LS-SVM時間序列預測
——免疫文化基因算法進行LS-SVM參數選優
2014-09-12 11:17:14王波梅倩
計算機工程與應用 2014年21期
關鍵詞:模型
王波,梅倩
重慶大學計算機學院,重慶 400030
LS-SVM時間序列預測
——免疫文化基因算法進行LS-SVM參數選優
王波,梅倩
重慶大學計算機學院,重慶 400030
針對最小二乘支持向量機(LS-SVM)在時間序列預測中的參數不確定問題,在訓練階段,使用結合了全局搜索和局部搜索的免疫文化基因算法來進行參數尋優。實驗中通過對Lorenz時間序列和建筑能耗的兩組預測實驗,對比了免疫文化基因算法、遺傳算法和網格搜索算法對LS-SVM參數的優化效果,證明了免疫文化基因算法的優化效果最好,且LS-SVM的預測精度比支持向量機(SVM)和BP網絡預測都要高。
時間序列預測;最小二乘支持向量機;文化基因算法;能耗預測
1 引言
時間序列指存在于自然科學或社會科學中的某一變量或指標的數值或觀測值,按照其出現時間先后次序,以相同的間隔時間排列的一組數值[1]。自從20世紀60年代以來,來自天文、水文、氣象等領域如太陽黑子、徑流量、降雨量等時間序列都被發現含有混沌特性。時間序列預測技術在復雜系統建模、數據流技術和故障診斷等領域都具有較為廣泛的應用,是當前理論研究的熱點之一。
基于傳統統計學的預測方法是利用時間序列之間的相關性來建立線性預測模型,如回歸模型、移動平均模型、自動回歸滑動模型[2]等方法雖然建模機理簡單,建模和預測速度快,適用于對線性、平穩的時間序列建模,但實際應用中采集到的時間序列一般是非線性、非平穩的,所以這些方法建立的線性模型與非線性系統部匹配,導致預測精度下降。而基于上面的線性模型改進的ARIMA模型、自回歸條件異方差模型、廣義自回歸條件異方差模型與小波分解等理論結合的局部建模[3]等方法雖然在一定程度上解決了非線性時間序列的預測問題,但是這些方法的針對性較強,對不同的時間序列未必適用,通用性較差。目前基于人工神經網絡(ANN)的方法也廣泛使用在時間序列預測中,如Elman網絡、回聲狀態網絡[4-5]等,ANN具有較強的非線性逼近能力、自學習能力和并行協同處理信息的能力,在時間序列的預測中精度較高,但其自身也存在參數選擇困難、計算復雜度高、過學習和收斂于局部最小值的現象,當特征空間維數增大時,其運算量將急劇增加,導致ANN難以處理高維問題。
支持向量機(SVM)是Vapnik于1995年首先提出的一種新型的機器學習算法,它解決了以往機器學習方法中小樣本、高維數、局部極小、非線性等問題[6]。SVM采用結構風險最小化準則,將泛化誤差的上界最小化,而不是將訓練誤差最小化,因此泛化能力較強,并且它通過核函數實現了到高維空間的線性映射。SVM模型的這些優點使之成為了時間序列預測領域的研究熱點。
2 LS-SVM簡介
2.1 LS-SVM模型
LS-SVM是SVM的改進算法,用等式約束代替標準支持向量機中的不等式約束條件,極大減少了SVM由于求解二次規劃問題帶來的大量復雜計算。作為一種通用函數逼近器,LS-SVM可以以任意精度逼近非線性系統,它的預測原理介紹如下:

則x時刻輸出模型如式(6)所示:

2.2 模型參數對預測效果影響分析
在訓練LS-SVM模型階段中關鍵問題就是參數的選取,即模型待確定參數C和核參數σ[8]。正則化參數C的主要作用是調節經驗風險和正則化部分的平衡關系,決定對誤差平方項的懲罰力度。C越小對誤差的平方項的懲罰力度越小,對各個點的約束力變小,回歸曲線趨于平坦,回歸機可能出現欠學習現象,導致預測精度下降;C越大則對偏差的懲罰力度越大,LS-SVM構造的回歸曲線會盡力使得各點距回歸曲線的誤差最小,過度要求極小化訓練誤差容易導致訓練過程中產生過學習現象,使預測過程中模型的泛化能力下降。
RBF核函數的函數寬度系數σ控制最終解的復雜性。σ越小誤差容限ξ-帶越敏感,核映射更容易局部化,容易導致訓練的回歸機有過學習現象,導致模型的泛化能力下降;σ越大則誤差容限ξ-帶越不敏感,回歸曲線趨于平坦,這樣可能會導致回歸機的欠學習現象。因此參數的選取會決定模型預測輸出和系統實際輸出之間的誤差大小,直接影響到LS-SVM的泛化能力和預測精度。
文獻[9]通過遺傳算法來進行預測,具有一定的現實意義。但是算法在參數尋優過程中會出現因遺傳優秀個體的破壞而導致優化過程不完全收斂,而且會陷入局部最優。因此本文利用能克服局部最優缺點的免疫文化基因算法進行LS-SVM參數的選優。
3 免疫文化基因算法選擇最優C和σ
文化基因算法[10-13]是一種基于種群的全局搜索和基于個體的局部搜索的混合算法,它引入了局部搜索機制,結合了群體算法搜索范圍大的優點和局部搜索算法的深度優勢。該算法實質上是一種框架,在此框架下采用不同的搜索策略可以形成不同的文化基因算法。針對LS-SVM的參數優化問題,本文采用克隆算法進行全局搜索,用Baldwin學習作為局部搜索策略。
為了避免在優化過程中產生過擬合和欠學習的情況,將初始的含有N個樣本的總訓練樣本集分成兩個子樣本集,用一個子樣本集進行訓練,另一部分子樣本集進行驗證,對于檢驗訓練優化的效果,用驗證樣本的評價絕對誤差(MAE)作為評價依據,因此對MAE取倒數作為個體評價標準:

3.1 危險信號提取
免疫克隆選擇算法是通過種群初始化、克隆、變異、選擇等操作對候選抗體進行進化的一種進化算法。免疫學基本原理認為,對于所有異己抗原,其最優匹配可通過免疫響應進行選擇[14],基于免疫危險理論,將種群濃度的變動作為環境因素,以抗體與抗原的親和力為依據計算各個抗體在該環境因素下的危險信號,最終通過危險信號自適應地引導免疫克隆、變異和選擇等后續免疫應答過程。
定義一種危險信號函數gi如式(9)所示,模擬不同種群下各抗體所處危險信號狀況。該函數以當前種群平均濃度和各抗體—抗原親和力為輸入,產生該抗體所處危險信號值向量[11]。

其中,fit(Ai)為抗體Ai的抗體—抗原親和力的歸一化表示,歸一化可采用各種不同的方式[14];C為抗體種群平均濃度;α和β為調節參數,一方面控制種群濃度和抗體—抗原親和力值對危險信號的影響程度,另一方面使危險信號值gi∈[α,α+β]。可以看出,種群平均濃度越小,抗體多樣性越大,因而在此環境中各抗體所處危險信號相應較大,該危險信號值引導后面的克隆擴增、變異及免疫選擇過程。
3.2 Baldwin效應
Baldwin效應是指如果父代學到某些有用的特性,那么它的后代也有很大的概率獲得同樣的特性[14]。這種免疫系統的增強學習機制,使得抗體親和度進一步提高。使用這種免疫系統的Baldwin效應,通過對最優值閾值附近的個體進行鼓勵來加快進化過程,這些解通過簡單的調整(即學習)就有可能成為較優解。具體而言,把Baldwin效應引入到算法設計中,對親和度值較大的抗體進行一定的鼓勵,提高它的生存率,加快算法的收斂速度。具體方法如下:
假設抗體Ai原來的親和度值為fit(Ai),則學習激勵后的抗體親和度為:

3.3 免疫文化基因算法設計
本文用免疫文化基因算法實現LS-SVM參數優化的流程圖如圖1所示,算法實現步驟如下:
(1)生成初始種群解(候選解集)P,種群大小取100,α和β分別取0.06、0.8,w(Ai)取1.3。使用二進制編碼,每個抗體由參數C和σ的二進制編碼組合而成。
(2)對種群解中的每個個體代入LS-SVM模型,用式(8)進行評價,即每個個體的親和度。
(3)根據式(9)進行危險信號提取操作,獲得各個抗體的危險信號值。
(4)根據每個抗體的親和度值進行克隆擴增操作,克隆數量與抗體的危險信號值成比例,抗體的危險信號值越大,濃度越小,則克隆數量越大,即
(5)選取群體中性能最好的20%的抗體作為精英粒子,采用第3.2節的局部搜索策略對精英抗體進行優化,更新個體和全局極值點。
(6)對克隆種群進行高頻變異,變異概率為Pm=0.5,獲得一個變異后的抗體群C*。設計了一種自適應變異概率,保證算法在進化初期采用較大的變異尺度以保持種群的多樣性,而在進化后期采用較少尺度的變異,以提高局部微調能力。其中,變異概率為,其中t為進化代數。
(7)對C*中所有抗體進行解碼,得到各個優化參數的實際值,用訓練樣本訓練LS-SVM,并根據式(8)對當前個體進行評價,重新選擇親和度高的改進個體產生下一代候選解P。
(8)令進化次數t=t+1,如果t<tmax,則轉到步驟(2)。
(9)輸出最優解,建立LS-SVM預測模型。

圖1 算法流程圖
4 仿真實驗與分析
4.1 混沌時間序列預測
利用Lorenz混沌方程:

其中,a,b和r都是常數,當取a=10,b=8/3,r=28,x(0)=10,y(0)=1及z(0)=0時,系統產生混沌。利用四階Runge-Kutta法迭代產生混沌時間序列,步長為0.02,延遲時間和嵌入維數分別取13和3。生成1 000個Lorenz時間序列數據,如圖2所示,前500個數據用于訓練LSSVM模型,后500個數據用于對訓練好的LS-SVM進行測試。

圖2 Lorenz時間序列
本文選用Matlab R2010a作為實驗仿真平臺,為了檢驗預測效果,用歸一化均方根誤差NRMSE(Normalized Root Mean Square Error)對學習效果和預測結果進行評價,NRMSE的計算如式(12)所示。其中xt為能耗時間序列實際值,為預測值,n為預測的數據個數。
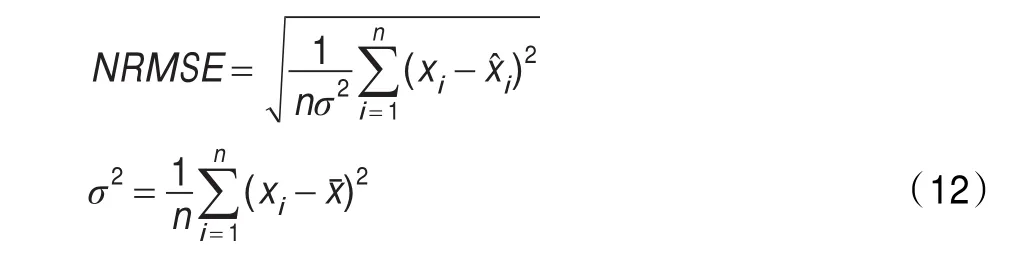
分別采用免疫文化基因、遺傳算法、網格搜索優化的LS-SVM,SVM和BP神經網絡,連續進行500步長單步預測。LS-SVM參數C和σ分別初始化為10和0.1,迭代次數為100。SVM模型的參數C=10,p1=75。BP神經網絡模型的隱藏層節點數設為20,第一層傳遞函數為tansig,輸出層傳遞函數為purelin,迭代1 000次。
從圖2和圖3中可以看出本文方法和傳統LS-SVM分別對Lorenz時間序列的預測情況和誤差對比,表1中對四種預測方法的對比可看出,本文方法由于采用了基于免疫算法全局搜索與基于Baldwin效應局部搜索結合的方法,相比遺傳算法與網格搜索算法0.091 9和0.098 7的測試誤差,能更快速地找到最優解,測試誤差為0.086 5,相比SVM、BP分別為0.121 9、0.315 6的測試誤差,免疫文化基因算法優化的LS-SVM誤差為0.086 5,對時間序列預測更加準確,且沒有因為學習誤差較低而產生過擬合現象。

