移動環境下個性化推薦系統的設計實現
2013-12-10 14:07:14西安電子科技大學經濟管理學院
電子世界 2013年5期
西安電子科技大學經濟管理學院 田 亮 宋 薇
東軟集團大連有限 公司 黃少冰
1.引言
近年來,隨著移動互聯網的迅速發展,特別是國內3G牌照發放后,移動互聯網用戶增長迅速。根據中國互聯網絡信息中心(CNNIC)發布的《第30此中國互聯網絡發展狀況統計報告》顯示,2012年上半年中國互聯網電腦網民規模達到5.38億,而手機網 民數量將達到3.88億。據DDCI互聯網數據中心預測,到2013年中國手機網民將達7.2億,首次超越電腦網民[1]。隨之而來的是移動互聯網上各類信息的爆炸式增長,使得人們通過移動網絡獲取信息更加方便的同時,也使得人們獲取有價值的信息愈發的困難。
為解決Internet上信息淹沒的現狀,個性化推薦技術得到了廣泛的應用。針對移動互聯網的特殊性,本文把傳統Internet上個性化推薦技術應用到移動互聯網上,提出了移動個性化推薦的離 線解決方案,并且設計了基于J2ME的移動個性化推薦系統。
2.A TC與CF結合的推薦模型
2.1 相關技術概述
為解決文本分類中人為因素的影響,自動文本分類(Automatic Text Categorization)技術得到了快速的發展與應用。目前比較常用的有KNN,樸素貝葉斯分類,SVM等分類方法。這些方法都是建立在統計學的基礎上,通過特征提取來標注文本文檔,建立文檔模型后不同的方法應用不同的分類器來進行文本分來處理。文本分類建立在大量文檔的基礎之上,從而消除了不同的人對文檔文類不同的分歧,使得分類過程不受人為因素的影響。
協同過濾(Collaborative Filtering,CF),又稱協作型過濾,是在信息過濾與信息發現領域非常受歡迎的技術。一個協作型過濾算法通常的做法是對一大群人進行搜索,從中找出與當前用戶喜好相同的一小群人,并且對這些人的偏好內容進行考察,將結果組合起來構造出一個經過排名的推薦列表[2]。協同過濾技術分為基于用戶相似性的協同過濾(User-based),基于推薦項目的協同過濾(Item-based)與基于模型的協同過濾(Model-based)三種基本方式。Userbased協同過濾是發現相似用戶群體,根據相似用戶的瀏覽記錄來進行興趣發現并推薦給用戶;Item-based協同過濾計算推薦項目之間的相似性,把與用戶以前瀏覽的項目相似的項目推薦給用戶;Modelbased協同過濾首先建立個性化推薦的數學模型,根據數學模型來計算推薦集。
本文主要應用樸素貝葉斯分類器與基于項目的協同過濾算法來構建移動網絡的個性化推薦系統。
2.2 個性化推薦模型
基于J2ME的移動網絡個性化信息推薦系統整體架構如圖1所示,系統模型基于C/S結構設計,客戶端采用J2ME技術實現手機客戶端信息瀏覽系統,服務器端采用Servlet實現。
由圖1可以看出推薦模型可以分為四個主要部分:
