微博中基于增強(qiáng)型倒排索引的特定文檔影響力估計算法
2014-09-15 01:23:30司宏偉
計算機(jī)工程與科學(xué) 2014年3期
關(guān)鍵詞:模型
司宏偉
(國防科學(xué)技術(shù)大學(xué)計算機(jī)學(xué)院,湖南 長沙 410073)
微博中基于增強(qiáng)型倒排索引的特定文檔影響力估計算法
司宏偉
(國防科學(xué)技術(shù)大學(xué)計算機(jī)學(xué)院,湖南 長沙 410073)
微博搜索系統(tǒng)中,將微博帖子根據(jù)搜索相關(guān)性和重要性進(jìn)行排序,并通過列表的方式返回結(jié)果,是目前信息內(nèi)容的主要展示手段。基于向量空間模型的打分函數(shù)被廣泛地應(yīng)用于該類系統(tǒng)中。事實上,微博系統(tǒng)中的帖子重要性打分函數(shù)實際取值并不為用戶所見,文檔的影響力通過排名的方式表現(xiàn)出來。對于一個檢索外的文檔,如何衡量其在信息檢索系統(tǒng)文庫中的影響力?一般搜索引擎或信息檢索系統(tǒng)并不能很好地回答該問題。在微博短文本的基礎(chǔ)上引入了社交影響力這一概念,并通過在文本倒排索引基礎(chǔ)上設(shè)置反向位置標(biāo)記,給出了一種全新的影響力度量指標(biāo),有效地回答了前述問題。理論分析和數(shù)據(jù)實驗驗證了算法的有效性和效率。
信息獲取;倒排索引;TFIDF指標(biāo);索引標(biāo)記
1 引言
隨著信息技術(shù)的快速發(fā)展和互聯(lián)網(wǎng)應(yīng)用的普及,社會各行業(yè)對信息化需求不斷增加,產(chǎn)生了大量的信息內(nèi)容,極大促進(jìn)了信息檢索系統(tǒng)的發(fā)展。特別是近年來,以微博為代表的社交網(wǎng)絡(luò)獲得了快速的發(fā)展,受社交網(wǎng)絡(luò)的推動,信息傳播模式快速朝著去中心化的方向發(fā)展,人類使用互聯(lián)網(wǎng)的方式產(chǎn)生了深刻變革:由簡單信息搜索和網(wǎng)頁瀏覽轉(zhuǎn)向網(wǎng)上社會關(guān)系的構(gòu)建與維護(hù)、基于社會關(guān)系的信息創(chuàng)造、交流和共享。
對于一個特定的信息內(nèi)容,如何快速度量其在微博上的影響力呢?微博中,社會個體通過各種連接關(guān)系在社交網(wǎng)絡(luò)上構(gòu)成“關(guān)系結(jié)構(gòu)”,基于社交網(wǎng)絡(luò)的關(guān)系結(jié)構(gòu),大量網(wǎng)絡(luò)個體圍繞著話題內(nèi)容而聚合,相互影響、作用、依賴,形成具有共同行為特征的“網(wǎng)絡(luò)群體”;各類“網(wǎng)絡(luò)信息”得以快速發(fā)布并傳播擴(kuò)散形成社會化媒體,反饋到現(xiàn)實社會,從而使得社交網(wǎng)絡(luò)與現(xiàn)實社會間形成互動,并對現(xiàn)實世界產(chǎn)生影響。正是因為這個原因,以微博為代表的社交網(wǎng)絡(luò)中,信息內(nèi)容的影響力度量方法應(yīng)該兼顧信息內(nèi)容本身的影響力和社交網(wǎng)絡(luò)對其的放大作用。
傳統(tǒng)信息檢索應(yīng)用中,用戶通過輸入一組關(guān)鍵詞,文檔檢索系統(tǒng)返回一組文檔列表,其中列表中的文檔根據(jù)與查詢(關(guān)鍵詞)的相關(guān)程度進(jìn)行排名。向量空間模型作為一種用于衡量文檔間相關(guān)度的模型,被廣泛地應(yīng)用于該類系統(tǒng)中[1,2]。在該模型中,文檔和針對文檔的查詢都被模型化為由關(guān)鍵詞組成的多維向量空間,而文檔與查詢間的相關(guān)程度可以由文檔向量與關(guān)鍵字向量的夾角來進(jìn)行衡量,從而作為信息檢索系統(tǒng)排列文檔的依據(jù)。作為一種信息檢索系統(tǒng)中的打分函數(shù),向量空間模型有多種變種。公式(1)展示了一種基于余弦相似度的向量空間模型的例子。
