基于網絡社團檢測的電信客戶細分
2014-09-29 10:32:26蔣盛益a吳美玲b楊博泓a
計算機工程 2014年7期
蔣盛益a,吳美玲b,楊博泓a
(廣東外語外貿大學 a.思科信息學院;b.國際工商管理學院,廣州 510006)
1 概述
我國電信業發展迅速,行業發展在獲取客戶資源和提升客戶價值上面臨新的挑戰。電信企業為提高競爭力,必須采用精準的營銷策略,而客戶細分是電信企業有效實施市場策略和客戶關系管理的基礎。傳統的客戶細分大多使用數據挖掘中的聚類方法,根據屬性數據將個體劃分成不同的群體[1-3]。這種劃分方法僅考慮個體的行為特征,而忽略了個體之間的交互關系對行為特征的影響和群體形成。利用電信企業的通話明細記錄可以構造以客戶為節點、以通話關系為邊的電話呼叫網絡,該網絡在一定程度上體現了客戶之間的社交關系,屬于關系數據。通過電話呼叫網絡將客戶細分為不同的群體,電信企業能夠發現不同的客戶關系圈,如親戚圈、同學圈、同事圈等,同時識別關系圈中較大影響力的客戶,為電信企業客戶挽留、精準營銷等提供有效的決策支持,以在激烈的競爭中保持領先優勢。
網絡社團檢測是指將網絡劃分成多個關系緊密對象組成的社團,使得同一社團對象間的關系較緊密,不同社團對象間的關系較稀疏。通過社團檢測,電信企業能夠有效地在電話呼叫網絡中進行群體劃分。近年來,國內外學者針對不同的網絡類型和社團結構提出多種社團檢測方法,文獻[4]給出一種加權網絡的社團檢測方法;文獻[5]提出一種基于隨機漫步模型的節點相似度計算方法,并使用層次聚類算法實現網絡節點的劃分,該方法能檢測不同規模的社團;文獻[6]提出基于模塊度優化的方法,該方法具有較高的時間效率;文獻[7]針對網絡隨時間變化的特性,提出一種基于時間戳的動態網絡社團檢測方法;文獻[8]根據社團間的連接研究網絡的重疊社團檢測問題;文獻[9]從網絡中心點的角度出發,檢測以中心點為核心的社團結構。但現有方法在電話呼叫網絡的應用研究較少。文獻[10]探索了呼叫網絡的基本屬性,但沒對社團結構展開研究。文獻[11]的方法只能尋找較大的社團,但忽略網絡中的小社團,并提到網絡加權方法會影響社團檢測效果。文獻[12]使用基于最大化派系的方法研究呼叫網絡的社團檢測,該方法的效率較低,不適用于大規模網絡。另外,這些研究都沒有結合電信業的特性對社團檢測結果進行分析,因而不能為電信企業提供精確的決策支持。
本文在構造電話呼叫網絡的基礎上,提出使用高效的、適應多分辨率的加權網絡社團檢測算法建立客戶細分模型,并對不同網絡加權方法進行測試。同時,結合客戶通話特征和基本屬性分析社團特征以識別不同的客戶社團類型,并尋找社團內較大影響力的中心客戶。
2 電話呼叫網絡的社團檢測
2.1 網絡加權方法
已有研究中的電話呼叫網絡大多是沒有加權的[10-11]。然而,客戶之間的聯系緊密程度體現在網絡的邊權重上。本文分別使用客戶之間的通話總時長、通話總次數和平均通話時長對邊進行加權,以構造相應的加權網絡,測試并選擇最佳的加權方法。
2.2 網絡社團檢測算法
目前,網絡社團檢測算法包括分割算法、基于模塊度優化算法、譜分析法、信息論方法和動態建模方法。分割算法依賴于邊的分裂標準,對網絡不具有自適應性。基于模塊度的方法建立于隨機圖沒有社團結構的假設,具有一定缺陷。譜分析法將網絡節點映射到多維向量空間中,運用聚類方法將節點聚成社團。信息論方法把網絡模塊化描述看作網絡拓撲結構的有損壓縮,將社團發現問題轉換為尋找拓撲結構的有效壓縮方式,對社團大小及邊密度不一的社團發現問題,性能優于基于模塊度優化算法。動態建模方法中的隨機漫步模型算法使用隨機策略搜索網絡得到拓撲結構信息,具有較高效率,能檢測不同分辨率的社團。
