一種基于蜂群算法的數據庫知識發現過程的研究
2014-10-11 11:22:34黎華
湖南師范大學自然科學學報 2014年2期
黎 華
(西昌學院電子工程系,中國四川 615000)
數據挖掘(data mining)是當前數據庫研究領域一個的重要方向.數據挖掘主要是指利用各種分析方法和技術,對以往累積的大量復雜的數據進行分析、歸納和整合,從而在大量數據中發掘出有用的信息,為相應的決策提供依據.
所以借助數據挖掘技術,企業完全有能力從浩瀚的數據海洋中,挖掘出全面而又有價值的信息和知識,并作為決策支持之用,進而形成企業獨有的競爭優勢.
1 CRISP-DM模型
CRISP-DM模型是由歐盟幾家在數據挖掘應用上有豐富經驗的公司共同籌劃提出來的,CRISP-DM模型主要強調完整的數據挖掘過程,不是只針對數據整理、數據顯示、數據分析和模型的構建,而是將對企業的需求問題的理解和后期對模型的評價和模型的延伸應用都應用于數據挖掘中[1-2].

圖1 CRISP-DM模型Fig.1 CRISP-DM model
因此,CRISP-DM模型強調實施數據挖掘項目的方法和步驟,同時該模型獨立于每種具體數據挖掘算法和數據挖掘系統之外.
2 蜂群算法
2.1 基本原理
自然界中,蜂群實現采蜜的集體智能行為主要包括3個主要部分,分別為蜜源、采蜜蜂EF、待工蜂UF.另外,在此基礎上又引入3種行為模式,分別為搜索蜜源、為蜜源招募以及放棄蜜源[3-4].
蜂群采蜜的流程圖如圖2所示.
假設目前有2個已經被發現的食物源A和B,起初,待工蜂沒有獲得任何食物源的信息,那么它有兩個可能的選擇:
(1)待工蜂作為偵察蜂,由于外在因素或激勵因素的存在,其會自動搜尋蜂巢附近的食物源(圖中‘S’線).
(2)當待工蜂發現其他蜜蜂之后,其被招募,按照自身獲取的信息搜尋食物源(圖中‘R’線).
當待工蜂找到新的食物源的時候,蜜蜂可以記住并獲取食物源所在的位置,與此同時實現采蜜工作.
因此,這時待工蜂成為采蜜蜂,等到蜜蜂采蜜回到蜂箱,此時將采到的蜜吐到空的蜂房之后,其有下面幾個選擇:
a)拋棄食物源,變成待工蜂的跟隨蜂;
b)返回同一食物源之前,通過跳搖擺舞實現蜂群的招募;
c)繼續采蜜,不招募其他蜂群.
初始時,所有蜜蜂都是偵察蜂,等到它們隨機搜索到食物源后,偵察蜂重新回到蜂巢的舞蹈區.依據食物源的收益度的大小,偵察蜂可以變成任何一種蜜蜂.
