基于Ap rio ri改進(jìn)算法的中藥處方分析技術(shù)
2014-02-18 05:43:38滕璐靈張寶林
西部中醫(yī)藥 2014年5期
滕璐靈,宋 堯,張寶林
甘肅省中醫(yī)院,甘肅 蘭州 730050
在中醫(yī)醫(yī)院,HIS系統(tǒng)數(shù)據(jù)庫里的中藥處方數(shù)據(jù)是極其寶貴的,對中醫(yī)處方數(shù)據(jù)的分析,可以得到中醫(yī)師針對不同患者開具的中醫(yī)處方用藥規(guī)律,可對今后同類病癥的治療起到輔助參考的作用。因此本研究以關(guān)聯(lián)規(guī)則挖掘為模型,設(shè)計了中藥處方分析算法。
1 中藥處方分析的基本原理
Apriori算法是一種挖掘布爾關(guān)聯(lián)規(guī)則頻繁項集的算法。其核心是基于兩階段頻集思想的遞推算法。算法需要對數(shù)據(jù)集進(jìn)行多步處理,第一步,簡單統(tǒng)計所有含有一個元素項目集出現(xiàn)的頻率,并找出不小于最小支持度的項目集;從第二步開始循環(huán)處理直到再沒有最大項目集生成。循環(huán)過程是:第n步中,根據(jù)第n-1步生成的(n-1)維最大項目集產(chǎn)生m維候選項目集,然后對數(shù)據(jù)庫進(jìn)行搜索,得到候選項目集的項集支持度,與最小支持度比較,從而找到n維最大項目集[1]。
中藥處方分析算法是以關(guān)聯(lián)規(guī)則模型為依據(jù),在給定中醫(yī)數(shù)據(jù)集中進(jìn)行頻繁項集的搜索[2],應(yīng)用最小支持度計數(shù)閾值為度量標(biāo)準(zhǔn)從候選集中查找頻繁項集。關(guān)聯(lián)規(guī)則在D中的支持度(suppor t)是D中事務(wù)同時包含X、Y的百分比,即概率;置信度(conf idence)是包含X的事務(wù)中同時又包含Y的百分比,即條件概率。