最好的社團發現方法往往與應用場景相關[13]。本文考慮電信數據特點選擇合適的算法:(1)電信業是數據密集型企業,算法應能處理大規模數據;(2)客戶通話緊密程度不同,算法應適用于加權網絡;(3)基于實際的社會結構,客戶形成不同規模的群體,如小規模的親戚圈、大規模的企業圈等,算法應能發現不同規模的社團。
根據上述特性,本文選取隨機漫步模型算法作為網絡劃分方法[5],該算法對于稀疏網絡時間復雜度為O(n2logn)(n和m分別為節點數和邊數),可處理百萬節點的大規模網絡,并適用于加權網絡和發現不同規模的社團。
2.3 隨機漫步模型算法
隨機漫步模型的原則是:若網絡具有很強的社團結構性,則隨機漫步者多數時間停留在社團內部邊上。基于圖的隨機漫步理論計算節點之間、社團之間的距離,再使用層次聚類進行網絡劃分。算法中參數t為漫步步數,通過t步從節點i到 j的概率為。漫步者更可能走向度數大的節點,會受度數d(j)的影響;若節點i和 j屬于同一社團,則i和 j更傾向走到相同的節點集合,即為獲得網絡拓撲信息,t應設置足夠大,同時需控制上限值。下面介紹基于上述隨機漫步特性的距離計算:
定義1節點i和 j的距離為:
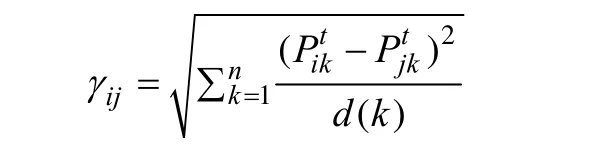
其中,d(k)為節點k的度數。
定義2從社團C到節點 j的概率定義為C中任意一個節點i到 j的概率平均值,即:
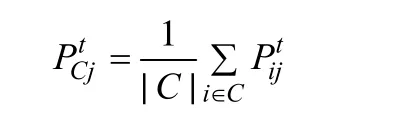
定義3若社團C1和C2至少有一條連邊,則稱C1和C2為鄰接社團,且C1和C2的距離為:
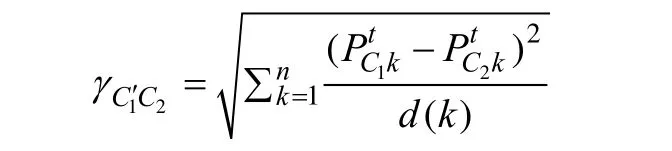
基于距離計算方法,網絡劃分步驟如下:
(1)每個節點作為單獨的社團,初始網絡劃分為P1={{v},v∈V },計算任意鄰接社團的距離。
(2)對于第h次劃分結果Ph,根據:
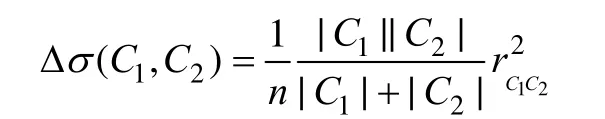
標準選擇使得Δσ最小的2個社團C1和C2進行合并。
(3)更新網絡劃分為Ph+1=(Ph{C1,C2}) ∪{C3},重新計算鄰接社團距離。
(4)重復步驟(2)、步驟(3),n-1次形成網絡劃分序列(Ph)i≤h≤n,使用加權模塊度函數判定(Ph)i≤h≤n中效果最好的網絡劃分。
2.4 社團檢測算法性能評價
社團質量評價方法有2種:(1)使用質量函數;(2)最小化社團模型與實際社團結構的差異。由于很難獲得實際社團結構,因此質量函數是常用的社團質量評價準則。
模塊度成為目前廣泛使用的社團評價方法,其目的是社團內節點連邊盡量多,社團間連邊盡量少。針對加權網絡,文獻[4]提出加權模塊度公式:
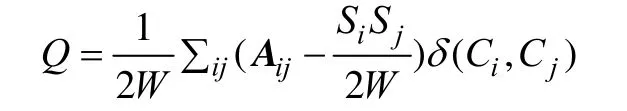
其中,W 為網絡邊權重和;Aij為網絡鄰接矩陣;Si和Sj分別為節點i和 j的連邊權重和;Ci和Cj分別為i和 j所在的社團,當Ci=Cj時 δ(Ci,Cj)=1,否則為0。Q值在[0,1],Q=0.3為網絡有明顯社團結構的下界。
