基于多特征分類的微博好友推薦
2015-01-02 02:00:52程倩倩王路路姬東鴻
計算機工程 2015年4期
程倩倩,王路路,鄭 濤,姬東鴻
(武漢大學計算機學院,武漢430072)
1 概述
隨著Web2.0的迅速發展,社交網絡與人們的生活越來越密切,成為人們生活中必不可少的一部分。一方面,社交網絡能夠幫助用戶認識有相同愛好的人,聯系現實生活中的好友、分享信息等。另一方面,社交網絡也為用戶提供了海量社交信息,使大家可以共同分享與交流。社交網絡的運作蘊藏了巨大商機,挖掘和利用這些信息已經在各領域展開,但是隨著用戶數量和信息量的增大,信息過載問題變得越來越嚴重,如何從大量用戶中為目標用戶推薦感興趣的用戶,即好友推薦系統是一個重要的研究方向。
好友推薦系統研究在學術界引起了高度關注,存在諸多推薦算法,主要包括:基于協同過濾的推薦,基于內容的推薦,基于關聯規則技術的推薦,基于聚類技術的推薦等。其中,基于協同過濾的推薦算法是目前最受歡迎的推薦技術,不依賴物品本身,主要依賴目標用戶或與目標用戶相似的用戶對物品的評分矩陣進行推薦。但是社交網絡中不存在這種共同的打分項,所以,這種經典的推薦算法不能直接用于用戶社交網絡的好友推薦,并且也存在一些難以克服的問題,比如:可信問題,冷啟動問題和數據稀疏問題等[1]。
由于在用戶微博內容中隱含用戶感興趣的話題和領域,因此基于用戶內容的推薦算法也是一項重要技術。文獻[2]對用戶的Twitter內容進行處理,發現用戶的興趣點,進而為目標用戶推薦具有相同興趣的用戶。這是對基于用戶內容的推薦算法的一個運用。但是這種推薦算法僅使用用戶的內容信息,推薦結果往往過于專一化,更傾向于推薦具有相同興趣愛好的陌生人[3]。
一些研究者將基于內容的推薦算法和社交網絡的好友關系相結合。文獻[4]提出Twittomender系統,根據目標用戶的Twitter內容、好友、粉絲以及好友和粉絲的Twitter內容進行建模。文獻[5]利用概率模型進行協同過濾,進而為目標用戶進行推薦最感興趣的用戶,概率模型綜合考慮Twitter內容和用戶間的關系。但是上述研究都沒有使用大量存在的用戶間的交互信息和用戶的個人信息。
