據集,本文提出本地讀寫率與系統存儲容量的折中辦法,為社交網絡系統設計提供參考。
本文的文章組織如下:第1節介紹相關的符號和概念;第2節對實際問題進行抽象,根據需求定義約束條件;第3節提出本文的動態貪心算法;第4節通過實驗驗證本文的有效性;第5節對全文進行總結并提出下一步研究方向。
2 概念及符號定義
本節主要介紹一些概念和符號。
關系圖:關系圖G = (V, E)是一個無權重無向圖。其中點集V表示社交網絡中的所有用戶;邊集E表示用戶間的朋友關系。
交互圖:加權有向圖G’ = (V, E’)記錄用戶之間的寫操作,稱為交互圖。G’中的V與G中的V相同,E’是E的子集,僅參與寫操作的用戶之間存在有向邊。e’(u, v)表示用戶u對用戶v的寫操作,e’的權重We’表示用戶之間寫操作的累積影響。我們用c(u, v, ti, tj)記錄ti到tj時段內,u對v寫操作的次數。當采樣時間固定為Δt時,e’(u, v)在時段(ti, tj)內的權重定義為:
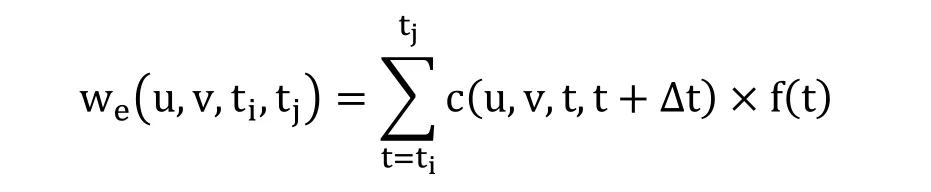
其中f(t)是t時刻的衰退因子。
圖劃分:依據上述兩個社交圖對用戶數據進行劃分和復制,每一個服務器節點稱為一個劃分。劃分總數用m表示,用戶總數用n表示。Mi表示i劃分中的主本集合,Si表示副本集合。對于每個用戶v,P(v)表示v的拷貝所在的劃分集合,主本所在的劃分記為 vM,副本所在的劃分集合,記為vS。在我們的模型中,系統存儲容量是有限的,每個節點的存儲容量用所能保存的最大拷貝數定義,記為C。
讀權重:讀權重描述在一個劃分中創建一個副本的重要性。用戶v對劃分i的讀權重由以下公式計算:
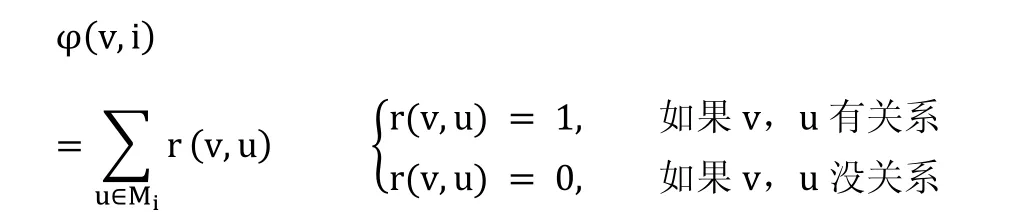
換句話說,讀權重定義了用戶v有多少個朋友的主本在劃分i中。
寫權重:寫權重描述一個主本對一個劃分的重要性。用戶v對劃分i的寫權重由以下公式計算:
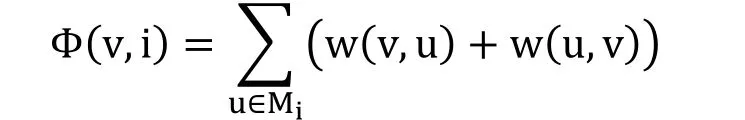
寫權重定義了用戶v與劃分i中用戶累積的交互。
3 問題定義和形式化
3.1 問題定義
有限的存儲容量:服務器節點存儲容量受限是一個現實約束條件。
最小化跨節點操作:減少跨節點的讀寫操可以減少網絡通信。社交網絡結構遵循帕累托分布(即少數用戶產生大多數用戶行為),使得大多數讀寫操作能通過合理分配復制成為本地操作。
負載平衡:一、保證所有劃分中拷貝數相等,因為大多系統中服務器節點同構,存儲容量相同;二、保證每個劃分中的主本數近似相等,因為寫操作必須發生在主本之間,時間代價比讀操作更高,主本帶來的負載大大超過副本,為了使每個服務器節點負載平衡需要保持主本數近似相等。
