基于眾包的社交網(wǎng)絡(luò)數(shù)據(jù)采集模型設(shè)計與實現(xiàn)
2015-01-02 02:00:50高夢超胡慶寶程耀東李海波
計算機工程 2015年4期
高夢超,胡慶寶,程耀東,周 旭,李海波,杜 然
(1.四川大學(xué)計算機學(xué)院,成都610065;2.中國科學(xué)院高能物理研究所計算中心,北京100049;3.中國科學(xué)院聲學(xué)研究所,北京100190)
1 概述
互聯(lián)網(wǎng)的興起打破了傳統(tǒng)的社會交往方式,簡單、快捷和無距離的社交體驗推動社交網(wǎng)絡(luò)快速發(fā)展,以Facebook、Twitter、微博等為代表的應(yīng)用吸引了大量活躍網(wǎng)絡(luò)用戶,社交網(wǎng)絡(luò)信息呈現(xiàn)爆發(fā)式的增長。社交網(wǎng)絡(luò)信息反映了用戶的網(wǎng)絡(luò)行為特征,通過對這些信息的研究,可以實現(xiàn)社會輿論監(jiān)控、網(wǎng)絡(luò)營銷、股市預(yù)測等。社交網(wǎng)絡(luò)信息的重要價值在于實時性,如何快速、準確、有效地獲取目標信息非常重要。但社交網(wǎng)絡(luò)屬于Deep Web的專有網(wǎng)絡(luò)[1],信息量大、主題性強,傳統(tǒng)搜索引擎無法索引這些Deep Web頁面,只有通過網(wǎng)站提供的查詢接口或登錄網(wǎng)站才能訪問其信息,這增加了獲取社交網(wǎng)絡(luò)信息的難度。
目前國外有關(guān)社交網(wǎng)絡(luò)數(shù)據(jù)采集模型的研究較少,對社交網(wǎng)絡(luò)的研究主要集中在社會網(wǎng)絡(luò)分析領(lǐng)域。國內(nèi)社交網(wǎng)絡(luò)平臺的數(shù)據(jù)采集技術(shù)研究有一定成果,如文獻[2]提出并實現(xiàn)一種利用新浪微博應(yīng)用程序接口(Application Programming Interface,API)和網(wǎng)絡(luò)數(shù)據(jù)流相結(jié)合的方式采集數(shù)據(jù),文獻[3]利用人人網(wǎng)開發(fā)平臺提供的API實現(xiàn)數(shù)據(jù)采集,并通過WebBrowser和HttpFox監(jiān)測信息交互時的數(shù)據(jù)包,實現(xiàn)動態(tài)獲取Ajax頁面信息等。
本文采用模擬登錄技術(shù),利用社交平臺賬戶獲取平臺訪問權(quán)限,通過設(shè)置初始任務(wù)集對目標信息進行定向獲取,避免請求不相關(guān)的信息頁面,既保證了信息的實時性,又提高了信息獲取效率。但是頻繁地使用缺少維護的社交賬戶爬取數(shù)據(jù),容易導(dǎo)致賬戶被平臺封殺,為獲取大量有效的社交賬戶并在服務(wù)器端避免繁重的賬戶維護工作,利用Hadoop平臺的MapReduce計算模型處理結(jié)果數(shù)據(jù)[4],選擇基于Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System,HDFS)的HBase數(shù)據(jù)庫存儲MapReduce處理結(jié)果,完成海量數(shù)據(jù)的有效存儲。
2 數(shù)據(jù)采集模型設(shè)計
2.1 設(shè)計原理