綜上所述,目前在好友推薦系統中采用的信息過于單一,沒有綜合利用多種信息特征,導致推薦效果不佳。本文歸納了影響用戶推薦的4類信息:用戶標簽信息,用戶內容信息,用戶交互信息,用戶社交拓撲信息,利用這些信息計算出相關特征,并采用分類算法為目標用戶進行好友推薦。
2 相關知識
2.1 線性判別分析主題模型
線性判別分析(Linear Discriminant Analysis,LDA)是一種非監督學習技術,可以用來挖掘大規模文檔集或語料庫中潛藏的主題信息。它采用詞袋的方法,將每一篇文檔視為一個詞頻向量,從而將文本信息轉化為易于建模的數字信息。每一篇文檔被看作主題的一種概率分布,主題又被看作是單詞的一種概率分布。
對于語料庫中的每一篇文檔,LDA定義了如下的生成過程:
(1)選擇N~Possion(ξ);
(2)選擇一個多項式分布參數θ~Dir(i);
(3)對于文檔中的每個詞:
1)選擇一個topic z~Multinomial(θ),z是從以θ為參數的多項式分布中選出,共有k個topic;
2)從概率分布p(wn|zn,β)中選擇一個詞 wn,p為topic zn下的一個多項式分布。
上述過程可以用圖1所示的貝葉斯網絡圖來表示。
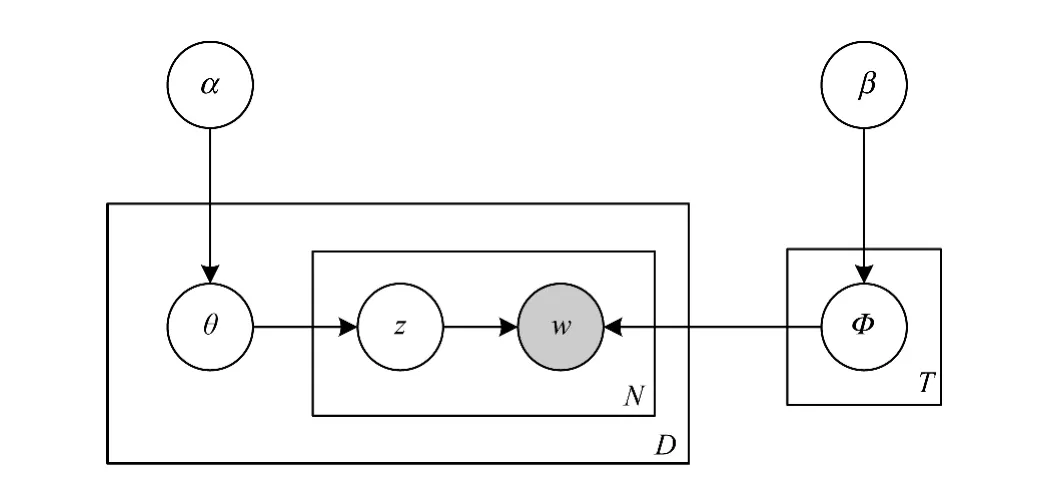
圖1 貝葉斯網絡
在圖1中,α是θ的超參數;β是Φ的超參數;θ是文檔-主題概率分布;Φ是主題-詞概率分布;z是詞的主題分布;w是詞;D是文檔數;N是詞數;T是主題數。整個貝葉斯網絡圖的聯合概率為:
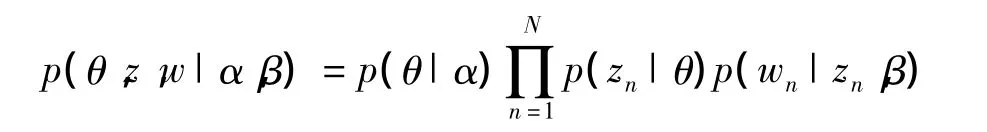
2.2 K最近鄰算法
K最近鄰(K Nearest Neighbor,KNN)分類算法的核心思想是如果一個對象在特征空間中的k個最相似的對象中的大多數屬于某一個類別,則該對象也屬于該類別,并具有該類別上對象的特性。
使用KNN算法對未知類別的點進行分類,具體步驟如下:
(1)計算已知類別數據集中的點與該點之間的距離;
(2)按照距離遞增次序排列;
