PSO應用于QoS偏好感知的云存儲任務調度
2014-01-06 01:46:10王娟李飛張路橋
通信學報 2014年3期
關鍵詞:用戶
王娟,李飛,張路橋
(成都信息工程學院 信息安全工程學院,四川 成都 610225)
1 引言
近年來,隨著云計算[1,2]技術和軟件即服務(SaaS)[3]思想的興起,云存儲成為信息存儲領域的一個研究熱點。云存儲系統的任務調度前期的研究多脫胎于數據網格和云計算領域。這些工作[4~8]的主要目的是選擇哪些響應時間最短的副本。但是云系統與傳統網格最大的不同在于“一切都是服務”,更加關注服務質量(QoS, quality of service)。既然一切都是服務,那么用戶的感受無疑是最重要的。因此,近年來的云存儲任務調度的研究熱點在于滿足系統QoS的要求。但是,很遺憾現有算法提供的QoS普遍存在2個致命缺點。
1) QoS大多是針對系統而言,而不是使用它的用戶。這與“以服務為中心”的宗旨相違背。如果用戶的需求得不到滿足,即便使得整個系統擁有最大的吞吐率,也應該是失敗的,因為結果不被用戶認可,系統的價值得不到實現。
2) 針對用戶提供的 QoS幾乎都是統一的,沒有意識到用戶的需求存在差異。這也很不符合實際情況。用戶天然存在需求的差別,提供統一的QoS服務不但不能滿足所有用戶的要求,而且造成了不必要的浪費。
舉個很簡單的例子:某云存儲系統提供用戶各種各樣的數據。系統采用的調度算法以使整個系統的吞吐量最大為目標,從系統角度看這是無可厚非的。但是用戶的QoS要求是有差異的:其中一些用戶不希望多花錢,為此寧愿降低自己的優先級多等待一些時間;而另一些用戶,寧愿多花錢來獲得最短的響應時間。系統如果不能提供滿足用戶偏好(時間或代價)的任務調度方案,先滿足了愿意等待的用戶而延遲了不愿意等待用戶的要求,顯然會造成2種用戶都不滿意。前者認為自己多付了錢(快的響應往往代表高的花費),后者則覺得浪費了自己的時間。盡管整個系統的吞吐率最高,資源利用率和負載均衡率都較好,但是明顯不符合現實情況的需要。
在云計算領域已有少量對QoS偏好性的探討,例如文獻[9]。但是,云計算和云存儲系統存在很大的區別,這些方法都不適合直接應用于云存儲系統,需要做較大修改。云存儲系統與云計算的不同主要表現在以下兩方面。
1) 云計算的任務是計算型任務,任務可以指派到系統的任意節點執行,區別僅僅在于在高效率(CPU性能高)節點上執行時間短,而在低效率節點上執行時間長,不會有任務不能由某個節點執行的情況。但是云存儲的任務大多是數據傳輸任務,首要的前提就是節點有任務所需要的數據,因此某任務不能由某個節點提供數據的情況大量存在,這點導致很多從云計算領域移植的算法生成的結果對云存儲系統是無效的。
2) 云計算領域的任務之間存在先后關系,即某些任務必須等到另一些的結果后才能執行。而云存儲系統的任務一般不存在這種先后關系,數據傳輸不存在必須先傳哪部分后傳哪部分。這樣使得原有云計算領域中的調度算法可以適當簡化,不必考慮任務的先后關系。
以上兩點不同提醒大家,現有從傳統云計算領域移植的算法應該考慮這兩大不同,做出改進以適應云存儲環境的特點。例如:云計算中占據重要地位的CPU的計算能力等參數將不再起主導作用,而帶寬、網絡延遲等性能成為任務調度的重要參考。
由于任務調度是一個NP問題,因而以粒子群優化(PSO, partical swarm optimization)算法為代表的啟發式算法近年來在云任務調度領域受到關注,取得了不錯的系統吞吐率。本文就利用PSO算法解決帶偏好的云存儲任務調度問題進行研究,對PSO怎樣解決偏好不同、解決的效果和原因進行實驗和分析。
2 云存儲系統任務調度抽象
為了描述方便,先對云存儲中的任務調度進行抽象。