查找頻繁項集是實現(xiàn)中藥處方分析的關(guān)鍵,采用查找頻繁項集的經(jīng)典算法——Apriori算法為核心進(jìn)行設(shè)計實現(xiàn),但又通過縮小掃描事務(wù)集的范圍提高算法的執(zhí)行效率。
2 中藥處方數(shù)據(jù)的預(yù)處理
數(shù)據(jù)挖掘?qū)A(chǔ)數(shù)據(jù)的要求較高,因此數(shù)據(jù)預(yù)處理就變得尤為重要。數(shù)據(jù)的預(yù)處理通常按照以下步驟進(jìn)行:
2.1 數(shù)據(jù)篩選 中藥處方分析技術(shù)的研究對象是中醫(yī)醫(yī)囑中相關(guān)中藥處方的內(nèi)容,所以作為基礎(chǔ)數(shù)據(jù),首先需要將中藥處方信息從醫(yī)囑信息中分離開來[3]。
2.2 數(shù)據(jù)表標(biāo)準(zhǔn)化 在標(biāo)準(zhǔn)化處理的過程中需要解決的問題是中藥藥名的統(tǒng)一,一味中藥可能存在不同的別名,因此在統(tǒng)計分析時不應(yīng)作為不同的藥物來對待,需要根據(jù)中藥藥名對照表進(jìn)行匹配核對。
2.3 生成中藥處方 生成中藥處方布爾值統(tǒng)計表與事務(wù)統(tǒng)計表,流程見圖1、表1—5。
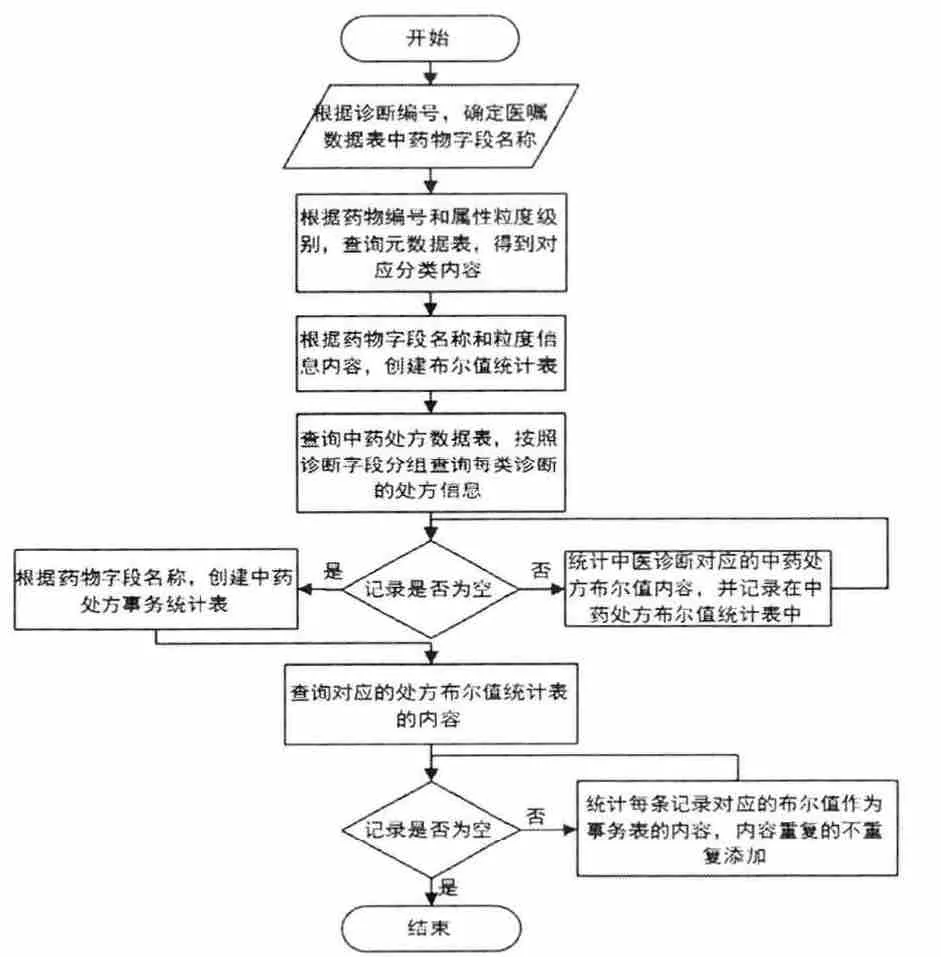
圖1 生成布爾值統(tǒng)計表與事務(wù)統(tǒng)計表的流程

表1 中醫(yī)診斷類別定義
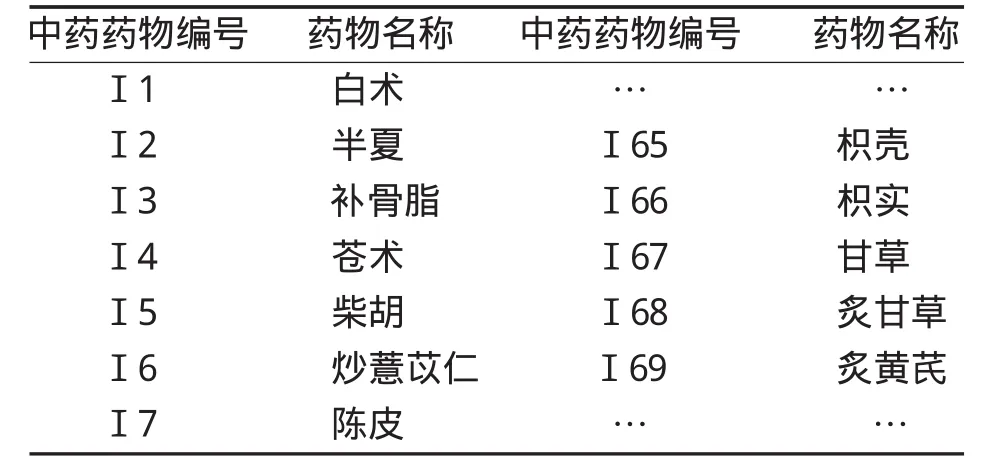
表2 中藥藥物信息定義

表3 中藥處方信息定義

