基于語音識別與特征的無監督語音模式提取
2014-08-05 04:28:34趙慶衛顏永紅
計算機工程 2014年5期
張 震,趙慶衛,顏永紅
(中國科學院語言聲學與內容理解重點實驗室,北京 100 190)
基于語音識別與特征的無監督語音模式提取
張 震,趙慶衛,顏永紅
(中國科學院語言聲學與內容理解重點實驗室,北京 100 190)
在語音識別與特征系統中,通過無監督的方法搜索未知語音流中出現的語言模式。利用語音識別系統的多候選結果,通過分段動態時間彎曲算法進行語言模式的搜索,采用有效的聚類算法以及置信度估計算法,提高系統性能,同時建立僅基于特征匹配的相似音頻片段檢測系統,不使用任何知識源,僅從語音中獲取重復的語音模式,在廣播電視新聞與自然口語對話2個測試集上對比2個系統的性能。實驗結果表明,基于識別的系統具有較好的檢測效果,而基于特征的系統具備多語種的推廣性。
語音識別;語音模式發現;分段動態時間彎曲算法;圖聚類算法;音素回環后驗概率計算
1 概述
隨著多媒體互聯網的發展,出現越來越多的多媒體數據。之前網絡傳輸成本、存儲成本都相對高昂,人們更喜歡使用文本形式進行信息的存儲,而隨著信息科技的不斷發展,網絡傳輸速度的飛速提高,存儲的成本越來越低廉,可以大量存儲多媒體信息,如語音、視頻錄像等。目前如何有效地處理這些數據成為了一個研究熱點,許多研究單位和機構致力于有效地進行信息利用。因為多媒體數據的信息存儲于圖像、聲音中,無法直接利用這些信息,需要一些技術對信息進行相關處理,在圖像上有圖像識別等關鍵技術,而語音上則依賴于語音識別的相關技術,比如語音轉文本技術[1]、語音識別關鍵詞技術[2]。而某些場景需要在兩段音頻中挖掘出一些有效信息,并不像進行關鍵詞搜索一樣,有預先定義的關鍵詞列表,在語音中搜索對應的關鍵詞結果。所以需要一些新的方式進行語音流中相似信息的檢出,這種無監督的方法對于語音的利用提供了很多方便[3],比如對海量數據進行無監督聚類,對于刑偵案件上,需要提取出發音相同或者相近的片段進行比對,以作為案件偵破的證據。
本文工作的出發點是在未知信息的語音流中,用語音流檢索語音流的方式進行語音信息無監督的發掘,找到語音流中重復的短語語義實體等[4]。文中構建了2套系統,分別為基于語音識別的相似音頻片段檢測系統與基于特征匹配的相似音頻片段檢測系統。基于識別的系統具有檢出率高、精度高的特點,而基于特征的檢測系統構建簡單,并且不需要積累大量的知識源,可以用于多語種音頻模式的檢測。
2 任務背景以及相關工作
在過去幾十年中,在自動語音識別領域,研究者在大詞表連續語音識別領域做出了巨大努力,同時獲得了很好的技術進步[1]。不過對于大多數應用場景,技術架構思路基本相同,那就是將語音送入到語音識別器,將語音轉換為文本,然后在文本層面上搜索需要的語義實體,但是這些都是在預先定義的一系列詞語框架內。然而,人類和機器的學習方式具有本質的區別,機器學習中對語音的處理是將語音從頻譜域映射到狀態域,然后在狀態域中結合了預先定義的知識源,如發音詞典、語言模型等,將語音轉換為預先定義的詞典中的單元序列。關心的是如何在無監督的輸入下從語音本身去發掘一些信息[4]。
2.1 模式發現
模式發現在各個領域都有一定的應用,從計算生物學到音樂分析再到多媒體總結,這些領域存在共通點是需要利用模式發現的原則對數據進行梳理,在計算生物學上[5],在模式發現上研究動機是尋找生物序列中顯著基本圖樣。
2.2 無監督語言獲取
這個領域的工作和本文的內容比較接近,其研究重點都是關心如何在發音層面無監督地獲得語言的信息。近來,一些研究者提出了機器利用多關聯輸入進行發音獲取的模型。有些研究者利用回溯神經網的長記憶結構將分段的語音轉化為音素的后驗概率,在后驗概率上進行匹配,獲得一些發音結構[6]。文獻[7]提出了基于模型的詞庫感應方法。這種方法迭代地更新模型的參數來最小化輸入語音與模型之間的描述長度。以及基于模型的動態規劃算法對語音進行分段來獲得詞語實體獲取。
3 基于識別的相似音頻片段檢測系統
3.1 系統架構
首先將語音信號進行分段處理,將分段之后的語音送入到語音識別器中進行識別,生成中間結果(多候選結果)。將識別中間結果送入到語音片段檢測模塊得到匹配的結果信息,之后將這些結果按照一定準則進行聚類[8],得到聚類的不同類別,這些類的結果被送入到置信度重估模塊[9],對置信度得分進行重估,得到最終的搜索結果。系統結構如圖1所示。