1)用戶信息采集分為顯性的信息采集與隱性信息采集方式。顯性的信息采集方式為在用戶的終端瀏覽界面設置信息反饋欄目,在該欄目中用戶可以設置自己的使用偏好信息;隱性的信息采集方式為根據用戶對信息的瀏覽時間,對信息是否保存,對信息是否轉發等情況對信息內容做出隱性的評價。本文使用5分制規則,對信息保存,轉發評分為5分,根據用戶對信息瀏覽時間的長短為信息設置1-5分的分值。
2)信息發布系統主要負責添加推薦信息,在此過程中使用樸素貝葉斯文本分類器對文本類別進行劃分。
3)個性化推薦引擎采用基于用戶背景信息分類與歷史記錄可信度加權的Item-Based協同過濾算法產生推薦信息集。
4)終端系統采用基于J2ME技術實現,提供信息瀏覽與用戶偏好采集功能等。
2.3 樸素貝葉斯文本分類
文本分類是將未知的文本類型劃分到規定好的類別中,從而降低人為因素的影響。樸素貝葉斯分類以古典數學理論為基礎,分類效率穩定,同時模型構建簡單,性能優越。因此本文選取樸素貝葉斯分類器作為文本分類的工具。
本文使用的基于樸素貝葉斯分類的文本分類過程如下:
(1)訓練文本的向量空間表示
生成向量空間模型的步驟有文本分詞處理,除去停用詞,特征選擇等。經過各個階段,最終將確定一組特征詞作為特征詞空間W={w1,w2,w3,…,wm},w表示特征詞。將文本映射到該組特征詞空間,使文本的表示形如T(A)={pA1,pA2,pA3,…,pAm},pAi為文檔頻率法表示詞wi在文檔A上的權重。pAi還可以通過信息增益法,開方擬合檢驗等其他方法表示[3]。
(2)計算每個特征詞所屬類別的概概率分布
計算每個特征詞屬于每個類別的概率,具體計算方法:分別計算每類文件的質心,并計算出每個詞能夠代表每個類別的概率,最終形成如表1所示的特征詞-文本類別對應矩陣。關于文件集質心的計算可以
[4][5]。
(3)向量空間模型的形成
根據已選定的特征詞空間,將待分類文本映射到特征詞空間中,使其表示為向量空間形式:T(X)={pX1,pX2,pX3…pXm}。
(4)根據特征詞的概率分布情況,計算待分類文本所屬類別的概率
確定待分類文本T(X)屬于分類Ck(Ck∈{C1,C2,C3…Cn})的概率R(k),R(k)的計算方法如公式1所示。
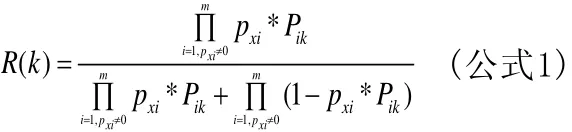
(5)確定待分類文本的類別
按(4)中所提計算公式分別計算待分類文本屬于每個類別的概率R(k),具有最大值R(k)的類別即為該待分類文本的最終分類。
2.4 基于用戶分類與記錄可信度加權的協同過濾算法
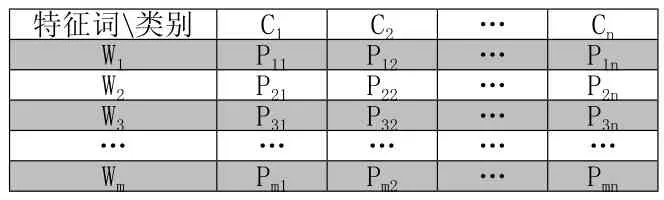
表1 特征詞——類別對應概率分布
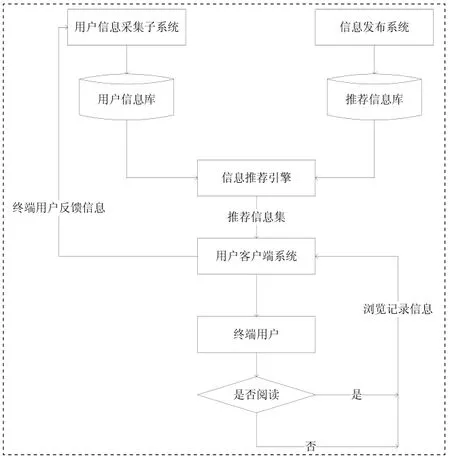
圖1 基于J2ME的移動網絡個性化推薦模型
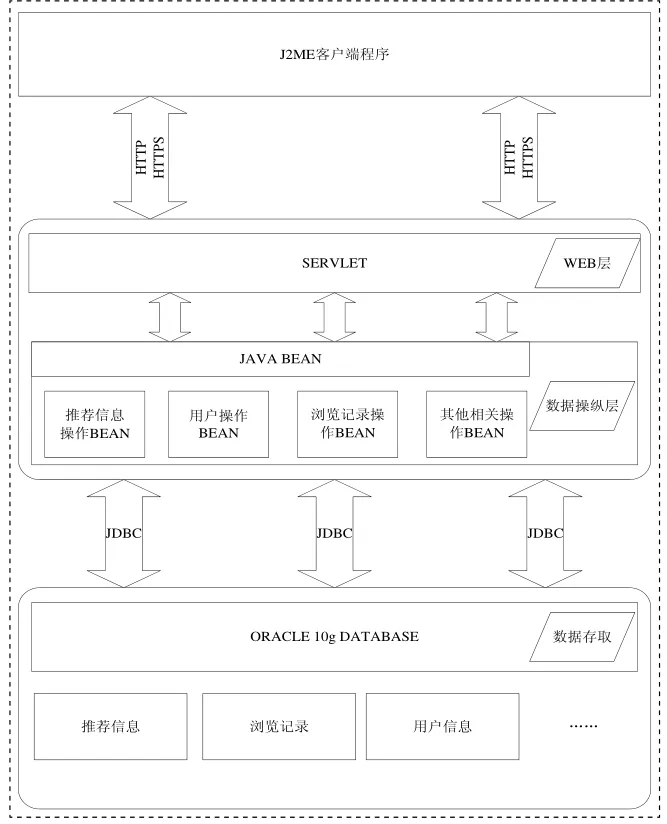