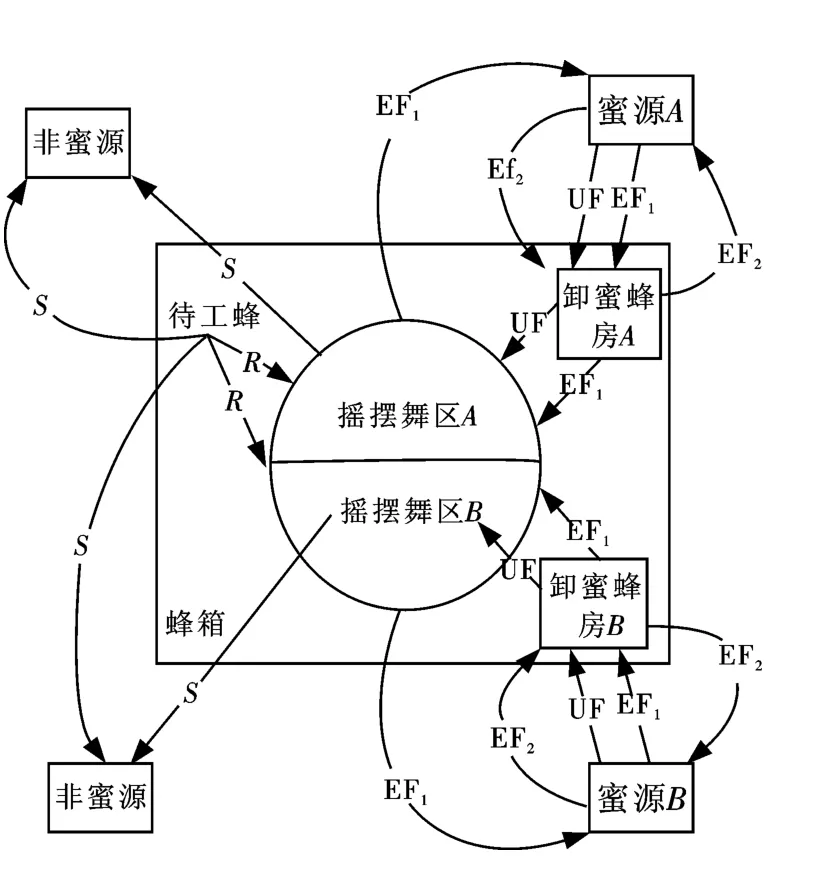
圖2 蜜蜂采蜜工作圖Fig.2 Working drawing of honey bees
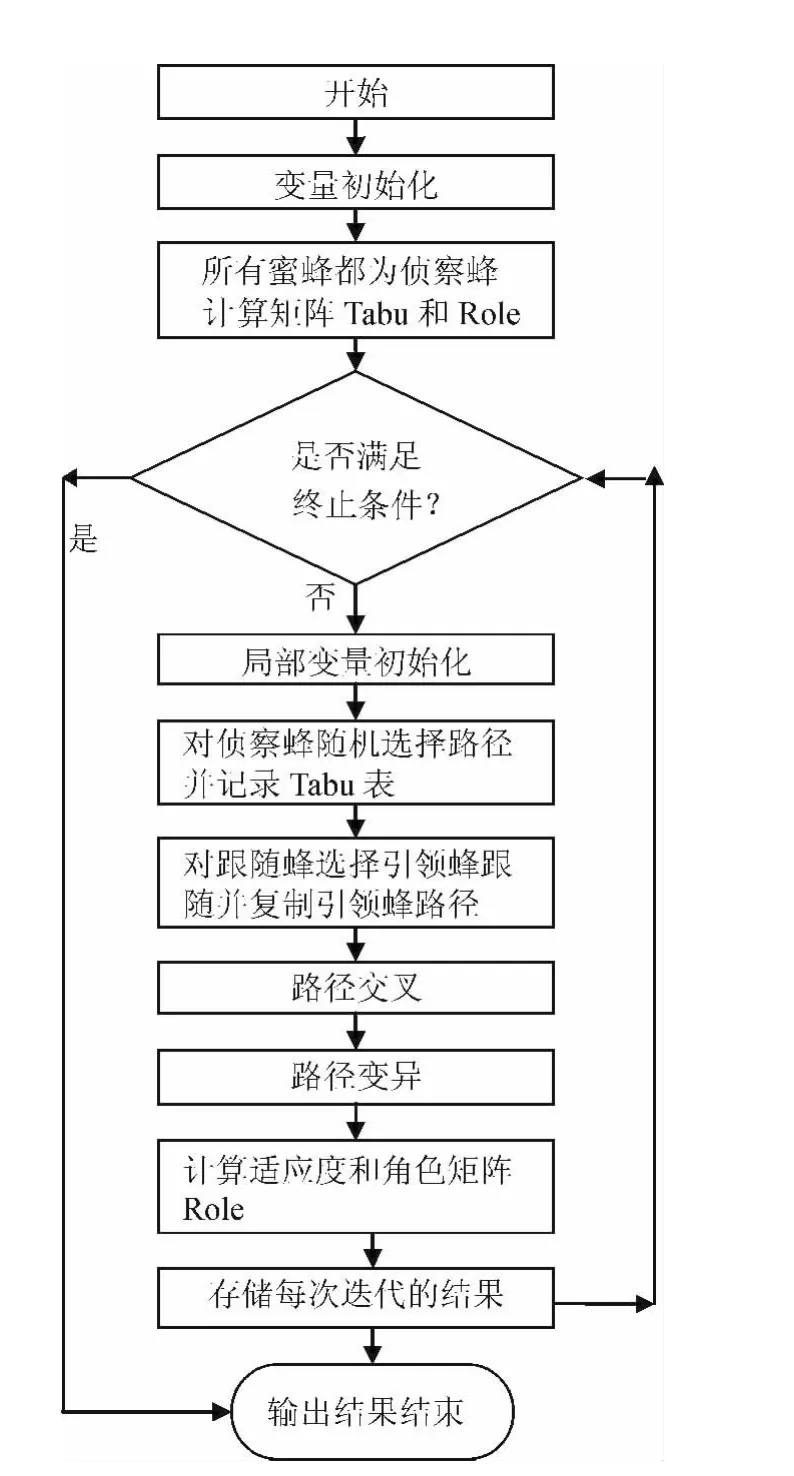
圖3 蜂群算法流程圖Fig.3 Flowchart of bee colony algorithm
2.2 要素組成
依據蜂群算法的原理介紹,蜂群算法主要有以下3個基本要素構成:
(1)食物源.食物源表示各種可能的解;食物源值由多種因素決定的,比如食物源和蜂巢的距離、能量的大小和集中程度等.
(2)采蜜蜂EF.采蜜蜂是和食物源有聯系的,采蜜蜂擁有采集到的具體的食物源信息,信息主要有食物源和蜂巢的距離、食物源方向以及食物源的收益度;
(3)待工蜂UF.待采蜜蜂尋找食物源,主要分為偵察蜂和跟隨蜂;偵察蜂負責找尋蜂巢附近的新食物源;而跟隨蜂在蜂巢內等待,通過分享到的采蜜蜂的信息,實現食物源的尋找[4].
算法流程如圖3所示.
3 基于蜂群算法的數據庫知識發現模型
參考CRISP-DM模型和數據庫知識發現的多處理階段模型[5],本文提出將信任分配學習機制和基于蜂群算法的規則發現機制有機地結合在一起的基于蜂群算法的數據庫知識發現系統模型,其特點是系統采用概率轉換規則,使用并行的規則觸發機制,是一種自適應的學習系統.