穩定性:用戶之間的關系和交互情況隨著時間變化,需要動態調整主副本。該算法需要快速高效地響應這些改變,同時必須保證穩定性,防止頻繁操作導致系統顛簸。
3.2 問題抽象
算法的目標是最小化跨節點操作次數,該目標可以定義為以下兩個問題:
一、最小化跨節點寫操作:
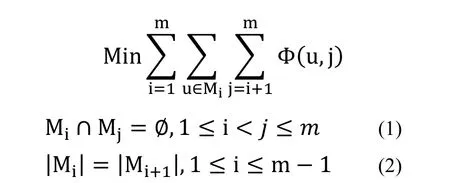
約束條件1保證每個用戶只有一個主本。約束條件2保證每個劃分的主本數相等,即負載平衡。
二、創建讀權重最高的副本:
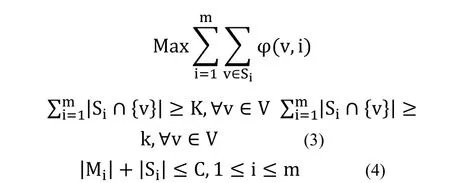
約束條件3是對系統冗余性的要求,使每個用戶至少有K份副本。K稱為冗余系數,如果系統不需要冗余性,把K設為0即可。約束條件4要求每個劃分的拷貝數小于存儲容量限制C,并且每個劃分是同構的。
4 算法描述
本文算法是一種動態的貪心算法,由五種事件觸發。
4.1 算法思想
網絡初建時,用戶數相對較小,此時的存儲容量不受限制。我們把用戶的主本隨機分配到任意劃分,并在其他所有劃分中創建對應的副本。這些副本在保證冗余性的同時,保證了100%的本地讀率。
隨著用戶數量增加,存儲容量不足以滿足第一階段的方法,此時需要挑選一些副本刪除,為新的主副本騰出空間。
過程中根據用戶交互頻繁程度動態調整主本位置,盡可能將頻繁交互用戶的主本分配到同一劃分,以此提高本地寫率。
4.2 算法概括
創建新節點:網絡初建時,新用戶的主本分配到主本負載最低的劃分, m-1個副本創建在其他劃分。存儲容量不足時,在主本負載最低的劃分中先刪除一個讀權重最低的副本,并在其他劃分中類似創建K個副本。
移除一個節點:一個用戶注銷賬號后,他的主副本被移除,相關劃分中其他拷貝的讀寫權重都相應降低。考慮到該事件發生概率較低,并不調整主本分配。
交互邊權重更新:每隔一段時間統計該時段內用戶的交互次數,這些計數被加到原有的權重上,原有的權重需要乘以衰退因子 f(t)。在實驗中,我們簡單地把衰退因子設為介于[0, 1]之間的常數,記為F,并把時間間隔設為一周。
寫權重更新:交互邊權重的更新引起主本分配的相應調整。由于需要保持負載平衡,只對兩個主本進行交換操作,不進行單向移動。算法 1描述了該過程,可能的操作如下:如果v、u的主本在同一劃分,(1)不做任何交換。否則找出u所在劃分中寫權重最低的主本u’,計算交換v和u’的收益δv,u’。相同的計算 δu,v’。根據δ的取值不同,分為以下三種情況:(2)交換v和u’的主本;(3)交換u和v’的主本;(4)不做交換。