1) 用R={r1,r2,…,ri, …,rm}表示m個資源,其中,ri表示第i個資源,i∈1,2,…,m。
2) 用J={j1,j2, …,ji, …,jn}表示n個任務,其中,ji表示第i個任務,i∈1,2,…,n。
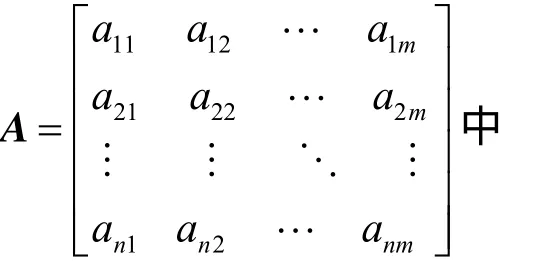

云存儲系統任務調度的目標就是在適應度函數的指引下找到最符合目標函數的調度方案。這里的適應度函數可以簡單指任務完成時間,也可以是使用資源的代價、可靠性等。而目標函數則只有 2種:一種是取適應度函數的最大值,另一種是取適應度函數的最小值。很多情況下,通過改變適應度函數的定義,目標函數可以相互轉換。例如:取任務完成時間為適應度函數,一般的目標函數就是取完成時間的最小值。這個定義等同于取任務完成時間的倒數為適應度函數,而目標函數取該倒數的最小值。因此,本文不設專門的目標函數,只使用適應度函數F,目標就是取使得F最小的調度方案。
已有的研究已經證明多因素下的任務調度是一個NP難題,沒有最優解,只能通過啟發式算法尋找比較優化的解[10]。當前常用的啟發式算法中,粒子群優化算法以其算法簡單、計算方便、求解速度快受到任務調度研究者的重視[11]。下面研究如何改進PSO算法以感知用戶偏好差異。
3 適應用戶QoS偏好的PSO云存儲任務調度
本節先介紹 PSO算法及其應用到云存儲系統中的編碼方式,進而從解空間、適應度等方面對現有云計算中的PSO調度算法進行改進,首先保證不產生對云存儲系統來說無意義的解;其次,修改適應度函數定義來感知用戶偏好。
3.1 標準粒子群算法簡介
PSO[12]是一種基于種群搜索策略的自適應隨機優化算法。在基本粒子群算法中,生物的個體被抽象為沒有質量和體積的粒子,生物群體被抽象為由e個粒子組成的群體。粒子i代表優化問題在D維搜索空間中可能的解,表示為位置矢量Xi= (x1,x2,…,xN),位置可以通過飛行速度矢量更新Vi= (v1,v2,…,vN)。每個粒子都有一個由目標函數決定的適應值(fitness value),并且知道自己到目前為止發現的最好位置(pbest)和現在的位置Xi。這個可以看作是粒子自己的飛行經驗。除此之外,每個粒子還知道到目前為止整個群體中所有粒子發現的最好位置(gbest)(gbest是pbest中的最好值)。這個可以看作是粒子同伴的經驗。粒子就是通過自己的經驗和同伴中最好的經驗來決定下一步的運動。
PSO的初始化為一群隨機粒子(隨機解)。然后通過迭代找到最優解。在每一次的迭代中,粒子通過跟蹤2個“極值”(pbest,gbest)來更新自己。在找到這2個最優值后,粒子通過下面的公式來更新自己的速度和位置。
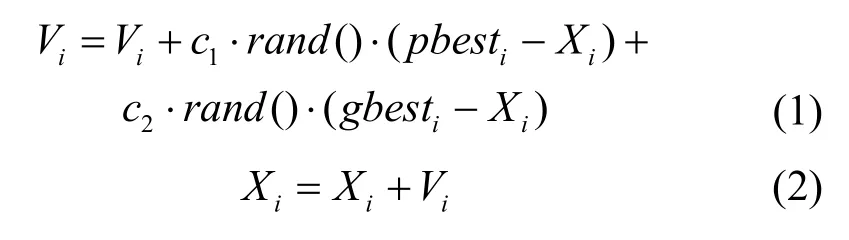
在式(1)和式(2)中,i=1,2,…,m,m是該群體中粒子的總數,Vi是粒子的速度;pbest和gbest如前定義;rand()是介于(0,1)之間的隨機數;Xi是粒子的當前位置。c1和c2是學習因子,通常取c1=c2=2。在每一維,粒子都有一個最大限制速度Vmax,如果某一維的速度超過設定的Vmax,那么這一維的速度就被限定為Vmax(Vmax>0)。
1998年Shi等[13]對前面的式(2)進行了修正。引入慣性權重因子,如式(3)所示。
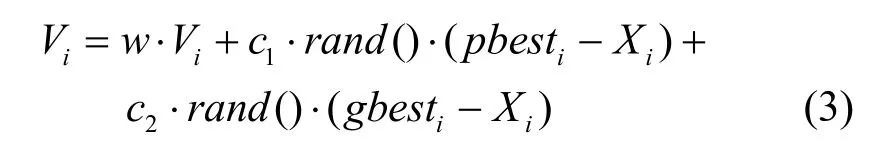

其中,w為非負,稱為慣性因子。式(3)和式(4)被視為標準PSO算法。w值較大,全局尋優能力強,局部尋優能力弱;w值較小,反之w值較大。
3.2 編碼策略