基于蜂群算法的數據庫知識發現模型基本結構如圖4所示.
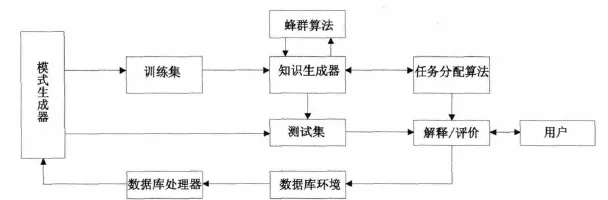
圖4 基于蜂群算法的數據庫發現模型Fig.4 Model of database discovery based on bee colony algorithm
客觀數據庫環境信息通過數據處理器將完整的數據信息發往模式生成器,模式生成器根據指定的數據挖掘任務,從數據信息中提取相關的模式并將這些模式劃分為訓練數據集以及測試數據集[6].被觸發的知識生成器通過設計的蜂群算法與訓練集交互的學習,將滿意的學習結果提供給測試集,測試集將評測結果交給解釋評價價機構,通過解釋/評價機構將知識提交給用戶并作用于數據庫環境,同時更具評測結果和用戶需求,修改信任分配算法,以希望下次能得到更好的結果[7].
4 仿真實驗
數據挖掘算法的任務是對海量數據庫進行挖掘,對于只有如此少的記錄數據庫的效果不能說明問題.作者又選擇了機器學習研究通常使用的Cleve心臟病例比較實驗數據庫進較實驗.訓練數據為200個,測試數據為103個.
