電子商務環境下企業信息平臺相關關鍵技術研究
2014-07-13 06:45:20劉慧梅殷鋒社
電子設計工程 2014年12期
劉慧梅,殷鋒社
(1.陜西國防工業職業技術學院 陜西 西安 710300;2.陜西工業職業技術學院 陜西 咸陽 712000)
電子商務環境下企業信息平臺相關關鍵技術研究
劉慧梅1,殷鋒社2
(1.陜西國防工業職業技術學院 陜西 西安 710300;2.陜西工業職業技術學院 陜西 咸陽 712000)
目前物流企業以及大型制造企業管理信息系統之間的互聯互通和互操作性很差,導致信息資源的巨大浪費和利用效率低下。針對企業信息集成、企業應用集成和數據抽取、轉換、裝載,為實現LIP開放、復雜、多層次的計算任務,對分布式對象和分布式數據庫技術進行了分析,并在Matlab環境下,對這些數據進行聚類仿真。
管理信息系統;信息集成;計算任務;遠程數據庫
隨著中國物流行業的發展,物流運營管理也正在逐步走向現代化。目前物流企業以及大型制造企業的運輸公司建立了諸多運輸管理信息系統,為物流運輸管理及調度指揮發揮了巨大作用。但是,由于管理體制、建設時間、建設需求等多方面原因,造成信息系統的重復建設、數據質量較差,形成各自獨立、自成體系的信息孤島,各系統之間的互聯性、互通性和互操作性很差,導致信息資源的巨大浪費。
1 分布式對象與分布式數據庫技術
物流過程中信息的流動是跨系統進行的,物流系統必須實現跨地區的信息實時傳輸、遠程數據訪問、數據分布處理和集中處理的結合等。由于物流系統相關部分的地域分布性,為有效的控制物流企業信息平臺(LIP)開發、管理和維護的復雜性,實現LIP開放、復雜、多層次的計算任務和同時快速平穩的處理大流量數據,使用了分布式對象和分布式數據庫技術[1]。
1.1 分布式對象技術
分布式對象技術是指在網絡計算平臺上開發、部署、管理和維護以資源共享和協同工作為主要應用目標的分布式應用系統的技術。它采用面向對象的多層客戶/服務器計算模型,將分布在網絡上的全部資源(系統層或應用層)都按照對象的概念來組織,每個對象都有定義明晰的訪問接口。目前分布式對象技術已經成為建立應用框架和軟構件的核心技術,OMG的CORBA,Microsoft的ActiveXIDCOM和Sun公司的JavaIRMI是目前流行的3種主流技術。
1.2 分布式數據庫技術
分布式數據庫系統是物理上分散而邏輯上集中的數據庫系統。分布式數據庫系統使用計算機網絡將地理位置分散而管理和控制需要不同程度集中的多個邏輯單位 (通常是集中式數據庫)連接起來,共同組成一個統一的數據庫系統。這里的邏輯單位指LIP的相關節點,由于每個節點在業務上需要處理各自的數據,因此它們都有自己的數據庫、中央處理機、終端,以及各自的局部數據庫管理系統。采用分布式數據庫結構,解決了大量數據集中存放所帶來的問題,通過系統內在的訪問、采集、分布和復制機制實現對遠程數據庫的操作。
2 異構數據傳輸技術
在電子商務環境下,LIP必需解決聯盟成員、客戶企業、相關政府機構之間的大量異構數據傳輸的問題。物流網絡中,所有節點企業或集團子公司的物流信息可以認為被包含在一個廣義的數據庫中。這種情況下,每個節點企業的物流系統就是該數據庫中的一個數據源。由于不同企業的物流信息和業務組織不盡相同,該廣義數據庫是異構的。要挖掘并有效利用異構數據[2],需要集成物流網絡中所有的數據源,這在實際操作中將是困難的。
EDI一直都是商業機構間數據交換的標準,我國的很多政府機構如海關、銀行、稅務、保險等都建立了各自的EDI系統,因此現階段LIP必需支持EDI。但是EDI結構復雜、開發和應用成本昂貴,不可能被普遍應用,XML的出現突破了EDI的發展瓶頸。開放且基于文本的XML非常適用于服務器之間交換事務信息,利用XML的可延伸性及自我描述的特性,同一數據可以用不同的表現方式提供給不同用戶,在多個不同的數據庫之間傳遞信息。應用XML進行數據傳輸并不強迫物流網絡中的所有節點企業使用統一的數據處理標準,而是通過客戶化的接口來實現不同系統數據格式之間的統一,能夠實現企業與多個不同的供應商、客戶及配送單位之間物流信息互動,使銷售或采購訂單可以直接驅動物流的運作,并將即時的物流運作信息反饋到企業內部信息管理系統。
3 數據倉庫技術
數據倉庫[3]是一個面向主題的、集成的、時變的、非易失的數據集合,支持管理部門的決策過程。它從大量的事務型數據庫中抽取數據,并將其整理、轉換層新的存儲和組織格式,通過數據清理、數據變換、數據集成、數據裝入和定期數據刷新來構造,是一種多個異種數據源在單個站點以統一的模式組織的存儲。從概念上說,數據庫支持的是操作型的日常事務處理,面對的是低層操作人員與管理人員;而數據倉庫支持的是信息型或分析型的數據處理,即是針對制訂決策過程中管理層的需求而進行的處理,或是通過瀏覽大量數據以找出其中的趨勢的處理,所面對的是中高層決策管理人員。