表4 中藥處方藥物布爾值統(tǒng)計
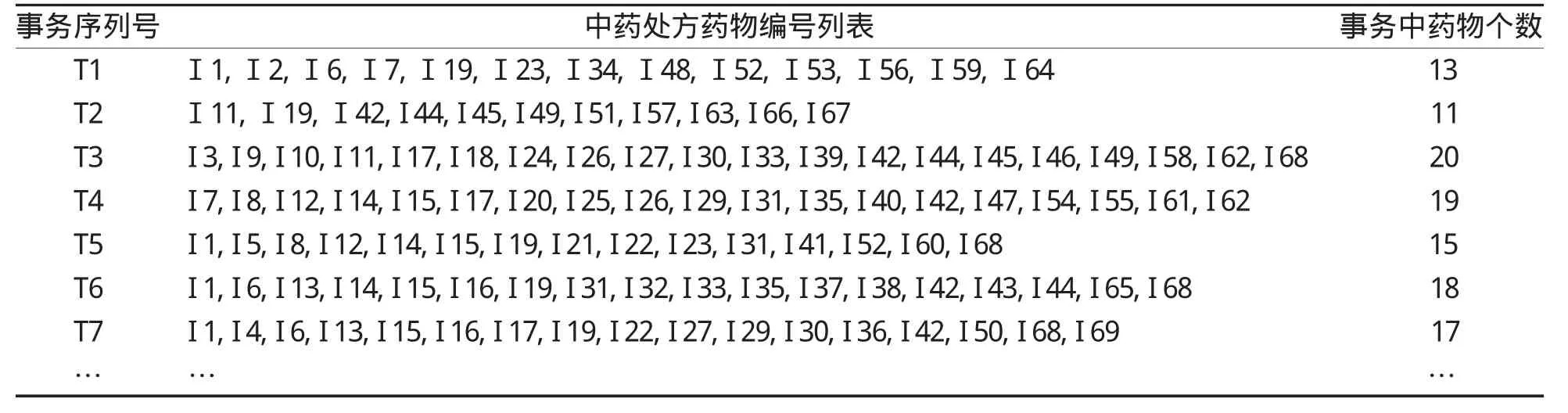
表5 中藥處方事務(wù)統(tǒng)計
3 中藥處方分析算法設(shè)計
以上得到的中藥處方事務(wù)統(tǒng)計表不是真正需要的有價值的信息,還需要通過中藥處方分析算法,對表中的記錄進(jìn)行進(jìn)一步分析[4],主要流程見圖2:
L1=f ind_f requent_1-itemsets(D);
for(k=2;Lk-1≠Φ;k++){Ck=apriori(Lk-1,min_sup);
for each t ransaction t∈D{Ct=subset(Ck,t);
for each candidate c∈Ctc.count++;}
Lk={c∈Ck|c.count≥min_sup}}
return L=所有頻繁集;
4 中藥處方分析中的算法運(yùn)行情況
通過輸入不同的中醫(yī)診斷編碼,可以得到不同病癥的中藥處方分析數(shù)據(jù)。首先篩選出中醫(yī)診斷中痹癥的中藥處方部分事務(wù),結(jié)合這些數(shù)據(jù)說明算法的實際應(yīng)用,見附圖1。
臨時表中輸出頻繁項集為{I1,I15,I19,I68}。由頻繁項集可產(chǎn)生中藥處方用藥規(guī)則,其置信度計算如下:

將事務(wù)編號進(jìn)行替換后得到中藥藥物名稱的規(guī)則記錄表,見表6。
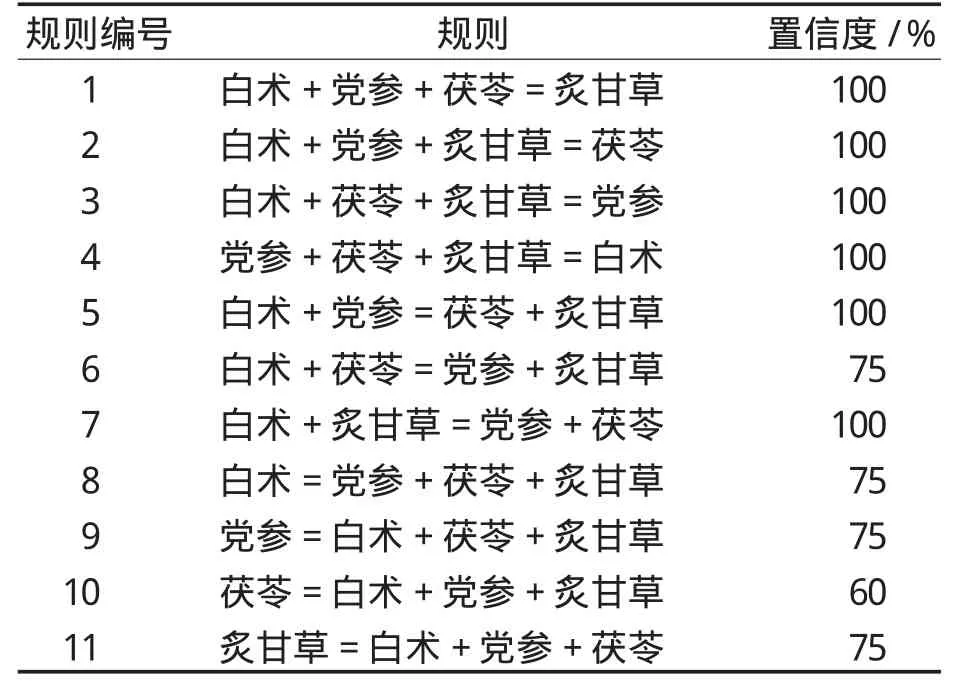
表6 轉(zhuǎn)換后的規(guī)則記錄
5 討論