大規(guī)模獲取社交網(wǎng)絡(luò)數(shù)據(jù)需要解決3個問題:(1)獲取社交平臺的數(shù)據(jù)采集權(quán)限;(2)數(shù)據(jù)的快速采集;(3)數(shù)據(jù)的有效存儲。
一些社交平臺如Twitter、新浪微博、人人網(wǎng)等,允許用戶申請平臺數(shù)據(jù)的采集權(quán)限,并提供了相應(yīng)的API接口采集數(shù)據(jù),通過注冊社交平臺、申請API授權(quán)、調(diào)用API方法等流程獲取社交信息數(shù)據(jù)。但社交平臺采集權(quán)限的申請比較嚴格,申請成功后對于數(shù)據(jù)的采集也有限制。因此,本文采用網(wǎng)絡(luò)爬蟲的方式,利用社交賬戶模擬登錄社交平臺,訪問社交平臺的網(wǎng)頁信息,并在爬蟲任務(wù)執(zhí)行完畢后,及時返回任務(wù)執(zhí)行結(jié)果。
為提高數(shù)據(jù)的采集速度,本文采用分布式采集方式,通過設(shè)置初始任務(wù)集,按照任務(wù)調(diào)度機制把數(shù)據(jù)采集任務(wù)下發(fā)到用戶機器,由用戶機器完成整個數(shù)據(jù)的獲取工作。然而,為了保護數(shù)據(jù),減輕服務(wù)器的負擔(dān),社交平臺通常會采取一些反爬蟲措施,如封殺賬號、封鎖登錄IP等。隨著社交賬戶的申請流程越來越嚴格,社交賬戶的獲取和有效性維護也成為制約大規(guī)模采集社交網(wǎng)絡(luò)數(shù)據(jù)的瓶頸之一。
為解決以上問題,本文引入眾包思想。眾包是一種分布式的問題解決和生產(chǎn)模式,由美國《連線》記者Jeff Howe于2006年6月提出,即指公司或機構(gòu)把公司內(nèi)部任務(wù)以公開的方式外包給非特定的大眾網(wǎng)絡(luò)的行為。本文參考其商業(yè)運作模式,將其運用到互聯(lián)網(wǎng)的相互協(xié)作中,通過社交網(wǎng)絡(luò)的數(shù)據(jù)共享吸引網(wǎng)絡(luò)用戶作為志愿者參與到該項目平臺中,由志愿者提供計算資源和社交賬戶在本地完成信息的分布式采集,并由志愿者負責(zé)維護自己的社交賬戶,解決了計算資源和社交賬戶的獲取以及維護大量社交賬戶的難題。
本文采集模型采用自主開發(fā)的C/S架構(gòu)軟件系統(tǒng)作為分布式采集的基礎(chǔ)框架,利用Hadoop計算平臺[5]作為采集模型的數(shù)據(jù)處理框架。爬蟲應(yīng)用獲取到的初始數(shù)據(jù)是非結(jié)構(gòu)化和半結(jié)構(gòu)化的網(wǎng)頁信息,對網(wǎng)頁信息進行抽取后,得到指定格式的目標結(jié)果數(shù)據(jù),經(jīng)過MapReduce計算模型的處理后,保存在HBase數(shù)據(jù)庫中。
MapReduce編程模型是Hadoop平臺的核心技術(shù)之一,它掩蓋了分布式計算底層實現(xiàn)的細節(jié),并提供相關(guān)接口,使編程人員能夠快速實現(xiàn)分布式并行編程。HBase是一個分布式存儲模型,是Bigtable[6]的開源實現(xiàn),把HDFS作為HBase的支撐系統(tǒng),一方面可以提高數(shù)據(jù)的可靠性和系統(tǒng)的健壯性,另一方面也可以采用MapReduce模型處理HBase中的數(shù)據(jù),便于充分發(fā)揮HBase的大數(shù)據(jù)處理能力。采集模型整體結(jié)構(gòu)如圖1所示。
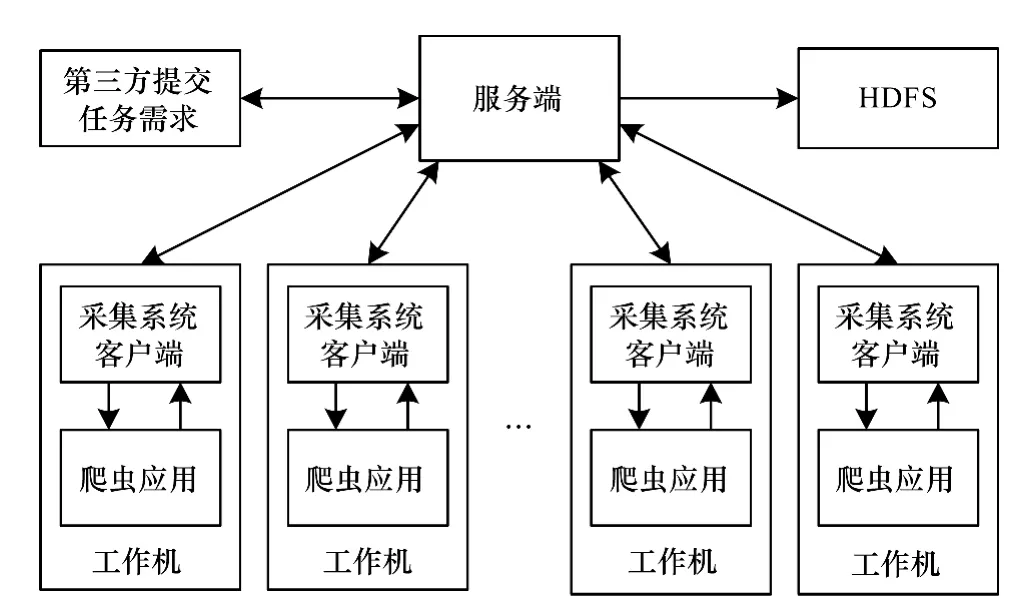