很顯然以上算法適合求解實數問題,但對離散化的任務調度不能直接應用。需要進行轉化,一般方法是進行編碼。對云存儲系統來說,一個編碼就代表一個任務調度序列。出于描述方便采用十進制編碼,假設有m個資源,n個任務,用Code=e1e2…ei…en表示任務調度向量,即一個調度方案。對云存儲系統來說,ei代表第i個任務的數據由ei的值代表的資源節點提供,而該向量的長度即是單位時間內要調度任務的總量n。例如,某任務調度向量為[2, 4, 3, 4, 1, 5, 6],這個向量的長度是7,代表該單位時間需要調度的任務數為7。序號1的位置上的值是2,代表任務1的數據由系統的2號節點提供。以此類推,任務2和4的數據由節點4提供;任務3的數據由節點3提供;任務5的數據由節點1提供;任務6的數據由節點5提供;任務7的數據由節點6提供。
3.3 限制解空間
傳統云計算領域的PSO算法,初始解和解的更新都是整個解空間,即云計算任務可以調度到任何一個節點計算。但是如引言中所述,在云存儲系統中,由于任務資源只在特定節點存儲,因此任務不能被調度到任意節點執行,即云存儲中的解必然是受限制的。
針對這個問題,引入存在矩陣(EM, exist matrix)[14]來指示任務和資源節點間的對應關系。EM是一個n×m的矩陣,n是調度任務數目,m是系統資源節點數目。矩陣的項eij代表節點j是否有i任務的數據,有則為1,無則為0。該矩陣可以從云存儲系統的資源列表中生成。資源列表記錄了數據塊 ID和存放的資源節點的對應關系,為了保證數據的安全,數據塊往往被冗余存儲在多個資源節點上,因此,存在矩陣中代表任務的一行中會存在多個1的情況,對應的列數就是該擁有任務數據的節點ID。
在存在矩陣的限制下,對傳統云計算中基于PSO的任務調度算法做以下3點改進。
1) PSO的初始化解不再隨機產生,而是根據存在矩陣生成;生成算法簡單來說是先從EM中獲取每行值為1的序號,然后從這些序號中隨機選擇一個作為該行代表任務的解,n個任務的解構成一個任務調度解V。
2) 在根據式(3)和式(4)產生新的解時,先不進行適應度的計算和比較,先進行存在性檢測,即產生的新解是否符合存在矩陣,如果不符合則另外產生一個解直到滿足存在矩陣,之后再進入適應性檢測。
3) 在算法陷入局部最優時,同樣從存在矩陣EM中產生新的解,而不是像傳統算法一樣隨機在整個解空間產生新解。
3.4 用戶QoS偏好適應
從前面標準PSO流程可以看出,決定PSO解優劣程度的是其目標函數和由目標函數決定的適應度。為了適應不同的用戶QoS需求的差異,下面對PSO的適應度定義進行改進,加入對云存儲系統非常重要的QoS因素,并對這些因素進行分類,用權重因子來指示這些因素的重要程度,即可以通過權重因子的調節來達到適應不同用戶不同 QoS偏好的作用。
3.4.1 云存儲中的QoS因素歸納與效用函數定義
1) 云存儲中常見的QoS因素
適應度函數F由多個約束因素決定,這些約束因素就是決定任務調度QoS的因素。根據現有研究[1~9,15,16]和自身經驗,總結出以下主要影響因素。
si代表任務i所需要傳輸的數據量的大小(size,單位:Megabyte)。
bij代表任務i的請求者和資源j之間的帶寬(bandwith,單位:Mbit/s,如果有多個帶寬值取最小值)。
以上二者的商其實就是任務i由資源j提供時要耗費的傳輸時間tij。無論對云計算還是云存儲系統。一般時間以秒為單位。
cj代表使用資源j所花費的代價,例如,使用服務器的代價明顯和使用一般的主機是不同的,中心節點使用的代價和邊緣節點使用代價也肯定是有差異的。各個節點的代價構成了代價向量C= [c1,c2,…,cm]。
lj代表資源j在本調度周期前的負載(CPU負載、內存負載、數據存儲負載等或者是綜合)。各個節點的負載構成了負載向量L=[l1,l2, …,lm]。
