基于空間向量模型的先秦文獻相似性研究
2014-03-21 07:16:56屈探春
文教資料 2014年30期
屈探春
(南京師范大學(xué) 文學(xué)院,江蘇 南京 210097)
基于空間向量模型的先秦文獻相似性研究
屈探春
(南京師范大學(xué) 文學(xué)院,江蘇 南京 210097)
本文基于空間向量模型,利用TF-IDF值,對《楚辭》、《公羊傳》、《管子》、《谷梁傳》、《國語》、《韓非子》、《老子》、《禮記》、《論語》、《呂氏春秋》、《孟子》、《墨子》、《商君書》、《詩經(jīng)》、《孫子》、《武子》、《孝經(jīng)》、《荀子》、《晏子春秋》、《儀禮》、《周禮》、《周易》、《莊子》、《尚書》和《左傳》等二十五本先秦文獻進行了相似度計算,通過分析文本的相似系數(shù),考察文本間的相似程度和文獻本身的特殊性。最終發(fā)現(xiàn):部分文獻用詞較為封閉,用語風格獨樹一幟;部分文獻用詞則包容性,與其他文本的一致性較高。
先秦文獻 相似性 向量空間模型 TF-IDF值
古漢語研究中,文本作者考證、著作年代探究等都是學(xué)者們的研究重點之一。他們常常從文本風格、用詞特征等角度出發(fā),通過比較同時期的同類作品或者尋找詞語源流演變的軌跡等方法來探尋文獻創(chuàng)作者,確定文獻創(chuàng)作年代或判別文獻真?zhèn)巍_@類研究中,古漢語研究者多依賴于文獻典籍或考古文物等資料,以此為據(jù)作出相應(yīng)的假設(shè)或者是論證已有假設(shè)。本文則主要利用自然語言處理中的相似度計算方法,通過計算文獻間的相似系數(shù)來判斷彼此間的相似程度。主要考察了《楚辭》、《公羊傳》、《管子》、《谷梁傳》、《國語》、《韓非子》、《老子》、《禮記》、《論語》、《呂氏春秋》、《孟子》、《墨子》、《商君書》、《詩經(jīng)》、《孫子》、《武子》、《孝經(jīng)》、《荀子》、《晏子春秋》、《儀禮》、《周禮》、《周易》、《莊子》、《尚書》、《左傳》這二十五本文獻,在統(tǒng)計各文本的詞頻、詞長等基本數(shù)據(jù)的基礎(chǔ)上,計算彼此間的相似系數(shù),分析相似情況。
一、相似度計算與面向空間的向量模型
(一)相似性計算
相似度計算在中文信息處理中較常使用,它多服務(wù)于文本分類和文本聚類,同時也在某種程度上依賴于文本分類和聚類,常用的特征項選取方法--信息增益(IG)就需依先前預(yù)定的分類情況來計算。無論是文本分類還是文本聚類,都需用一定的特征項來表示文本,也就是所謂的文本表示,其中特征項的選擇是基礎(chǔ)。