(1) 只更新,不交換:由于u和v的主本已經在同一劃分,不需要做任何交換。增加的權重使這個劃分變得更加穩定,需要更新u和v的寫權重。
(3) 交換u和v’的主本:該情況與(b)相似。
加入新的服務器節點:當系統存儲容量不足時,加入新的服務器節點,即新的劃分。采用以下兩種策略:一、不做任何調整,新的劃分等待新的用戶加入。二、當劃分數從m增加到m+1時,每個劃分中選出n/(m2+m)個寫權重最低的主本放入到新劃分中。
移除一個服務器節點:需要刪除這個劃分中的所有主本和副本,同樣采取兩種策略:一、把移除劃分中的節點當做新節點加入到其他劃分中。二、選擇把其他劃分中讀權重最高的副本替換當前被刪除的主本。
5 實驗結果及分析
5.1 評價方法
指標:本文使用三個指標評估算法:本地讀寫率、系統穩定性及讀寫操作響應時間。本地讀寫率反映劃分描述社團結構的能力。系統穩定性用每周交換主本所占的百分比描述。讀寫操作響應時間用讀操作和寫操作的延遲來表示,反應了實際系統中用戶的直觀體驗。
數據集:本文抓取了人人網從2010年9月1日到2011年9月1日的部分數據,包括67747個用戶節點和1760424條關系邊。我們分析了4365455個狀態和2801043個留言,最終得到453392次有效的交互行為。
對比方法:我們將本文算法與現有的圖劃分算法進行比較:
(1) 隨機劃分算法:現在大部分社交網絡采用Key-Value的存儲模式,并隨機分配這些用戶數據。
(2) METIS:METIS是一個靜態的圖劃分工具,該工具通過多次迭代劃分,能夠保持負載平衡和非常高的本地讀寫率。唯一的問題是,它是一個靜態算法,不能處理動態圖。因此,我們考慮將METIS與本文算法結合。
(3) 本文算法 DPRA:按寫權重動態分配主本,再根據讀權重復制副本。
(4) METIS+DPRA:主本周期性使用METIS進行劃分主本,周期間隔之間根據寫權重動態調整,按DPRA算法復制副本。
5.2 實驗結果
5.2.1 本地讀率
以16個劃分為例,如圖2所示:
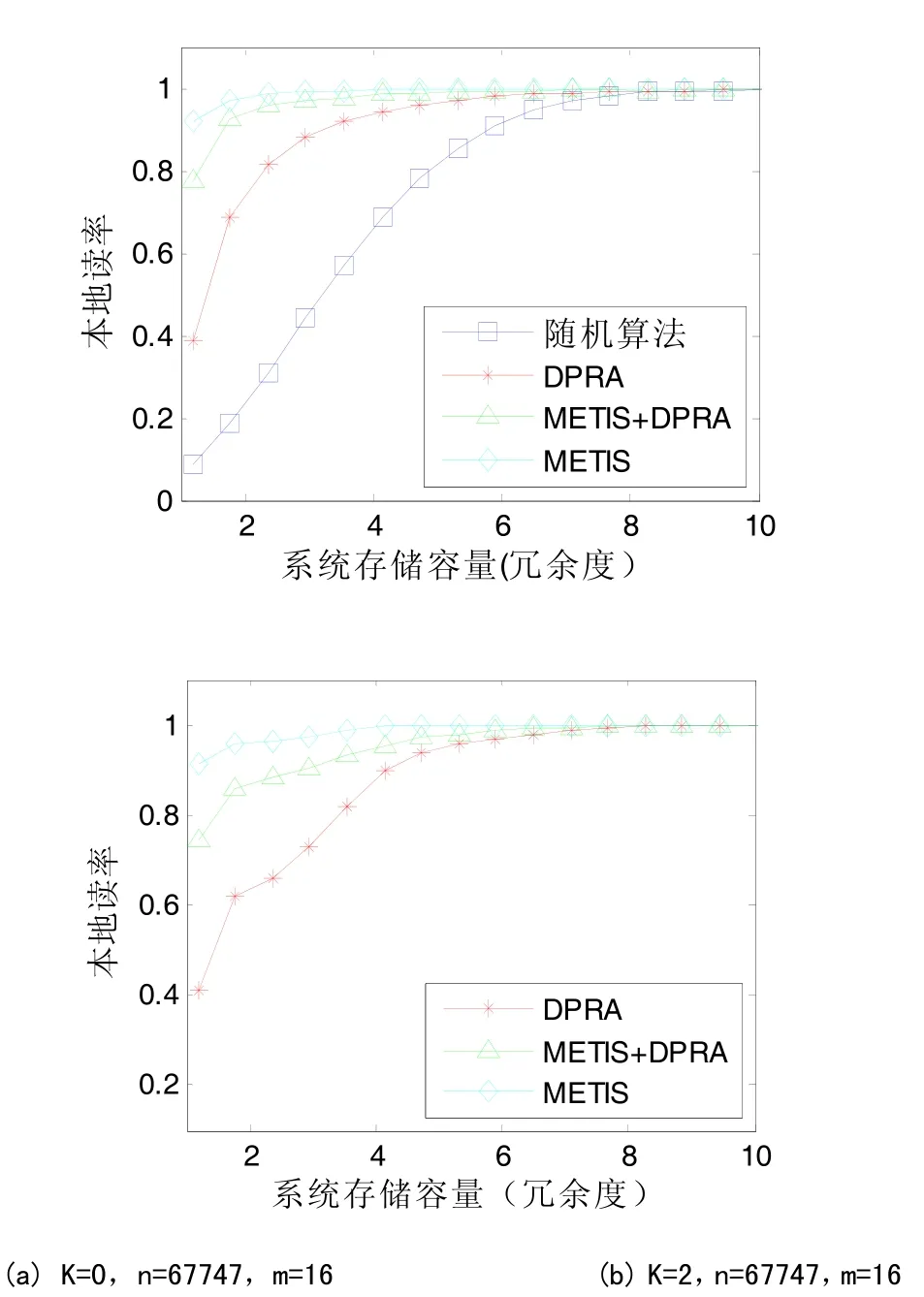
圖2 本地讀率與系統存儲容量的關系
圖2(a)顯示不同算法處理后,本地讀率與存儲容量之間的關系。
隨機算法的本地讀率非常低。根據 DRPA交換主本后本地讀率進一步提高。METIS的性能在低存儲容量時非常優秀,但在存儲容量寬裕的情況下,優勢不大。
基于以上的觀察,我們將METIS與讀寫權重算法進行組合,用 METIS周期性對用戶信息進行調整,調整周期之間采用動態算法。圖中三角形曲線先使用METIS劃分一半用戶,再使用本文算法分配剩下的一半用戶。在系統存儲容量是用戶數1倍、2倍和3倍情況下,本地讀率分別為70%、91%和94%。