圖2 軟件層次模型
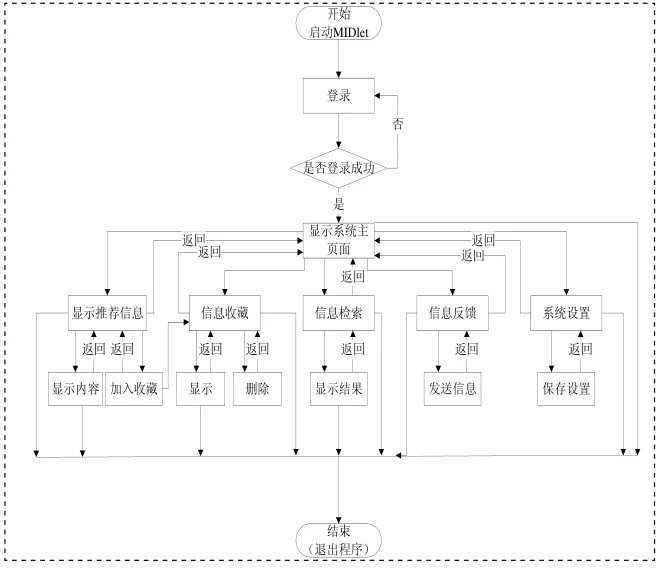
圖3 客戶端軟件流程圖
本文提出的改進的協同過濾算法與傳統的協同過濾算法的區別主要有兩點:依據用戶的背景信息進行分類與用戶的歷史記錄信息加權。按用戶背景信息進行過濾的想法源于一個假設:相同背景信息的用戶具有相似的信息需求,根據用戶的背景信息去除關聯度小的用戶群體記錄,可以降低歷史評分記錄的維數,提高程序的運行速度;考慮到用戶的偏好可能隨著時間的推移而變換,歷史的評分記錄不能真實反映當前的用戶偏好,因此對用戶的歷史評分記錄進行加權處理,使得距離當前時間較近的評分記錄擁有較高的權限,這樣既考慮歷史記錄的影響,又可以突出最新評論的真實性。
(1)用戶分類方法
對用戶進行分類,就是要篩選出影響用戶獲取信息類別的關鍵背景信息,又稱為關鍵因素。以獲得的關鍵因素作為分類標準對用戶進行分類。
用戶分類主要有三個步驟:
1)統計用戶最關注信息的所屬類別,也就是用戶的偏好情況。
2)計算出用戶信息基本信息集的信息熵。
3)計算用戶基本信息中每個屬性的信息增益,從中選擇信息增益最大的屬性作為影響用戶獲取信息的關鍵因素,并以此關鍵因素作為用戶背景信息分類標準來進行用戶分類。

圖4 系統運行界面
當用戶背景信息分類量較大,或者用戶歷史記錄信息量非常大時,可以采用多個用戶背景信息組合的方法獲取關鍵因素。信息增益與信息熵的相關用法可以參考ID3分類算法[6],此外還有一些基于信息增益的特征選取方法,文獻[7]給出了一種改進的特征選取方法。
(2)信息相似度計算
研究發現“用戶的最新評價信息擁有最高的權重,而距離當前時間越遠的記錄擁有的權值越小”,項目加權便是建立在這個基礎上進行的。由此可知項目可信度函數具有單調遞增性。另外,為了確保近期不同用戶的評分信息具有大致相同的權值,可信度函數應是一個凸函數。所以,可信度函數要綜合考慮長期情況下數據權重的差別性和短期內數據權重的相似性。最終設定可信度函數為:以項目排列順序為自變量的函數f(Sui),1≤Sui≤M,M為記錄總數,并且0<f(Sui)≤1。根據以上條件我們選擇對數函數作為可信度函數,并將函數進行歸一化處理。這里設置可信度函數為如公式2所示:

從公式1中可見f(Sui)值域為[0,1],符合上述描述條件。
計算項目相關相似度的方法有很多,包括余弦相似度法,Pearson相關性[8]等。本文采用余弦相似度法來獲取相似性,公式3為改進的余弦相似度公式[9]。
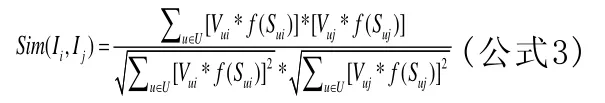
其中,U表示項目Ii,Ij已經評價的用戶集;Vui為用戶u對Ii項目的評價分數;Sui為用戶u對Ii項目評價記錄的標識序號;f(Sui)則表示用戶u針對Ii項目評價記錄所占的權值。
(3)改進的協同過濾算法描述
輸入:推薦用戶u基本信息,所有用戶背景信息及歷史評論信息。