(3)選取與當前點距離最小的k個點;
(4)確定前k個點所在類別的出現頻率;
(5)返回前k個點出現頻率最高的類別作為當前點的預測分類。
3 微博好友推薦算法
本文通過分析總結了影響好友推薦的4類關鍵用戶信息:(1)用戶內容信息,主要是指用戶發布、轉發的微博內容;(2)用戶標簽信息,這是用戶注冊時對自己興趣愛好的一組標簽描述;(3)用戶交互信息,這是用戶間評論、轉發、贊等交互行為;(4)用戶社交拓撲信息,這是用戶的關注列表和用戶的被關注列表,即粉絲列表。在這4類關鍵信息的基礎上,利用LDA主題模型從用戶內容信息中挖掘用戶潛在的興趣愛好,并計算用戶間的主題相關度;通過用戶標簽信息,計算用戶間的顯式的興趣相關度;從用戶交互信息和社交拓撲信息中,利用加權最小信息比率(Weighted Minimum-message Ratio,WMR)[6]算法計算用戶間的親密度;最后將主題相關度、興趣相關度、親密度作為特征向量,利用KNN分類方法進行好友推薦。
3.1 主題相關度計算
主題模型已經成功應用于很多文本挖掘任務中,比如熱點主題發現、用戶興趣發現、文本分類等[7-9]。本文采用LDA主題模型對用戶潛在的興趣進行發現。由于微博內容長度必須限制在140字以內,而一些研究者指出LDA模型應用于短文本時準確率較低[10],它適合用于長文本。但文獻[11]實驗證明在特定參數設置下,LDA模型應用于短文本時同樣可以取得和長文本一樣的效果。另外,文獻[12]通過在WebMd數據集上的實驗證明,即使在平均長度僅為5.2個詞的短文本上LDA模型也可以取得很好的效果。為準確挖掘用戶感興趣的主題,本文把用戶的所有微博內容集中到一個文檔中,即一個用戶對應一篇內容文檔;然后利用漢語詞法分詞系統(Institute of Computing Technology,Chinese LexicalAnalysis System,ICTCLAS)對文檔進行分詞,由于名詞和動詞對主題的辨識作用較大,因此只提取出文檔中的名詞和動詞,去掉其他詞性的詞語以及停用詞;然后利用LDA主題模型挖掘每篇文檔的主題,結果存儲到矩陣中;最后使用Jensen-Shannon散度計算主題的相關度:

3.2 標簽相關度計算
標簽是用戶在完善個人資料時填寫的關于個人興趣愛好描述的一組關鍵字,是表征用戶興趣愛好的一種重要信息。用戶相同的標簽越多,用戶與標簽的關聯度越大,則2個用戶的興趣愛好越相似。本文采用式(1)計算2個用戶的標簽相似度:
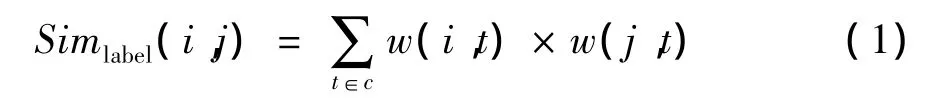
其中,c為用戶 i、用戶 j共同的標簽集合;t∈c,w(i,t)表示標簽 t與用戶 i的關聯度,w(i,t)的初始值為1,標簽每次在用戶i的關注用戶中出現一次值增加0.1,最后對Simlabel值進行歸一化處理。
3.3 親密度計算
用戶交互信息即微博用戶間的信息交互行為,包括評論、轉發、贊等動作。交互行為直接反映了用戶間社交關系的強弱,即用戶間的親密度,交互越頻繁說明用戶間的關系越親密。文獻[13]將用戶網絡分成2個部分,即相似用戶網絡和熟悉用戶網絡,并通過比較這2類網絡的推薦情況,證明基于熟悉用戶網絡推薦的效果要好于基于相似網絡的推薦。因此,構建一個以用戶為頂點、交互次數為邊的有向網絡是十分有必要的。根據文獻[14]中提出的小世界理論,任何2個陌生人最多不超過6個中間人就可以互相認識。所以,只需以目標用戶為根節點,向外延伸6層即可。用戶間的交互信息可以使用圖2的網絡圖進行模擬。
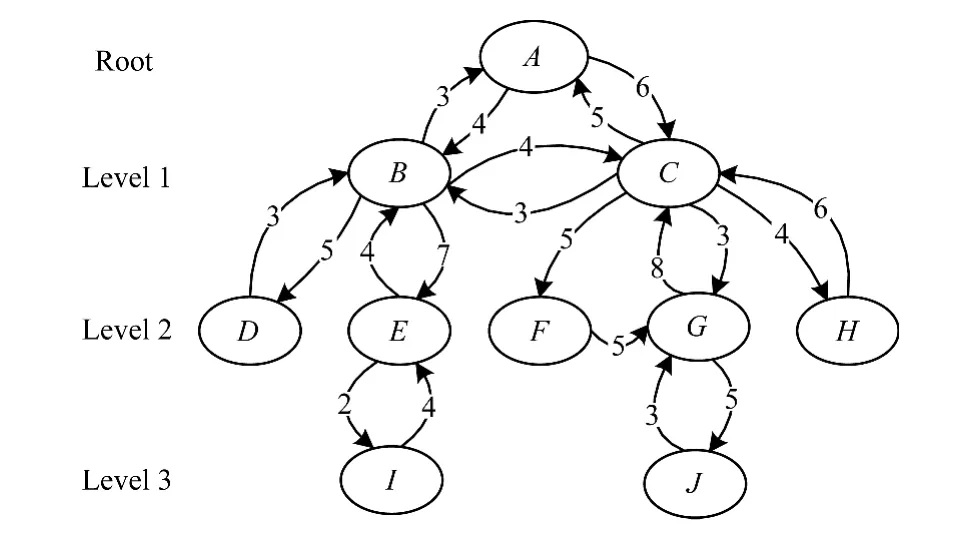
圖2 用戶交互網絡
本文結合文獻[6]中提出的WMR算法,計算用戶間的親密度。首先用戶交互是一個雙向的行為,取2邊中較小的一個值,這樣可以有效防止騷擾性的用戶交互;然后取消同層用戶間交互的信息,因為這些信息對最終不同層用戶與目標用戶的親密度的計算沒有影響,經過處理,得到如圖3所示的一個無向的網絡圖;最后使用式(2)計算用戶間的親密度。
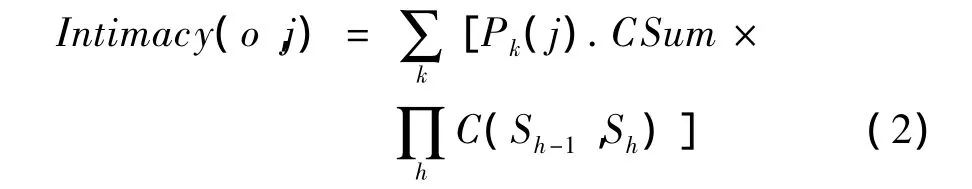
