利用SQL存儲過程實現數據分布存儲
2014-07-07 02:44:06黃世芹簡薇薇
中低緯山地氣象 2014年2期
王 珺,倪 雷,李 揚,黃世芹,簡薇薇
(貴州省貴陽市氣象局,貴州 貴陽 550002)
1 引言
當前區域自動站數據庫的應用現狀:自從全省大范圍增建區域自動站,并提高區域自動站的數據發送頻次以來,截止目前,全省有近2 000個區域自動站,每10 min就有一次氣象數據。高覆蓋、高頻次的氣象要素為實時氣象的監控分析和防災減災提供了非常關鍵的數據支持。同時,這些數據也已不再是文本數據,而是基于SQL的數據庫數據,查詢統計使用更方便快捷。也正因此如此,各種基于SQL氣象數據的應用系統廣泛開發和使用,不光省級部門開發,地州級部門也在開發各種適于自身的應用系統。但是,由于所有的區域自動站數據都是由省氣象統一接收、管理和使用,所有地州、區縣都通過氣象專線連接省局SQL服務器獲取數據,而隨著過多應用系統的使用,和省局SQL服務器的連接數量劇增,查詢統計應用的頻次也相應劇增,給SQL服務器的負擔也越來越重,另外,如果應用系統的SQL操作代碼不正確或不完善,將會給SQL服務器帶來更大的壓力,甚至SQL服務器因無法處理而崩潰,2012年就數次出現SQL服務器崩潰的情況,導致大量使用該服務器的應用系統無法正常使用。此外,過多的數據連接、過多的數據交換也占用了氣象專線的帶寬,雖然每次數據交換的量不算很多,但是隨著系統的過多使用,無形中,這樣的占用還是會造成一定的影響。
2 數據分布式存儲的思考
由于全省都集中使用省局的SQL服務器,考慮到負擔和網絡開銷的問題,省局會根據自身的需要調整SQL服務器的存儲,一般只保存當年的數據或近段時間的數據,這就給其他部門在使用上帶來不便,只能查詢近期一段時間的數據或實時數據,而不能進行歷史數據的統計應用等。如果放開限制,可以任意查詢,則服務器是很難承受和處理如此眾多的查詢請求的。因此有必要考慮數據的分布存儲,將省局的數據分布存儲到9個地州級部門,形成省局是一級SQL服務器,地州局是二級SQL服務器的形勢,省局只負責一級SQL服務器的維護和各種應用,而每個地州局及其縣級部門的應用系統使用該地州局的SQL服務器,以這樣的方式布局,則能很大程度上減輕省級服務器的負擔、降低的網絡帶寬的消耗、同時,提升了地縣一級部門的應用系統的統計查詢和應用效率。
2.1 分布式存儲的方法
省級SQL服務器到地州級服務器的存儲應該是實時存儲的,即當省級服務器有更新數據時,也要在地州級數據庫上同步更新同樣的數據,并且,省級數據庫在進行刪除和其他操作時不會對地州級數據庫有任何影響,只需保證有更新數據時傳輸給地州級數據庫即可。
實現以上步驟的方法可以考慮在地州級固定某IP的服務器,然后在省級SQL上做對該IP的發布與訂閱,但是,該方法需要省級SQL上主動發布,如果地州級服務器出現故障不能及時傳輸數據,則需要省級管理人員通知地州級管理員,這也在一定程度上增加了省級管理人員的工作負擔。
另外,可以由地州級編寫合適的更新數據軟件來同步更新SQL數據,但是編寫程序繁瑣,而且如果程序編寫得不好,一方面會造成程序的維護困難,另一方面可能會造成省級服務器的負擔增加或直接癱瘓,2012年省局服務器就出現類似的癱瘓故障。而采用在地州級服務器上做SQL的存儲過程和代理作業,則省級部門只需要管理維護好省級的服務器即可,有任何硬件故障只需地州級管理員自行解決,地州級服務器會自行檢測并自動更新數據,且很穩定。