依據(jù)是否需要類別信息,特征選擇可分為有監(jiān)督和無監(jiān)督兩種,文本分類多采用有監(jiān)督特征選擇方法,而文本聚類則多采用無監(jiān)督特征選擇方法,當然也有很多學(xué)者為了達到更高的選擇精度而嘗試把類信息融入到文本聚類中,使用有監(jiān)督學(xué)習(xí)方法中的信息增益來尋找文本中最具分類能力的特征運用于文本聚類。本文主要是對先秦二十五本文獻進行聚類分析,在未預(yù)測各文本間的分類情況的基礎(chǔ)上計算每兩本文獻間的相似性,將其與人們的主觀歸類進行比較,分析其差異。由于是在未知類信息的情況下進行的研究,所以主要通過無監(jiān)督特征選擇方法中的文檔頻率來控制特征項的選擇,同時從傳統(tǒng)的TF-IDF值出發(fā),充分考慮古典文獻的文本特征,通過實驗選取合適的閥值進一步提取特征項,利用空間向量模型計算各文本間的相似度。
(二)面向空間的向量模型
計算對象相關(guān)度的常用模型主要有空間向量模型和集合運算模型等。由于后者的局限性比較大,所以常用向量空間模型來計算文檔相似度。
向量空間模型是20世紀60年代由Salton等人提出的,該模型利用從文本中提取出的特征項的集合來概念化地表示整個文檔,并且依據(jù)每個特征項在文檔中的重要性來賦給不同的權(quán)重,也就是說一個未分類的文本就是一個由各個不同權(quán)重的特征項表示的向量,每個特征項代表向量中的一個維度,其中特征項既可以是文檔中的詞語也可以是短語還可以是單個的字。例如:假設(shè)存在一個文檔D,它由t1,t2,t3……tn這樣一些特征項組成,且各個特征項的權(quán)重分別為w1,w2,w3……wn,那么文檔D就可以表示為D(t1,w1;t2,w2……tn,wn)。但需要注意的是,在空間向量模型中,各特征項必須是互異的,且假設(shè)各特征項之間不存在先后順序。基于這兩個條件,特征項t1,t2,t3……tn就可被簡單地看作是一個n維的坐標系,而權(quán)重w1,w2,w3……wn則可看作是對應(yīng)維度的坐標值,那么,一個文檔便可以表示為一個n維的空間向量。D(w1,w2,w3……wn)就是該文本的空間向量模型,如右圖。
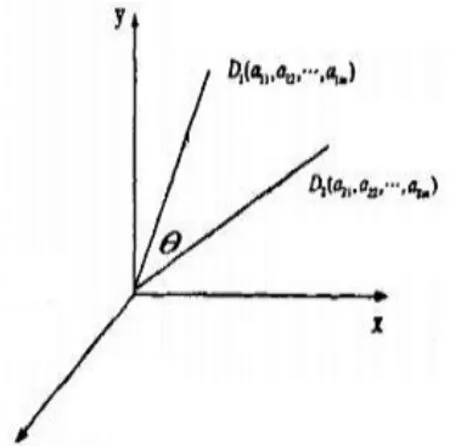
利用空間向量模型,文檔的相似度可以通過向量間的相關(guān)程度來度量。假設(shè)任意兩個文本D1和D2,那么這兩個文本可以用向量D1(w11,w12……w1n)和D2(w21,w22……w2n)來表示。從上圖可以看出,如果兩個文檔也就是兩個向量之間關(guān)系越靠近,那么它們兩者形成的夾角θ也就越小,相應(yīng)的cosθ就越大。因而,可以利用兩者夾角的余弦值來表示文本的相似系數(shù):