圖1 采集模型整體結(jié)構(gòu)
2.2 功能架構(gòu)
采集模型基于眾包模式,采用C/S架構(gòu),包含了服務(wù)端、客戶端、存儲系統(tǒng)與爬蟲系統(tǒng)4個模塊。服務(wù)端是系統(tǒng)控制核心,控制任務(wù)在下發(fā)前的一切操作以及結(jié)果校驗等工作,且系統(tǒng)只有一個服務(wù)端。客戶端置于分布式機器節(jié)點中,通過socket套接字與服務(wù)端通信,接收服務(wù)端命令、調(diào)用爬蟲程序等。存儲系統(tǒng)采用HDFS,具體的數(shù)據(jù)獲取工作由爬蟲程序使用HttpClient對象來模擬瀏覽器操作完成。
系統(tǒng)的主題爬蟲應(yīng)用程序通過HttpClient對象模擬瀏覽器操作實現(xiàn)。HttpClient[7]是 Apache Jakarta Common下的子項目,它是一個客戶端的傳輸類,支持自動轉(zhuǎn)向、HTTPS協(xié)議、代理服務(wù)器等。爬蟲的模擬登錄功能模塊與數(shù)據(jù)獲取功能是基于HttpClient提供的HTTP方式與Cookies管理功能實現(xiàn)。
HDFS是 Hadoop核心技術(shù)之一[8-10],可以運行在通用硬件上、具備高度容錯性、支持超大文件的分布式文件系統(tǒng)以及以流的形式訪問文件系統(tǒng)中的數(shù)據(jù),適合大規(guī)模數(shù)據(jù)集上的應(yīng)用。HDFS程序的文件操作模式大部分是一次寫入、多次讀取的簡單數(shù)據(jù)一致性模型,這種設(shè)計簡化了數(shù)據(jù)一致的問題并使高吞吐量的數(shù)據(jù)訪問變得可能[11],非常適合網(wǎng)絡(luò)爬蟲程序。采集模型各組成部分在運行時的調(diào)用關(guān)系如圖2所示。

圖2 采集模型中各組成部分在運行時的調(diào)用關(guān)系
在客戶端啟動后,調(diào)用爬蟲程序向服務(wù)器請求任務(wù)并執(zhí)行數(shù)據(jù)獲取任務(wù)。服務(wù)端的控制模塊負責(zé)管理服務(wù)端與客戶端的通信,并接收第三方提交的任務(wù)需求。Mysql數(shù)據(jù)庫用來存儲和任務(wù)有關(guān)的一切數(shù)據(jù),并接收任務(wù)調(diào)度中心的命令生成任務(wù)。任務(wù)調(diào)度中心接收爬蟲程序的任務(wù)請求,并返回任務(wù)文件,由爬蟲程序完成具體的數(shù)據(jù)獲取操作。數(shù)據(jù)獲取結(jié)果返回給服務(wù)端的接收模塊后,再由校驗?zāi)K負責(zé)校驗,并修改Mysql數(shù)據(jù)庫中任務(wù)狀態(tài)。校驗成功后,如果任務(wù)是第三方提出的,將數(shù)據(jù)獲取結(jié)果發(fā)送給第三方,否則傳輸給 HDFS,利用MapReduce完成數(shù)據(jù)結(jié)果的存儲。
3 數(shù)據(jù)采集模型的功能實現(xiàn)
3.1 邏輯功能
眾包模式的實現(xiàn)需要基于C/S架構(gòu)的通信主體。服務(wù)端包含控制模塊、任務(wù)調(diào)度模塊、接收模塊、校驗?zāi)K和Mysql數(shù)據(jù)庫。客戶端主要功能是接收服務(wù)器命令、啟動爬蟲程序等。
控制模塊向客戶端下發(fā)命令并接收客戶端的反饋信息,并接收第三方提交的任務(wù)需求參數(shù),并根據(jù)配置文件將其轉(zhuǎn)化為相應(yīng)的任務(wù)類型,存儲到Mysql數(shù)據(jù)庫中,等待任務(wù)調(diào)度模塊的調(diào)度。