數據倉庫具有下列特征:
1)面向主題性與傳統數據庫面向應用相對應,主題是一個在較高層次上將數據歸類的標準,每一個主題對應一個宏觀的分析領域,并通過一系列具有共同的公共碼鍵的表在數據倉庫中實現。
2)集成性原始數據與適合DSS分析的數據之間的差別很大,因此數據進入數據倉庫之前,必然要經過加工和集成。
3)穩定性數據倉庫主要為決策分析提供經過綜合、集成的面向某一分析主題的數據,這些數據原則上是只讀的,不允許決策分析人員直接對數據進行修改或刪除等操作。因此數據倉庫中的數據是相對穩定的。
4)隨時間變化性數據倉庫的穩定是相對于應用而言,由于事務處理數據庫中數據是不斷更新的,每過一定的時間階段,事務處理數據就要轉化為歷史數據增加到數據倉庫中來。
LIP中數據倉庫主要作用就是跨越企業時空界限,把不同部門不同事務處理系統的數據集成起來提供一個統一的數據視圖,從而使各數據倉庫應用方便地獲得有關公司運作狀況或客戶行為等方面更為綜合的信息。數據倉庫系統運作流程如圖1所示。

圖1 數據倉庫系統運作Fig.1 Operation of data warehouse system
最流行的數據倉庫模型是多維數據模型,這種模型可以以星型模式、雪花模式或事實星座模式(星系模式)形式存在。 LIP數據倉庫采用事實星座模式,因為它能對多個相關的主題建模。在開發利用LIP時,使用的數據庫服務器是Microsoft SQL Server 2000,它提供了一個綜合的數據倉庫平臺,是設計、創建、維護及使用數據倉庫解決方案更加容易和快捷。
4 數據挖掘技術及其系統實現方案
目前,數據挖掘涉及的學科領域和方法很多,有多種分類法。根據挖掘任務,可分為分類或預測模型發現、數據總結、聚類、關聯規則發現、序列模式發現、依賴關系或依賴模型發現、異常和趨勢發現等等;根據挖掘對象,可分為基于關系數據庫、面向對象數據庫、空間數據庫等多種數據庫,以及基于Web的數據挖掘;根據挖掘方法,可分為機器學習方法、統計方法、神經網絡方法、決策樹方法和數據庫方法等。
4.1 數據挖掘中聚類分析方法研究
在物流信息平臺上物流企業業務量大、信息來源多和各種實時交互信息量巨大,蘊藏著豐富的隱藏信息,同時這些信息是呈實時、動態變化的。從物流企業的信息網絡中抽取所需用信息作分析對企業作出正確的決策和史好的適應市場的需求是非常重要的。數據挖掘技術正是從此類汪洋大海似的信息寶庫中實時發現、貯存,及時地提取,并充分地利用各領域中隱含的知識、規律、規則,以用于決策、過程控制、信息處理、查詢處理等。
一般來說,作某種分析時所要求的系列數據往往是同一類型的數據,如某網點某段時間某種貨品的存儲數量等,這時候要用到數據挖掘中的聚類分析方法。所謂聚類[4],是將物理或抽象對象的集合分割成為由類似的對象組成的多個類的過程,由聚類所生成的簇是一組數據對象的集合,同一個簇中的對象彼此相似,不同簇中的對象間區別較大。聚類分析是根據事物本身的特性,研究對象分類的方法,依據的原則是使同一類中的對象具有盡可能大的相似性,而不同類中的對象具有盡可能大的差異性。聚類分析要解決的就是實現滿足這種要求的類的聚類。作為統計學的一個分支,聚類分析已經被廣泛地研究了許多年,主要集中在基于距離的傳統聚類算法,如 k-means(k一平均值)、k-rnedoids(k一中心點)算法等。這些算法具有聚類結果清晰,無模糊、二義的優點,但也存在許多問題,如要求事先指定K個聚類初始點,且結果對K值(聚類數)大,}1、非常敏感,對于不同K值的聚類結果往往大相徑庭。因此,如何事先確定K值是傳統聚類算法所存在的最大問題。神經網絡是在研究生物神經系統的啟示下發展起來的一種信號處理方法,其具有強大的并行處理機制、任意函數的逼近能力、學習能力,以及自組織和自適應能力等特性,從而可代替復雜的傳統算法,使信號處理過程更接近于人類思維活動。神經網絡在人工智能、自動控制、計算機科學、信息處理、模式識別等方面的應用越來越廣,為實現企業信息平臺中的數據挖掘聚類功能,本文就應用Kohonen神經網絡實現聚類分析的方法及應用進行研究。
4.2 Kohonen神經網絡算法分析
自組織特征映射網絡((SOM網絡)是由芬蘭赫爾辛基大學神經網絡專家Kohonen教授提出來的,這種網絡模擬大腦神經系統自組織特征映射的功能,它是一種競爭式學習網絡,在學習中能無監督地進行自組織學習。由于聚類分析結果的不可知性,聚類不是基于訓練數據的,而是直接對數據源進行處理,其過程是一個無導師指導的學習過程,因此,本文在聚類分析器中采用了Kohonen神經網絡[5]。