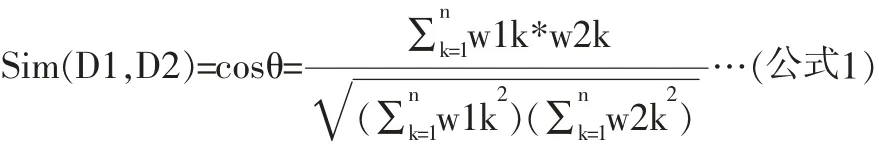
二、實驗操作
本文利用上面所介紹的空間向量模型對先秦的二十五本文獻進行了相似度計算,文本的原始資料來源于李斌等人的《Corpus-Based Statistics of Pre-Qin Chinese》一文,在實驗過程中,我們首先對原始數(shù)據(jù)進行預(yù)處理,結(jié)合古代漢語的特點刪除或者保留相應(yīng)數(shù)據(jù)。在此基礎(chǔ)上計算各詞語的TF-IDF值,結(jié)合詞語的文檔、頻率選取特征項。最后,根據(jù)特征項的權(quán)重計算文本相似度,制作圖表。
(一)預(yù)處理
古代文獻多以單字詞為主,但是也有多字詞的存在。在此需要聲明的是,本文以詞為特征項,從詞出發(fā)計算文本相似度。在對統(tǒng)計所得的原始資料進行處理時,我們充分考慮了古代漢語的語詞特點,刪去某些無用信息,保留相應(yīng)的數(shù)據(jù)。
首先,去標點符號。由于現(xiàn)代人所使用的古代文獻版本多為后人的注本,所以其中不免參雜了一些現(xiàn)在文本的信息。古代文本不存在標點,所以在預(yù)處理的過程中首先要將標點符號相關(guān)的數(shù)據(jù)資料刪去,以避免處理過程中無關(guān)信息的干擾。
其次,保留相同語詞的不同詞形。古代漢語文本中存在許多同義異形詞,對現(xiàn)代漢語而言這可能是一種用語不規(guī)范的問題,但是對古代漢語而言,同義異形詞也反映了一定的文本風格,體現(xiàn)了作者的創(chuàng)作習(xí)性。同時,也是不同時代用詞情況以及詞語發(fā)展演變情況的映射。因而,在文本預(yù)處理的過程中,我們保留了不同的詞形,把它們當作不同的條目來處理,例如:將“爲”和“為”列作兩個條目。
再次,保留相同詞形不同詞性的詞語。古代漢語中大量存在詞類活用的現(xiàn)象,而在不同時期的不同文本中活用的情況不同,這也是古漢語不同時期語言演變的特點之一,所以,我們也將不同詞性相同詞形的語詞分作不同的條目進行處理。如:將“食(n)”和“食(v)”作為兩條詞項。
(二)基于VSM的TF-IDF值計算