輸出:對用戶u的Top-N推薦
具體步驟:
1)找出影響用戶分類的關鍵因素
2)以1)中獲得的關鍵因素為基礎,選取所屬類別相同的用戶群體。根據分類規則和個體用戶的基本資料獲取與該用戶所屬類別相同的用戶群組。
3)獲取用戶群的歷史記錄,按時間排序。
4)根據3)所得的記錄順序進行記錄可信度加權,獲得評分矩陣。
5)在用戶參與評論的條目中搜尋未經用戶評論條目的最近鄰居集。
6)預測用戶對未瀏覽和未評論過的條目的評價情況,生成推薦集。獲取評價排序的TopN條信息推薦給用戶。
3.移動個性化推薦系統設計
3.1 整體架構
如圖2給出了基于J2ME的移動網絡個性化信息推薦系統的層次模型,主要分為客戶端數據獲取層,Web層,數據操縱層,數據存儲層。客戶端主要負責向終端用戶顯示推薦信息并且獲取用戶的顯性輸入的信息和用戶隱性輸入的信息;Web層主要由Servlet,JSP實現,負責向系統的數據庫中添加推薦信息,并且提供Servlet訪問接口供J2ME客戶端程序以HTTP/HTTPS方式獲取或添加信息;數據操縱層主要是一些JAVA BEAN,這些JAVA BEAN封裝了數據操縱API,向外界提供統一的訪問接口;數據存儲層主要應用Oracle 10g數據庫管理軟件。
3.2 客戶端程序流程
客戶端通過一個主MIDlet程序啟動,提供了推薦信息顯示,信息收藏,信息檢索,用戶個人偏好反饋等主要功能模塊,主要功能的程序流程圖如圖3所示。首次使用客戶端程序需要注冊用戶名、密碼等信息,以后應用可以直接利用保存在J2ME記錄管理系統(RMS)中的個人信息進行登錄,經過驗證成功后的用戶可以進行相關操作。
3.3 服務器端程序結構
服務器端程序主要模塊為文本分類模塊,個性化推薦模塊。為降低用戶等待時間,這兩個模塊的運行均采用離線運行的模式執行。即設定固定的運行時間或手動運行來更新特征詞空間,概率分布信息,以及用戶的分類屬性,推薦集信息等。
文本分類模塊負責將文本分類相關的數據信息保存在文本文件或數據庫中,以便輸入文本時無需再次計算相關參數,可以直接進行分類運算,提高實時性。
個性化信息推薦模塊負責產生與維護用戶對用戶的推薦信息集,該過程要保證推薦信息的新穎性,因此需要在后臺啟動一個運行線程,實時更新推薦集信息。
3.4 客戶端-服務器通信方法
JAVA ME API提供了J2ME MIDlet程序與服務器端通信兩種方法:基于socket連接的方式和基于超文本傳輸協議的HTTP通信方式,本文使用HTTP方式實現客戶端-服務器端通信。客戶端與服務器通過HTTP輸入/輸出流的方式進行數據交換,程序的一端使用特定的編碼格式向輸出流(OutputStream)中寫數據,在另一端打開輸入流(DataInputStream),并且從流輸入流中讀取數據,解碼后完成信息的傳遞。下面給出了一個Post方式提交信息的Http方式連接服務器的代碼片段。

4.系統仿真實驗結果