dij代表任務i的請求者和資源j之間的網絡延遲(可以通過歷史數據預測,包括等待時間、預熱時間等),一般來說以秒為單位。各個節點的延遲量構成了代價向量D=[d1,d2, …,dm]。
qj代表資源j的質量,對于云存儲系統來說,主要考慮該資源節點的故障率,各個節點的質量評價構成了質量向量Q= [q1,q2, …,qm]。
IOj代表資源j的IO并發數,該數目有上限,超過的話,服務器對新到的請求會拒絕。
2) QoS效用函數
由于各個QoS要求的物理意義不完全相同,計量單位也不一定相同,從而使得QoS值的量綱和數量級可能不同。需要利用 QoS 效用函數將每個候選資源節點的QoS屬性映射到一個實數值,通過該值對每個候選節點進行評估和比較,以便選擇到滿足 QoS 約束的資源節點。
本文采用的效用函數是歸一化函數,其構造方法是,將候選節點某QoS屬性與其對應的最大值或最小值進行比較,從而將多個QoS屬性值進行歸一化處理(范圍在0~1),使其轉化到一個綜合衡量的實數值(獨立于每個具體屬性的單位或范圍),如下所示。
當qi是效益型屬性,效益型的屬性值越大,表明屬性質量越優。
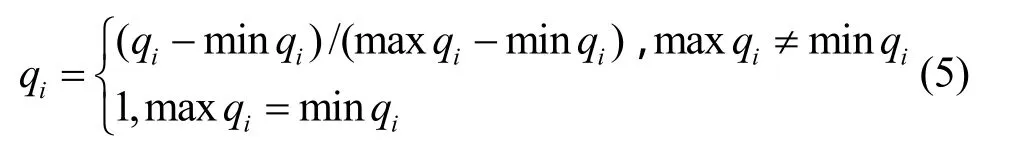
當qi是成本型屬性,成本型的屬性值越小,表明屬性質量越優。
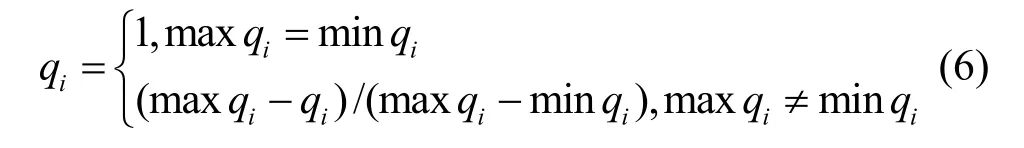
其中,minqi和maxqi分別表示在服務組QoS屬性q的最小值和最大值。
3.4.2 QoS偏好感知的適應度定義
定義以下的適應度函數fij,代表任務i由資源j執行的適應度為
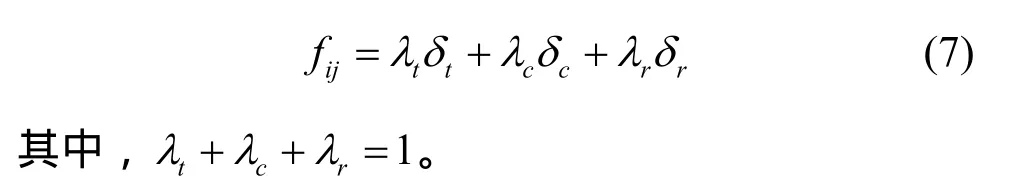
因素的性質各有不同,大致包括時間、代價、和質量 3大方面。例如,文件大小si除以帶寬bij就是時間;費用cj、負載lj屬于代價衡量范圍,而網絡延遲dij、網絡節點的質量qj、服務器IO數是否充足可以看作是服務質量衡量范疇。因此,適應度函數可以被化為3大部分,由各自的因子協調重要性,λt、λc和λr分別被稱為時間因子、代價因子和可靠性因子。它們值的大小反映了對時間、代價和質量的重視程度。

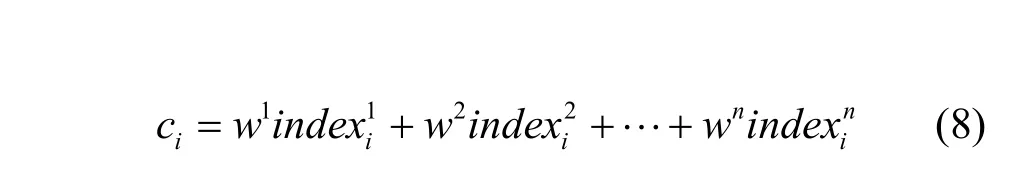
該權重和適應度權重(λt、λc和λr)設定本文采用優序判定法,減少主觀判斷。首先構建判斷尺度,重要程度判斷尺度用1、2、3、4、5五級表示,數字越大,表明重要性越大。當2個屬性對比時,如果一個屬性重要性為5,則另一屬性重要性為0;如果一個屬性為3,則另一個屬性為2。
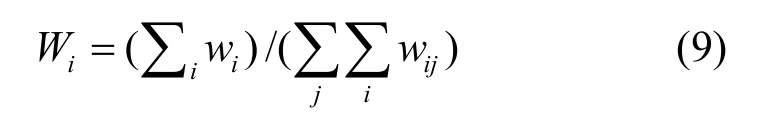
該適應度函數定義具有以下優點。
1) 具有很好的可擴展性:本文所總結的因素僅僅是針對云存儲系統而言比較重要的一部分。在計算網格或其他系統中,還會有其他一些因素。當需要的時候,這些因素可以融入已有框架中,加入時間、代價或可靠性部分。需要的時候現有的因子也可以被剔除。即僅僅需要根據實際情況對適應度函數f做相應修改,其他部分不變,就可以滿足不同系統的需要。
2) 具有偏好適應性:可以根據各因子的調整,滿足不同偏好的要求。例如,某些用戶對數據的傳輸時間并不看重,它們寧愿用更多的等待時間來換取更低的服務費用。對這類任務調高代價因子、調低時間因子能獲得更加有針對性的調度方案。
3.4.3 用戶QoS偏好感知算法流程
1) 任務優先度決定因子設定值
前文提到 QoS可以歸為3類,任務對QoS偏好的組合,根據對用戶的調查(主要是詢問了本校網絡專業 10級的學生)主要可以分為以下5類。
