數(shù)據(jù)中心網(wǎng)絡(luò)快速反饋傳輸控制協(xié)議
2015-01-02 02:00:56蘇凡軍牛詠梅
計(jì)算機(jī)工程 2015年4期
蘇凡軍,牛詠梅,邵 清
(上海理工大學(xué)光電信息與計(jì)算機(jī)工程學(xué)院,上海200093)
1 概述
隨著云計(jì)算的發(fā)展,數(shù)據(jù)中心已成為實(shí)現(xiàn)云計(jì)算、云存儲(chǔ)的重要基礎(chǔ)設(shè)施。由于數(shù)據(jù)中心可以為大型信息系統(tǒng)提供海量數(shù)據(jù)處理和存儲(chǔ)服務(wù),現(xiàn)今建立起了許多大型服務(wù)數(shù)據(jù)網(wǎng)絡(luò),如 Amazon,Google和Yahoo等大公司都擁有了自己的數(shù)據(jù)中心,且隨著數(shù)據(jù)中心網(wǎng)絡(luò)的快速發(fā)展,其服務(wù)器的數(shù)量也呈指數(shù)級(jí)增長(zhǎng)。但是數(shù)據(jù)中心網(wǎng)絡(luò)在實(shí)現(xiàn)數(shù)據(jù)中心的通信時(shí),數(shù)據(jù)流一般具有高帶寬和低延遲的特點(diǎn),容易引起許多問(wèn)題的出現(xiàn),如擁塞通知問(wèn)題、能量消耗問(wèn)題以及TCP Incast問(wèn)題等。針對(duì)這些問(wèn)題,許多研究者們進(jìn)行了研究,如卡耐基梅隆大學(xué)的PDL Project和加州大學(xué)伯克利分校的RAD Lab的2個(gè)實(shí)驗(yàn)項(xiàng)目,國(guó)內(nèi)清華大學(xué)的任豐原等人對(duì)TCP Incast問(wèn)題的實(shí)驗(yàn)研究和分析等。
為了避免TCP Incast問(wèn)題造成的性能惡化,國(guó)內(nèi)外已經(jīng)展開了這方面的研究工作[1-3]。例如數(shù)據(jù)中心網(wǎng)絡(luò) TCP 協(xié)議(DCTCP)[1,4]利用了 ECN 的顯式擁塞通知功能,交換機(jī)在擁塞時(shí)做擁塞標(biāo)記,接收端將擁塞信息反饋給發(fā)送端,發(fā)送端估計(jì)擁塞程度從而調(diào)整擁塞窗口,但該算法存在反饋慢、擁塞估計(jì)不準(zhǔn)確等問(wèn)題。此外,還有ICTCP(Incast Congestion Control for TCP)[5]。ICTCP通過(guò)計(jì)算接收端的流量來(lái)估計(jì)鏈路可用帶寬的變化,然后通過(guò)調(diào)節(jié)接收窗口進(jìn)行速率控制。相比于傳統(tǒng)的TCP協(xié)議,ICTCP能夠有效地避免擁塞,緩解TCP Incast問(wèn)題,但其應(yīng)用場(chǎng)景很有限,只適用于很簡(jiǎn)單并且固定的TCP Incast場(chǎng)景。Alizadeh M等人提出了在數(shù)據(jù)中心網(wǎng)絡(luò)鏈路層進(jìn)行擁塞控制的QCN(Quantized Congestion Notification)算法[6],QCN 可以有效地控制鏈路速率,但是在TCP Incast場(chǎng)景下性能很差。
針對(duì)以上算法的缺點(diǎn),本文提出一種可快速反饋的數(shù)據(jù)中心網(wǎng)絡(luò)TCP協(xié)議。該協(xié)議的設(shè)計(jì)思想是交換機(jī)直接判斷擁塞情況發(fā)送擁塞反饋給發(fā)送端;發(fā)送端根據(jù)反饋信息快速準(zhǔn)確地調(diào)整擁塞窗口。最后采用NS2[7]的模擬實(shí)驗(yàn)對(duì)算法性能進(jìn)行驗(yàn)證。