當冗余系數K=2時,結果產生如圖2(b)的變化(由于隨機算法不能保證冗余性,不在該圖顯示)。結果與圖2(a)相似,區別在于圖2(b)中的每條曲線都有一個拐點,并且這些拐點都出現在系統存儲容量為3倍處。當系統容量小于3倍時,無法保證冗余系數K=2,所以提供冗余性的副本會被優先創建。當系統容量大于3倍時,系統保證了冗余度K=2,后續創建的副本都有較高的讀權重,因此本地讀率在這些拐點后快速提高。
5.2.2 本地寫率和系統穩定性
仍以16個劃分為例子,如圖3所示:

圖3 本地寫率及主本交換率與時間關系
根據不同的衰退因子F,我們測試了一年內本地寫率的變化。在這個實驗中,F以0.05為步長增長,圖3(a)最終選取了F=0、0.4、0.7和1進行分析。
F越大,交互歷史比重越大,劃分越穩定,每周交換的主本越少。圖3(b)顯示了不同F下,每周交換的主本數占所有主本的比例。本文劃分算法的實質是:使用過去的交互行為預測未來的交互傾向。這解釋了本地寫率隨著時間升高的原因。通過實驗發現F=0.7是理想值,本地寫率最終高于 65%,而每周交換的主本數不到 2.5%。同時交換主本的任務可以放置在網絡負載較低的空閑段,因此并不會造成網絡負載過高。
隨機分配算法產生了非常低的本地寫率,只有12%左右。METIS則達到 81%左右。然而,這是不公平的。由于METIS的靜態屬性,調用METIS時預先使用了全年的信息,這些信息在當時甚至是沒有發生的。盡管如此,我們的算法僅比METIS低了16%。
5.2.3 讀寫操作響應時間
針對不同算法,我們模擬測試了讀寫操作的響應時間,如圖4所示:
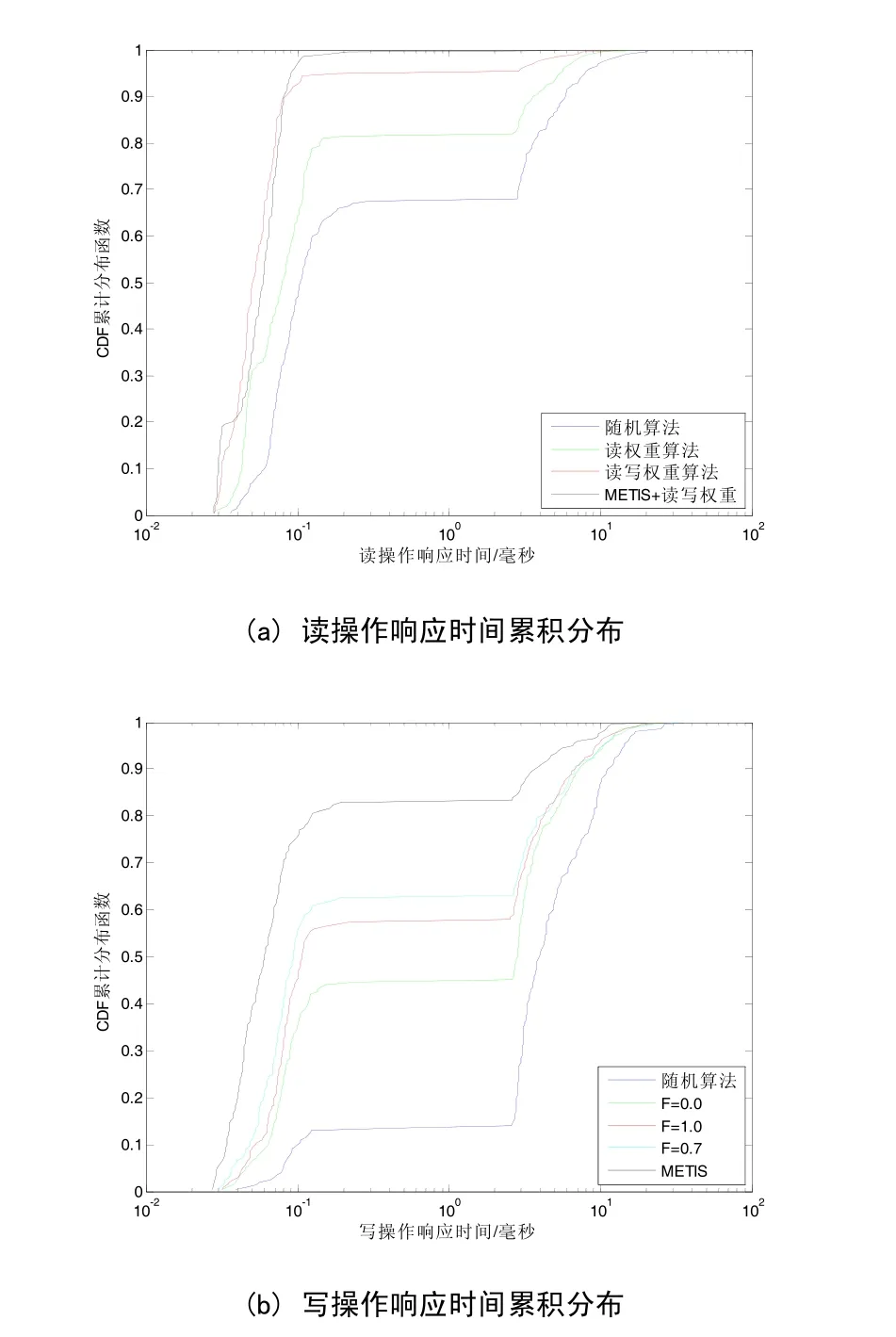
圖4 讀寫響應時間的累積分布函數
對于讀操作,我們模擬在C=3、K=2的情況下,客戶端連續發送200個請求,每個請求隨機讀20-200個字符的信息,通過多次測量記錄中位數,繪制出圖4(a)。其中橫坐標為響應時間,取對數;縱坐標為累計分布。從圖4(a)中可以看出,單次本地讀操作響應時間基本小于0.1毫秒,而遠程訪問則大于2.5毫秒,并且受網絡影響可能更長。多個操作疊加后,遠程響應時間將比本地響應時間大幾個數量級,對用戶體驗造成實質影響。我們采用的算法(METIS+讀寫權重)本地讀率達到 90%以上,相比隨機算法大大降低了讀操作響應時間。
寫操作與讀操作類似,取52周的本地寫率進行分析。客戶端連續發送200個請求,每個請求隨機寫20-200個字符的信息,如圖4(b)所示。本地寫率比本地讀率差異更大,取F=0.7時,我們的算法明顯優于隨機算法。讀寫響應時間的大大縮短證明我們的算法是有效的。