傳統(tǒng)的Apriori算法在候選項集進(jìn)行支持度計數(shù)時,每次都要對原事務(wù)表進(jìn)行掃描,原事務(wù)表中的數(shù)據(jù)往往較巨大,導(dǎo)致該算法效率低下,因此在中藥處方分析算法中,設(shè)置了“藥物個數(shù)”字段,記錄每張?zhí)幏街邪闹兴幩幬飩€數(shù),在進(jìn)行候選集支持度計數(shù)時,只針對“藥物個數(shù)”>=3的記錄進(jìn)行掃描,以提高算法的執(zhí)行效率。

附圖1 頻繁項集生成過程
[1] Jiawei Han,Michel ine Kamber.數(shù)據(jù)挖掘概念與技術(shù)[M].范明,孟小峰,譯.北京:機(jī)械工業(yè)出版社,2007:133.
[2] 李凌艷,李認(rèn)書,孫鶴.數(shù)據(jù)挖掘技術(shù)在中藥研究中的應(yīng)用[J].中草藥,2010,41(5):I0016-I0018.
[3] 錢增瑾,辛燕.中醫(yī)藥數(shù)據(jù)預(yù)處理方法的設(shè)計與實現(xiàn)[J].計算機(jī)工程與設(shè)計,2005,26(12):3199-3200.
[4] 丁一琦.基于Apriori算法的數(shù)據(jù)挖掘技術(shù)研究[J].現(xiàn)代計算機(jī),2012(24):20-22.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中老年保健(2021年4期)2021-12-01 11:19:40
中老年保健(2021年4期)2021-08-22 07:08:32
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
金橋(2020年7期)2020-08-13 03:07:00
基層中醫(yī)藥(2018年6期)2018-08-29 01:20:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02