圖1 基于語音識別的檢測系統架構
3.2 模式發現算法
基于識別的相似音頻片段檢測系統的核心部分是在識別生成的中間結果上進行相似片段的檢索,尋找序列中的匹配符號串采用動態時間彎曲算法是比較常見的方法[10]。但是傳統的動態時間彎曲算法是針對整段的符號序列進行對齊,尋找最優序列,而對于整段語音流的輸入來尋找最優對齊序列的問題,傳統的動態時間彎曲就有其局限性,因為難以確定在語音流中什么位置才是真正的匹配最優序列的起始位置,需要對動態時間彎曲算法進行一定的改進以適應在整段語音流中檢測出能夠匹配的語音模式的要求,所以采用改進的分段動態時間彎曲算法作為主要手段來搜索語音流。
3.2.1 分段動態時間彎曲算法
改進動態時間彎曲算法,建立全局的約束條件來限制對齊算法可以進行的區域形狀;通過對同一對進行對比的序列設定多個對齊的起點和終點獲得多個對齊路徑,然后進行失配函數的計算。
如圖2所示,所有的對齊區域都限定在一定范圍內,假定現在有2個符號序列X和Y,分別表示為X={x1, x2,…,xNx}與Y={y1,y2,…,yNy}。設定一個對齊寬度的方法保證了2個序列在進行對比時,其中一個不會在序列長度上超出另外一個序列很多。這里設定了一個準則。
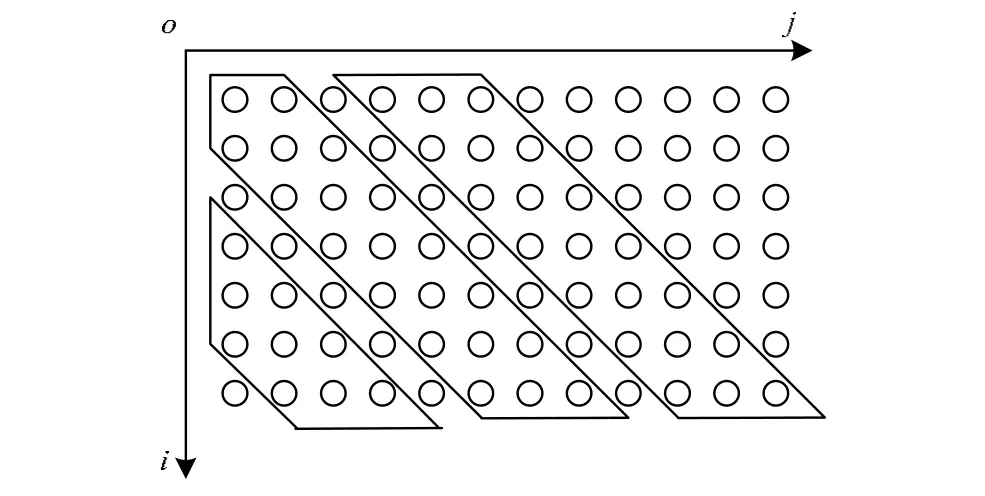
圖2 分段動態時間彎曲算法示意圖
對于一個對齊路徑起始于{i1,j1}經過了k步對齊到達的狀態pk={ik,jk}必須滿足下列條件:

這就限制了在局部進行對齊尋找最優路徑的區域限制在寬度為2R+1的對角線區域內,幾個對齊區域設定的R=1,而由于存在對齊區域的限制,局部對齊的路徑很可能無法達到{Nx,Ny},這樣只有每個序列的部分可以匹配。
3.2.2 詞語實體的搜索匹配
因為目前識別器性能受語音質量、環境噪音等影響比較大,識別首選的識別率有限,只使用識別的首選結果,將會對語音的搜索結果造成一定影響,所以考慮采用語音識別器生成的多候選結果進行詞語實體的搜索。在語音識別器常用的多候選結構中,詞圖與混淆網絡是比較常用的,因為詞圖是一個嚴格的有向無環圖的結構,而分段動態時間彎曲算法需要輸入的序列是線性結構,這里采用混淆網絡作為進行搜索的多候選結構,一個典型的混淆網絡結構如表1所示。

表1 一個典型的混淆網絡線性結構
混淆網絡中的每個元素都同樣可以表示為三元組:xi={phi, p( phi),pos( phi)}。其中,phi是發音單元在語音識別器的發音詞典的代表符號;p( phi)為該識別單元的置信度分數;pos( phi)為該識別單元在識別出的句子中的位置,識別單元的置信度采用詞圖置信度進行估計。
而混淆網絡中的每個聚類可以將其考慮為一個結果向量:X={(w1, c1),(w2, c2),…,(wn, cn)}。其中,wi表示一個聚類中第個詞的詞id;ci表示該詞的置信度。
而對于混淆網絡的匹配得分計算公式為:

其中,X與Y分別為對比的2個結果向量;?(X, Y)為規整因子,計算得到的得分處于同樣的動態范圍內可以比較。
3.3 聚類算法
將語音中的不同片段視為結點,而語音片段之間的相似關系作為連接2個結點的邊,可以將語音中的不同片段映射為鄰接圖,如圖3所示。圖中連接的邊為一個聚類中2個結點的相似性得分,采用一種自上而下的聚類方法[11],先將每一個結點視為獨自一個分類,然后通過逐漸將連接關系加回到鄰接圖內,使得結構化得分最大,這是一種在社交網絡中尋找社團實體的聚類算法,和研究的目標類似。

圖3 語音片段轉換為鄰接圖的示意圖
3.4 進一步的置信度估計方法
在尋找到合適的聚類模式之后,為了提高系統的性能,采用基于音素回環的音素后驗概率[12]作為置信度計算,計算公式為:

其中,ps為搜索到的結果中包含的音素序列,共有Nt個音素;tsi與tei分別為音素的起止時間;P( phti|Ot
t seii
)為音素的聲學后驗概率,通過三音子保持上下文而中間音素進行回環計算得到。
4 基于特征匹配的相似音頻片段檢測系統
基于識別的相似音頻片段檢測系統需要大量的數據訓練知識源,知識源的積累是一個長期的過程,數據需要人工進行標注,這無形中又是一筆巨大的投入。而且對于語料豐富的語種來說,比如漢語、英語,可以有資源進行語料積累,但是對于比較小的語種,語料的積累是很難實現的,所以希望能利用本身來搜索語音中的信息。
4.1 系統架構
基于特征匹配的系統架構因為沒有使用語音識別器,所以架構相對簡單,輸入的語音經過分段模塊分成小段的語音,根據特征提取模塊,直接用3.2節描述的算法進行匹配搜索,然后進行結果聚類。系統架構如圖4所示。

圖4 基于特征的相似音頻片段檢測系統架構
4.2 相似度計算
在基于特征的相似音頻檢測系統上,相似度的計算,直接通過計算特征域的歐幾里得距離加權得到。現有X= {x1,x2,…,xNx}為一段語音的特征序列,Y={y1,y2,…, yNy}為與X匹配的語音特征序列,存在著一組映射關系:

則X與Y的相似度計算公式為:

其中,d(x, y)代表了向量x與向量y的歐幾里得距離。
5 實驗與分析
5.1 實驗設置
在2個測試集上進行了實驗,一個測試集為廣播新聞的測試集,時長為2 h,說話人使用語言均為標準普通話,語速均勻,背景噪音比較小。在廣播新聞的測試集上一共有197個聚類,也就是發音相同或者相似的詞語實體,另外一個測試集自然電話口語對話的測試集時長為1.5 h,說話人帶有一定口音和感情色彩,具有一定的背景噪音,在自然口語對話的測試集上一共有136個聚類。
在系統上選用的分段模塊為基于能量檢測的分段模塊,將輸入的語音流按照能量比切分為小段的語音,語音識別器采用的是中科信利基于樹拷貝的單邊解碼器[13],聲學模型使用400 h數據進行訓練,采用的特征為39維的PLP特征(13維基維特征做二階差分),發音詞典采用了包含44 92 0個中文詞組的中文詞典,語言模型的階數為三階,語言模型的訓練預料為6 GB的文本。在語音識別器解碼的參數設置方面,集束搜索寬度設置為120,相當于1.5倍實時(xRT)的解碼速度。在進行分段動態時間彎曲匹配搜索時,對角線區域的限制參數R=2,表明在進行動態時間彎曲匹配的時候,允許2個音素的匹配錯位。
在使用特征匹配的系統上,設置了R=10,代表在進行分段動態時間彎曲的時候,允許10幀的匹配錯位。
本文采用的指標為純度,其計算為每個聚類精度的均值,計算公式如下:

另外還采用了召回率作為指標,表示召回的詞語數與語音流中的匹配詞語實體總數的比值。
5.2 結果分析
在廣播電視測試集上用基于語音識別的系統進行檢測,性能如表2所示。

表2 系統在廣播電視測試集上的性能
從表2中可以看到,在語音質量比較好的語音上,純度和召回率的表現都比較令人滿意,使用聲學置信度進行置信度的重估之后,會使純度指標大幅上升,但是會對召回率有一定的影響。在自然電話口語對話測試集上的性能如表3所示。

表3 系統在自然口語對話測試集上的性能
從表3中可以看到,由于自然電話口語對話測試語音質量相對較差,最后得到的純度和召回率都和在廣播新聞電視測試集上的性能有一定差距,同時聲學置信度對于性能的影響與廣播新聞電視測試集是一致的。
測試了2個測試集在基于特征的相似音頻片段檢測系統的性能,如表4所示。