relevance(d,q)=cosθ=(d·q)/(|d||q|)
(1)
其中,d表示文檔向量,而q表示關(guān)鍵詞向量。余弦為零表示檢索詞向量垂直于文檔向量,即沒有符合,也就是說該文檔不含此檢索詞。目前這種基于向量空間模型的方法被廣泛應(yīng)用在了各類微博搜索引擎中。具體來說,文檔向量模型表現(xiàn)了微博帖子(文檔,本文用d表示)和查詢關(guān)鍵詞(本文用q表示)之間的關(guān)聯(lián)關(guān)系,關(guān)聯(lián)越緊,打分函數(shù)取值越大,對應(yīng)內(nèi)容排名也就越高,這種排名反映出了文檔的影響力。
在微博中,文檔是通過社交網(wǎng)絡(luò)中節(jié)點間的通道進(jìn)行傳播的,因此節(jié)點間的結(jié)構(gòu)特性極大地影響著內(nèi)容的傳播能力。而在社交網(wǎng)絡(luò)中,文檔通過社交網(wǎng)絡(luò)中的信息通道傳播,直接將上述模型應(yīng)用到社交網(wǎng)絡(luò)中,并不能體現(xiàn)文檔的影響能力。針對這一問題,部分微博類社交網(wǎng)絡(luò)應(yīng)用,例如新浪微博,常利用微博文檔所特有的“轉(zhuǎn)發(fā)數(shù)”來衡量文檔重要與否,即一個文檔獲得轉(zhuǎn)發(fā)越多,這個文檔越重要,其檢索系統(tǒng)將文檔向量模型與轉(zhuǎn)發(fā)數(shù)結(jié)合,綜合計算文檔重要性指標(biāo)。隨著基于社交網(wǎng)絡(luò)和微博營銷等業(yè)務(wù)的快速發(fā)展,微博水軍等快速發(fā)展,使用“轉(zhuǎn)發(fā)量”或“點擊率”的文檔重要性衡量方法的客觀性逐漸獲得質(zhì)疑。針對這一問題,本文給出了一種改進(jìn)的解決方案,我們創(chuàng)新性地將文檔向量模型和基于鏈接的節(jié)點權(quán)威性度量方法,通過一種多準(zhǔn)則約束的排序策略,有機(jī)地結(jié)合在一起。此外,本文提出的方法還在廣告收益估計、新聞輿論影響評估等領(lǐng)域具有重要的作用和廣闊的前景。
本文的主要思想是在充分預(yù)處理數(shù)據(jù)全集的前提下,通過對索引設(shè)置“相關(guān)度反向排名標(biāo)記”,使微博的檢索系統(tǒng)具有快速估計新文檔在不同查詢下排名的能力。基于向量空間模型和倒排索引,設(shè)計中實現(xiàn)了一種新型的索引結(jié)構(gòu),并結(jié)合海量文本管理中數(shù)據(jù)規(guī)模龐大、數(shù)據(jù)更新快等特點,結(jié)合分布式集群化的特點,設(shè)計了一種高速的、可擴(kuò)展的索引更新策略。
2 問題定義
通常意義上講,衡量一篇特定文檔在一個文檔集合中的影響力往往要考慮多種因素,例如文檔的時效性、文檔所表述的觀點態(tài)度、文檔發(fā)表的時機(jī)和場合、社交網(wǎng)絡(luò)對信息的放大效果等。而且對于特定讀者,文檔影響力的衡量具有強(qiáng)烈的主觀性,即每個讀者都會站在自己的角度上,對影響力的認(rèn)識也有著不同的理解。例如,體育類的新聞往往對財經(jīng)類讀者缺乏吸引力。因此,文檔影響力的衡量是一個復(fù)雜的過程,且方法并不具有唯一性。
本文考慮在社交網(wǎng)絡(luò)環(huán)境下,一個特定文檔的影響力應(yīng)至少由兩部分組成,即信息內(nèi)容本身的影響力和社交網(wǎng)絡(luò)中作者的權(quán)威性。
定義1 社交影響力模型:用A(d)表示文檔的影響力度量指標(biāo),它由兩個要素組成,即A(d)=αr(d)+βsi(d),其中r(d)表示文檔d和查詢關(guān)鍵詞的相關(guān)程度,si(d)表示文檔d在社交網(wǎng)絡(luò)中所處的位置節(jié)點的固有影響力,α和β表示加權(quán)因子。