3 實例分析
3.1 實驗數據
本文以電信運營商固話客戶的通話數據為研究對象,共148570條記錄,每條記錄為客戶的一次通話,如表1所示。另一類數據是客戶基本信息,如表2所示。
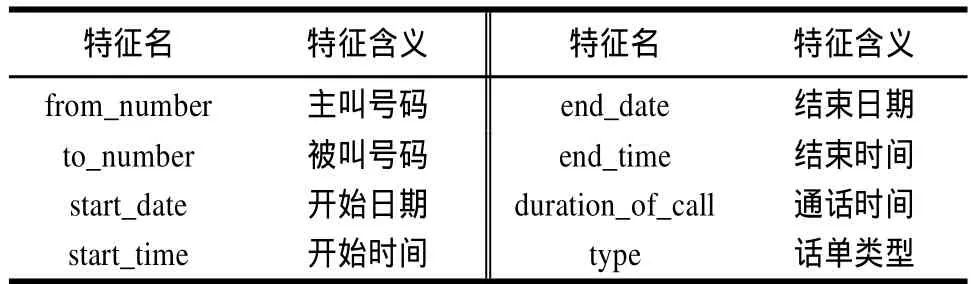
表1 通話明細記錄
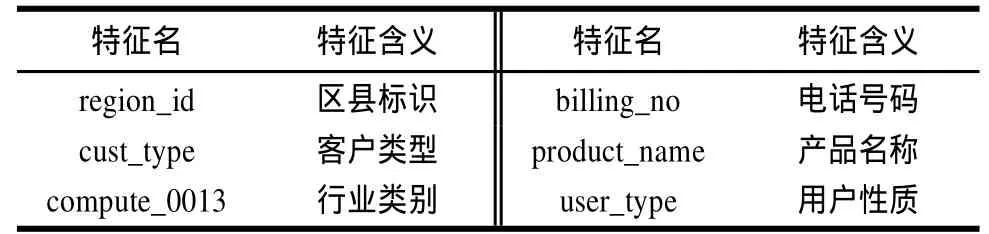
表2 客戶基本信息
3.2 數據預處理
為使挖掘的效率和效果更好,在建模之前需要對數據樣本進行預處理以保證數據質量。采用如下步驟:(1)數據清洗。機器故障導致的噪聲數據,如空值、通話過長的記錄,將其刪除。(2)數據變換。政企客戶打外線號碼時,被叫號碼以9開頭,需還原成原始號碼。(3)樣本選擇。本文實驗的目的是通過運營商內部客戶的社會關系進行客戶群體細分,選取對象是客戶間的市內通話數據。(4)特征構造。為測試加權方法對網絡劃分的影響,需要匯總2個相同客戶的通話記錄,以構造通話次數、通話時長、平均通話時長3個特征。(5)構造電話呼叫網絡。預處理后的數據有59317條記錄,特征包括原始主叫號碼、原始被叫號碼、通話次數、通話時長、平均通話時長。以號碼為節點、呼叫為邊并選取加權方法,構造節點數為23166,邊數為59317的加權網絡,該網絡是密度為0.00022的稀疏網絡。
3.3 實驗結果及分析
在構建加權呼叫網絡的基礎上,本文采用隨機漫步模型算法[5]進行社團檢測。由算法可知,社團結果受漫步步數的影響,步數太小則無法獲取整個網絡結構的特性,步數過大則轉換概率完全由節點度數決定,所以步數的合理選擇是實驗結果的有效保證。另外,社團檢測結果與加權方法密切相關。針對上述問題,測試多種加權網絡在不同步數參數值的劃分效果,并選擇最佳的加權方法和步數,如表3所示,其中,NC為社團個數。
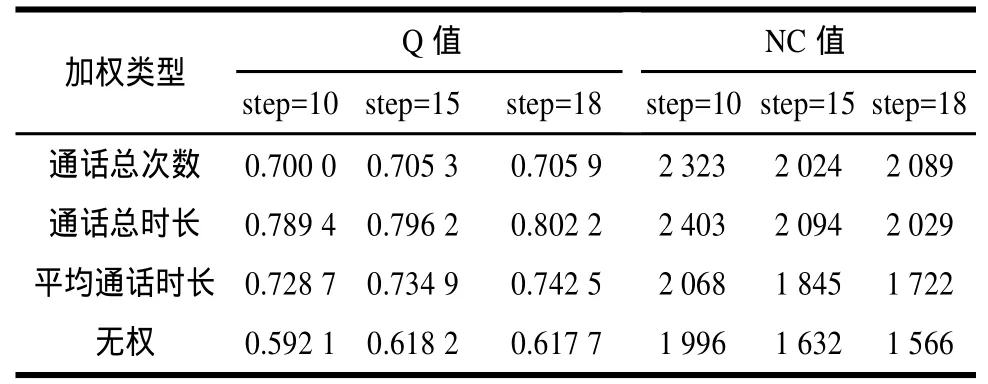
表3 不同加權網絡的社團檢測結果
由表3可知,使用通話總時長的加權網絡劃分效果最好,以此為例測試步數對社團結果的影響。
如圖1所示,步數在15以后Q值較穩定,在18處達到第1個峰值。同時考慮算法時間復雜度隨步數呈指數收斂,因而步數不宜設置太大。本文選取18為算法的步數參數,并使用通話總時長為權重進行網絡社團檢測和結果分析,得到的模塊度值為0.8022,社團個數為2029。社團規模分布如圖2所示,難以對每個社團進行分析。社團規模在10、100、500處的變化率較大,將社團分為4類:小規模社團,中等規模社團,大規模社團和超大規模社團。再通過社團的通話特征分析和客戶屬性分析來驗證社團的類型。
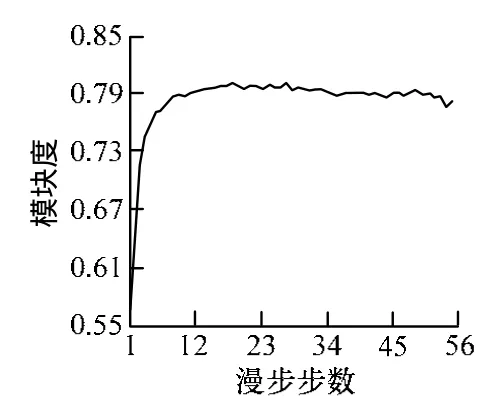
圖1 漫步步數與模塊度相關性
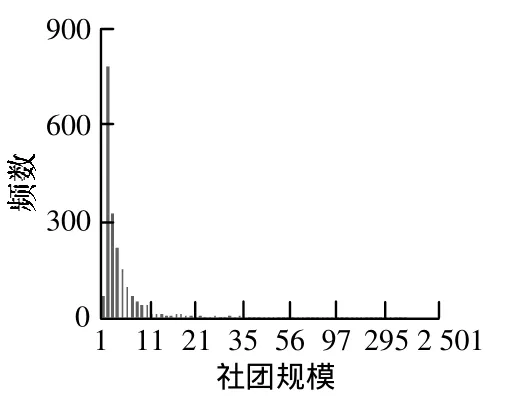
圖2 社團規模分布
3.3.1 社團的通話特征分析
通過社團統計特征和客戶通話特征對社團進行分析,以驗證社團類型,如表4所示。

表4 4種社團類型的統計和通話特征
社團的平均密度公式為:
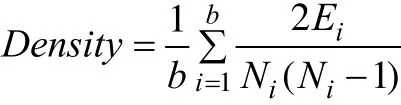
其中,b為每種類型的社團個數;Ni為第i個社團的節點數;Ei為社團內邊數。
由于社團節點數會影響社團內的通話特征,因此在計算社團平均通話特征時需使用規范化公式:
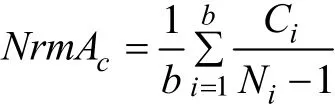
其中,Ci為第i個社團的通話特征。休息工作時段比例為休息時間(12:00-14:00,17:30-8:00)與工作時間(8:00-12:00,14:00-17:30)的通話次數比例。從社團類型分布來看,規模越大社團個數越少,而總客戶數與規模和社團個數相關,同時密度與規模呈正比關系。類型1的社團規模小密度大,規范化平均總時長最大,且休息時段通話也較多,說明客戶之間比較熟悉;類型4的社團規模大密度小,規范化總次數最大,說明客戶聯系范圍廣,且通話主要分布在工作時段,可能為商業關系;類型2和類型3相對來說社團規模和密度處于中間值,該類客戶通話頻率較少但每次通話時間較長,可能是偶爾聯系的朋友群。
3.3.2 社團的客戶屬性分析
不同社團類型的特征具有差異性,因此,需要根據客戶基本信息分析客戶類型的分布和社團形成因素。
本文實驗中家庭客戶、政企客戶和其他客戶的比例分別為:73.10%,16.33%和10.57%;客戶性質以城市私人(75.10%)、辦公用戶(10.73%)為主體;行業類別主要為其他行業(86.03%),少數為住宿和餐飲業(2.41%)、批發和零售業(2.28%)。
4種社團類型在客戶類型、行業類別和客戶性質的分布如表5所示。客戶類型分布中A1~A3代表家庭客戶、政企客戶、其他客戶;行業類別分布中B1~B11代表采礦業、房地產、公共服務業、公共管理、交通運輸、郵政業、金融業、科學教育、批發和零售業、信息傳輸、軟件業、住宿和餐飲業、其他行業;客戶性質分布中C1~C9代表城市辦公、城市私人、公免用戶、經營、局內職工、農村辦公、農村私人、辦公用戶、其他。

表5 4種社團類型的客戶特征
類型1以家庭客戶為主(83.20%),且多為私人用戶(89.28%)。類型4在政企客戶、辦公客戶、住宿和餐飲業、批發和零售業客戶中的比例都高達70%,如圖3所示。
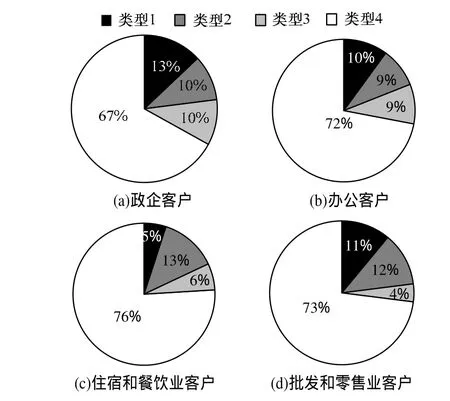
圖3 4種社團類型的客戶比例
從表4、表5和圖3可知,類型1符合親戚圈,類型4符合大企業關系圈,類型2或類型3符合中等規模同學圈。
3.3.3 社團的中心客戶發現
本實驗使用節點中心性方法中的點度中心度測量客戶的中心性,計算公式為:
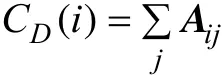
其中,Aij為網絡鄰接矩陣。比較不同網絡節點度通常使用規范化公式:
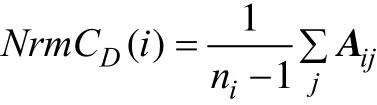
其中,ni為網絡節點數,使用貢獻率表示客戶中心性在社團中的比重,公式為:
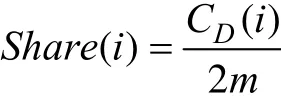
其中,m為網絡總邊數。以其中客戶數為97的社團為例計算客戶中心性。
由于中心客戶的數量與社團規模相關,本文根據社團內客戶中心性分布選取中心客戶數量,如圖4所示,中心性值在11之后比較平穩,因此選擇中心性值大于等于11的為中心客戶,如表6所示。
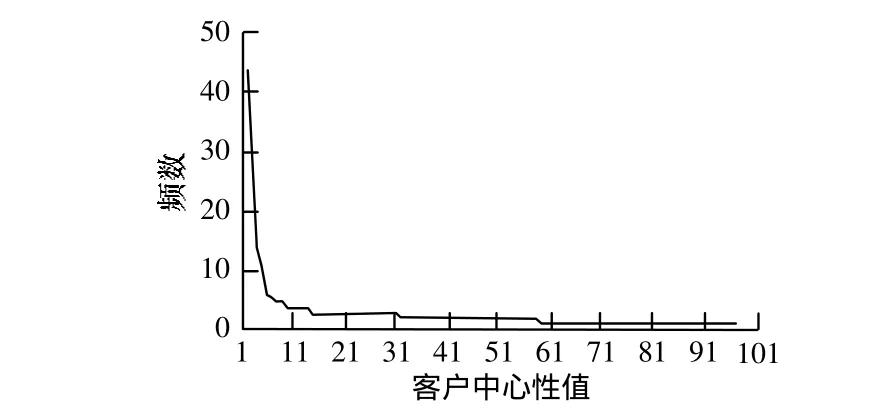
圖4 客戶中心性值分布

表6 中心客戶列表