系統仿真環境:采用HP Compaq dx7408 PC,開發軟件MyEclipse 7.0,Oracle 10g,Wireless Toolkit 2.5.2。
在上文提出的移動個性化信息推薦模型的基礎上,本文作者在實驗室環境下設計開發了一種基于J2ME的移動個性化信息推薦原型系統,系統運行界面如圖4所示。
為測試系統推薦的正確性,在實驗室六名志愿者的參與下,根據他們前四天的瀏覽記錄推薦第五天的偏好信息,推薦正確率在80%左右。
5.結束語
本文為解決移動網絡上的信息過載狀況提出了一種解決方案,設計實現了基于J2ME的移動網絡個性化推薦原型系統,并且取得了較好的推薦效果。由于時間有限,該原型系統在推薦效率和通用性方面仍然有待改進。
參考文獻
[1]工業和信息化部運行監測協調局[EB/OL].http://yxj.miit.gov.cn/n11293472/n11295057/n11298508/14741971.html.
[2]Toby Segaram.Programming Collaborative Intelligence[M].O’Reilly Media,2007(8).
[3]陸玉昌,魯明羽,李凡,周立柱.向量空間法中單詞權重函數的分析和構造[J].計算機研究與應用,2002,10(10):1205-1210.
[4]Lertnattee V,Theeramunkong T.Effect of Term Distributions on Centroid-based Text Categorization[J].Information .ciences,2004,158(1):89-115.
[5]E Han,G Karypis.Centroid-based document classi fi cation:Annlysis & experimental results.In: European Conf on Principles of Data Mining and Knowledge Discovery(PKDD).Berlin:Springer-Verlag,2000:424-431.
[6]J.Han and M.Kamber.Data Mining:Concept and techniques Second Edition[M].北京:機械工業出版社,2006(4).
[7]朱顥東,鐘勇.基于改進的ID3信息增益的特征選擇方法[J].計算機工程,2010,4(8):37-39.
[8]劉枚蓮,從曉琪,楊懷珍.改進鄰居集合的個性化推薦算法[J].計算機工程,2009,6(11):196-168.
[9]黃少冰.基于J2ME的移動網絡個性化信息推薦研究[D].西安電子科技大學(碩士論文),2010.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