4.1 Cleve原始數據的處理
(1)C leve原始數據含有部分數據屬性值的缺失,首先補足缺失數據.
(2)對于 Age,Trestbps,Cholesterol,Fasting blood sugar,Max heart rate,Old peak 和 Number of vessels colored的連續屬性進行離散化為:
Age:>47.5;<47.5 兩類
Trestbps,Cholestrol對其劃分的邊界計算信息嫡,其信息消值都不足以對分類進行有效劃分,因此這兩個屬性對分類的劃分不起任何作用,因而從屬性列表中刪去.
Fasting blood sugar:>120;<120兩類;
Max heart rate:> 147.5;< 147.5 兩類;
Old peak:> 1.7;< 1.7 兩類 ;
Number of vessels colored:> 0.5;< 0.5兩類:
由于離散屬性的屬性值均較少(2~4個),無需對其縮減.
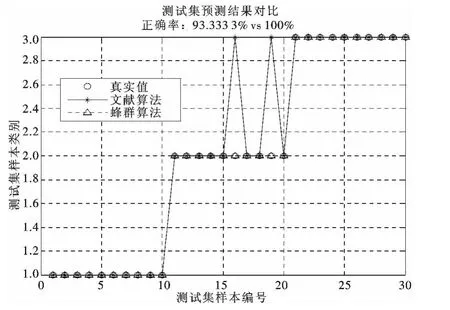
圖5 測試結果對比Fig.5 Comparsion chart of test results
4.2 實驗結果
為了進一步驗證蜂群算法進行數據庫知識發現的優越性和準確性,將其同文獻[8]算法進行對比,主要從訓練準確率、測試準確率和運行時間3個方面進行驗證,運用仿真進行仿真,仿真結果分別如圖5~圖7.