本文對該社團的交互情況進行可視化,如圖5所示。可見節點中心性較高的為中心客戶(如節點37,32),通話較活躍、社交廣泛,處在網絡圖的中心位置,起領導作用;中心性值中等的客戶(如節點73)通話范圍不廣但有較高信息傳遞能力,起橋梁作用;中心性很小的客戶(如3,24)處在網絡邊緣位置,受社交關系約束很小,為易流失客戶。

圖5 社團可視化
3.3.4 基于社團檢測的電信客戶細分的特點
與傳統客戶細分相比,基于社團檢測的客戶細分具有以下特點:(1)客戶以社交關系形成不同社團,電信企業可針對不同社團實施精準營銷,如向親戚圈推廣親情網語音業務、向大企業關系圈提供語音包月套餐。還可根據不同關系圈的通話時段特征,提供通話價格優惠,如向親戚圈提供晚間通話優惠。(2)在關系圈基礎上識別中心客戶,電信企業可以少量中心客戶為目標進行業務營銷推廣,利用信任機制讓中心客戶自發地通過人際關系向圈內其他客戶進行產品或業務推廣,大大減少企業的營銷成本,提高響應率。(3)電信企業針對客戶社團進行客戶流失預測,替代傳統的個體流失預測,降低管理成本。如一個核心客戶離網,則及時監控該客戶社團中其他客戶的行為并及時挽留。
4 結束語
本文提出使用社團檢測方法進行客戶細分,并測試多種加權網絡的劃分效果。以電信業客戶通話明細數據為研究對象,使用預處理技術整合數據及構建電話呼叫網絡。在呼叫網絡的基礎上,首先以網絡社團檢測為工具,建立基于社交關系的電信客戶細分模型;其次分析社團特征和識別社團的中心客戶;最后對社團進行可視化以清晰地展現客戶交互情況和在社團中的地位。經實例數據與分析表明,該模型可以有效地識別不同關系類型的客戶群,是一種有效的電信客戶細分方法。在模型的基礎上可以準確地描述群體特征,從而為電信企業提供決策依據和技術支持。下一步將對以下2個方面進行研究:(1)結合客戶消費屬性分析社團的消費特性,以提升社團的價值;(2)研究具有時間因素的動態社團檢測算法,跟蹤關系圈的演化。
[1]Li Jinfeng,Wang Kanliang,Xu Lida.Chameleon Based on Clustering Feature Tree and Its Application in Customer Segmentation[J].Annals of Operations Research,2009,168(1):225-245.
[2]Konstantinos T,Antonios C.Data Mining Techniques in CRM:Inside Customer Segmentation[M].[S.l.]:Wiley,2010.
[3]王扶東,馬玉芳.基于數據挖掘的客戶細分方法的研究[J].計算機工程與應用,2011,47(4):215-218.
[4]Newman M E J.Analysis of Weighted Networks[J].Physical Review E,2004,70(5).
[5]Pons P,Latapy M.Computing Communities in Large Networks Using Random Walks[C]//Proc.of the 20th International Conference on Computer and Information Sciences.Berlin,Germany:Springer-Verlag,2005:284-293.
