Hadoop在客票日志處理系統中的應用
2014-10-10 07:28:24戴琳琳閻志遠梅巧玲
鐵路計算機應用 2014年5期
關鍵詞:系統
苗 凡,戴琳琳,閻志遠,梅巧玲
(中國鐵道科學研究院 電子計算技術研究所,北京 100081)
Hadoop在客票日志處理系統中的應用
苗 凡,戴琳琳,閻志遠,梅巧玲
(中國鐵道科學研究院 電子計算技術研究所,北京 100081)
借助Hadoop技術提出了一種新的架構,用于處理客票系統中產生的海量交易日志。首先將多個業務的數據收集起來并以一定的格式存儲在hase與hive中,然后對平臺中的數據進行建模分析從中提取出有價值的關鍵業務信息。目前該系統已經開發完成,切實提高了客票系統維護與運營的水平和效率。
Hadoop;大數據;客票系統;日志處理系統
鐵路客票發售與預訂系統(簡稱客票系統)經過十余年的發展已實現了全國聯網售票,目前互聯網注冊用戶達7 000多萬,每天用戶的登錄量達數百萬,產生的交易日志達數百Gbyte,這非常有益于聚合數據,用于了解旅客如何使用系統,同時還可以用于解決系統出現的異常問題。比如旅客無法購票或無法取票,開發人員可以根據相關日志發現問題并進行調試。為了使開發與維護人員快速的發現問題,系統中的原始日志至關重要。
由于交易日志的數據量巨大,常規的數據庫已遠遠不能在本文可以接受的時間內給出想要的結果,而且受制于傳統單機有限的計算機能力和存儲能力,所以本文選擇基于分布式計算的系統,利用其開放的接口進行日志的信息處理。Apache下的開源框架Hadoop是一個容易開發和并行處理大規模數據的分布式計算平臺,同時并行計算中存在的問題如分布式存儲、負載均衡、容錯處理、工作調試、網絡通信等也都由Hadoop負責。本文將簡單介紹Hadoop,包括HDFS和Mapreduce的組成與工作原理,并設計一種基于Hadoop的日志分析系統。
1 Hadoop相關技術
1.1 HDFS
HDFS是一個可擴展的分布式文件系統,與其它文件系統相比它同樣提供文件的重命名、移動、創建、刪除等操作,還具有文件的備份、數據校驗等特殊功能。一個HDFS集群包含一個主服務器(nameNode)和多個塊服務器(dataNode),內部機制是將一個文件分割成一個或多個固定大小的塊(block),每個塊在被創建的時候,服務器會分配給它一個全球唯一的64 bit句柄進行標識,dataNode把塊作為linux文件保存在本地硬盤上,并根據指定的塊句柄和字節范圍來讀寫塊數據。為了保證可靠性,每個塊都會復制到多個dataNode上,缺省情況下,會保存3個備份。nameNode管理文件系統所有的元數據,包括命名空間、訪問控制信息、文件到塊的映射信息以及塊當前所在的位置。
1.2 Mapreduce
對于大數據量的計算,通常采用的處理手法就是并行計算,但現階段并行計算對許多開發人員來說還比較復雜。Hadoop Mapreduce是一種處理海量數據的并行編程模型,用于大規模數據的計算,使開發者在實現中不用考慮太多分布式相關的操作,只需要定義需要的map和reduce操作即可,極大的簡化了分布式編程。
2 系統架構
日志分析系統是一個完整的信息系統,它的架構由上到下依次為表現層、服務層、資源層和總線層。表現層常用的構架有Web/Restful,它們是數據的外在表現形式。服務層通過制定一系列業務規則來保證數據的合法性。資源層為系統的核心,所有交易日志的數據都存放在hbase/hive中,它通過jdbc的方式與服務層進行通信。總線層直接與各業務子系統進行通信,通過它們之間的標準接口來收集各模塊的原始日志信息,從圖1中可以看到各層之間相互依賴,相互關聯構成統一整體。