最高級為同時看重質量和時間的任務,如此高要求代價上就不能要求太多,等級標記為 5(組合中三方面同時要求的情況實際中不允許,而學生們對得到高效有質量保證的服務必須付出的代價也有共識)。其次,對質量、時間、代價其一做要求,其中,由于時間要求比較緊迫,設定等級為 4;要求質量的等級設定為 3;僅僅對代價有要求的設定為 2(要求少花錢,那么對效率和質量就不能有太高要求,這類劃分也受到被詢問學生的贊同)。最后,沒有要求的被設置為等級1。
用1~5代表不同的程度,根據等級設定時間因子、代價因子和可靠性因子的取值。例如,設定等級5代表用戶希望任務耗時短、可靠性高、不計代價,那么時間和可靠性因子則設為高值,代價因子設為低值;等級2則代表用戶希望代價越低越好,不計較消耗的時間和可靠性,對應時間和可靠性因子則設為低值,代價因子設為高值。等級1比較特殊,沒有要求,這里視為對代價有最高要求。不同于等級 2,雖然對代價看重但對時間和質量還有一定的期待。等級1代價取1,其他因素取0。
對于因子的具體取值,本文采用優序對比法進行設定,能夠一定程度上減弱用戶和系統管理員的主觀影響,具體如下。
以任務優先級為5時的各因子值設定優序對比為例。
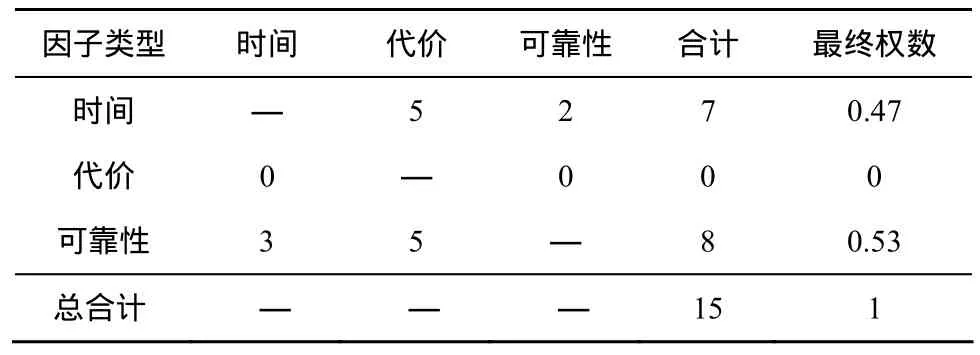
表1 基于優序判定法的因子值設定(當任務優先級為5時)
當任務為其他優先級時的設定方法以此類推,最終的設定值如表2所示。
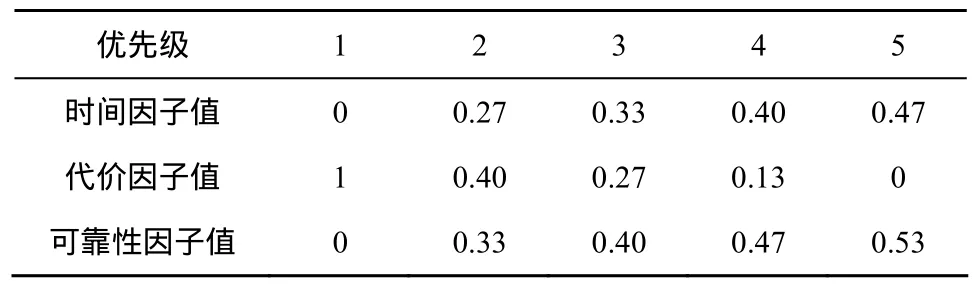
表2 任務優先級對應的各因子取值
于是,一個等待調度的任務實際上包含2個維度的數據(數據量大小s,任務優先級p)。計算適應度時,根據p取3個因子的值。
而代價向量C= [c1,c2,…,cm]是一個預定義的向量,序號代表系統節點的編號,即c1代表節點1的使用代價。代價的程度值是系統的管理人員根據節點本身的配置花費、能耗花費等評估而得。
適應度計算還需要l、d、q等值,可以實時從系統節點日志記錄中獲取,與代價類似構成負載向量L、延遲向量D、質量向量Q等。再根據定義和式(5)、式(6)計算需要的歸一化值。本文的實驗系統設計并實現有專門記錄和計算這些值的模塊,隨著調度的進行,各項值會按當前值與記錄的最大最小值進行更新。
以上的計算是針對某一個確定解的,即任務在某個具體的節點執行已經確定,則以上各項值都可以獲取到。最后比較所得所有解的適應度值,取最小適應度對應的解為最終確定解。
2) 算法流程
依照以上定義和改進,適應用戶 QoS偏好的PSO云存儲任務調度算法流程示意如圖1所示。限于篇幅標準PSO流程省略,僅僅突出了改進之處。
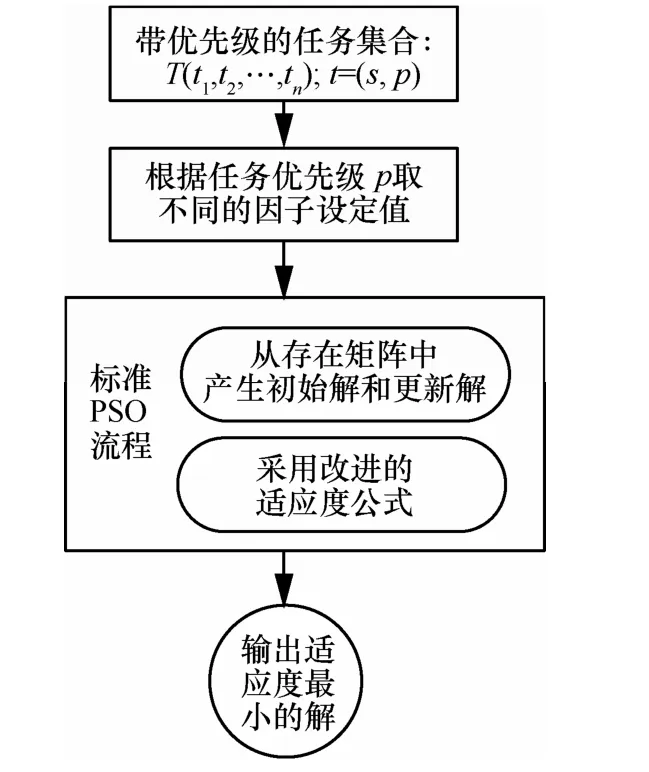
圖1 帶QoS偏好感知的PSO任務調度
4 實驗與分析
為了分析本文所提偏好感知任務調度算法的有效性,設計并用 MATLAB實現了一個云存儲偏好感知仿真平臺,模擬云存儲從提交任務請求到調度指定節點提供任務資源的過程。仿真平臺由3大模塊組成,其中,模擬條件生成模塊負責模擬云存儲系統的各種條件,包括網絡的帶寬、網絡線路的延遲、節點的負載、節點故障、節點的 IO并發數等;資源定位模塊負責根據任務需求和系統本身的資源記錄表實時生成資源存在矩陣EM;任務調度模塊則負責根據本文的算法對任務進行調度。
實驗統一設置最大迭代次數為100次,為避免干擾導致的某些個別情況,每個實驗重復進行 10次,每次實驗記錄“運行時間”、“迭代次數”等參數以待對比。運行時間就是指算法從開始接受輸入需要調度的任務向量開始,到最后輸出一個可以接受的調度序列的時間。迭代次數記錄的是最后輸出的調度序列是第幾次迭代產生的,這個值可以考察算法的收斂速度。偏好適應率則是考察生成的調度序列多大程度上滿足了用戶的偏好。