r(d)表示信息內(nèi)容和用戶查詢的關(guān)聯(lián)程度。其意義表示在一般信息檢索系統(tǒng)中,信息內(nèi)容在特定用戶查詢下的打分函數(shù)取值。r(d)的實現(xiàn)并不唯一,本文使用上一節(jié)介紹的向量空間模型實現(xiàn)。si(d)表示文檔d在社交網(wǎng)絡(luò)中的位置權(quán)威性,通過其作者在社交網(wǎng)絡(luò)中的節(jié)點權(quán)威性進(jìn)行度量。在社交網(wǎng)絡(luò)中,基于鏈接的節(jié)點權(quán)威性度量函數(shù)是一種常見的度量節(jié)點社會地位的方法。本文采用了一種類PageRank的節(jié)點權(quán)威性度量函數(shù)。
si(d)=A(u)=
其中,A(u)表示帖子d的博主u的權(quán)威性指標(biāo),M(u)表示u的鄰居集合,表示阻尼因子,L(v)表示貼子的數(shù)量。上述公式表示了一種權(quán)威性傳遞的思想。本文認(rèn)為一個節(jié)點在社交網(wǎng)絡(luò)中的權(quán)威性指標(biāo)取決于其周圍的鄰居,體現(xiàn)了一種信息傳遞和社交的思想。
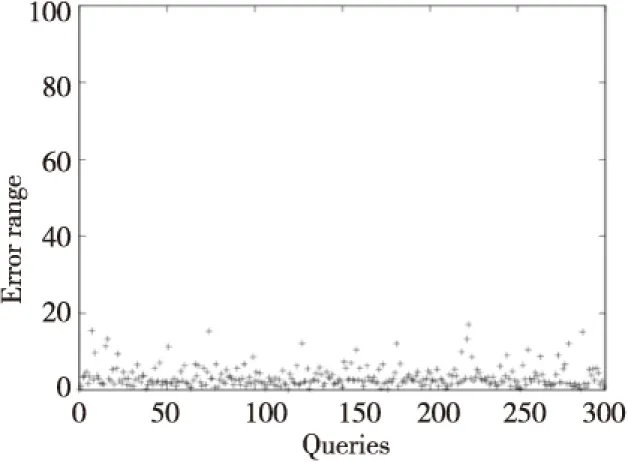
社交影響力模型使用了文檔向量空間模型和基于鏈接的作者權(quán)威性度量函數(shù)取值兩部分的線性組合作為衡量一個文檔影響力的方法。本文中公式(1)的文檔向量空間模型中,cosθ的取值在0~1,由于si是一種概率模型,其取值也在0~1,因此可以簡單推算出,由于A(d)=αr(d)+βsi(d),如果文檔庫中文檔數(shù)量大于1,且社交網(wǎng)絡(luò)中節(jié)點數(shù)量大于1,則必然有0 定義2 基于排名的文檔影響力:給定一個關(guān)鍵字集合K={k1,…,kn}和語料庫C={d1,…,dn},其中,di=〈km,…,kj〉∈D代表一個由關(guān)鍵字序列組成的文檔;給定一個關(guān)鍵詞,在關(guān)鍵詞上的的排名估計查詢函數(shù)表示為RankD:D×K→N,Rank(d,k)=r表示在語料庫C中,有且僅有r-1個d′≠d,使relevance(d′,k)>relevance(d,k),即文檔d在關(guān)鍵字k查詢下在C中的排名。 排名估計查詢返回一個文檔在特定查詢下的排名,需要注意的是,排名是一個全局概念,要獲得文檔d在特定查詢k下的排名,需要通過比較所有其他文檔和k的相關(guān)程度才能獲得結(jié)果;而對海量文本系統(tǒng),其值可能達(dá)到千萬甚至上億的規(guī)模,這樣規(guī)模的比較操作顯然無法滿足大規(guī)模系統(tǒng)的需要。信息檢索系統(tǒng)通常使用倒排索引(Inverted Index),對于內(nèi)容待定的文檔,我們可以將文檔插入語料庫,更新索引,并執(zhí)行查詢來獲得文檔的排名;由于倒排索引可以將相似度比較次數(shù)限定在包含有k的文檔集中,可以有效減少比較次數(shù)。然而,這種操作會對索引產(chǎn)生不必要的更新開銷,特別是對于內(nèi)容待定的文檔,內(nèi)容往往需要多次修改,頻繁更新索引會帶來大量索引碎片,從而影響全系統(tǒng)效率。 如何在不對文檔索引進(jìn)行更新的前提下,估計文檔在特定查詢下的排名,依然是一個具有挑戰(zhàn)性及實際應(yīng)用價值的問題。 3.1 社交網(wǎng)絡(luò)的影響力估計方法 一般來說,國內(nèi)外對社交網(wǎng)絡(luò)信息傳播學(xué)影響的研究主要有經(jīng)濟(jì)學(xué)方法、傳播學(xué)方法和概率論方法等。1992年,紐約大學(xué)的Shenoy P P等人[1]利用經(jīng)濟(jì)學(xué)方法,提出了基于效用評價的信息傳播影響力求解方法,利用一種可替換公式,基于效用評價系統(tǒng)對信息傳播影響力問題進(jìn)行表示和求解。1999年,丹麥奧爾堡大學(xué)的Madsen A L等人[2]提出了一種基于熵的網(wǎng)絡(luò)信息傳播的影響力評估函數(shù)方法,通過在強(qiáng)連接樹中進(jìn)行傳播信息的影響力推理估算。