任務(wù)調(diào)度模塊的核心功能是保證客戶端爬蟲程序能有序地獲取到有效任務(wù)。任務(wù)調(diào)度模塊、接收模塊、校驗?zāi)K共同維護Mqsql數(shù)據(jù)庫中的taskinfo表。taskinfo表設(shè)計了14個字段,包含索引值taskhash、任務(wù)類型type、任務(wù)狀態(tài)state、任務(wù)創(chuàng)建時間createtime、任務(wù)下發(fā)時間requestindex、任務(wù)超時時間mactimelength等。taskinfo表包含了每一個任務(wù)的索引目錄,但是沒有任務(wù)內(nèi)容,任務(wù)內(nèi)容存放在次級任務(wù)表里,每種小任務(wù)對應(yīng)一個次級任務(wù)表,每一個任務(wù)文件都由若干個小任務(wù)組成。任務(wù)調(diào)度模塊創(chuàng)建任務(wù)時,使用taskhash來標識任務(wù)的唯一性,并按照 createtime設(shè)定任務(wù)的優(yōu)先級,同時選擇taskhash作為次級任務(wù)表的外鍵,并在次級任務(wù)表中添加與taskhash相應(yīng)的任務(wù)內(nèi)容。任務(wù)調(diào)度模塊根據(jù)state的狀態(tài)決定任務(wù)的下發(fā)。state有7種狀態(tài),分別 是 created,dealing,dealed,analysing,failed,success,stop。任務(wù)調(diào)度模塊接收到爬蟲程序的任務(wù)請求后,選擇 taskinfo表中 state為 created或 failed狀態(tài)的優(yōu)先級最高的任務(wù)的taskhash,通過SQL語句查詢次級任務(wù)表,生成最終任務(wù)文件,以json文件格式返回給爬蟲程序。state狀態(tài)之間的轉(zhuǎn)換如圖3所示。
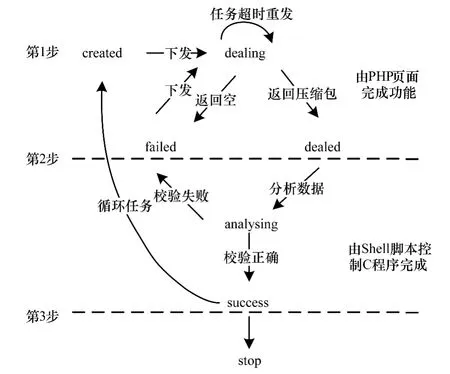
圖3 任務(wù)狀態(tài)轉(zhuǎn)換
對于只需要執(zhí)行一次的任務(wù),在state轉(zhuǎn)換成success后,任務(wù)結(jié)束。對于需要循環(huán)執(zhí)行的任務(wù),如定時爬取社交網(wǎng)絡(luò)用戶的注冊信息來保證信息的動態(tài)更新等,state在轉(zhuǎn)換到success一定時間內(nèi),如果沒有被修改為stop狀態(tài),會轉(zhuǎn)換到created狀態(tài),重新等待節(jié)點請求。
接收模塊使用超文本預(yù)處理器(PHP)代碼實現(xiàn),調(diào)用PHP代碼的標準函數(shù)move_uploaded_file,接收使用repost上傳的文件,并存儲到磁盤指定位置。如果壓縮包為空,state被修改為failed,否則修改為dealed。如果壓縮包非空,進入到校驗?zāi)K,修改state狀態(tài)為analysing。壓縮包由包含json字符串的文件組成,校驗?zāi)K根據(jù)C語言標準函數(shù)json_object_object_get,json_object_get_string,json_object_array_length對上傳的json數(shù)據(jù)進行抽取分析,如果與定義的結(jié)果格式一致,校驗成功,修改state狀態(tài)為success,否則state被修改為failed。在該任務(wù)被重新下發(fā)后,state被修改為dealing。校驗成功后的文件被發(fā)送到HDFS中進行進一步處理,最后完成數(shù)據(jù)存儲。