下面就傳統 PSO算法和改進后的帶偏好感知的PSO算法對偏好感知的具體效果進行考察(都有存在矩陣限制)。隨機生成的Task向量自帶對QoS因素的要求(代價、時間、質量),對應的值在0~1之間。調度結果提供節點的對應值大于或等于要求則視為滿足了用戶QoS要求,反之視為不滿足。用一個偏好評價函數進行自動檢查,給出任務偏好滿意百分比,計算方法如下

需要說明的是,IO并發數對質量的影響,已有并發數多并不一定就比已有并發數少的服務器提供更差的服務,這點在實驗時表現出對調度評價的影響并不符合實際。更多情況下要考慮剩余并發數的多少。因此,將 IO改為剩余并發數,即從成本型改為效益型,值越大越好。調度模塊為某節點調度一個任務后,更新節點的各項值,對 IO來說減少了一個并發數。
對比結果如表3所示,可以看到,傳統PSO對有偏好要求的任務是完全沒辦法滿足的,平均只有22%的滿足率,全憑運氣。而本文改進的PSO算法偏好滿足率上升 40%達到了 60%。說明改進后的PSO算法確實帶有一定的偏好感知能力。但是距離預計80%以上的偏好滿足率還有一定差距。
開始以為是因子設置問題,但是無論怎么調整因子的值,實驗的偏好滿足率都只有約50%~70%。后來發現,問題不在于因子值,以上優序判定的因子已經比較合適。真正的原因是各個等級任務所占百分比。實驗模擬是一般的金字塔型的任務分布,即高等級的任務比例比較小,大量的是低級任務的情況,中間等級的任務中等數量,這也是一般系統的任務分布。第3.4.2節設計的感知偏好的適應度具有對單個任務QoS感知識別的能力。但是PSO算法的選擇是對總體QoS的評估。于是出現了占80%以上的優先級只有1、2的任務的偏好左右了總體QoS偏好,導致整體偏好滿意率不高。這50%~70%被滿足的任務大部分是占有率高的低級任務。這種情況在筆者調整了各個等級任務的分布百分比后有所改善,特別當各等級任務所占百分比相同的情況下,占有率對整體偏好影響達到最小,偏好滿足率基本在 80%以上。但是這種情況在現實中是很少的。大量存在的其實是表 3代表的金字塔型的任務分布。因此,這次實驗說明對于偏好不同且分布相差大的任務調度其實不適合用PSO算法進行整體調度。
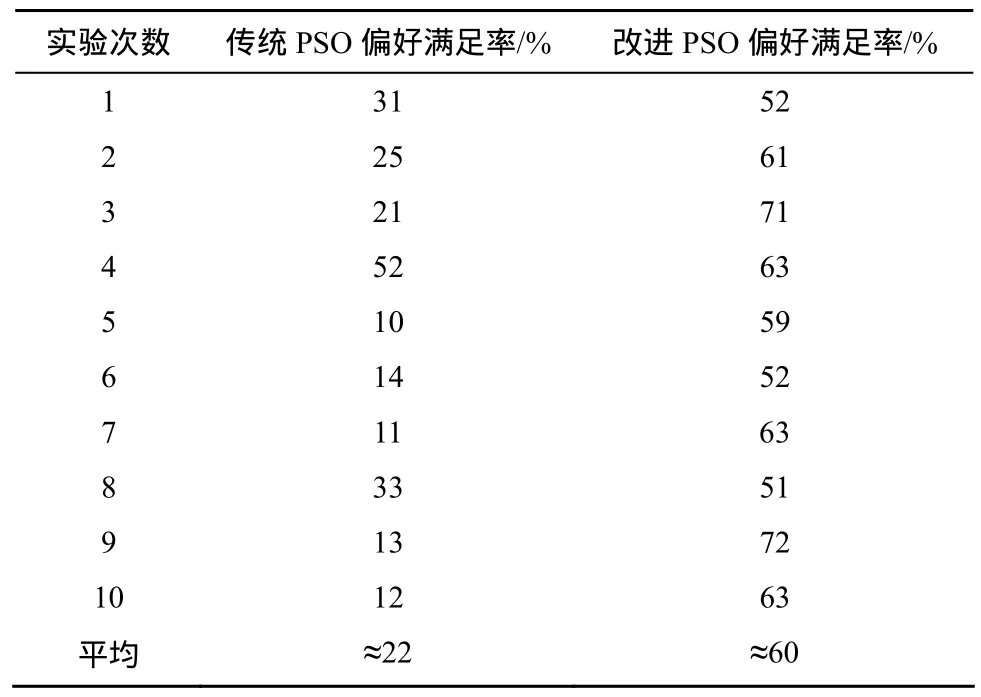
表3 帶偏好感知的PSO云存儲調度算法
最后,筆者把這些任務按優先級進行分級調度(按優先級先后順序調度),即將3.4.3節算法里的“任務矩陣”按優先級先后輸入,高優先級完成后,再進行低優先級的調度,其余不變,得到了90%~100%的偏好滿足率如表4所示。雖然總體滿意率較高,但是優先級低的滿意率居然高于優先級高的。分析發現原因在于:由于是按優先級從高到底順序調度,優秀的資源優先調度給了優先級較高的任務。但是資源總是比任務少,高優先級的任務意味著高資源要求,在總體資源受限的情況下,無法完全滿足高優先級任務。而低優先級任務唯一的就是代價要求,因此在其他任務將代價高的資源先占用的情況下反而可以保證其代價低的要求,因而其滿足率最高。
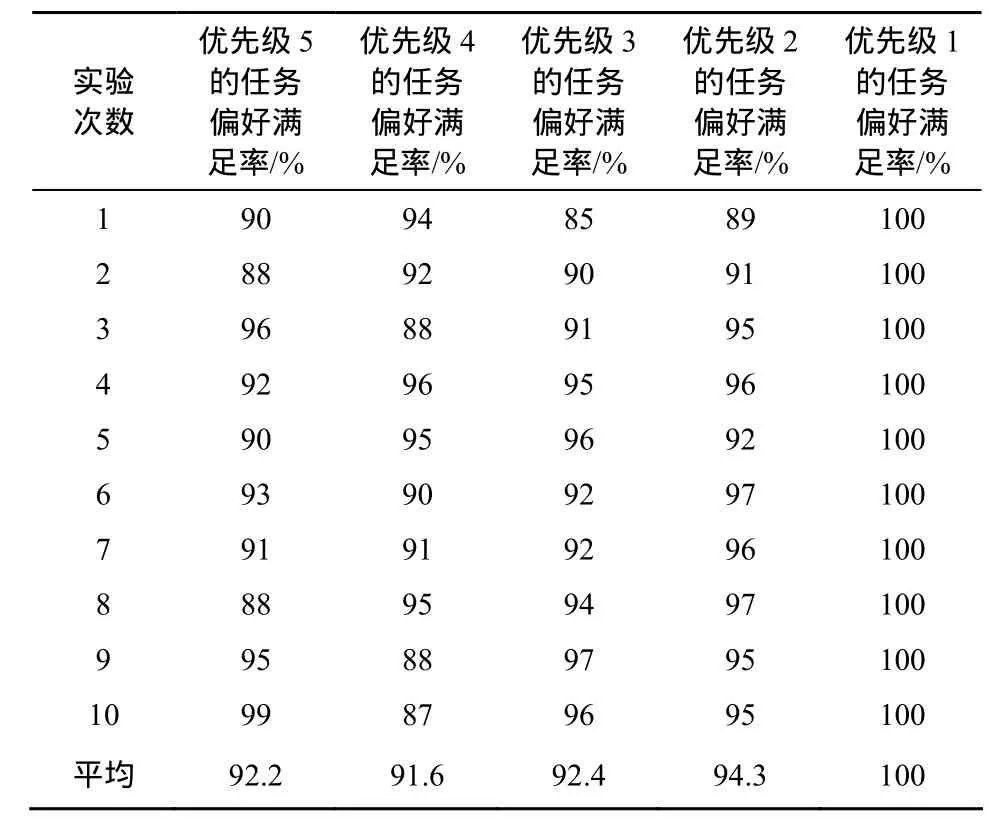
表4 分級的帶偏好感知的PSO云存儲調度算法
因而算法流程改變為圖2所示按優先級先后調度,調度算法內部流程不變,輸入改為按任務優先級順序輸入。不建議并發調度,因為并發過程優秀資源可能被低級任務占用。
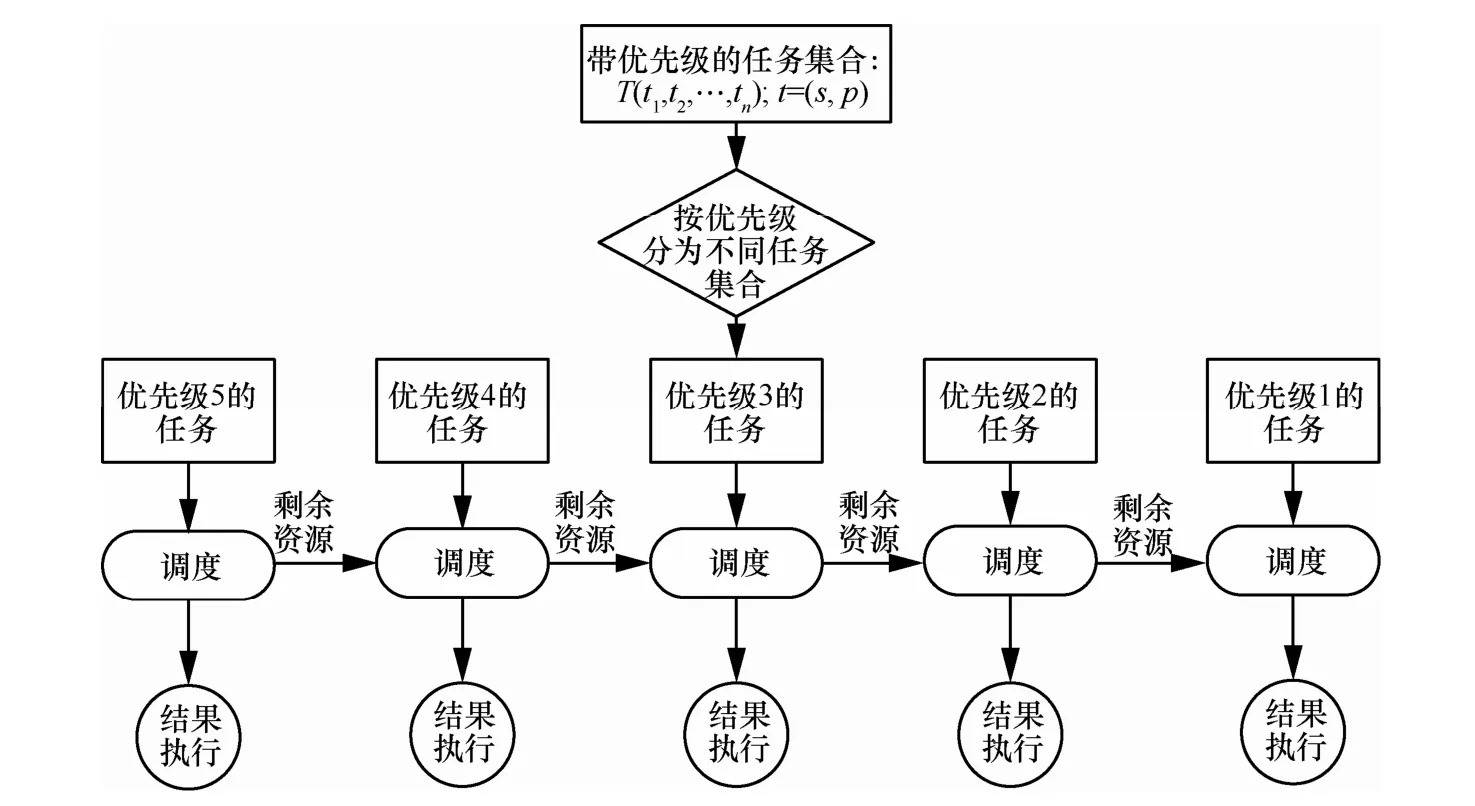
圖2 分級的帶偏好感知的PSO調度
5 結束語
本文對云存儲任務調度進行建模,總結并歸納出云存儲任務QoS要求主要有3個方面,即時間、代價和質量,每個方面又包含若干具體因素。修改PSO算法的適應度定義,用權重因子調節對不同QoS偏好的要求。實驗表明,通過對適應度的修改,確實可以使得PSO調度具備一定的偏好感知能力。但是,由于PSO是整體評價算法,則在各優先級任務分布差異較大的情況下,占有率較高的任務的QoS偏好會掩蓋其他占有率較低的任務的偏好,影響這些任務的偏好滿足率。解決方案是按優先級分別調度這些任務。