2006年,加拿大西蒙菲莎大學(xué)的McCandless L C等人[3]利用概率論,提出了基于蒙特卡羅的信息傳播計算方法,但是這種類型的影響力分析方法不能有效揭示非線性關(guān)系。同時,研究者還探討了概率結(jié)構(gòu)模型的影響力分析方法,如美國匹斯堡大學(xué)的Wang H等人[4]研究發(fā)現(xiàn),貝葉斯網(wǎng)絡(luò)對于參數(shù)概率的變化非常敏感,并論證了敏感度分析對貝葉斯網(wǎng)絡(luò)參數(shù)分析非常有效,但這些貝葉斯網(wǎng)絡(luò)敏感度分析方法還僅涉及到單個參數(shù);荷蘭烏特勒支大學(xué)的Renooij S等人[5]將貝葉斯網(wǎng)絡(luò)靈敏性分析延伸到多個參數(shù),利用動態(tài)概率結(jié)構(gòu)模型進(jìn)行影響力的敏感度分析等。2006年,法國巴黎大學(xué)的Maes S等人[6]基于多Agent因果概率圖模型給出了一種利用部分信息的影響力分析方法。 本文的目標(biāo)是在已知節(jié)點影響力計算方法的前提下,快速估計未知文檔(新文檔)在文檔庫中的影響力指標(biāo)。上述方法更側(cè)重通過量化分析社交網(wǎng)絡(luò)中節(jié)點的傳播特性來分析節(jié)點的影響力,與本文的需求和定義有較大的差異。 3.2 倒排索引與TFIDF函數(shù) TFIDF(Term Frequency Inverse Document Frequency)是一種常見的向量空間模型的實現(xiàn),是一種統(tǒng)計學(xué)模型,用于衡量一個詞對于語料庫中文檔的重要性,其值與詞在特定文檔中的頻率成正比,與該詞在其他文檔中的頻率呈反比。TFIDF[7~9]函數(shù)由兩部分組成,其中,tf表示詞的詞頻,指的是某一個給定的詞在文檔中出現(xiàn)的頻率;idf表示反向文檔頻率,表示一個詞在一個特定文檔中的重要性,是一個詞在語料庫中普遍重要性的度量,由總文檔數(shù)目除以包含該詞語的文檔的數(shù)目,再對得到的商取對數(shù)。在系統(tǒng)實現(xiàn)中,人們通常結(jié)合TFIDF,使用倒排索引組織文檔索引。倒排索引也常被稱為反向索引、置入檔案或反向檔案。文檔的倒排索引由形如〈t,posting〉的結(jié)構(gòu)組成,每個元組由一個詞語t引導(dǎo),posting中存儲包含這個詞語的文檔列表,即Score(d,t)>0的文檔。為了提高查詢效率,posting中的文檔通常根據(jù)文檔與t的相關(guān)度Score(d,t)進(jìn)行排序。 本文結(jié)合倒排索引中相關(guān)度排序的這個特點,提出了一種增強(qiáng)型的倒排索引方法。 倒排索引的建立過程通常包含幾個步驟:(1)文檔解析。將不同的文檔存儲格式轉(zhuǎn)換為統(tǒng)一的字符串形式。(2)關(guān)鍵詞提取。這個步驟主要完成包括中文分詞、去除停用詞、大小寫轉(zhuǎn)換、時態(tài)還原等操作。(3)建立、存儲倒排索引。將關(guān)鍵詞、文章號、關(guān)鍵詞的出現(xiàn)位置加入到前面所述的倒排索引數(shù)據(jù)結(jié)構(gòu)中,將倒排索引數(shù)據(jù)結(jié)構(gòu)存儲到數(shù)據(jù)庫或文件等持久化設(shè)備中。假設(shè)綜合分析文檔d的全局影響力,需要對任意一個可能獲取到d的查詢,都要進(jìn)行排名。對于已經(jīng)建立了倒排索引的語料庫,本文給出了一種直觀算法。 4.1 簡單算法 對于任意ti∈d,首先計算tfi;之后對于其他文檔dj∈{d|ti∈d},計算tfi,j,并對TF值進(jìn)行排序,從而獲得文檔d在ti下的排名(單關(guān)鍵詞查詢無需計算IDF)。 算法1 簡單算法 輸入:文檔dm,語料庫C; 輸出:影響力向量ri。 變量tfi向量:dm中詞語的TF值向量 1. 