[6]Zhen Zhou,Wang Wei,Wang Liang,et al.Community Detection Based on an Improved Modularity[C]//Proc.of Chinese Conference on Pattern Recognition.Beijing,China:[s.n.],2012:638-645.
[7]Mucha1 P J,Richardson T,Macon K,et al.Community Structure in Time-dependent,Multiscale,and Multiplex Networks[J].Science,2010,382(5980):876-878.
[8]Ahn Y Y,Bagrow J P,Lehmann S.Link Communities Reveal Multiscale Complexity in Networks[J]. Nature,2010,466(7307):761-764.
[9]Chen Qing,Fang Ming.Community Detection Based on Local Central Vertices of Complex Networks[C]//Proc.of International Conference on Machine Learning and Cybernetics.[S.l.]:IEEE Press,2011:920-925.
[10]Nanavati A A,Gurumurthy S,Das G.On the Structural Properties of Massive Telecom Call Graphs:Finding and Implication[C]//Proc. of the 15th ACM International Conference on Information and Knowledge Management.New York,USA:ACM Press,2006:435-444.
[11]Pandit V,Modani N,Mukherjea S,et al.Extract Dense Communities from Telecom Call Graphs[C]//Proc.of the 3rd International Conference on Communication Systems Software and Middleware.[S.l.]:IEEE Press,2008:82-89.
[12]Wu Bin,Ye Qi,Yang Shengqi,et al.Group CRM:A New Telecom CRM Frameworkfrom Social Network Perspective[C]//Proc.of the 1st ACM International Workshop on Complex Networks Meet Information and Knowledge Management.New York,USA:ACM Press,2009:3-10.
[13]黃發良.信息網絡的社區發現及其應用研究[J].復雜系統與復雜性科學,2010,7(1):64-74.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