總體來說,本文最大的發現是對于任務分布不均的系統,不適宜用PSO進行有偏好感知的整體調度,一定要進行分級的調度。本文將PSO算法引入云存儲領域并進行偏好感知的一些經驗,特別是不成功的經驗希望能給后來者以參考。
[1] HAYES B. Cloud computing[J]. Communications of the ACM, 2008,51(7):9-11.
[2] LIN G , DASMALCHI G, ZHU J. Cloud computing and IT as a service:opportunities and challenges[A]. Proceedings of 2008 IEEE International Conference on Web Services[C]. Beijing, China, 2008.5.
[3] NAMJOSHI J, GUPTE A. Service oriented architecture for cloud based travel reservation software as a service[A]. Proceedings of the 2009 IEEE International Conference on Cloud Computing(CLOUD'09)[C].Bangalore, India, 2009.147-150.
[4] VAZHKUDAI S, TUECKE S, FOSTER I. Replica selection in the globus data grid[A]. Proceedings the First IEEE/ACM International Symposium on Cluster Computing and the Grid[C]. Brisbane, Qld, 2001.106-113.
[5] VAZHKUDAI S, SCHOPF J M, FOSTER I. Predicting the performance of wide area data transfers[A]. Proceedings of International Parallel and Distributed Processing Symposium, Marriott Marina[C]. Fort Lauderdale, FL, USA, 2002.34-43.
[6] CHANG R S, CHEN P H. Complete and fragmented replica selection and retrieval in data grids[J]. Future Generation Computer Systems,2007, 23(4): 536-546.
[7] RAHMAN R M, ALHAJJ R, BARKER K. Replica selection strategies in data grid[J]. Journal of Parallel and Distributed Computing, 2008,68(12): 1561-1574.
[8] JIN J, ROTHROCK L, MCDERMOTT P L,et al. Using the analytic hierarchy process to examine judgment consistency in a complex multi-attribute task[J]. IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, 2010, 40(5): 1105-1115.