其中,Sh∈Pk(j)∩L(h),h=1,2,…,6;j∈L(h)且h≠1;Cij表示用戶i和用戶j之間交互的次數;L(h)表示在網絡圖中所有屬于第h層的用戶;Pk(j)表示從根節點即目標用戶開始到達用戶j的第k條路徑;Pk(j).CSum表示路徑Pk(j)上交互次數的總和;L(h).CSum表示第h層交互次數的總和;C(i,j)表示 Cij占 L(h).CSum 的比例,用戶 i∈L(h-1),用戶j∈L(h);Intimacy(o,j)表示用戶j與目標用戶o的親密度。
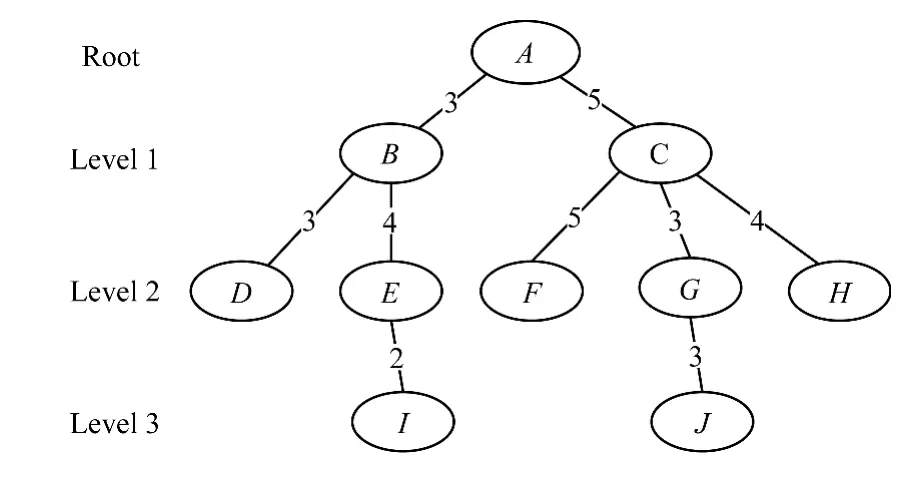
圖3 改進后的用戶交互網絡
3.4 利用KNN分類算法的微博好友推薦
目前用戶推薦研究采用的信息都比較單一[15-16],且都是采用排序函數實現排序,最終得到推薦列表,這樣的推薦模型在參數較多的情況下效果都不理想。因此,本文充分考慮用戶內容的主題相似度Simtopic、用戶的標簽相似度Simlabel,以及用戶的親密度Intimacy,然后利用KNN分類算法進行分類推薦。推薦框架如圖4所示,帶箭頭的虛線表示用戶間的關注關系。訓練數據是由目標用戶u的部分好友以及非好友組成的集合,如果用戶i是用戶u的好友,標記為+1,否則標記為-1。測試數據使用的用戶數據類型和訓練數據相同,對于每個測試用戶i,利用KNN算法計算分類結果。然后根據式(3)計算測試用戶i的推薦得分,最后根據得分降序為目標用戶u產生一個好友推薦列表。
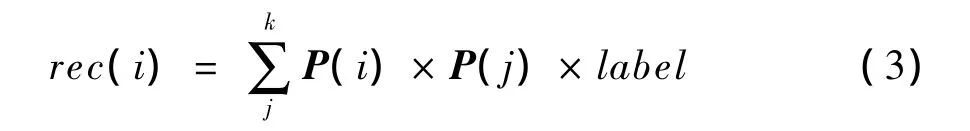
其中,P(i)表示測試用戶的特征向量;P(j)表示訓練用戶的特征向量;k為KNN算法中k的取值;label表示用戶i的分類結果,label的取值為+1,-1。
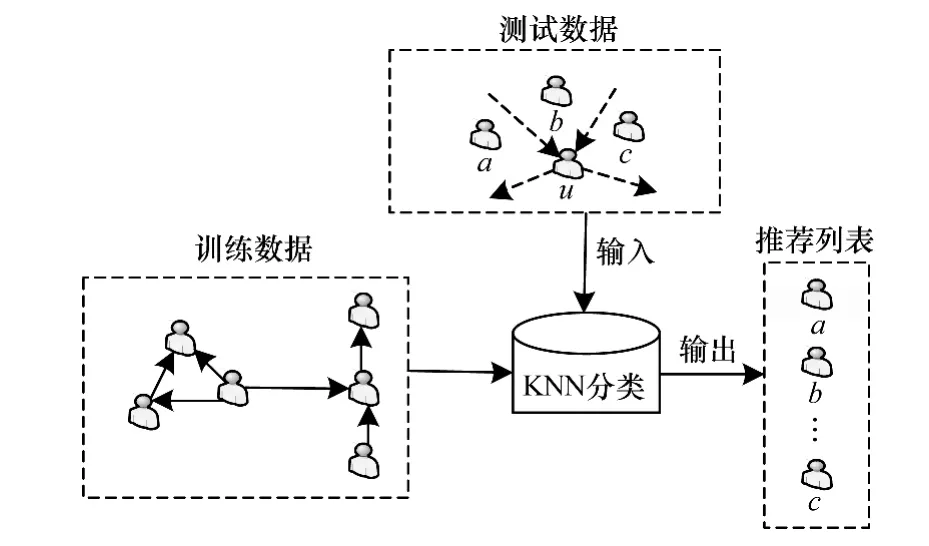
圖4 利用KNN分類算法的微博好友推薦框架
4 實驗結果及評估
4.1 實驗數據及參數設置
新浪微博是在國內使用人數最多、最受歡迎的微博,用戶可以標示自己的興趣愛好、添加好友、關注主題等。本文實驗使用新浪微博API抓取用戶的標簽信息,用戶的微博以及每條微博的交互信息,如:評論,轉發,贊。從8個不同的領域選取一些用戶作為目標用戶,采用廣度優先的算法,抓取了2萬個用戶從2013年10月16日-2014年1月16日的數據。為了提高實驗算法的準確性,首先對數據進行清洗:
(1)排除粉絲數超過10萬但好友人數小于500的用戶。這類用戶通常是非常出名的用戶,這些用戶的微博有大量粉絲的轉發、評論,但是鮮有互動,因此本文暫不考慮這類用戶。
(2)排除粉絲數少于10且微博數少于10的用戶。這些用戶粉絲和微博數過少,說明這些用戶很少使用微博,因此為他們推薦的意義不大。
經過處理后,得到5 224個用戶數據,其中包括266 627條微博,105 583條交互信息。本文采用交叉實驗,將數據集劃分為80%訓練集和20%測試集并進行多次實驗以驗證本文算法。
當用LDA模型挖掘用戶微博的主題時,本文根據文獻[17],采用貝葉斯統計中的標準方法對LDA模型的參數進行設置。令α=50/T,T是主題數,取T=50,迭代次數為100次。該設置為經驗值,經過多次實驗結果表明,這些值在本文數據集上為最佳參數值。
4.2 評價指標
對于實驗結果,本文采用準確率(precision)、召回率(recall)、F1度量值(F1-measure)作為衡量標準。
準確率是推薦列表中正確推薦個數Nrt與推薦總數Nr之比,其值越高說明推薦準確率越大。
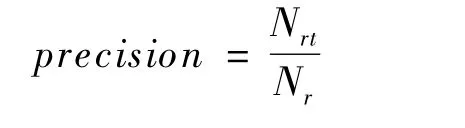
召回率是推薦列表中正確推薦個數Nrt與用戶總的好友個數Nf之比,值越高表示推薦效果越好。
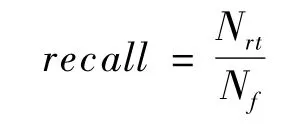
F1度量值(F1-measure)是準確率和召回率的加權調和平均,它綜合了準確率和召回率的結果。F1度量值越高說明推薦效果越好。
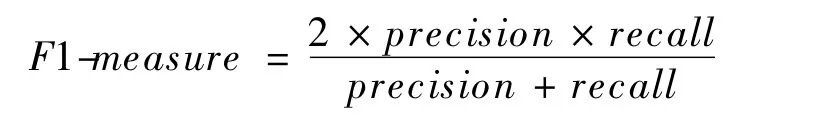
在本文實驗中,取不同推薦個數(N=2,4,6,8,10)進行對比。
4.3 結果分析
本文針對基于內容的推薦算法、基于社會過濾的推薦算法[18]和基于多因素分類的推薦算法(本文算法)分別進行實驗并進行對比。當N取不同值時3種算法的準確率、召回率、F1度量值分別如圖5~圖7所示。