2 TCP Incast問(wèn)題與解決方案
2.1 數(shù)據(jù)中心網(wǎng)絡(luò)TCP Incast問(wèn)題
如圖1所示的“多對(duì)一”的工作模式在現(xiàn)在的數(shù)據(jù)中心中已經(jīng)變得越來(lái)越普遍。其中,A1,A2,…,An表示數(shù)據(jù)中心的n個(gè)服務(wù)器。

圖1 TCP Incast模型示意圖
主機(jī)C請(qǐng)求的數(shù)據(jù)信息稱為SRU(Server Request Unit),分別存儲(chǔ)在各個(gè)服務(wù)器上。比如,SRU1存放在A1服務(wù)器上,為響應(yīng)主機(jī)請(qǐng)求,各個(gè)服務(wù)器將各自的數(shù)據(jù)發(fā)送到服務(wù)器B,組成完整的SRU,再反饋給主機(jī)C。這個(gè)通信過(guò)程中,A為發(fā)送端,C為接收端。典型例子如Google利用MapReduce技術(shù)處理搜索請(qǐng)求[8-10]。
當(dāng)這種“多對(duì)一”并發(fā)工作模式的多個(gè)發(fā)送者同時(shí)給服務(wù)器B發(fā)送數(shù)據(jù)塊時(shí),容易在服務(wù)器B處形成瓶頸,造成網(wǎng)絡(luò)擁塞,引起瓶頸鏈路吞吐量急劇下降,產(chǎn)生大量丟包。另外,在并發(fā)傳輸過(guò)程中,當(dāng)某個(gè)服務(wù)器發(fā)生了傳送超時(shí)而其他服務(wù)器已經(jīng)完成了傳輸,則客戶端在接收到剩余SRU之前必須等待至少RTOmins。等待期間客戶端的鏈路很有可能處于完全空閑狀態(tài),亦容易導(dǎo)致吞吐量顯著下降且總的請(qǐng)求延遲急劇增加,產(chǎn)生吞吐量崩潰現(xiàn)象,這個(gè)現(xiàn)象就是常說(shuō)的 TCP Incast問(wèn)題[11-12]。
2.2 DCTCP協(xié)議原理分析
TCP Incast問(wèn)題被提出后,國(guó)內(nèi)外的研究者從不同角度提出了解決該問(wèn)題的方案。DCTCP[1]是近年來(lái)提出的一個(gè)改進(jìn)TCP協(xié)議的算法。該算法需要發(fā)送端、接收端、中間交換機(jī)三者的協(xié)作。如圖1所示,交換機(jī)B檢測(cè)隊(duì)列長(zhǎng)度,當(dāng)隊(duì)列長(zhǎng)度大于某個(gè)閾值K時(shí),認(rèn)為網(wǎng)絡(luò)處于擁塞狀態(tài),在數(shù)據(jù)包中做顯式擁塞通知(Explicit Congestion Notification,ECN)的CE標(biāo)記;接收端C收到帶有ECN標(biāo)記的包后,在每個(gè)反向ACK包中做ECN-echo標(biāo)記;發(fā)送端收到ACK后,利用式(1)估計(jì)擁塞程度,其中,α為發(fā)送端測(cè)量被標(biāo)記的包的部分,α在每一個(gè)RTT中被更新。α的值代表了緩沖區(qū)占用大于閾值K的可能性,即α接近于0表示可能性很小(緩沖區(qū)占用小)。F表示被標(biāo)記的ACK在所有的ACK中的比例。發(fā)送端再按式(2)調(diào)整擁塞窗口。
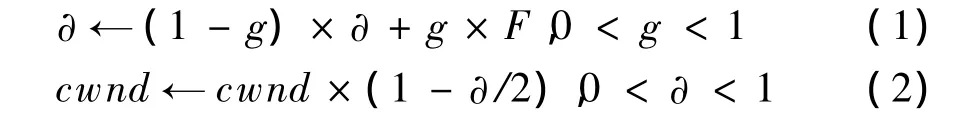