圖3 Lorenz時間序列預測結果
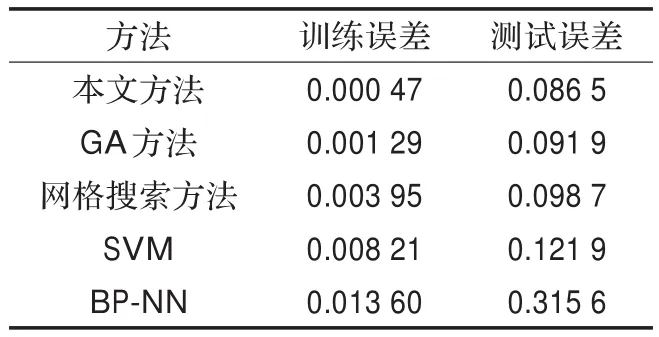
表1 Lorenz預測對比結果
4.2 建筑能耗預測
為了進一步驗證方法的有效性和實用價值,結合建筑能耗值進行預測,文獻[15-16]中已有將SVM、BP神經網絡用于建筑能耗預測的研究,下面實驗中將這幾種算法進行對比。建筑能耗數據如圖4所示。

圖4 建筑能耗數據

圖5 建筑能耗預測結果
對重慶某綜合大樓實行能耗采樣計量,本文選取夏季8月份的能耗數據(見圖5所示),以耗電量作為主要研究對象,每隔1 h對能耗數據采樣一次,預測步長為24,即用前后兩天同一時刻數據作為輸入輸出對。若要預測第di天24 h的能耗數據,則輸入序列為{di-1(1),di-1(2),…,di-1(24)},對應的輸出為{di(1),di(2),…,di(24)}。
預測月末最后一天的能耗情況如圖5所示,可以看出免疫文化基因算法優化的LS-SVM逼近真實值。各種預測方法應用在建筑能耗預測中的對比結果如表2所示。四種方法的測試誤差分別為0.194 3、0.275 1、0.327 1和0.573 6,本文方法比遺傳算法優化LS-SVM、SVM和BP網絡無論在學習精度還是預測精度上都有所提高,更適用于建筑的能耗預測。通過預測得到較精確的能耗值,與實際值的比較,可以實時地監測建筑能耗是否正常,將預測方法嵌入到建筑能耗管理系統中,可以為建筑節能管理提供一種手段。不失一般性,水、燃氣等用量的實時預測也可使用該方法。