圖5 算法準確率對比
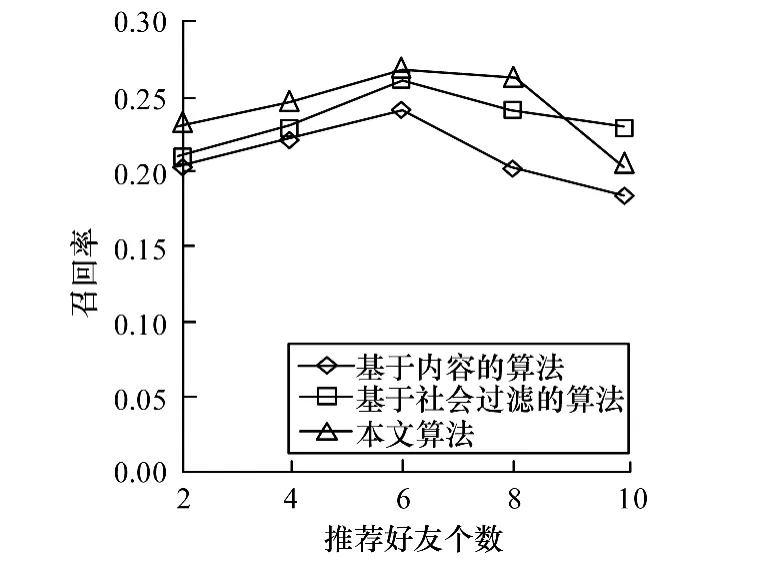
圖6 算法召回率對比
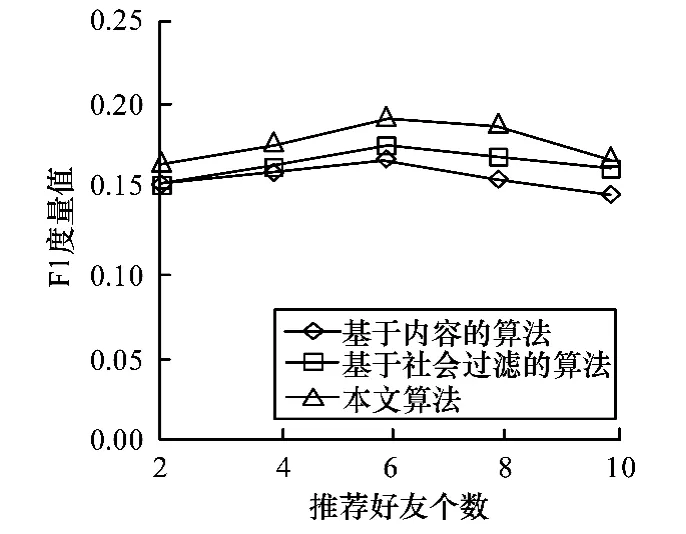
圖7 算法F1度量值對比
當N≤4時,基于內容的算法準確率高于基于社會過濾的推薦算法的準確率,而隨著N的增大,基于內容的算法準確率低于基于社會過濾的算法,它是這3種算法中準確率最低的,本文算法準確率最高。當N=4時,本文算法準確率達到最高的16.5%。
在召回率方面,當N<10時,基于多特征分類的算法的召回率最高,基于社會過濾的算法次之,基于內容的算法最低。當N=10時,本文算法召回率最低。當N=6時,本文算法的召回率達到了最高的26.8%。
從F1度量值方面,本文算法的推薦效果最好,而基于內容的算法推薦效果最差。一方面可能是因為微博內容簡短,而且內容中存在大量符號、表情、縮寫等,導致效果不好;另一方面,本文算法綜合考慮了用戶的主題相似度、標簽相似度和用戶間的親密度,利用更多的特征,所以取得了較好的推薦效果。而本文算法效果好于基于社會過濾的算法效果,是因為本文在計算用戶親密度時已經隱含利用用戶的社交網絡信息,而且還進一步利用用戶的主題相似度和標簽相似度來提高推薦效果。當N=6時,本文算法的F1度量值達到最高的19.2%。
綜上所述,本文提出的基于多特征分類的推薦算法要優于其他推薦算法。
5 結束語
本文總結影響微博用戶推薦的4類信息,并提出如何使用這些信息的方法,通過在新浪微博數據集上進行實驗,結果表明本文提出的基于多特征分類的推薦算法能有效為用戶進行好友推薦,但其對于新用戶,由于缺少用戶內容信息、交互信息和社交拓撲信息,因此退化為類似基于標簽的推薦算法,推薦效果不理想。在今后工作中,將研究使用微博用戶的其他信息進行好友推薦,如用戶的影響力、傳播范圍等,進一步改善推薦效果。
[1] 李克潮,梁正友.基于多特征的個性化圖書推薦算法[J].計算機工程,2012,38(11):34-37.