從統(tǒng)計特性的角度來看,判斷詞對于分類提供的信息量的大小主要有兩條標準:(1)一類文章中出現(xiàn)頻繁,而其他文章中出現(xiàn)不多的詞提供較多的分類信息;(2)在多類文章中均出現(xiàn)頻繁的詞含有較少的信息量。上文已經(jīng)提到利用權(quán)重來表示特征項在文本中的重要程度,并以此計算文檔相似度,而權(quán)重的計算則要通過TF-IDF公式計算獲得,TFIDF也正是在考慮了上述兩條標準。TF-IDF的基本思想就是把一個文檔分成兩個部分,一部分是帶有文本特征信息的,而另一部分則是不帶或者基本不帶文本分類信息的。各部分中所帶的文本特征信息的多少以及該信息在文檔中的重要性則是通過TF和IDF以TF*IDF的方式來衡量。其中,TF表示絕對詞頻,指一個詞在某一篇文檔中出現(xiàn)的頻率,該頻率越高,說明它區(qū)分文檔的能力也就越強。IDF指的是倒排文檔頻度,利用公式計算,表示一個詞在不同文檔中出現(xiàn)的范圍越廣,它區(qū)分文檔的能力就越低。利用TF-IDF公式可以尋找出頻率不高但是區(qū)分能力很強的一些特征項。TF-IDF值計算公式如下:

本文在通過統(tǒng)計所獲得的詞頻信息的基礎(chǔ)上利用該公式對各文本中的每一個詞語的TF-IDF值進行計算,為之后的特征選取以及相似度計算提供前提信息。
(三)特征項的選取
特征選取的主要作用是降維。在向量空間模型中,如果維數(shù)較大,也就是表示文本的特征項較多,那么不可避免會帶來很大的噪聲信息。而這些噪聲信息不僅對于文本表示不起積極作用,更會增加機器處理的工作量。因而用特征項表示文檔,不僅不會使重要的文本特征信息流失還可以達到減少機器處理的工作量的目的,從而提高效率。
本文的處理對象是古代漢語文本,其本身具有較大的特殊性,所以在特征項選取時,不僅僅要考慮除去噪聲和降低維度,另一重要任務(wù)是使文本之間詞例的頻度達到平衡,不能產(chǎn)生過大的差距,如果差距過大勢必會影響文本之間的相似性程度。為了選取最佳特征項,我們充分考慮了各文本的特殊用語特點,針對這些特征進行多重選擇,并依據(jù)某些文本的語言特色,特殊對待個別文本,進行特殊化處理。主要的篩選步驟如下:
首先,將計算得到的TF-IDF值為0的詞語去除。與現(xiàn)代漢語相同,分布較廣或者涵蓋所有文本的特征對某一特定文本的代表性不高,所具有的文本信息也相對匱乏,對該文本與其他文本的區(qū)分度或者相似度的貢獻值較低,所以在選取特征項時不加考慮。
其次,仍從TF-IDF值出發(fā),依據(jù)二十五本文獻的詞語頻度以及彼此間詞例數(shù)量的差異程度選取閥值,根據(jù)閥值刪除對文本表示貢獻度較小的語詞,使各文本的特征項數(shù)量達到平衡。經(jīng)實驗表明,將閥值定為TF-IDF值等于0.00005時,效果最佳。如下面的“二十五本文獻詞頻表”所示,未經(jīng)篩選之前(已經(jīng)過預(yù)處理),各文本的詞語個數(shù)差異較大,其中《孝經(jīng)》總共包含468個詞例,而《左傳》則達到了13343個,兩者差距較大,即使刪去TF-IDF值為0共同詞例也無法真正達到平衡。