6 總結
本文提出了一種基于用戶交互行為的社交網絡動態劃分復制算法,在限制系統存儲容量的情況下給出數據的劃分復制策略,并將以往難以被統一考慮的讀寫操作結合在一起,通過減少遠程訪問縮短讀寫操作的響應時間,提升用戶體驗。通過實際數據集的驗證,該算法確實可以提高本地讀寫率,降低讀寫操作響應時間。
本文的算法仍然有進一步優化的可能,如每輪交換主本操作可以采用獨立級聯模型,多次迭代達到更好的效果。在未來的工作中,將繼續深入研究社交網絡結構特點,并希望能夠進一步完善本文算法。
[1]Lakshman A, Malik P.Cassandra: a decentralized structured storage system[J].ACM SIGOPS Operating Systems Review, 2010, 44(2): 35-40.
[2]DeCandia G, Hastorun D, Jampani M, et al.Dynamo:amazon's highly available key-value store[j]//ACM Symposium on Operating Systems Principles: Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles.2007, 14(17): 205-220.
[3]Newman M E J.Modularity and community structure in networks[J].Proceedings of the National Academy of Sciences, 2006, 103(23): 8577-8582.
[4]Pujol J M, Erramilli V, Siganos G, et al.The little engine (s) that could: scaling online social networks//ACM SIGCOMM Computer Communication Review.[C]ACM, 2010, 40(4): 375-386.
[5]Karypis G, Kumar V.A fast and high quality multilevel scheme for partitioning irregular graphs[J].SIAM Journal on scientific Computing, 1998, 20(1): 359-392.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