DCTCP協(xié)議比較簡(jiǎn)單,在一定程度上明顯改善了TCP Incast問(wèn)題。但是通過(guò)分析,其存在如下缺點(diǎn):
(1)反饋慢。整個(gè)反饋過(guò)程需要交換機(jī)做標(biāo)記,數(shù)據(jù)到了接收端C后,C在反向ACK中再次做標(biāo)記發(fā)送到發(fā)送端An,發(fā)送端再根據(jù)式(1)估計(jì)擁塞程度,并按式(2)調(diào)整擁塞窗口。這種算法環(huán)節(jié)多,尤其是接收端主機(jī)位于普通網(wǎng)絡(luò)中,延遲較大。
(2)擁塞估計(jì)不準(zhǔn)確。一個(gè)原因是由于反饋信息滯后;另外一個(gè)原因是擁塞信息太簡(jiǎn)單,只是根據(jù)一個(gè)隊(duì)列閾值發(fā)送單值擁塞信息。
3 FFDTCP協(xié)議
針對(duì)DCTCP存在的問(wèn)題,本文提出了FFDTCP協(xié)議。如圖1所示,該算法在交換機(jī)B根據(jù)當(dāng)前隊(duì)列長(zhǎng)度判斷網(wǎng)絡(luò)擁塞程度后,直接將擁塞信息利用反向的ACK包發(fā)送給發(fā)送端A,發(fā)送端不需要估計(jì)算法直接根據(jù)擁塞反饋信息調(diào)整擁塞窗口,因此節(jié)省了交換機(jī)B到接收端C這段的時(shí)延。而且為了準(zhǔn)確反饋擁塞信息,使用了3個(gè)比特位標(biāo)識(shí)擁塞程度,提供了更準(zhǔn)確的擁塞反饋。
3.1 中間交換機(jī)的快速擁塞反饋
中間交換機(jī)可以根據(jù)隊(duì)列長(zhǎng)度直接判斷擁塞情況。本文假設(shè)交換機(jī)使用 RED(Random Early Detection)算法[4,8]。該算法在當(dāng)前交換機(jī)、路由器中廣泛實(shí)現(xiàn),是基本隊(duì)列算法。RED算法認(rèn)為緩沖區(qū)隊(duì)列長(zhǎng)度超過(guò)一定的閾值是擁塞即將出現(xiàn)的征兆,故RED算法通過(guò)檢測(cè)緩沖區(qū)隊(duì)列長(zhǎng)度來(lái)發(fā)現(xiàn)擁塞的征兆,及時(shí)采取措施來(lái)防止擁塞,這就避免了擁塞對(duì)業(yè)務(wù)性能的不利影響,同時(shí)也避免了振蕩。在RED算法中,對(duì)每個(gè)隊(duì)列設(shè)置2個(gè)門限 minth和maxth,avq為平均隊(duì)列長(zhǎng)度。FFDTCP新添加一個(gè)隊(duì)列閾值midth,設(shè)為minth和maxth的中間值。不同的隊(duì)列長(zhǎng)度對(duì)應(yīng)不同的擁塞程度,交換機(jī)在反向ACK包上做標(biāo)記。這些標(biāo)記使用了網(wǎng)絡(luò)層包頭保留的8 bit的區(qū)分服務(wù)字段中的3個(gè)比特位,初始值為000,標(biāo)記的含義如表1所示。

表1 擁塞標(biāo)記的含義
3.2 發(fā)送端擁塞窗口的調(diào)整
假設(shè)收到的擁塞程度標(biāo)記值用θ表示,當(dāng)發(fā)送端收到交換機(jī)發(fā)送來(lái)的反饋信息后,根據(jù)標(biāo)記值的不同,按照不同的方式調(diào)整擁塞窗口:
(1)當(dāng)θ=000時(shí):如表1所示,θ=000表示網(wǎng)絡(luò)不擁塞,因此TCP的擁塞窗口按照標(biāo)準(zhǔn)TCP的算法調(diào)整。每收到一個(gè)ACK,按式(3)增加擁塞窗口。