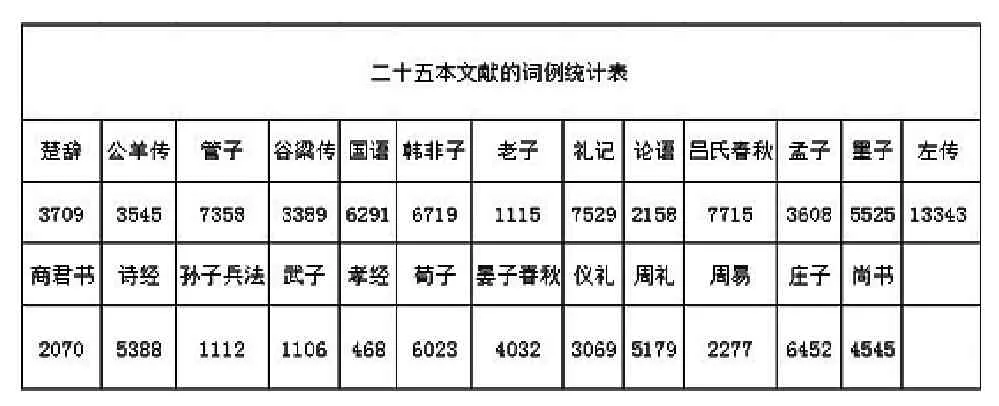
相比之下,以wij=0.00005為閥值進行篩選之后,所得結(jié)果中,各文本的詞例個數(shù)的差距顯著下降。如下面的“二十五本文獻的特征詞統(tǒng)計表”所示,《孝經(jīng)》的特征詞數(shù)量為376個,相比未篩選數(shù)據(jù)減少了92個;而《左傳》的特征詞數(shù)量為801個,比未進行篩選時減少了12542個,所降維度較大,經(jīng)處理后,兩者差距明顯縮小。就整體而言,篩選后的數(shù)據(jù)差異幅度較小,80%的詞例的頻度在300850之間,僅有兩例的詞頻達到了2000以上。
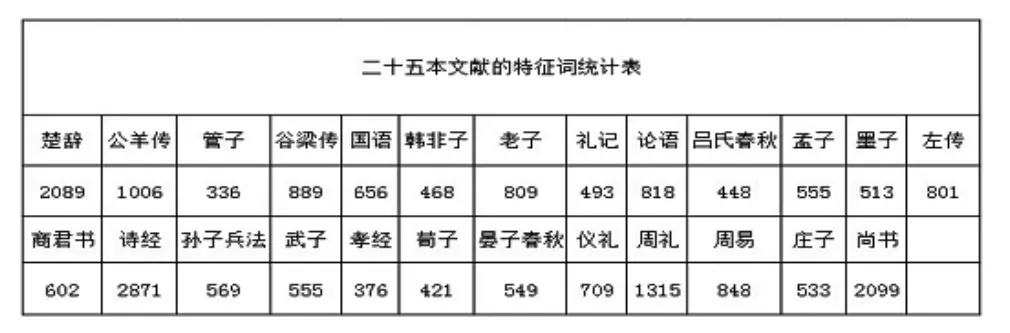
除了為了使各詞例的出現(xiàn)頻度達到均衡之外,將各文本的降維閥值設(shè)定為0.00005的原因還在于,降維前后文本間相似度的改變程度十分微小,不會對文本間的相似性關(guān)系的挖掘產(chǎn)生不利影響。以《公羊傳》和《禮記》為例,兩者在未降維之前相似度為0.0749,經(jīng)降維處理之后相似度變?yōu)?.0786。而《莊子》和《韓非子》在未降維之前的相似度為0.1875,經(jīng)降維之后為0.1845。兩者都只有很微小的改變,這種改變并不會對文本間的相似性產(chǎn)生重大影響。
(四)文本相似度計算
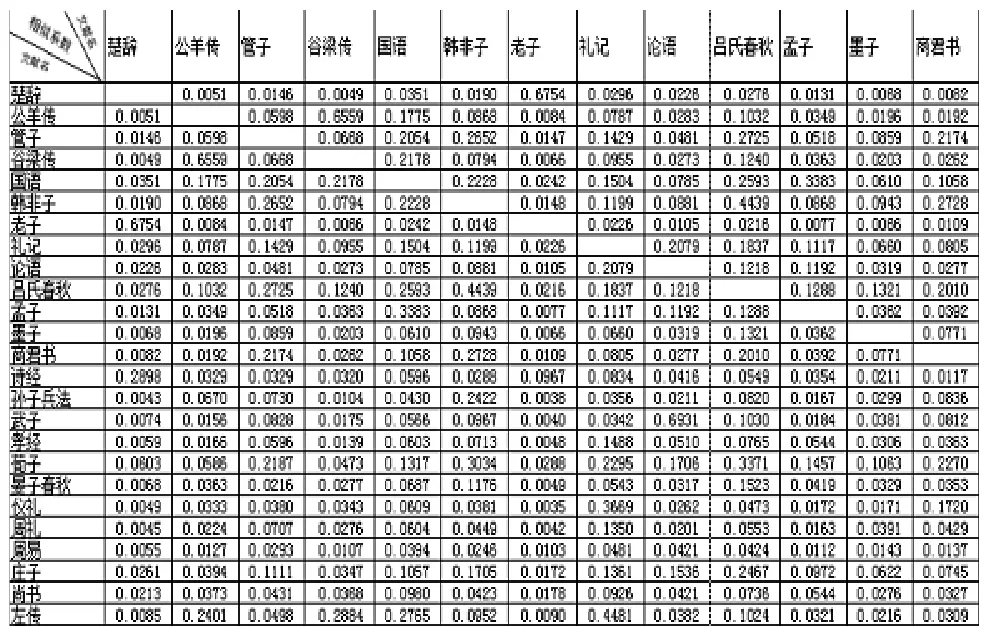
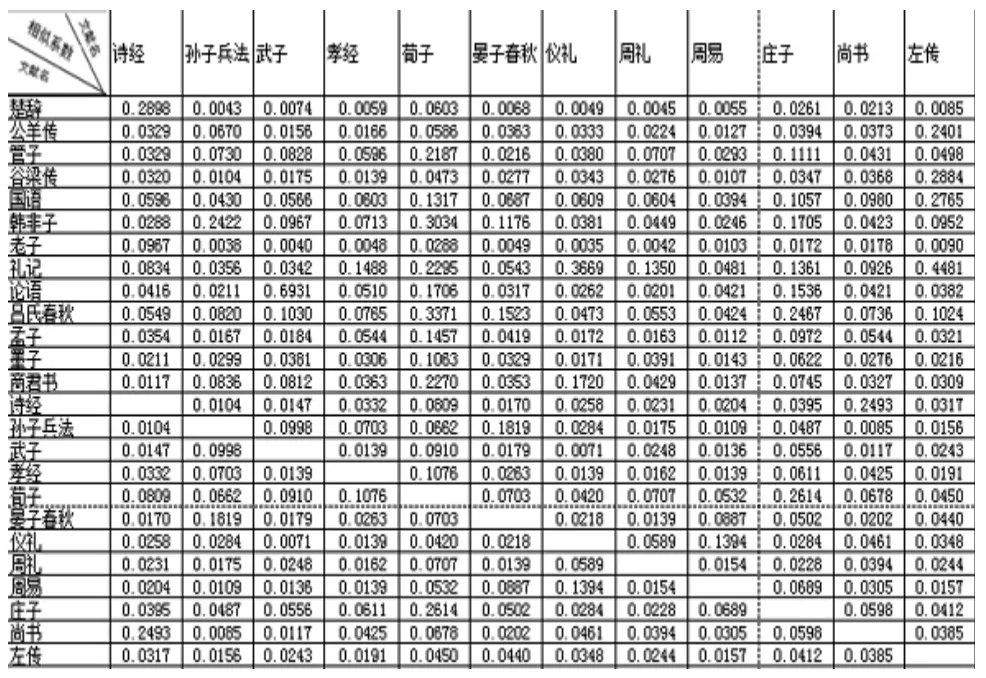
文本相似度是表示兩個或者多個文本之間的匹配程度的一個度量參數(shù),相似度越大,說明文本相似程度越高,反之越低。本文利用上述所述的方法篩選得出的特征項來表示文本,根據(jù)各特征項在不同文本中的權(quán)重,用公式(2)分別計算每兩個文本之間的相似系數(shù),所得的具體參數(shù)如下表。
三、實驗結(jié)果和分析
實驗的對象是先秦二十五本文獻,各文獻所屬類別不同,部分差異較大,若暫不考慮古漢語研究中對這二十五本文獻所持的觀點,僅從本文相似度計算所得的數(shù)據(jù)來觀察,我們發(fā)現(xiàn)了這樣一些特點和文本間的相關(guān)關(guān)系。