從圖5中可以看出,蜂群算法的準確率達到100%,而文獻中的算法的準確率只達到93.333 3%.從圖6中可以看出,蜂群算法的準確率普遍高于文獻算法的準確率.從圖7中可以看出,蜂群算法的運行時間也優于文獻算法.
通過算例的測試,發現蜂群算法有很好的尋優能力,求解速度也快.下面重點研究蜂群算法的不用參數對尋優結果的影響.
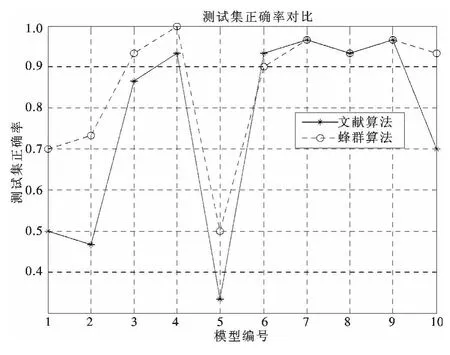
圖6 測試結果正確率對比圖Fig.6 Comparison chart of correct rate of testing result
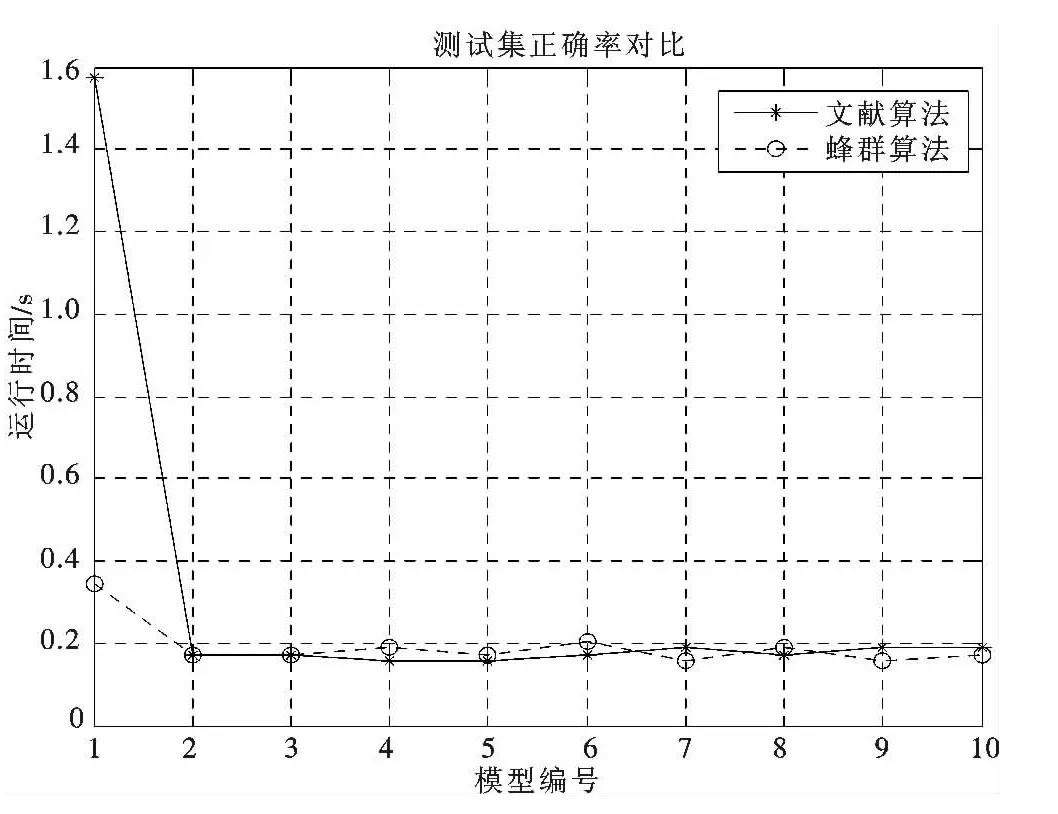
圖7 算法時間對比圖Fig.7 Comparison chart of algorithm time
5 不同種群大小對蜂群算法性能的影響
5.1 不同種群大小對收斂性的影響
分別分析種群數為15,30,45時,種群大小對蜂群算法性能的影響.
通過圖8(a)、(b)、(c)3圖的對比,發現種群越大,蜂群算法收斂性越快,更容易逼近最優值.
5.2 不同迭代次數對蜂群算法性能的影響
分析迭代次數為100,200,300時,迭代次數對GA算法性能的影響.
通過圖9(a)、(b)、(c)3圖的對比發現,隨著迭代次數的增加,蜂群算法求解問題的收斂性不斷增加,能更快地逼近最優值.