2.2 SQL上存儲過程的代碼實現
建立SQL存儲過程,實現實時更新數據的原理為:
①獲取全省的站點的站號;
②使用循環,查詢每個站點在地州一級數據庫的最新數據的時間;
③使用循環,查詢每個站點在省級數據庫上大于本地最新數據時間的數據;
④將查詢出的更新數據寫入到本地數據庫中。
以下是相應的存儲過程代碼(以小時數據庫為例):
Create Procedure[dbo].[tabhourdata_CC]
AS
declare@StaID varchar(10)
declare@BD_Observtime datetime
declare staid_cursor SCROLL CURSOR for
select distinct StationID
from OpenDataSource('SQLOLEDB','Data Source=10.203.6.35;User ID=***;Password=***').[AWSGZ].DBO.StationPar
begin
open staid_cursor
Fetch First from staid_cursor Into@StaID
While(@@Fetch_Status=0)
begin
set@ BD_Observtime =(selecttop 1 observtime from
tabhourdata where stationID=@Staid order by observtime desc)
insert into tabhourdata select* from
OpenDataSource('SQLOLEDB','Data Source=10.203.6.35;User ID=***;Password=***').[AWSGZ].DBO.tabhourdata
where observtime>@BD_Observtimeand stationID=@staID
Fetch next from staid_cursor into@staID
end
end
close staID_cursor
deallocate staid_cursor
go
代碼中,要先創建游標,之后通過兩個begin….end循環完成數據的查詢和寫入,但是一定要注意代碼where observtime>@BD_Observtime and stationID=@staID,這一句代碼涉及到地數據和省局數據對比查詢的條件,一個是時間對比查詢,一個是對應站點的查詢,這里的代碼如果沒寫好,將會造成無限循環,從而導致存儲過程的運行無法成功,甚至還會給兩端的數據庫系統造成負擔。
以上存儲過程的代碼也相應適用于分鐘數據庫,只需更改代碼中相應的數據表名即可,需要注意的是,地州一級的SQL數據庫在庫結構和表結構上須和省級保持一致。
3 SQL上的代理作業設置流程
建立存儲過程后,需要在SQL上做代理作業,類似Windows系統中的計劃任務,使得存儲過程能按計劃運行,步驟如下。