首先,各文本相似性差異較大,部分文本只與某一個或者兩個文本相似度較大,與其他文本的相關(guān)性很小,如:《老子》、《公羊傳》、《谷梁傳》和《楚辭》等,其中《老子》和《楚辭》僅彼此間相似度較高,與其他文本的相似度接近于0,值得注意的是,和其他文本的相似系數(shù)相比,《老子》和《楚辭》同《詩經(jīng)》的相似系數(shù)都要高一些。另有一部分文本則恰恰與此相反,它們約與一半以上的文本較為相似,只與少數(shù)文本有較大差異,如:《莊子》、《韓非子》、《管子》等。還有一部分文本是與其他文本也有一定的相關(guān)度,但是尤以某一本較為突出,如:《武子》與《論語》,《尚書》與《詩經(jīng)》,《周易》與《儀禮》等。
其次,本文是通過詞頻來計算相似性的,所以相似系數(shù)在某種程度上反映的是各文本在用語方面的相關(guān)性。那么,從用詞角度來講,部分文本的語言較具特色,如《老子》,它幾乎只與《楚辭》和《詩經(jīng)》相關(guān),可見其用詞風格的獨樹一幟。雖然在內(nèi)容和思想方面,《老子》和《楚辭》、《詩經(jīng)》大相徑庭,但是在用語上兩者卻又較為相似,這可能與《老子》一書多采用四字格、三字格等較為精煉的語句且多用對偶形式有關(guān),這與《楚辭》的體式非常相似。二十五本文獻中,除了用詞特殊的文本之外,也有具有很大包容性的文本,可以說某些文本的用詞是兼容并包的,它們與大部分文本相似,如:《商君書》、《荀子》等。這一方面說明在本文分析的二十五本文獻中,與該文本用語相似的文本較多,另一方面也說明了,該文本的用語較為通俗,為許多其他作品所共有。如《呂氏春秋》這一本百科全書式的著作,內(nèi)容包含甚廣,且由呂不韋眾多門客的作品編輯而成,這勢必會使其在用語和言語分格上呈現(xiàn)兼容并包的特點,這就使得其與其他各類題材的文本有較大的相似性。
最后,通過分析各文本的相似度關(guān)系折線圖,會發(fā)現(xiàn)詞語包容性較小的文本,與其相關(guān)的文本數(shù)量也相對有限且與不同文本比較所得的相似系數(shù)差異也較大,因而聚類相對容易。通過對相似文本較少的文本的分析,我們發(fā)現(xiàn)可對其作如下歸類:《公羊傳》和《谷梁傳》同屬一類,它們與《左傳》的語言風格最為接近。《楚辭》和《老子》可歸為一類,兩者與《詩經(jīng)》具有很大的共同點,但是《詩經(jīng)》一書中又融合了較多其他文本的特點,與《老子》的相似度不是特別高,而《楚辭》與《詩經(jīng)》卻具有很大相似性,所以三種可歸為同一類,其中《老子》又存在著某種特殊的差異性。《武子》與《論語》同屬一類,兩者與其他文本的相似程度都較低。
四、結(jié)語