表2 能耗預測對比結果
5 結束語
本文在LS-SVM的訓練階段使用了免疫文化基因算法對參數進行了優化,該算法結合了全局搜索與局部搜索,收斂速度快,克服了一般優化算法容易陷入局部最優的缺點,相比遺傳算法和網格搜索算法,本文的算法尋優效率更高。結合建筑能耗預測的實際應用,說明了本文方法具有實用價值,但本文方法訓練預測過程是離線的,下一步的研究就是在本文方法的基礎上設計在線預測方法。
[1]Farmer J D,Sidorowich J J.Predicting chaotic time series[J]. Physical Review Letters,1987,59(8):845-848.
[2]Contreras J,Espinola R,Nogales F J.ARIMA models to predict next-day electricity prices[J].Power Systems,2003,18(3):1014-1020.
[3]謝品杰,譚忠富,尚金成,等.基于小波分析與廣義自回歸條件異方差模型的短期電價預測[J].電網技術,2008,32(16):96-100.
[4]Chandra R,Zhang M.Cooperative coevolution of Elman recurrent neural networks for chaotic time series prediction[J].Neurocomputing,2012,86(1):116-123.
[5]Deihimi A,Showkati H.Application of echo state networks in short-term electric load forecasting[J].Energy,2012,39(1):327-340.
[6]Cortes C,Vapnik V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[7]Ito K,Kunisch K.Karush-Kuhn-Tucker conditions for nonsmooth mathematical programming problems in function spaces[J].SIMA Journal on Control and Optimization,2011,49(5):2133-2154.
[8]Rubio G,Pomares H,Rojas I,et al.A heuristic method for parameter selection in LS-SVM:application to time series prediction[J].International Journal of Forecasting,2011,27(3):725-739.
[9]周輝仁,鄭丕諤,趙春秀.基于遺傳算法的LS-SVM參數選優及其在經濟預測中的應用[J].計算機應用,2007,27(6).
[10]Gong Maoguo,Jiao Licheng,Zhang Lining,et al.Immune secondary response and clonal selection inspired optimizers[J].Progress in Natural Science,2009,19(2):237-253.
[11]劉合安,張群慧.免疫文化基因算法求解多模態函數優化問題[J].計算機應用研究,2012,19(12):4515-4517.
[12]Gong Maoguo,Jiao Licheng,Liu Fang,et al.Memetic computation based on regulation between neural and immune systems:the framework and a case study[J].Science China:Information Sciences,2010,45(11):2131-2138.
[13]張明明,趙曙光,王旭.基于Baldwin效應的自適應有性繁殖遺傳算法及其仿真研究[J].系統仿真學報,2010,22(10):2229-2332.
[14]Matzinger P.The danger model:a renewed sense of self[J]. Science,2002,296(5566):301-305.
[15]DongB,CaoC,LeeSE.Applyingsupportvector machines to predict building energy consumption in tropical region[J].Energy and Buildings,2005,37(5):545-553.
[16]Kalogirou S A,Bojic M.Artificial neural networks for the prediction of the energy consumption of a passive solar building[J].Energy,2000,25(5):479-491.
WANG Bo,MEI Qian
College of Computer Science,Chongqing University,Chongqing 400030,China
Aiming at the problem that the parameters of Least Squares Support Vector Machines(LS-SVM)are uncertain in time series prediction,this paper utilizes immune clonal memetic algorithm which adopts the advantage of global search and local search to optimize the parameters of LS-SVM.Simulation results of Lorenz time sequence prediction and building energy consumption prediction show that the prediction accuracy of this optimization method is higher than genetic algorithm and grid search algorithm,and the comparison shows that the optimized LS-SVM produces better results than Support Vector Machines(SVM)and BP neural network.
time series prediction;Least Squares Support Vector Machines(LS-SVM);memetic algorithm;energy prediction
A
TP391
10.3778/j.issn.1002-8331.1212-0031
WANG Bo,MEI Qian.Time series prediction based on LS-SVM optimized by immune clonal memetic algorithm. Computer Engineering and Applications,2014,50(21):254-258.
王波(1960—),男,副教授,碩導,主要研究方向為建筑與城市智能化、物聯網與網絡安全、信息集成與系統集成;梅倩(1988—),女,碩士研究生,主要研究方向為時間序列預測、支持向量機、神經網絡。E-mail:wangbo@cqu.edu.cn
2012-12-04
2013-01-19
1002-8331(2014)21-0254-05
CNKI出版日期:2013-03-26,http://www.cnki.net/kcms/detail/11.2127.TP.20130326.1042.016.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