客戶端使用MFC框架實現(xiàn),機器節(jié)點通過安裝客戶端即可選擇加入系統(tǒng)中的某一項目,通過節(jié)點自身的運算能力為項目提供計算資源。
3.2 主題爬蟲
主題爬蟲應(yīng)用程序是實現(xiàn)數(shù)據(jù)獲取的核心模塊。基于社交網(wǎng)絡(luò)信息的特點,爬蟲程序包含模擬登錄、請求任務(wù)、執(zhí)行任務(wù)、數(shù)據(jù)上傳4個功能,與傳統(tǒng)爬蟲程序的區(qū)別是增加模擬登錄功能,通過構(gòu)建目標數(shù)據(jù)所在頁面的URL實現(xiàn)信息的定向獲取。本文以新浪微博為例,介紹爬蟲的工作原理。
針對新浪微博的主題爬蟲應(yīng)用程序,基于J2SE平臺進行實現(xiàn)。模擬登錄功能的實現(xiàn)方式是讀取包含賬號信息的配置文件,模擬網(wǎng)頁登錄新浪微博的過程,獲取訪問新浪微博頁面時所需要的有效認證信息,即需要保存在本地的Cookie信息。程序向新浪服務(wù)器發(fā)送經(jīng)過加密的用戶名(username)和密碼(password),服務(wù)器從傳遞的URL參數(shù)中提取字符串并解密得到原用戶名和密碼,其中對username和password的加密是模擬登錄過程中的關(guān)鍵步驟。對username進行Base64編碼得到用戶名的加密結(jié)果。但password的加密過程比較復(fù)雜。首先利用HttpClient對象訪問新浪服務(wù)器獲取服務(wù)器時間(servertime)、一個隨機生成的字符串(nonce)2個參數(shù)。然后利用新浪服務(wù)器給出的pubkey和rsakv值創(chuàng)建RSA算法公鑰(key)。將servertime,nonce和password按序拼接成新的字符串message,使用key對message進行RSA加密并將加密結(jié)果轉(zhuǎn)化為十六進制,得到password的加密結(jié)果。將加密后的用戶名和密碼一起作為請求通行證的URL請求的報頭信息傳遞給新浪服務(wù)器,新浪服務(wù)器經(jīng)過驗證無誤后,返回登錄成功信息,HttpClient保存有效的Cookies值。模擬登錄成功后,程序會向服務(wù)端請求數(shù)據(jù)獲取任務(wù),否則結(jié)束本次任務(wù)。
任務(wù)請求模塊向服務(wù)端的調(diào)度中心請求數(shù)據(jù)獲取任務(wù)。爬蟲程序通過httpClient的HttpGet方法,對指定 PHP頁面進行請求,獲取任務(wù)對應(yīng)的taskhash。然后把 taskhash和機器 mac地址作為URL參數(shù)對另一PHP頁面進行請求,服務(wù)端PHP頁面接收到請求后,服務(wù)端程序?qū)askhash和mac地址進行驗證,檢測無誤后,通過SQL語句查詢次級任務(wù)表,并把查詢結(jié)果組合成任務(wù)文件,以json字符串的形式返回給爬蟲程序。
任務(wù)執(zhí)行模塊解析任務(wù)文件,完成具體的數(shù)據(jù)獲取操作。在爬蟲程序中,不同數(shù)據(jù)類型的獲取功能被封裝成了不同類對象,以便程序調(diào)用。在執(zhí)行數(shù)據(jù)獲取任務(wù)時,根據(jù)目標數(shù)據(jù)的類型調(diào)用相應(yīng)的類對象,然后執(zhí)行相應(yīng)的成員函數(shù)來獲取數(shù)據(jù)。