預(yù)操作建立倒排索引 2. FOR eachti∈dm 3.tfi=ni,m/∑knk,m; 4. FOR eachdj∈{d|ti∈d} 5.tfi,j=ni,j/∑knk,j; 6. END FOR 7. 計算tfi在tfi,j中的位置 8. 輸出ri 9. END FOR 10.結(jié)束 算法1描述了簡單算法的全過程。要估計文檔d中在其所包含的所有詞語{t|t∈d}上的影響力,該算法需要執(zhí)行∑t:t∈d|{dj|t∈dj}|次tfi,j運算操作,并對每個t∈d,都要進(jìn)行一次規(guī)模為|{dj|ti∈dj}|的排序并插入。對于長文檔在大規(guī)模語料庫中的影響力估計,開銷很大。通常搜索引擎或文檔檢索系統(tǒng)會預(yù)先計算并使用矩陣存儲每個文檔的值,這樣可以達(dá)到使用存儲空間換取效率的目的,并在對倒排索引的posting列表進(jìn)行降序排列時,使用閾值TA(Threshold Algorithms)算法降低排序開銷。即使在這樣的條件下,對文檔在大規(guī)模語料庫中的影響力分析,尤其是對流行詞語的分析,仍然面臨著超長posting列表的問題,依然具有相當(dāng)?shù)奶魬?zhàn),仍然需要占用大量的空間來存儲矩陣,也對索引的有效組織帶來了困難。 4.2 帶有反向位置標(biāo)記的擴(kuò)展索引 本文在一般倒排索引的基礎(chǔ)上,通過添加反向位置標(biāo)記實現(xiàn)了擴(kuò)展索引結(jié)構(gòu),系統(tǒng)體系結(jié)構(gòu)如圖1所示。該擴(kuò)展索引結(jié)構(gòu)具有自更新和自調(diào)整的能力,當(dāng)新文檔到來的時候,擴(kuò)展索引隨倒排索引自動更新,并透明地進(jìn)行自調(diào)整優(yōu)化。當(dāng)用戶進(jìn)行一般關(guān)鍵字查詢,即keyword-posting查詢時,系統(tǒng)通過原倒排索引完成結(jié)果返回;當(dāng)用戶執(zhí)行影響力評估操作時,查詢首先通過擴(kuò)展索引進(jìn)行結(jié)果預(yù)估,之后通過倒排索引進(jìn)行結(jié)果精化。 Figure 1 System architecture圖1 系統(tǒng)體系結(jié)構(gòu) 圖2是本文設(shè)計的擴(kuò)展索引結(jié)構(gòu)。為了使傳統(tǒng)的倒排索引具有能夠快速計算特定文檔序的功能,本文對一般倒排索引進(jìn)行了如下改進(jìn):(1)對倒排索引的每個反向鏈表,均按照對應(yīng)詞語的TF值進(jìn)行降序排列;(2)對于降序排列的0,k,2k,…,nk位置,記錄其對應(yīng)文檔的tfi值mi,n、代表詞語ti的nk位置的tfi值。 Figure 2 Extent inverted index structure(k=3)圖2 k=3的擴(kuò)展倒排索引結(jié)構(gòu) 在實際實現(xiàn)中,我們稱這些位置為反向位置標(biāo)記(Milestone),在本節(jié)描述的索引結(jié)構(gòu)中,該值采用外部分離存儲的方式,無需修改原倒排索引結(jié)構(gòu)。當(dāng)收到新的排名估計查詢d后,對于任意ti∈d,首先計算tfi,并比較與對應(yīng)鏈表中反向位置標(biāo)記mi,n的大小,初步定位。k值的選擇通常與搜索引擎或文本檢索系統(tǒng)中每頁顯示文檔數(shù)量相當(dāng)。這樣僅通過上一步操作,即可直接定位目標(biāo)文檔d在查詢ti下所處的目標(biāo)頁數(shù),對反向位置標(biāo)記使用二分插入方法[7](對于n個元素,二分插入方法的平均比較次數(shù)是logn),比較次數(shù)僅為∑ti:ti∈dlog(|{dj|ti∈dj}|/k)。以k=20,posting平均長度|{dj|ti∈dj}|=1000為例,如僅需定位文檔在檢索系統(tǒng)中出現(xiàn)的頁碼數(shù),比較次數(shù)僅為原來的5%。 算法2 使用擴(kuò)展索引的算法 輸入:文檔dm,語料庫C; 輸出:影響力向量ri。 