數(shù)據(jù)挖掘在地質(zhì)環(huán)境評測中的應(yīng)用
2014-01-28 07:39:48李佳,李瀟
城市地質(zhì) 2014年4期
李 佳,李 瀟
(1.北方工業(yè)大學(xué),北京 100186;2.北京市地質(zhì)調(diào)查研究院,北京 102206)
1 應(yīng)用現(xiàn)狀
數(shù)據(jù)挖掘技術(shù)在金融業(yè)、零售業(yè)、餐飲業(yè)及電信等行業(yè)中的到了廣泛應(yīng)用,并為人們帶來了良好的經(jīng)濟(jì)效益,但在地質(zhì)行業(yè)中的應(yīng)用相對比較少,主要被用在石油挖掘、探礦工程、地震預(yù)警預(yù)報(bào)等重大領(lǐng)域。但數(shù)據(jù)挖掘技術(shù)分析、處理大量數(shù)據(jù)信息能力的特點(diǎn)很適合應(yīng)用在有大量數(shù)據(jù)的地質(zhì)環(huán)境評測工作上。如果能夠通過數(shù)據(jù)挖掘技術(shù)分析出地質(zhì)環(huán)境各數(shù)據(jù)之間的關(guān)聯(lián)關(guān)系,并歸納出其權(quán)重指標(biāo),將會推進(jìn)環(huán)境評測工作的精準(zhǔn)性。
2 數(shù)據(jù)挖掘的方法
(1)數(shù)據(jù)挖掘過程
地質(zhì)環(huán)境數(shù)據(jù)挖掘過程一般由數(shù)據(jù)準(zhǔn)備、數(shù)據(jù)挖掘、知識表達(dá)3個(gè)階段組成,如圖1所示。地質(zhì)環(huán)境數(shù)據(jù)挖掘算法對數(shù)據(jù)有一定的要求,如數(shù)據(jù)冗余性小,出錯(cuò)率小等。由于地質(zhì)行業(yè)的特殊性, 現(xiàn)實(shí)各區(qū)域所采集到的地質(zhì)環(huán)境數(shù)據(jù)通常具有數(shù)據(jù)來源廣泛、異構(gòu)性、模糊性、冗余性、不完整性、噪聲、隨機(jī)性、數(shù)據(jù)量大而復(fù)雜的特點(diǎn)。因此,數(shù)據(jù)挖掘必須經(jīng)過數(shù)據(jù)準(zhǔn)備以提高數(shù)據(jù)質(zhì)量;數(shù)據(jù)挖掘階段包括選擇合適的數(shù)據(jù)挖掘算法模型, 并對挖掘模型進(jìn)行分析、驗(yàn)證、調(diào)整, 挖掘有價(jià)值的知識;知識表達(dá)階段是對結(jié)果進(jìn)行分析, 提取出最有價(jià)值的信息。
(2)數(shù)據(jù)準(zhǔn)備
使用的數(shù)據(jù)為北京市房山區(qū)地質(zhì)環(huán)境評估報(bào)告中的實(shí)際數(shù)據(jù),共包括土壤樣2643件、河流沉積物樣17件、垃圾土壤樣36件、水樣33件、玉米樣74件、柿子7件、梨5件,總計(jì)2888件。
(3)核心算法
標(biāo)準(zhǔn)方差是在樣本統(tǒng)計(jì)中,特別是大量樣本的統(tǒng)計(jì)計(jì)算,最常用到的幾種算法之一,公式為:
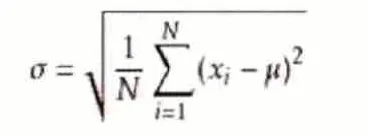
然而,在計(jì)算機(jī)編程中,還需要計(jì)算運(yùn)行方差(running variance),因?yàn)闃颖镜膫€(gè)數(shù)總是的在不斷變化的,即不斷遞增;如果每次增加,都要重新計(jì)算平均值,再按此公式計(jì)算出方差,雖可以實(shí)現(xiàn),但計(jì)算量會隨著數(shù)據(jù)的增加變的很大。
因此,遞推的公式就顯得格外重要;通過n-1個(gè)樣本時(shí)的方差值,和新增的樣本,就能得到此時(shí)這N個(gè)樣本的方差;這樣計(jì)算量不會變同時(shí)保持在一個(gè)很小的值,可大大提高程序的計(jì)算效率。遞推公式如下:
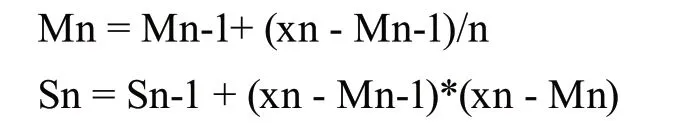
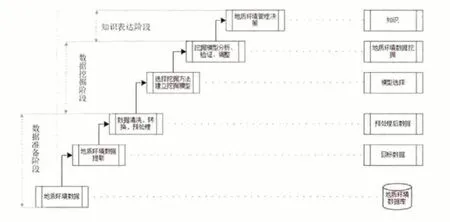
圖1 地質(zhì)環(huán)境評測數(shù)據(jù)挖掘過程
Mn為平均值,初始時(shí):M1 = x1, S1 = 0,而樣本方差 s =Sn/(n-1)
土地養(yǎng)分評價(jià)指標(biāo)包括大量營養(yǎng)元素、微量營養(yǎng)元素、有益元素等3個(gè)部分,均采用加法模型來計(jì)算指數(shù)得分P:
P肥綜=Σfi×Ci(i=1,2,3,4……n)
式中:P為指數(shù)得分;
fi為第i個(gè)評估指標(biāo)的隸屬函數(shù)值;
Ci為第i個(gè)評估指標(biāo)的權(quán)重。
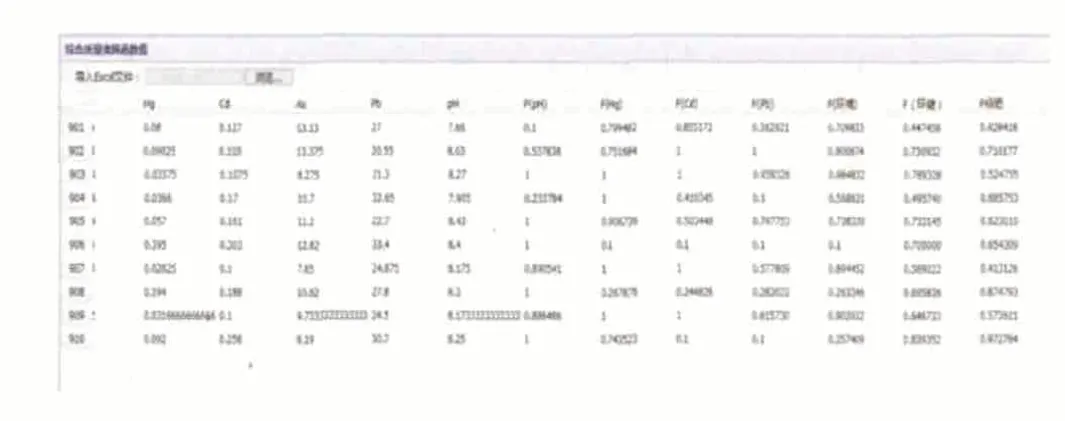
由此得到養(yǎng)分指標(biāo)(大量元素指標(biāo)得分 將土地養(yǎng)分和肥力劃分為3等(表1)。 表1 土地養(yǎng)分或肥力分等與綜合參數(shù)對應(yīng)表 數(shù)據(jù)導(dǎo)入后,經(jīng)過系統(tǒng)的分析統(tǒng)計(jì),結(jié)果如圖2所示: 圖2 數(shù)據(jù)挖掘系統(tǒng)計(jì)算結(jié)果 通過與人工計(jì)算結(jié)果(圖3)對比,可以算出數(shù)據(jù)挖掘計(jì)算結(jié)果與人工處理結(jié)果一致。 圖3 人工計(jì)算統(tǒng)計(jì)表 在數(shù)據(jù)挖掘過程中首先需要把已有的數(shù)據(jù)進(jìn)行規(guī)范化處理,建成數(shù)據(jù)挖掘源數(shù)據(jù)庫。處理方法包括統(tǒng)求和、求平均、正態(tài)分布、統(tǒng)一坐標(biāo)體系、監(jiān)測資料的規(guī)范化、評測單元的統(tǒng)一。然后進(jìn)行數(shù)據(jù)挖掘建模,進(jìn)行模型評估,選擇合適數(shù)據(jù)挖掘模型,部署模型,根據(jù)實(shí)施結(jié)果評測地質(zhì)環(huán)境健康度。實(shí)驗(yàn)證明,利用數(shù)據(jù)挖掘技術(shù)生成評測單元, 并利用預(yù)處理屬性數(shù)據(jù)庫對各區(qū)域進(jìn)行地質(zhì)環(huán)境評測, 其結(jié)果與環(huán)境現(xiàn)狀基本相符, 具有較高的可信度。 [1]黃 淇等.北京市平原區(qū)土地質(zhì)量地球化學(xué)評估報(bào)告[R].北京:北京市地質(zhì)調(diào)查研究院,2011. [2]于春香.數(shù)據(jù)挖掘技術(shù)簡介[J].福建信息技術(shù)教育,2005年01期. [3]梁 循.數(shù)據(jù)挖掘:建模、算法、應(yīng)用和系統(tǒng)[J].計(jì)算機(jī)技術(shù)與發(fā)展,2006年01期 [4]韓家煒.數(shù)據(jù)挖掘:概念與技術(shù)[M].北京:機(jī)械工業(yè)出版社,2012. [5]張良均.數(shù)據(jù)挖掘:實(shí)用案例分析[M].北京:機(jī)械工業(yè)出版社,2013. [6]坎塔爾季奇(美).數(shù)據(jù)挖掘:概念、模型、方法和算法[M].北京:清華大學(xué)出版社,2013.
3 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
電力與能源(2017年6期)2017-05-14 06:19:37
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