[9] 熊潤群, 羅軍舟, 宋愛波等. 云計算環境下QoS偏好感知的副本選擇策略[J]. 通信學報, 2011, 32(7):94-102.XIONG R Q, LUO J Z, SONG A B,et al. QoS preference-aware replica selection strategy in cloud computing[J]. Journal on Communications,2011,32(7):94-102.
[10] MA T H, YAN Q Q, LIU W J,et al. Grid task scheduling: algorithm review[J]. The Institution of Electronics and Telecommunication Engineers, 2011, 28(2):158-167.
[11] CHEN R M, WANG C M. Project scheduling heuristics-based standard PSO for task-resource assignment in heterogeneous grid[J].Hindawi Publishing Corporation Abstract and Applied Analysis, 2011,2011:1-20.
[12] KENNEDY J, EBERHART R C. Particle swam optimization[A].Preceedings of the IEEE International Conference on Neural Networks,Path[C]. Australia, 1995.1942-1948.
[13] SHI Y H, RUSSELL E B. A modified particle swarm optimizer[A].Proceedings of IEEE International Conference on Evolutionary Computation[C]. Anchorage, AK, 1998.69-73.
[14] 王娟, 李飛, 張路橋. 限制解空間的 PSO 云存儲任務調度算法[J].計算機應用研究, 2013,30(1):127-129.WANG J, LI F, ZHANG L Q. Task scheduling algorithm in cloud storage system using PSO with limited solution domain[J]. Application Research of Computers, 2013, 30(1):127-129.
[15] HE X S, SUN X H, GREGOR V L. QoS guided min-min heuristic for grid task scheduling[J]. Journal of Computer Science and Technology,2003, 18(4):442-451.
[16] CHAUHAN S S, JOSHI R C. QoS guided heuristic algorithms for grid task scheduling[J]. International Journal of Computer Applications,2010, 2(9):24-31.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