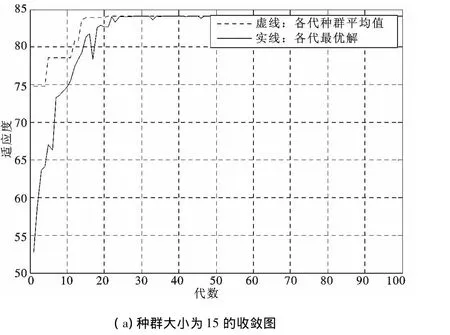
圖8 蜂群大小對收斂結果的影響Fig.8 Colony size effects on convergence results
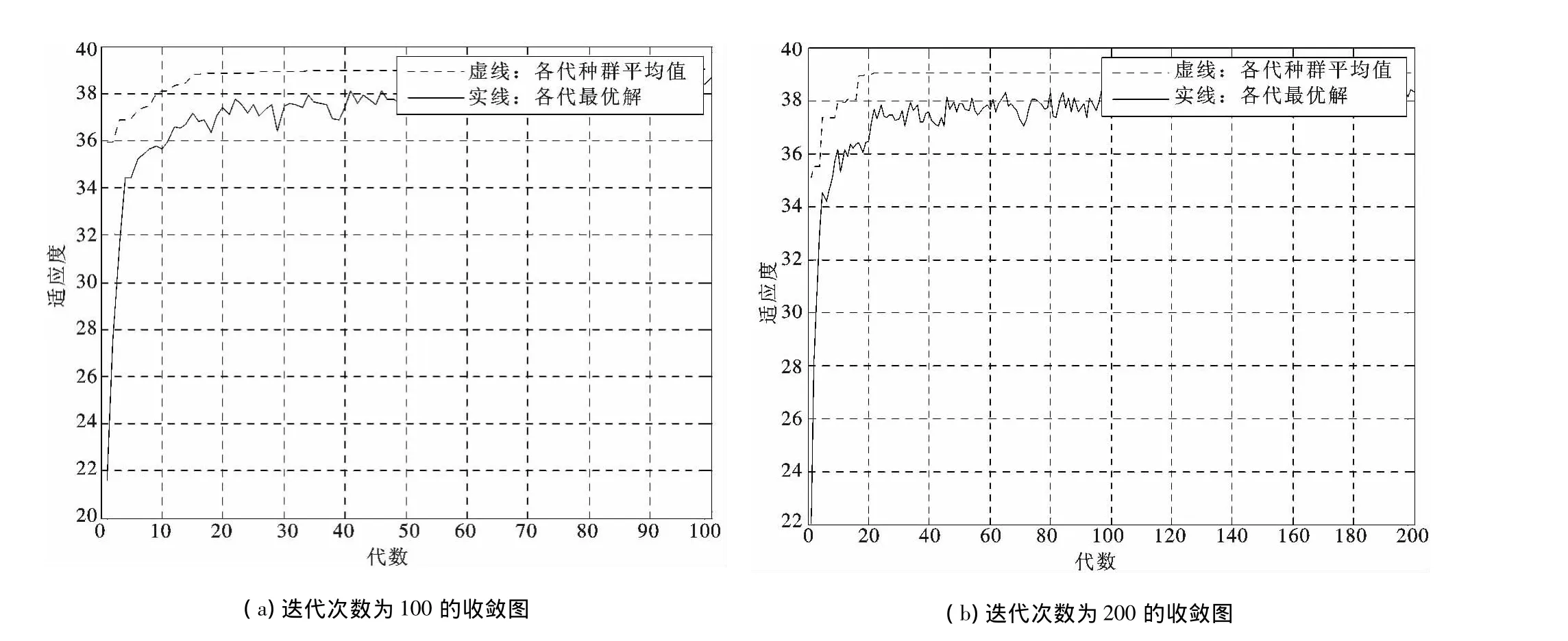
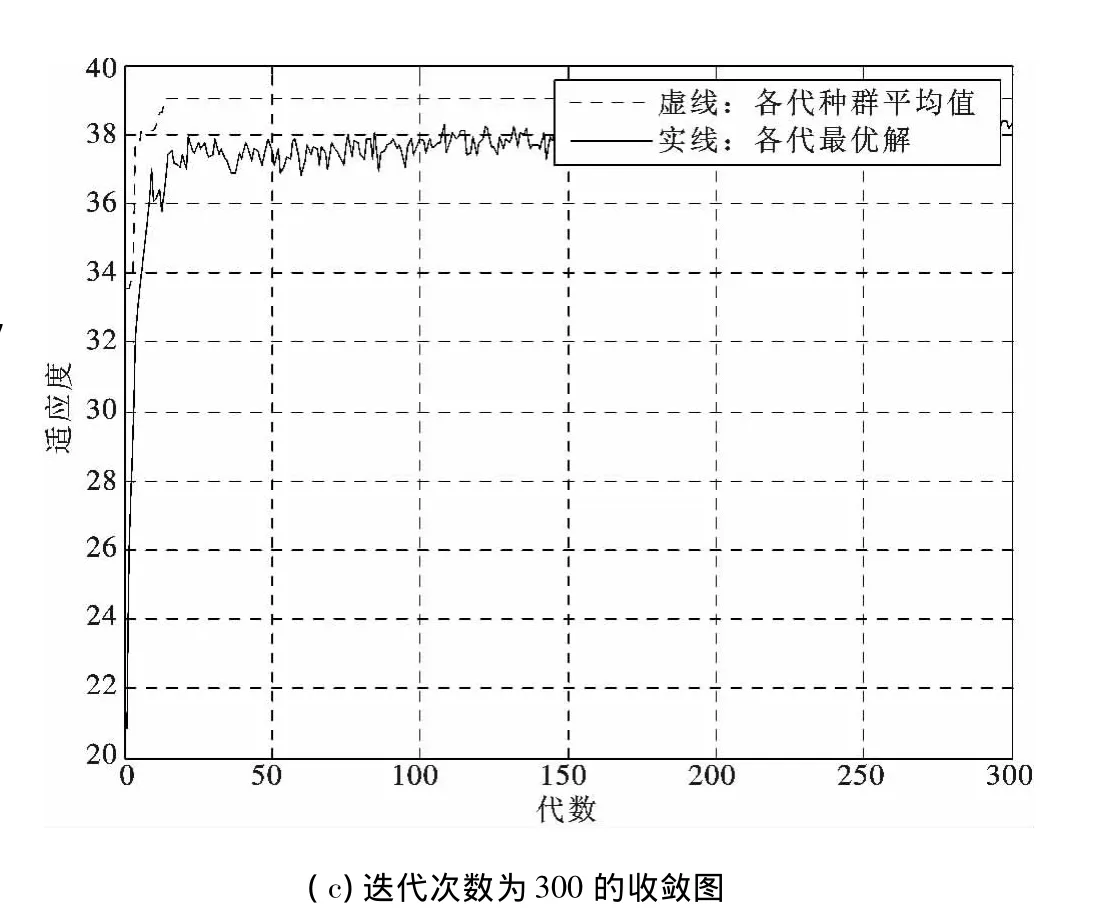
圖9 不同迭代次數對結果的影響Fig.9 Different iterations effects on results
6 結論
在CRTSP-DM模型的基礎上,本文提出一種基于蜂群算法的知識庫發現系統模型,將蜂群算法同CRTSP-DM模型有機地結合起來,運用Matlab軟件,進行仿真實驗,并同文獻中的算法進行了對比,主要研究結果如下:(1)根據仿真結果,蜂群算法的準確率達到98.1%,效果很好.(2)同文獻中的算法進行對比,主要從訓練準確率、測試準確率和運行時間3個方面進行驗證.從圖5中可以看出,蜂群算法的準確率達到100%,而文獻中的算法的準確率只達到93.333 3%.從圖6中可以看出,蜂群算法的準確率普遍高于文獻算法的準確率.由圖7可見,蜂群算法的運行時間也優于文獻算法.
最后,調整蜂群算法的不同參數,對比了不同參數對蜂群算法知識庫發現系統尋優結果的影響.
[1]王興偉,鄒榮珠,黃 敏.一種基于蜂群算法的ABC支持型QoS組播路由機制[J].計算機科學,2009(6):47-52.
[2]袁 浩.基于改進蜂群算法無線傳感器感知節點部署優化[J].計算機應用研究,2010,26(7):2704-2708.
[3]KARABOGA D,OKDEM S,OZTURK C.Cluster based wireless sensor network routings using artificial bee colony algorithm[J].J Wireless Networks,2012,18(7):847-860.
[4]丁海軍,馮慶嫻.基于boltzmann選擇策略的人工蜂群算法[J].計算機工程與應用,2009,45(1):53-55.
[5]暴 勵,曾建潮.一種雙種群差分蜂群算法[J].控制理論與應用,2011,28(2):267-272.
[6]胡中華,趙 敏.基于人工蜂群算法的機器人路徑規劃[J].電焊機,2009,26(1):93-96.
[7]康 飛,李俊杰,許 青.改進人工蜂群算法及其在反演分析中的應用[J].水電能源科學,2009,27(1):126-129.
[8]暴 勵,曾建潮.自適應搜索空間的混沌蜂群算法[J].計算機應用研究,2010,26(4):1331-1334.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