Kohonen神經網絡算法Kohonen算法是一種無教師示教的聚類方法,它能將任意維輸入模式在輸出層映射成一維或二維離散圖形,并保持其拓撲結構不變,即在無教師示教的情況下,通過對輸入模式的自組織學習,在競爭層將聚類結果表示出來。此外,網絡通過對輸入模式的反復學習,可以使連接權矢量空間分布密度與輸入模式的概率分布趨于一致,即連接權矢量空間分布能反映輸入模式的統計特性。該算法往往在完成極高維數、超大量數據和高度非線性問題的聚類,模式表征和數據壓縮,分類等任務時是一個很有效、很簡便、快速、并且穩健性好的算法。
Kohonen的學習算法如下:
1)給出輸出節點(即矢量模式)的個數M及輸入節點(即每個矢量元素)的個數N,并將從輸入節點i到輸出節點3的權值初始化。
2)對網絡輸入模式 X(t)=(x0(t),x1(t),…,xN-1(t))T計算輸入矢量X(t)全部輸出節點所連權矢量的距離。
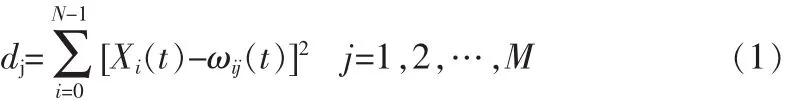
3)從dj中選出最小值所對應的輸出節點J為響應節點。
4)按照公式調整J及其鄰域NEj(t)內各輸出節點的權值。
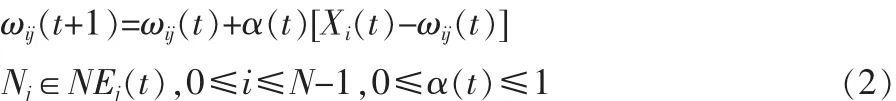
5)若還有輸入樣本數據,則轉到2),反復迭代,直到算法收斂。
4.3 實例測試與仿真分析
設有某一對一對應關系(X,Y),其中X表示輸入信號大小,Y表示輸入信號經過處理后的輸出信號大小,現在要考察輸入X與輸出Y之間的關系可分為多少類。每類輸入輸出關系是以一定形式來表示的,這種特定的形式可稱為某一聚類。從某數據庫中隨機選擇九百多組上述數據,下面使用聚類Kohonen神經網絡[6],在Matlab環境下,對這些數據進行聚類仿真。
1)準備數據源。由對應關系(X,Y)可知輸入矢量為兩輸入模式,將數據存入二維數組p,部分數據如下:

2)選定參數。取神經元為5,取學習速率為0.2,定義網絡最大訓練步數為1 500步。
3)運用newc()函數創建競爭層網絡,建立網絡結構。代碼如下:
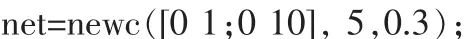
4)運用網絡初始化函數init(),對競爭網絡初始化。代碼如下:
5)初始化連接權矢量。代碼如下:

6)運用網絡訓練函數train()訓練上述初始化后的網絡。代碼如
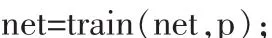
7)調用繪圖函數plot()繪制P輸入矢量值的平面圖和網絡訓練t權值矢量,并將結果以圖形的形式顯示出來。這里用加號“+”顯示輸出量,用圓圈來顯示經過網絡訓練后的權值矢量。代碼如下:
8)運用仿真函數sim()對一個具有輸入矢量p的神經網絡進行仿該函數最后返回網絡的輸出結果。以[0.7;5」為輸入矢量進行仿真,代碼如


5 結束語
隨著企業競爭的日趨激烈,需要企業信息系統為企業決策提供有關員工、供應商和客戶的詳細數據,并且要求這些數據是準確、一致和完整的。只有這樣才能夠保證更加高效的運營[7],更高的客戶滿意度,以及更加快速有效的科學決策。因此消除現有信息系統間的信息孤島問題,建立異構系統間信息共享、信息交換的有效機制,成為企業信息化建設中的首要問題。
[1]錢曉江.物流信息系統體系結構[J].東南大學學報,2001,31(11):40-41.
QIAN Xiao-jiang.The architecture of logistics information system[J].Journal of Southeast University,2001,31 (11):40-41.
[2]李玲青,竇明暉,周洞汝.C/S模式結合OLE技術在開發GIS系統中的應用[J].計算機工程,2002,28(1):260-262.
LI Ling-qing,DOU Ming-hui,ZHOU Dong-ru.application.C/S model with OLE technology in the development of GIS system[J].Computer Engineering,2002,28(1):260-262.
[3]鄒咸林,楊俊杰.分布式對象技術及客戶機/服務器體系結構[J].湖北民族學院學報,2002,20(3):62-65.