變量tfi向量:dm中詞語的TF值向量 1. 預(yù)操作建立倒排索引建立擴(kuò)展索引 2. FOR eachti∈dm 3.tfi=ni,m/∑knk,m//n定義參考2.1節(jié); 4. FOR eachmi,n(0≤n≤|{dj|ti∈dj}|/k) 5. IFtfi 6. 計算并輸出ri,Continue; 7. END IF 8. END FOR 9. END FOR 10.結(jié)束 4.3 索引更新策略 當(dāng)語料庫文檔改變時,需要對索引進(jìn)行更新。對于任意一個新文檔dm的插入,會影響到索引中|{t|t∈dm}|個反向鏈表。對于快速更新的語料庫,如何防止頻繁更新帶來的索引碎片和性能下降,也是一個具有挑戰(zhàn)性的問題。在本節(jié)中,我們設(shè)計了一個兼顧更新效率與索引維護(hù)效率的索引更新策略。 更新擴(kuò)展索引策略 反向位置標(biāo)記間維持(k-1)~2(k-1)個元素,當(dāng)新元素到來時,且反向位置標(biāo)記間元素數(shù)量達(dá)到2(k-1)時,創(chuàng)建一個新的標(biāo)記;當(dāng)元素被刪除,且反向位置標(biāo)記間元素數(shù)量少于(k-1)時,則刪除一個標(biāo)記。 圖3所示,當(dāng)一個新的文檔d到來時,需要更新tn引導(dǎo)的反向鏈表且mn,1 Figure 3 Update policy(k=3)圖3 k=3的更新策略 當(dāng)文檔列表進(jìn)行更新時,事實上上述排名估計方法存在一定的誤差。通過計算可以看出,兩個相鄰的位置標(biāo)記之間存在(k-1)~2(k-1)個元素,因此誤差范圍與k相關(guān),也與文檔的排名相關(guān)。也就是說,一個文檔排名越靠后,其可能的誤差范圍也就越大。 我們基于Apache軟件基金會的非結(jié)構(gòu)化信息管理結(jié)構(gòu)UIMA(Unstructured Information Management Architecture)平臺,開發(fā)了銀河博思輿情系統(tǒng),并在其中實現(xiàn)了本文描述的算法。本實驗使用的詳細(xì)配置如表1所示,實驗環(huán)境使用Java語言實現(xiàn),運行于基于Linux內(nèi)核的CentOS平臺上。 Table 1 Running environment of system development 在數(shù)據(jù)集的選擇上,我們挑選了微博文本數(shù)據(jù)集。Weibo2012是我們通過采集新浪微博上的博文構(gòu)造的文本數(shù)據(jù)集。數(shù)據(jù)集的統(tǒng)計資料如表2所示。由于中文文本特殊的語法結(jié)構(gòu),我們使用了中國科學(xué)院計算技術(shù)研究所發(fā)布的中文分詞器ICTCLAS。 Table 2 Corpus configuration 在實驗中,測試了不同k值對擴(kuò)展索引生成和執(zhí)行影響力查詢操作的運行時間。由于三個數(shù)據(jù)集在數(shù)據(jù)規(guī)模上有較大的差異,在建立索引實驗時,使用了兆字節(jié)/秒(MB/s)作為標(biāo)準(zhǔn)單位,出于公平原則,對于中文文檔,在運行時間上沒有計算對中文文本進(jìn)行分詞的時間。通過索引建立時間可以看出,k的取值對索引建立并沒有太大的影響,建立倒排索引的開銷依然支配著運行時間。 Figure 4 Running time圖4 運行時間(k=0表示沒有設(shè)置反向標(biāo)記) 對于查詢效率,采用隨機(jī)生成查詢文檔的方式,為了公平起見,以1 KB個長度為200詞的隨機(jī)文檔作為一個查詢的計時單位測試處理時間。通過圖4可以看出,設(shè)立反向位置標(biāo)記的索引相對于原始的倒排索引,在影響力估計查詢效果方面效率良好,反向位置標(biāo)記效果明顯。 為了驗證文中影響力估計方法的正確性,我們隨機(jī)挑選了300個“查詢-文檔”對,測試了k=10(假設(shè)搜索引擎每頁顯示10條信息)時的誤差率。