[2] Piao S,Whittle J.A Feasibility Study on Extracting Twitter Users’Interests Using NLP Tools for Serendipitous Connections[C]//Proceedings of the 3rd International Conference on Privacy,Security,Risk and Trust and the 3rd International Conference on Social Computing.Washington D.C.,USA:IEEE Press,2011:910-915.
[3] Chen J,Geyer W,Duguan C,et al.Make New Friends,But Keep the Old:Recommending People on Social Networking Sites[C]//Proceedings of SIGCHI Conference on Human Factors in Computing Systems.New York,USA:ACM Press,2009:201-210.
[4] Hannon J,Bennett M,Smyth B.Recommending Twitter Usersto Follow Using Contentand Collaborative Filtering Approaches[C]//Proceedings of the 4th ACM Conference on Recommender Systems.New York,USA:ACM Press,2010:199-206.
[5] Jamali M,Ester M.A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks[C]//Proceedings of the 4th ACM Conference on Recommender Systems.New York,USA:ACM Press,2010:135-142.
[6] Lo S,Lin C.WMR——A Graph-based Algorithm for Friend Recommendation[C]//Proceedingsof2006 IEEE/WIC/ACM InternationalConferenceonWeb Intelligence.Piscataway,USA:IEEE Computer Society,2006:121-128.
[7] Blei D M,Ng A Y,Jordan M I.LatentDirichlet Allocation[J].Journal of Machine Learning Research,2003,(3):993-1022.
[8] Zeng Jianping,Zhang Shiyong.Variable Space Hidden Markov Model for Topic Detection and Analysis[J].Knowledge-based Systems,2007,20(7):607-613.
[9] Zeng Jianping,Duan Jiangjiao,Wang Wei,etal.Semantic Multi-grain Mixture Topic Model for Text Analysis[J].Expert Systems with Applications,2011,38(4):3574-3579.
[10] Titov I,McDonald R.ModelingOnline Reviews with Multigrain Topic Models[C]//Proceedings ofthe17th International Conference on World Wide Web.New York,USA:ACM Press,2008:111-120.
[11] Duan J,Zeng J.Web Objectionable TextContent Detection Using Topic Modeling Technique[J].Expert Systems with Applications,2013,40(15):6094-6104.
[12] Denecke K,Brosowski M.TopicDetection in Noisy Data Sources[C]//Proceedings of the 15th International Conference on Digital Information Management.Piscataway,USA:IEEE Press,2010:50-55.
[13] Guy I,Zwerdling N,Carmel D,et al.Person-alized Recommendation of Social Software Items Based on Social Relations[C]//Proceedings of the 3rd ACM Conference on Recommender Systems.New York,USA:ACM Press,2009:53-60.
[14] Milgram S.TheSmall World Problem[J].Psychology Today,1967,2(1):60-67.
[15] Zhou T C,Ma H,Lyu M R,et al.UserRec:A User Recommendation Framework in Social Tagging Systems[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence.Palo Alto,USA:AAAI Press,2010.
[16] Koga H,Taniguchi T.Developing aUser Recommendation Engine on Twitter Using Estimated Latent Topics[M]//Jacko J A.Human-computer Interaction.Design and Development Approaches.Berlin,Germany:Springer,2011:461-470.
[17] Weng J,Lim E P,Jiang J,et al.Twitterrank:Finding Topic-sensitive Influential Twitterers[C]//Proceedings of the 3rd ACM International Conference on Web Search And Data Mining.New York,USA:ACM Press,2010:261-270.
[18] 高永兵,楊紅磊,劉春祥,等.基于內容與社會過濾的好友推薦算法研究[J].微型機與應用,2013,32(14):75-78.
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
臺聲(2016年2期)2016-09-16 01:06:53
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