ZOU Xian-lin,YANG Jun-jie.A distributed object technology and client/server architecture[J].Journal of Hubei Institute for Nationalities,2002,20(3):62-65.
[4]R.Otte,M.Roy.CoRBA教程:公共對象請求代理體系結構[M].北京:清華大學出版社,1999.
[5]Tilanus B.Information systems in logistics and transport[J].Bsenier Scienee,1997(5):56-66.
[6]唐衛寧,耿國華.電子商務中基于CORBA的WEB數據挖掘研究[J].計算機應用研究,2002(7):45-47.
TANG Wei-ning,GENG Guo-hua.Research of WEB data mining based on CORBA in electronic commerce[J].The Research and Application of Computer,2002(7):45-47.
[7]張海龍,馮森,李建祥,等.電動汽車充換電服務網絡運營管理系統的研究與設計[J].陜西電力,2011(11):47-50.
ZHANG Hai-long,FENG Sen,LI Jian-xiang,et al.Research and design of electric vehicle charging net management system[J].Shaanxi Electric Power,2011(11):47-50.
Research of key technology of enterprise information platform under the electronic commerce environment
LIU Hui-mei1,YIN Feng-she2
(1.Shaanxi Institute of Technology, Xi’an 710300, China; 2.Shaanxi Polytechnic Institute, Xianyang 712000, China)
At present,the interconnection between logistics enterprises and large manufacturing enterprise management information system and interoperability is poor,causing great waste of information resources and low utilization efficiency.In view of the enterprise information integration, enterprise application integration and data extraction, conversion, loading, in order to realize the LIP open, complex, multi-level computing tasks, the distributed objects and distributed database technology is analyzed, and in the Matlab environment, clustering of these data simulation-
management information system;information integration;computing;remote database
2014-01-13稿件編號201401094
咸陽市科技計劃項目(2012k02-14)
劉慧梅(1976—),女,甘肅武威人,工程碩士,講師。研究方向:軟件工程。
TN-9
A
1674-6236(2014)12-0030-04
猜你喜歡
物流技術與應用(2019年8期)2019-09-04 03:29:56
汽車觀察(2018年12期)2018-12-26 01:05:44
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
現代企業(2015年2期)2015-02-28 18:45:09
中外會展(2014年4期)2014-11-27 07:46:46
商界(2014年12期)2014-04-29 00:44:03