(2)當(dāng)θ=001時(shí):如表1所示,θ=001表示網(wǎng)絡(luò)雖然不擁塞但是即將面臨擁塞,因此保持擁塞窗口大小不變,窗口變化如式(4)所示。

(3)當(dāng)θ=011時(shí):如表1所示,θ=011表示網(wǎng)絡(luò)處于嚴(yán)重?fù)砣麪顟B(tài),發(fā)送端將按照標(biāo)準(zhǔn)TCP的方式即式(5)調(diào)整擁塞窗口。

(4)當(dāng)θ=010時(shí):如表1所示,θ=010表示網(wǎng)絡(luò)處于擁塞階段,但是還沒(méi)有嚴(yán)重到(3)的程度,因此:

由于這時(shí)網(wǎng)絡(luò)擁塞程度介于(2)和(3)之間,因此 0.5≤k≤1,本文取一個(gè)中間值0.75。
3.3 發(fā)送端擁塞反饋通知
發(fā)送端收到中間交換機(jī)的擁塞通知后,為了防止中間交換機(jī)不停地發(fā)送反饋信息,可以發(fā)送一個(gè)擁塞反饋通知消息,標(biāo)記值為111。交換機(jī)收到該通知后,停止發(fā)送擁塞通知。當(dāng)擁塞程度發(fā)生變化的時(shí)候(比如從擁塞變?yōu)閲?yán)重?fù)砣?,再重新發(fā)送新的擁塞通知。
3.4 協(xié)議的理論分析
通過(guò)以上分析可知,F(xiàn)FDTCP協(xié)議相對(duì)簡(jiǎn)單,在保證低時(shí)延的情況下同時(shí)具有高吞吐量,具體特點(diǎn)如下:
(1)反饋迅速、準(zhǔn)確。中間交換機(jī)通過(guò)用3個(gè)比特位判斷擁塞信息可以快速地給發(fā)送端反饋。其延遲分析如下:在圖1中,DCTCP時(shí)延用 λ表示,λ1為A到B的鏈路時(shí)延,λ2為交換機(jī)B處的排隊(duì)時(shí)延,λ3為B到接收端C處的鏈路時(shí)延,λ4、λ5分別為反饋信息C到B和B到A的鏈路時(shí)延,由分析可知λ=λ1+λ2+λ3+λ4+λ5;用Ω表示FFDTCP的時(shí)延,則知道Ω=λ1+λ5;對(duì)λ和Ω進(jìn)行比較,顯然Ω<<λ,所以,F(xiàn)FDTCP能夠使反饋更迅速和準(zhǔn)確。
(2)簡(jiǎn)單。相比于DCTCP,F(xiàn)FDTCP算法只需要交換機(jī)判斷擁塞情況,發(fā)送端不需要估計(jì)計(jì)算;另外借助擁塞確認(rèn),使交換機(jī)能夠準(zhǔn)確地收到發(fā)送端發(fā)來(lái)的確認(rèn)擁塞信息,并且發(fā)送端窗口已經(jīng)做了相應(yīng)的調(diào)整。
(3)不額外占用網(wǎng)絡(luò)帶寬。交換機(jī)B給發(fā)送端A的反饋信息借助ACK包,從而節(jié)省了網(wǎng)絡(luò)帶寬。
4 模擬實(shí)驗(yàn)與結(jié)果分析
本文采用軟件NS2進(jìn)行模擬,模擬拓?fù)渑c圖1相同(這是一個(gè)典型的數(shù)據(jù)中心網(wǎng)絡(luò)),網(wǎng)絡(luò)環(huán)境參數(shù)鏈路帶寬設(shè)置為1 Gb/s,服務(wù)器請(qǐng)求單元為256 KB,交換機(jī)緩沖區(qū)大小分別為64 KB和128 KB,發(fā)送端分別運(yùn)行普通 TCP,DCTCP,F(xiàn)FDTCP,每次模擬運(yùn)行時(shí)間為100 s。
4.1 吞吐量分析
圖2和圖3為發(fā)送端分別運(yùn)行普通 TCP,DCTCP和FFDTCP時(shí)的吞吐量大小比較。
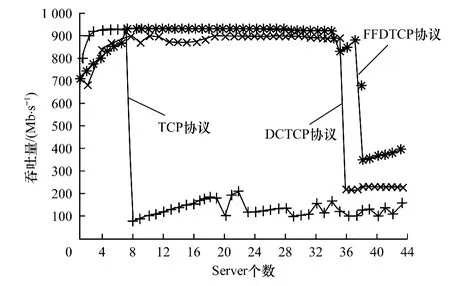