對定向獲取的微博信息的網(wǎng)頁源碼使用正則表達式進行正則匹配,將結(jié)果轉(zhuǎn)化為json數(shù)據(jù)并存儲到指定文件中,直到獲取微博內(nèi)容的任務(wù)全部完成。將結(jié)果數(shù)據(jù)壓縮后,上傳給服務(wù)端的接收模塊,本次任務(wù)結(jié)束。主題爬蟲系統(tǒng)流程如圖4所示。
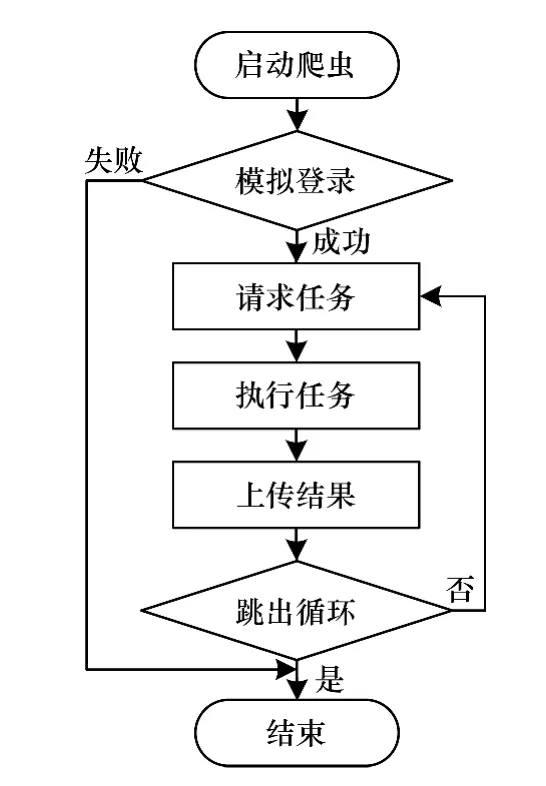
圖4 主題爬蟲系統(tǒng)流程
3.3 數(shù)據(jù)處理
MapReduce計算模型[12]在執(zhí)行計算任務(wù)時,需要HDFS集群的支持。HDFS采用主從(Master/Slave)體系結(jié)構(gòu),包含名字節(jié)點NameNode、數(shù)據(jù)節(jié)點DataNode和客戶端Client 3個重要部分。一個HDFS集群是由一個NameNode和若干個DataNode組成。
在寫入HBase數(shù)據(jù)庫前,需要使用MapReduce計算模型對原始數(shù)據(jù)進行清洗、篩選、統(tǒng)計等。MapReduce計算模型劃分為Map和Reduce 2個階段,分別采用Map()函數(shù)和Reduce()函數(shù)進行處理。其中,Map()函數(shù)主要對爬蟲獲取的結(jié)果數(shù)據(jù)進行格式清理,生成<key,list<value>>形式的中間結(jié)果,交由Reduce函數(shù)進行處理。Reduce函數(shù)對中間結(jié)果中相同鍵的所有值進行規(guī)約,可以去除結(jié)果中相同的記錄,利用Java API與HBase數(shù)據(jù)庫進行交互,通過創(chuàng)建 Put對象,實現(xiàn)數(shù)據(jù)批量導(dǎo)入HBase數(shù)據(jù)庫中。
為便于程序執(zhí)行,采集模型將MapReduce程序封裝成Jar包,利用Shell腳本進行控制執(zhí)行,在簡化數(shù)據(jù)處理步驟的同時,也通過對數(shù)據(jù)的集中處理,提高了MapReduce程序的工作效率。
4 實驗結(jié)果與分析
本文數(shù)據(jù)獲取系統(tǒng)目前處于測試階段,擁有146個志愿機器節(jié)點,分布在北京、海口和大慶3個地區(qū)。在普通網(wǎng)絡(luò)環(huán)境下,經(jīng)過一個月的試運行,系統(tǒng)數(shù)據(jù)獲取結(jié)果如表1所示。

表1 系統(tǒng)試運行的數(shù)據(jù)獲取結(jié)果
從結(jié)果可以看出,數(shù)據(jù)獲取系統(tǒng)的任務(wù)成功率約為92%,數(shù)據(jù)獲取效率很高,完成了預(yù)期結(jié)果。對抓取數(shù)據(jù)進行統(tǒng)計分析,可以觀察微博數(shù)據(jù)走勢。鳳凰衛(wèi)視2013年6月的微博轉(zhuǎn)發(fā)統(tǒng)計如圖5所示。

圖5 鳳凰衛(wèi)視2013年6月中旬微博評論轉(zhuǎn)發(fā)數(shù)量統(tǒng)計
5 結(jié)束語