①設置自動啟動SQL Server代理:首先運行SQL企業管理器,在企業管理器的界面中,在“SQL Server組”選擇本地服務器(Local(Windows NT)),在其上單擊鼠標右鍵,進入“屬性設置”,在屬性配置的常規選項卡中,將“自動啟動SQL Server代理”勾選上(圖1)。
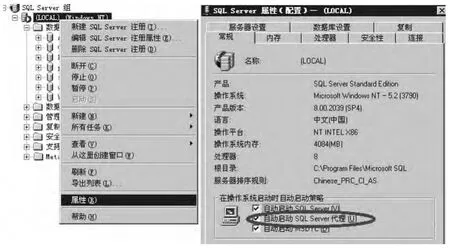
圖1 屬性配置選項卡
②啟動代理作業:展開本地服務器,進入“管理”選項中,選中“SQL Server代理”,并啟動該代理(圖2a)。
③新建作業:啟動“SQL Server代理”后,選擇其中的“作業”選項,并“新建作業”(圖2b)。

圖2 啟動代理、新建作業選項卡
④設置新建作業:在“新建作業”中,分別對“常規”、“步驟”、“調度”中分別設置,以更新小時數據庫為例,在“常規”選項卡中,為該作業命名為“HourData”。
在“步驟”選項卡中,同樣新建一個步驟名“Hour”,需要注意的是,下方的“數據庫”選項默認是“master”,需要選擇為本地的數據庫“AWSGZ”,否則不能正確運行;在“命令”文本框里,將上面的存儲過程的代碼復制并粘貼到文本框中(圖3)。最后單擊“確定”完成“步驟”的設置,這一步很關鍵。
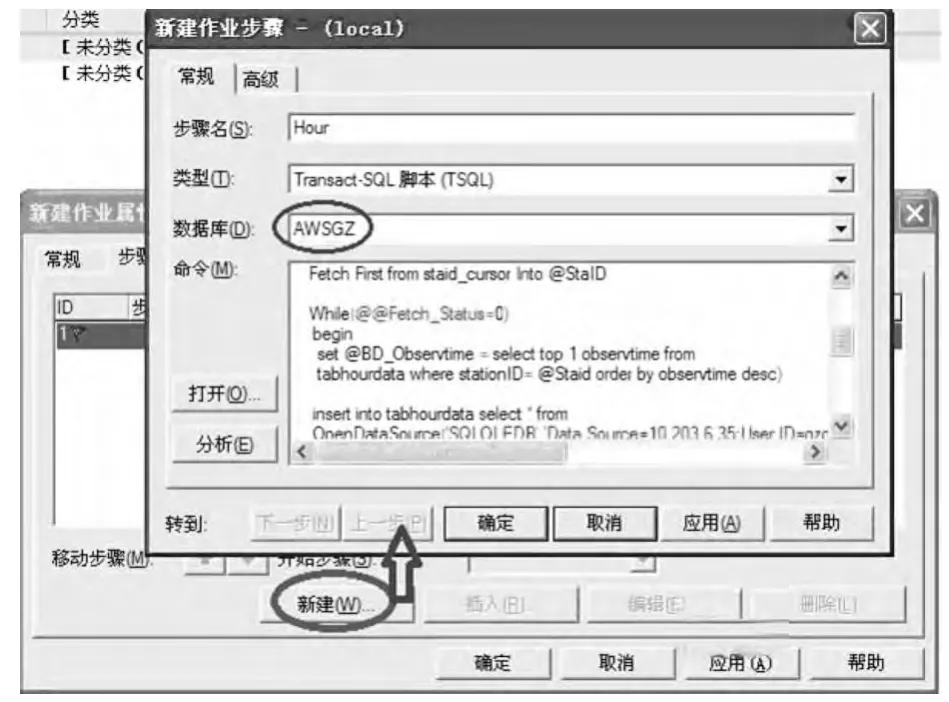
圖3 數據庫選項設置
其次設置“調度”作業,在“調度”選項卡中,設置命令的運行時間,類似windows系統的任務計劃,首先是“新建調度”,命名后,在“調度類型”上一定要選擇“反復出現”,并點擊“更改”,設置其重復時間,發生頻率上設定為“每天”,并且“每日頻率”上設定為1 h運行一次,考慮到省局數據庫實在整點10 min內完成數據的入庫,因此,在起始時間這里設置為整點15 min運行(圖4)。
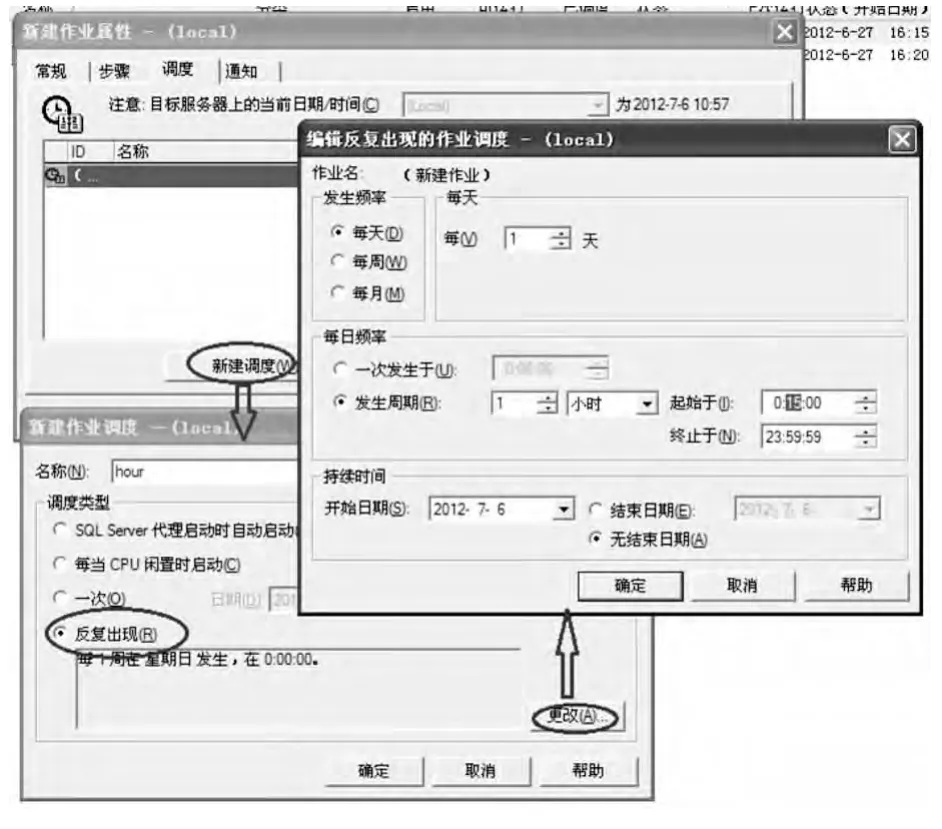
圖4 “調度”選項卡設置
修改參數后,最后確定,完成整個作業的設置,自此,該存儲過程就會在每小時整點15分由SQL自帶的管理器自動運行。
同樣的,分鐘數據庫的同步作業可按照上面的步驟建立即可。
4 使用測試總結
經過在貴陽市氣象局的運行測試,該SQL存儲過程和代理作業運行非常好,以普通性能的臺式機做測試,若每個站點只有一條數據記錄更新,全省近2 000個站點的記錄從查詢到寫入本地數據庫基本運行5~6 min,這其中大約只有5%的時間是和省級數據庫連接查詢產生,絕大部分時間都是消耗在寫入本地數據庫中,考慮到若只有9個連接數連接到省級服務器,這樣的時間效費比是很高的,省級的服務器壓力更小,運行也將更順暢。
[1]蔣秀英,張建成.SQL Server 2000數據庫與應用[M].北京:清華大學出版社,2006.
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
財經(2017年2期)2017-03-10 14:35:35
故事大王(2016年7期)2016-09-22 17:30:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
都市快軌交通(2014年4期)2014-02-27 08:35:05