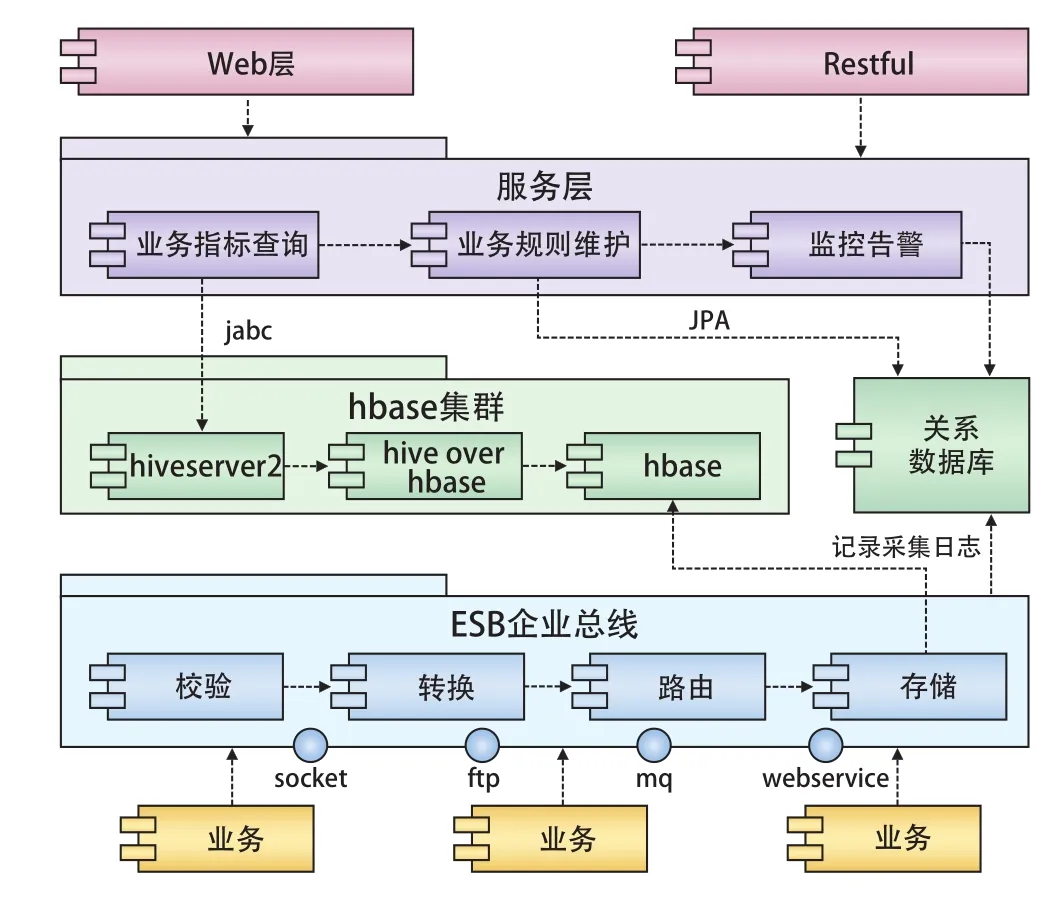
圖1 系統架構
2.1 日志收集
客票系統由許多業務子系統組成,每個子系統所產生的日志格式都不同。并且每個子系統每天產生的日志量非常大,僅INETIS原始日志一天大約為30 Gbyte,為了將所有日志存儲在一個共有的集群中,首先要在每個業務系統上安裝日志收集服務程序,各個程序都通過ESB服務總線進行交互,某個給定的服務既可以是提供者,也可以是請求者或者同時兼具2個角色。ESB提供4種標準接口與日志收集服務端進行通信,分別是SOCKET,MQ,WEBSERVICE與FTP。
使用基本的Python模塊可以編寫腳本與ESP總線交互。Python 2.x編寫的日志收集程序由2個功能塊組成:(1)通過re模塊的正規表達式去匹配原始日志,findall()可以取得所有感興趣的字段并過濾掉多余的信息,再將所得的內容一起寫入文件。(2)利用zipfile模塊對原始內容進行壓縮,大約可以節省90 %磁盤空間。由于客票主要業務都在白天進行,因此最好將這些腳本以定時任務方式掛到服務器上,再通過標準接口發到ESP企業總線上。
由系統架構圖可以看到,通過標準接口發到ESP總線上的消息,需要通過加密或包封轉換為提供者模式,再通過添加來自外部數據源的信息來增加消息的有效負載。更改消息的路由,可從支持請求者意圖的服務提供者中選擇。
2.2 日志存儲
系統中的Hadoop集群包括16個數據節點,共50 Tbyte的存儲空間。系統設計給需要保存半年的文件設置副本因子為3,其他文件設置副本因子為2。
Hadoop集群中的NameNode與DataNode使用完全相同的硬件,為了防止NameNode的單點故障,集群使用2臺單獨的機器配置NameNode,在任何時間點確保只有一臺處于active狀態,另一臺處于standby狀態,2個節點訪問同一個共享存儲設備,當active節點出現故障時,另一個能夠實現快速切換。
由于全天的日志數據量非常大,不可能統一收集到一臺服務器再一起導入,必須實時收集分散導入。而且由于Hadoop對于壓縮文件的導入效率不理想,系統會將原始格式分發到各個日志收集服務器,以分散計算提高整體的導入效率。在各個日志收集服務器上有一層負載均衡,以分散網絡I/O流量提高效率。日志存儲采用多進程同時導入,系統會對導入過程進行相關監控,包括日志信息是否導入成功以及導入出錯的報警與恢復等。
2.3 日志處理
系統通過瀏覽器來展現圖形化的數據。(1)用戶依據不同的需求分析制定不同的業務規則。用戶制定完規則后通過瀏覽器提交日志處理任務,此時MapReduce作業的2個階段及其InputFormat和OutputFormat一起形成了一個階段事件驅動架構(SEDA)模型,在這個模型中一個請求將會分割成很多小的任務單元,并查詢節點空閑列表。(2)將任務單元分派給集群中空閑的計算節點。計算節點根據任務單元中的數據源信息從數據存儲節點中獲取數據,并進行相應的計算工作。(3)將結果返回到任務調度節點進行匯總,由任務調度節點將最終結果返回給用戶。所有計算節點每隔一段時間要向JobTracker發送一個心跳信號,以證明該計算節點工作正常及是否處于空閑狀態。主節點JobTracker也要實時將計算節點的壯態返回給任務調度節點。
以ctms日志為例,制定合適的業務規則,將不必要的內容進行過濾,對關心的內容進行重新設計數據結構。原始的日志信息如下:

首先要處理的是日志數據的分隔符問題,hive的inputformat負責把輸入數據進行格式化,然后提供給hive,outputformat,負責把hive輸出的數據重新格式化成目標格式再輸出到文件,因此需要根據自己的需求重寫這2個方法,處理完后的內容大致如下:

現在可對幾個月的日志進行分析,如可統計每個請求響應時間的最大值、最小值和平均值,統計每個中心的訪問量并按訪問量進行排序,統計每秒訪問的tps,按訪問量降序排序并把結果輸出到表中等。hive提供的類sql語句對這些數據進行自動化管理和處理,系統管理員只需要定制自己的輸入輸出適配器,hive將透明化存儲和處理這些數據,使復雜工作簡化。
3 結束語
本文在客票系統中使用Hadoop進行日志處理,將某些業務的交易日志以一定的數據格式存儲于Hadoop中,并對關鍵業務數據進行監控,如:能根據某幾個字段查找出符合條件的交易日志,能根據某幾個字段的值分析系統當前的運行狀況等。后期還可以利用提取到的數據分析用戶行為,對用戶的歷史數據利用相關的技術進行建模分析,并對其再次瀏覽目的進行預測,同時投放相應的廣告。如何從幾百億的數據中獲取關鍵的業務數據,如何從這些數據中找出有價值的信息,將是后續研究的重點。
[1]朱建生,周亮瑾,單杏花,王明哲.新一代客票系統總體架構研究[J].鐵路計算機應用,2012(6):1-6.
[2]朱 珠.基于Hadoop的海量數據處理模型研究和應用[D].北京:北京郵電大學,2008.
責任編輯 方 圓
Application of Hadoop in Log Processing System of Ticketing and Reservation System
MIAO Fan, DAI Linlin, YAN Zhiyuan, MEI Qiaoling
( Institute of Computing Technologies, China Academy of Railway Sciences, Beijing 100081, China )
This paper, with the aid of Hadoop technologies, proposed a new architecture according to the transaction log which produced in Ticketing and Reservation System (TRS). First business data was modeled and saved in hase and hive with speci fi c format, then the interested key business information was extracted by designed business rules. At present, the System has been developed, the level and ef fi ciency of maintenance and operation were improved.
Hadoop; big data; Ticketing and Reservation System (TRS); Log Processing System
U293.22∶TP39
A
1005-8451(2014)05-0032-03
2013-12-02
苗 凡,研究實習員;戴琳琳,助理研究員 。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