本文設(shè)計并實現(xiàn)一個基于眾包模式的社交網(wǎng)絡(luò)數(shù)據(jù)采集模型,把數(shù)據(jù)獲取任務(wù)下發(fā)到不同的機器節(jié)點,通過主題爬蟲執(zhí)行任務(wù),實現(xiàn)對網(wǎng)頁信息的定向獲取,提高數(shù)據(jù)獲取速度。利用Hadoop分布式文件系統(tǒng)存儲結(jié)果數(shù)據(jù),在實現(xiàn)對數(shù)據(jù)進行有效存儲的同時,提高信息檢索效率,為進一步分析社交網(wǎng)絡(luò)數(shù)據(jù)提供功能支持。今后將對采集模型的任務(wù)調(diào)度系統(tǒng)進行優(yōu)化,并開放用戶管理平臺,提高用戶參與度。
[1] 高 原.面向領(lǐng)域的 Deep Web信息抽取技術(shù)研究[D].南京:南京信息工程大學(xué),2013.
[2] 黃延煒,劉嘉勇.新浪微博數(shù)據(jù)獲取技術(shù)研究[J].信息安全與通信保密,2013,(6):71-73.
[3] 鄧夏瑋.基于社交網(wǎng)絡(luò)的用戶行為研究[D].北京:北京交通大學(xué),2012.
[4] Prabhakar C.CloudComputingwithAmazonWeb Services,Part5:Dataset Processing in the Cloud with SimpleDB[EB/OL].(2009-05-11).http://www.ibm.com/developerworks/library/ar-cloudaws5/.
[5] Hadoop[EB/OL].[2013-05-28].http://hadoop.a(chǎn)pache.org/.
[6] Chang F,Dean J,Ghemawat S,et al.Bigtable:A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems,2008,26(2):4-12.
[7] HttpClient Tutorial[EB/OL].[2013-05-28].http://hc.a(chǎn)pache.org/httpcomponents-client-ga/tutorial/pdf/httpclient-tutorial.pdf.
[8] Hayes B.Cloud Computing[J].Communications of the ACM,2008,51(7):9-11.
[9] Konstantin S,Hairong K,Sanjay R,et al.The Hadoop Distributed File System[C]//Proceedings of the 26th Symposium on Mass Storage Systems and Technologies.Washington D.C.,USA:IEEE Computer Society,2010:1-10.
[10] 陳 康,鄭緯民.云計算:系統(tǒng)實現(xiàn)與研究現(xiàn)狀[J].軟件學(xué)報,2009,20(5):1337-1348.
[11] 崔 杰,李陶深,蘭紅星.基于Hadoop的海量數(shù)據(jù)存儲平臺設(shè)計與開發(fā)[J].計算機研究與發(fā)展,2012,49(Sl):12-18.
[12] 董西成.Hadoop技術(shù)內(nèi)幕:深入解析MapReduce架構(gòu)設(shè)計與實現(xiàn)原理[M].北京:機械工業(yè)出版社,2013.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