圖2 緩沖區(qū)為64 KB時(shí)3種協(xié)議的吞吐量比較

圖3 緩沖區(qū)為128 KB時(shí)3種協(xié)議的吞吐量比較
圖2為緩沖區(qū)大小為64 KB時(shí)3種協(xié)議下的吞吐量比較。通過(guò)圖2可以看出,當(dāng)Server個(gè)數(shù)增大到36之前,F(xiàn)FDTCP一直保持著比較高的吞吐量,吞吐量在Server個(gè)數(shù)為36時(shí)有所波動(dòng),Server個(gè)數(shù)大于36時(shí)吞吐量開始急劇下降;DCTCP在Server個(gè)數(shù)約為36時(shí)就出現(xiàn)吞吐量急劇下降的情況;TCP在Server個(gè)數(shù)為8時(shí)吞吐量就開始明顯降低了。同時(shí)可以看出當(dāng)Server個(gè)數(shù)為40時(shí),F(xiàn)FDTCP的吞吐量也開始急劇下降。這是由于當(dāng)Server的個(gè)數(shù)增加時(shí),即“多對(duì)一”模型中發(fā)送端數(shù)目偏大的情況下,緩沖區(qū)很快會(huì)被完全占據(jù),造成隨后的數(shù)據(jù)丟包以及數(shù)據(jù)重傳,從而降低了吞吐量。但FFDTCP吞吐量下降的幅度也比DCTCP和TCP的小,最后FFDTCP的吞吐量維持在300 Mb/s~400 Mb/s之間,DCTCP維持在250 Mb/s,TCP 維持在100 Mb/s~200 Mb/s。因此當(dāng)交換機(jī)緩沖大小為64 KB時(shí),與傳統(tǒng)TCP和DCTCP相比較,F(xiàn)FDTCP在吞吐量方面很好地解決了TCP Incast問(wèn)題。
圖3則是在交換機(jī)緩沖區(qū)大小為128 KB時(shí)進(jìn)行的仿真結(jié)果。從圖3可以看出,F(xiàn)FDTCP一直保持在900 Mb/s左右的吞吐量;DCTCP在Server超過(guò)36時(shí)吞吐量開始急劇下降;TCP在Server為16時(shí)吞吐量開始大幅度下降。可以看出在相同環(huán)境下,F(xiàn)FDTCP比DCTCP和TCP能保證更高的吞吐量。
從圖2和圖3的模擬結(jié)果中可以看出,瓶頸鏈路交換機(jī)緩沖區(qū)大小對(duì)解決TCPIncast問(wèn)題有一定影響。在同一交換機(jī)緩沖區(qū)下,相對(duì)于 TCP和DCTCP,F(xiàn)FDTCP能夠更好地解決TCPIncast問(wèn)題。例如,在128KB的緩沖區(qū)下,當(dāng)Server個(gè)數(shù)大于36時(shí),F(xiàn)FDTCP仍能夠保持高的吞吐量。其主要原因是FFDTCP通過(guò)中間交換機(jī)利用2個(gè)顯式通知位通告4種擁塞級(jí)別,發(fā)送端可以快速準(zhǔn)確地調(diào)整擁塞窗口,使擁塞窗口的變化不至于太激烈,加快恢復(fù)的速度;TCP在Server為16時(shí)吞吐量開始大幅度下降,主要原因是丟包導(dǎo)致TCP擁塞控制,發(fā)送窗口減半,降低發(fā)送速率,并且TCP擁塞控制后恢復(fù)較慢;DCTCP在Server個(gè)數(shù)為36之前能保持比較高的吞吐量,128 KB大的緩沖區(qū)起到比較關(guān)鍵的作用。在Server大于36時(shí)吞吐量開始大幅度下降,因?yàn)?比特位擁塞信息過(guò)于簡(jiǎn)單,使發(fā)送端不能及時(shí)準(zhǔn)確地調(diào)整擁塞窗口。而當(dāng)Server個(gè)數(shù)小于8時(shí),3種協(xié)議吞吐量方面并無(wú)很大差異主要原因是當(dāng)Server少時(shí),總的流量小,交換機(jī)的緩沖區(qū)不容易溢出,而且緩沖區(qū)隊(duì)列長(zhǎng)度一般小于 minth(所以 DCTPC,F(xiàn)FDTCP檢測(cè)不到擁塞),所以,3個(gè)協(xié)議的吞吐量相差不多。