在對相關(guān)的數(shù)據(jù)進(jìn)行連續(xù)插入更新操作后,計算算法估計排名和實際排名之間的差值。圖5中,橫坐標(biāo)表示“查詢-文檔”,縱坐標(biāo)表示對應(yīng)查詢的誤差率,通過結(jié)果可以看出,本文所提方法的誤差率很低,絕大部分查詢的誤差率在5%左右。 Figure 5 Accuracy analysis圖5 正確率分析 本文給出了一種全新的基于全局排名的影響力指標(biāo),并通過在傳統(tǒng)的倒排索引基礎(chǔ)上設(shè)置反向 位置標(biāo)記,使一般信息檢索系統(tǒng)具有快速估計新文檔影響力的能力。本文創(chuàng)新性地將文檔向量模型和基于鏈接的節(jié)點權(quán)威性度量方法,通過一種排序策略有機(jī)地結(jié)合在一起。本文提出的方法還在廣告收益估計、新聞輿論影響評估等領(lǐng)域具有重要的作用和廣闊的前景。 本文提出的模型當(dāng)前僅針對單個關(guān)鍵字查詢,今后還可以在此基礎(chǔ)上設(shè)計開發(fā)多關(guān)鍵字的文檔影響力估計模型,并結(jié)合惡意排名、垃圾信息檢測等工作開展進(jìn)一步的研究。 [1] Shenoy P P. Valuation_based systems for Bayesian decision analysis[J]. Operations Research, 1992,40(3):63-84. [2] Madsen A L. Lazy propagation:A junction tree inference algorithm based on lazy evaluation[J].Artificial Intelligence, 1999, 113(1-2):203-245. [3] McCandless L C, Gustafson P, Levy A. Bayesian sensitivity analysis for unmeasured confounding in observational studies[J]. Statistics in Medicine, 2006, 26(11):2331-2347. [4] Wang H. Building Bayesian networks: Elicitation, evaluation, and learning[M]. Pittsburgh:University of Pittsburgh, 2004. [5] Renooij S. Efficient sensitivity analysis in hidden Markov models[C]∥Proc of the 5th European Workshop on Probabilistic Graphical Modelsm, 2010:1. [6] Maes S, Philippe L. Multi-agent causal models for dependability analysis[C]∥Proc of the 1st International Conference on Availability, Reliability and Security, 2006:794-798. [7] Salton G, McGill M J. Introduction to modern information retrieval[M]. NY:McGraw-Hill, 1983. [8] Salton G, Fox E A, Wu H. Extended boolean information retrieval[J]. Communicaton of ACM,1983,26(11):1022-1036. [9] Salton G,Buckley C.Term-weighting approaches in automatic text retrieval[J]. Information Processing & Management, 