本文運用中文信息處理中常用的相似度計算方法對《楚辭》、《公羊傳》、《管子》、《谷梁傳》、《國語》、《韓非子》、《老子》、《禮記》、《論語》、《呂氏春秋》、《孟子》、《墨子》、《商君書》、《詩經(jīng)》、《孫子》、《武子》、《孝經(jīng)》、《荀子》、《晏子春秋》、《儀禮》、《周禮》、《周易》、《莊子》、《尚書》、《左傳》等二十五本先秦文獻進行了相似系數(shù)計算,通過分析計算所得的數(shù)據(jù)發(fā)現(xiàn)了這些文獻在用語等方面存在的特點。其中,部分文獻的用詞較為封閉,用語風格獨樹一幟,如《老子》、《楚辭》等;而部分文獻用詞具有包容性,與較多的文本存在一致性,相似度較高。
[1]嚴莉莉,張燕平.基于類信息的文本聚類中特征選擇算法[J].計算機工程與應(yīng)用,2007,43(12):4.
[2]Xia Tian,Du Yi.Improve VSM Text Classification by Title Vector Based Document Representation Method[A].in The 6th International Conference on Computer Science & Education(第六屆國際計算機新科技與教育學(xué)術(shù)會議ICCSE 2011)論文集[C].2011.
[3]宗成慶.統(tǒng)計自然語言處理[M],北京市:清華大學(xué)出版社,2008.
[4]Li Bin,Xi Ning,F(xiàn)eng Minxuan,Chen Xiaohe.Corpus-Based Statistics of Pre-Qin Chinese[J].in Chinese Lexical Semantics,Ji,D.,Xiao,G.,Editors,Springer Berlin Heidelberg,2013:145-153.
[5]Xiahui Pan,Jiajun Cheng,Youqing Xia,Xin Zhang,Hui Wang.Which Feature is Better?TFIDF Feature or Topic Feature in Text Clustering[A].Multimedia Information Networking and Security(MINES),2012 Fourth International Conference on,2012:425-428.
[6]李連,朱愛紅,蘇濤.一種改進的基于向量空間文本相似度算法的研究與實現(xiàn)[J].計算機應(yīng)用與軟件,2012,29(2).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