4.2 時(shí)延分析
圖4則為發(fā)送端分別運(yùn)行普通TCP協(xié)議、DCTCP協(xié)議和FFDTCP在緩沖區(qū)為128 KB時(shí)的時(shí)延分析比較。

圖4 3種協(xié)議的時(shí)延比較
由圖4可以看出,當(dāng)Server個(gè)數(shù)大于25時(shí),DCTCP的時(shí)延開始增加,TCP的時(shí)延開始急劇增加。這是由于DCTCP采用顯式擁塞通知功能ECN,在判斷擁塞即將發(fā)生的時(shí)候,接收端通過(guò)標(biāo)記反饋給發(fā)送端擁塞信息,通知即將發(fā)生的擁塞,而普通擁塞控制算法TCP是根據(jù)丟包來(lái)判斷擁塞發(fā)生的。當(dāng)服務(wù)器數(shù)目超過(guò)40時(shí),F(xiàn)FDTCP還沒(méi)有受到TCP Incast問(wèn)題影響。而TCP和 DCTCP已經(jīng)出現(xiàn)了不同程度的時(shí)延。這是由于DCTCP擁塞信息太簡(jiǎn)單,只是根據(jù)一個(gè)隊(duì)列閾值發(fā)送單值擁塞信息,而且擁塞反饋慢,發(fā)送端不能及時(shí)調(diào)整擁塞窗口,從而容易造成交換機(jī)平均隊(duì)列長(zhǎng)度增加甚至緩沖溢出。而FFDTCP剛好在這方面有所改善,根據(jù)當(dāng)前交換機(jī)緩沖區(qū)檢測(cè)到的當(dāng)前隊(duì)列情況,可以發(fā)送多值擁塞信息,快速的通知發(fā)送端動(dòng)態(tài)地調(diào)整擁塞窗口,讓交換機(jī)隊(duì)列平均長(zhǎng)度處于一個(gè)較低的值,從而減小延時(shí)。
5 結(jié)束語(yǔ)
本文主要研究云計(jì)算數(shù)據(jù)中心網(wǎng)絡(luò)中的TCP Incast問(wèn)題。首先對(duì)相關(guān)背景進(jìn)行介紹,包括國(guó)內(nèi)外研究成果以及研究現(xiàn)狀進(jìn)行全面的綜述,然后針對(duì)數(shù)據(jù)中心網(wǎng)絡(luò)中的吞吐量急劇下降和時(shí)延問(wèn)題,在研究DCTCP的基礎(chǔ)上提出一種新的協(xié)議FFDTCP,并通過(guò)NS2仿真實(shí)驗(yàn)對(duì)該問(wèn)題的幾種解決方案進(jìn)行比較分析,發(fā)現(xiàn)FFDTCP能夠很好地解決TCP Incast問(wèn)題,并能提高數(shù)據(jù)中心網(wǎng)絡(luò)中傳輸協(xié)議的性能。下一步工作將增加評(píng)測(cè)的指標(biāo)和環(huán)境的復(fù)雜度,并考慮增加背景流量,構(gòu)建更符合實(shí)際網(wǎng)絡(luò)的評(píng)測(cè)環(huán)境。
[1] Alizadeh M,Greenberg A,Maltz D A,et al.Data Center TCP(DCTCP)[J].ACM SIGCOMM Computer Communication Review,2010,40(4):63-74.