表4 系統在2個測試集上的性能表現
由表4可以觀察到,在少了知識源的加入,只依靠特征本身從語音中去尋找語音模式是比較困難的,性能與基于識別的系統存在較大的差距,但是因為此系統簡單,依賴的資源少,可以進行多語種檢測的推廣。
6 結束語
本文從無監督地從語音流中獲得語音信息的角度出發,從大量的語音中獲取一些重復的詞語模式。建立2套系統,分別是基于現在流行的語音解碼器的架構以及直接基于特征匹配的系統架構。在性能上,基于語音識別器的系統性能遠遠好于基于特征的系統,但是語音識別器的構建過程復雜,對于語言資源比較匱乏的小語種,則顯得無能為力,這時只依靠特征進行匹配的系統仍然能發揮一定作用。下一步研究將主要集中在基于特征匹配的相似音頻片段檢測系統性能的提升以及將相似音頻檢測技術推廣到多語種的應用場景中。
[1] 劉 加, 潘勝昔. 用TMS320C31實時實現電話語音識別系統[J]. 清華大學學報: 自然科學版, 1998, 38(z1): 51-54.
[2] 韓 疆, 劉曉星, 顏永紅, 等. 一種任務域無關的語音關鍵詞檢測系統[J]. 通信學報, 2006, 27(2): 137-141.
[3] Park A S. Unsupervised Pattern Discovery in Speech[J]. IEEE Transactions on Audio, Speech, and Langu age Processing, 2008, 16(1): 186-197.
[4] Shen Wade, White C M, Hazen T J. A Comparison of Queryby-Example Methods for Spoken Term Detection[C]//Proc. of Interspeech’09. Brighton, UK: [s. n.], 2009: 421-426.
[5] Rigoutsos I, Floratos A. Combinatorial Pattern Discovery in Biological Seque nces: The T EIRESIAS Algorithm[J]. Bioinformatics, 1998, 14(1): 55-67.
[6] Roy D K. Learning Words from Sights and Sounds: A Computational Model[J]. Cognitive Science, 2002, 26(1): 113-146.
[7] Brent M R. An Efficient, Probabilistically Sound Algorithm for Segmentation and Word Discovery[J]. Machine Learning, 1999, 34(1/3): 71-105.
[8] Ng A Y, Jordan M I. On Spectral Clustering: Analysis and an Algorithm[C]//Advances in Neural Information Processing Systems. Cambridge, USA: MIT Press, 2002: 849-856.
[9] 劉 鏡, 劉 加. 置信度的原理及其在語音識別中的應用[J]. 計算機研究與發展, 2000, 37(7): 882-890.
[10] Christiansen R, Rushfort h C. Detecting and Locating Key Words in Continuous Speech Using Linear Predictive Coding[J]. IEEE Transactions o n Aco ustics, Sp eech and Signal Processing, 1977, 25(5): 361-367.
[11] Newman M E J. Finding and Evaluating Community Structure in Networks[J]. Physical Review E, 2004, 69(2).
[12] Sun Yanqing, Z hao Qingwei. Combining Ph oneme L oop Posteriori with Decoding Posteriori as Confidenc e Measure for Speech Recognition in E-service[C]// Proc. of International Conference on e-Education, e-Bu siness, e-Manage ment, and e-Learning. [S. l.]: IEEE Press, 2010: 238-241.
[13] Gao Jie, Zhao Qingwei, Yan Yonghong, et al. Efficient System Combination for Syllable-confusion-network-based Chinese Spoken Term Detection[C]//Proc. of the 6th International Symposium on Chinese Spoken Lan guage Processing. Kunming, China: [s. n.], 2008: 366-369.
編輯 顧逸斐
Unsupervised Speech Pattern Extraction Based on Speech Recognition and Feature
ZHANG Zhen, ZHAO Qing-wei, YAN Yong-hong
(Key Laboratory of Speech Acoustics and Content Understanding, Chinese Academy of Sciences, Beijing 100190, China)
This paper proposes the unsupervised method based on both speech recognition system and feature-based system to search for the speech patterns. In speech recognition system, the alternative results of the speech recognition system decoder are us ed to search audio patterns with seg mental dynamic time warping alg orithm. Then gr aph clustering alg orithm is used, as well as confi dence estimati on algorithm, to improve the performance of the system. It also proposes the system based on feature only without any knowledge resource. In the final, the performances of the two systems on both radio and television news and spoken dialogue sets are compared. The speech recognition system achieves better performance, and the feature based system can be used on many languages.
speech recognition; speech pattern discovery; segmental dynamic time warping algo rithm; graph clus tering algorithm; phoneme loop calculation of posterior probability
10.3969/j.issn.1000-3428.2014.05.054
1000-3428(2014)05-0262-04
A
TN912.34
國家自然科學基金資助項目(10925419, 90920302, 61072124, 11074275, 11161140319, 91120001, 61271426);國家“863”計劃基金資助項目(2012AA012503);中國科學院重點部署基金資助項目(KGZD-EW-103-2);中國科學院戰略性先導科技專項基金資助項目“面向感知中國的新一代信息技術研究”(XDA06030100, XDA06030500)。
張 震(1984-),男,博士研究生,主研方向:語音識別,關鍵詞檢索;趙慶衛、顏永紅,研究員、博士生導師。
2013-05-02
2013-05-27E-mail:zhangzhen@hccl.ioa.ac.cn
文章編號:1000-3428(2014)05-0266-04
A中圖分類號:TP391
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