1988,24(5):513-523. SI Hong-wei,born in 1982,MS,his research interest includes computer network security. Estimating the influence of documents:An enhanced inverted index based approach SI Hong-wei Ranking the documents in a list has been extensively used in a lot of search engine systems. In these systems, vector space based ranking models are adopted. Actually, the ranking score of a given document is invisible to search engine users, and the rank position can be regarded as a measure of the influence of a given document. However, for a document outside corpus, how can we measure the influence of it? The question cannot be answered by using ordinary search engines. Social influence is introduced on a real micro-blogging system. Moreover, a large number of milestones are added into inverted indices for the sake of estimating the influence scores. Therefore, above questions can be well answered. The experiments on real data sets verify the effectiveness and efficiency. information retrieval;inverted index;TFIDF;milestone 2012-07-14; 2012-10-12 國家863計劃資助項目(2011AA010702,2012AA01A402);國家自然科學(xué)基金資助項目(91124002);科技支撐計劃課題(2012BAH38B06) 通訊地址:410073 湖南省長沙市國防科學(xué)技術(shù)大學(xué)計算機(jī)學(xué)院 1007-130X(2014)03-0545-06 TP391 A 10.3969/j.issn.1007-130X.2014.03.030 司宏偉(1982-),男,內(nèi)蒙古呼和浩特人,碩士,研究方向為計算機(jī)網(wǎng)絡(luò)安全。E-mail:sihongwei@163.com Address:College of Computer,National University of Defense Technology,Changsha 410073,Hunan,P.R.China3 相關(guān)工作
4 基于位置標(biāo)記的索引
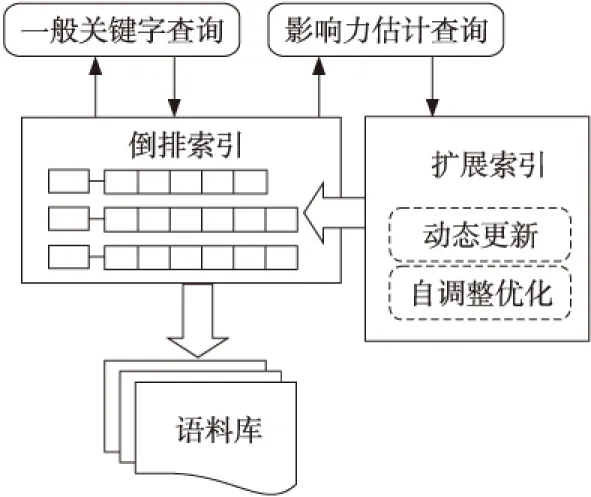

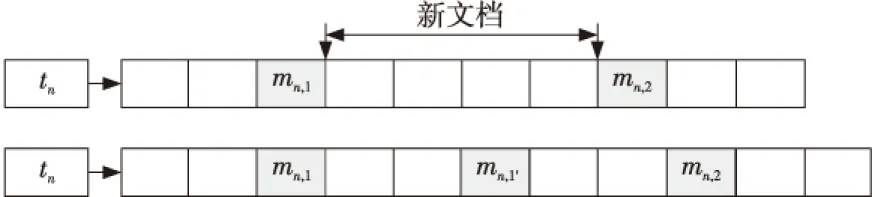
5 實驗

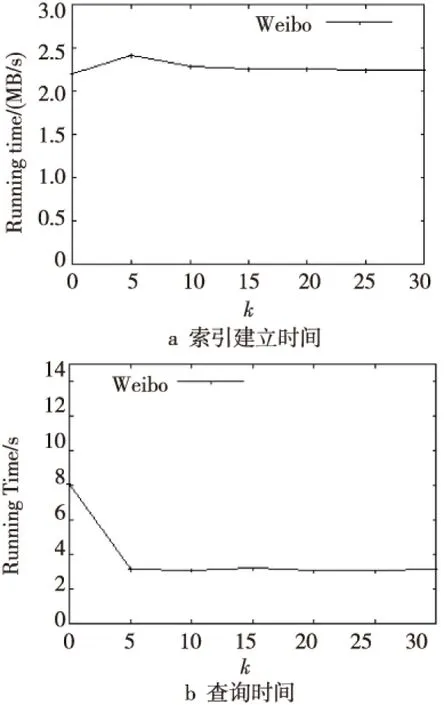
6 結(jié)束語
(College of Computer,National University of Defense Technology,Changsha 410073,China) 猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