[2] Phanishayee A,Krevat E,Vasudevan V,et al.Measurement and Analysis of TCP Throughput Collapse in Cluster-based Storage Systems[C]//Proceedings of the 6th USENIX Conferenceon Fileand Storage Technologies,F(xiàn)ebruary 26-29,2008,San Jose USA.Berkeley,USA:USENIX Association,2008:1-14.
[3] Rewaskar S,Kaur J,Smith F D.A Performance Study of Loss Detection/Recovery,in Real-world TCP Implementations[C]//Proceedings ofIEEE International Conference on Network Protocols.Washington D.C.,USA:IEEE Press,2007:256-265.
[4] Alizadeh M,Javanmard A,Prabhakar B.Analysis of DCTCP:Stability,Convergence,and Fairness[C]//Proceedings of ACM SIGMETRICS Joint International Conference on Measurement and Modeling of Computer Systems.New York,USA:ACM Press,2001:73-84.
[5] Wu Haitao,F(xiàn)eng Zhenqian,Guo Chuanxiong,et al.ICTCP:Incast Congestion Control for TCP in Data Center Networks[J].IEEE/ACM Transactionson Networking,2013,21(2):345-358.
[6] Alizadeh M,Atikoglu B,Kabbani A,et al.Data Center Transport Mechanisms:Congestion Control Theory and IEEE Standardization[C]//Proceedings of the 46th Annual Allerton Conference on Communication,Control,and Computing,October 1-5,2008,Allerton,USA.Washington D.C.,USA:IEEE Press,2008:1270-1277.
[7] McCanne S,F(xiàn)loyd S.Network Simulator——NS-2[EB/OL].[2014-03-15].http://www.isi.edu/nsnam/ns/.
[8] Ghemawat S,Gobioff H,Leung Shun-Tak.The Google File System[C]//Proceedings of ACM Symposium on Operating Systems Principles.New York,USA:ACM Press,2003:29-43.
[9] de Candia G,Hastorun D,Jampani M,et al.Dynamo:AmazonsHighly Available Key-value Store[C]//Proceedings of the 21st ACM Symposium on Operating Systems Principles,October 14-17,2007,Skamania Lodge,USA.New York,USA:ACM Press,2007:205-220.
[10] 李 震,杜中軍.云計(jì)算環(huán)境下的改進(jìn)型Map-Reduce模型[J].計(jì)算機(jī)工程,2012,38(11):27-29,37.
[11] Vasudevan V,Phanishayee A,Shah H,et al.Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication[C]//Proceedings of SIGCOMM’09,August 17-21,2009,Barcelona,Spain.New York,USA:ACM Press,2009:303-314.
[12] Podlesny M,Williamson C.An Application Level Solution for the TCP-incast Problem in Data Center Networks[C]//Proceedings of the 19th International Workshop on Quality of Service,June 16-18,2011,San Jose,USA.Washington D.C.,USA:IEEE Press,2011:1-23.
