基于圖模型和多分類器的微博情感傾向性分析
2015-01-02 02:01:02姬東鴻
計算機工程 2015年4期
黃 挺,姬東鴻
(武漢大學計算機學院,武漢430072)
1 概述
隨著網絡的普及和熱點輿論事件的網絡化,人們更加傾向于在互聯網上發表自己的個人觀點和看法,使得互聯網信息變得越來越豐富。這些信息不僅能幫助市場經濟的參與者加強服務質量,而且還能為決策者提供更多的決策信息。
文本的情感傾向性分析是指對包含用戶表示的觀點、喜好、厭惡和情感等主觀性文本進行情感分析。微博作為一種開放和即時性的信息傳播媒介,不僅需要對其進行安全監管,防止可能對社會造成負面的影響,而且還需要對微博內容進行二次開發,挖掘其中的海量信息便于更好服務大眾。最近這類的研究也比較多[1-2],例如文獻[3]重點考慮了連詞對句子情感極性分析的影響,結合短語和連詞分析句子情感極性。但系統依賴人工構建情感詞典,并且需要人工構建連詞規則,不具有領域適應能力。文獻[4]基于情感詞典擴展技術的網絡情感傾向分析,應用 HowNet[5]和 NTUSD[6]2 種資源對現有情感詞典進行擴展,建立了一個新的、具有傾向程度的情感詞典,但是建立的情感詞典不能完全反應特殊的微博語言環境。文獻[7]也提出一種融合最大熵模型和支持向量機模型兩者預測結果用于識別主觀句和褒貶極性分類問題的方法。
針對上述問題,本文提出基于圖模型識別情感詞語的情感傾向[8]和計算情感傾向度的方法,在此的基礎上利用條件隨機場模型[9]訓練和預測具體語境下的情感詞傾向[10],并結合支持向量機模型預測主客觀句和褒貶極性問題[11]。
2 情感詞典的構建和優化
2.1 圖模型
圖模型即表示為點和邊的集合,點代表著情感詞,邊代表情感詞對的潛在情感傾向相似關系,并用出現頻率表示其權值。
為了尋找潛在相似情感傾向的詞語對,需要在分詞和依存分析的基礎上進行如下步驟:
(1)通過依存關系分析,對于語法結構中依存于同一對象的修飾詞,認定為潛在相似情感詞對。例如“坑爹的國足,實在沒勁!”,其依存分析如圖1所示,雖然“坑爹”和“國足”之間沒有直接的依存關系,但是“的”沒有實際的語義作用,相當于“坑爹”和“國足”存在間接的依存關系,“坑爹”和“沒勁”都修飾“國足”且都有相同的依存關系,該語境下這對詞有相同的情感傾向。

圖1 依存關系示例
需要注意的是轉折連詞和轉折副詞可能會改變詞語對的相似性,此處采用的方法是出現就直接忽略,不作統計。
(2)對于同一個句子中多個并列結構短語的修飾詞,也認為是潛在相似情感詞對。例如“政客們的虛偽,統治者們的殘忍,民眾的盲從…”,在該語境下可認為虛偽、殘忍和盲從有著相似的情感傾向。
(3)同一句子中通過共現關系抽出用并列連詞連接的潛在相似情感詞對。例如“今年結了婚,又買了房子,感覺特別幸福和快樂!”,可以大致推斷“幸福”和“快樂”這組詞語在特定的環境下有著相同的情感傾向。
最終通過統計潛在相似情感詞對的出現頻率,如果超過X次則加入到圖模型中,并用出現頻率表示邊的權重。
通過新浪微博的API得到了大約10萬條微博數據進行上述規則的抽取,最終形成了如圖2所示的圖模型。
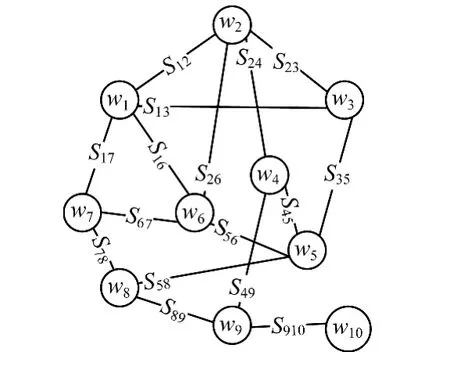
圖2 圖模型部分示例
2.2 種子詞
對上述微博語料進行處理之后(分詞,去掉停用詞,剪枝等),對潛在相似情感詞進行TF-IDF統計,具體公式如下:
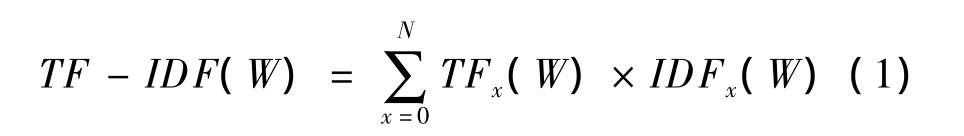
為了提高統計效果和精度,將同一話題的微博評論形成一個微博集合,其中,N表示微博集的數量,詞頻(Term Frequency,TF)表示詞語w在第N個微博集合中的出現頻率和語料中總出現頻率的比值,逆向文檔頻率(Inverse Document Frequency,IDF)表示微博集合數N和出現詞語w的微博集合數量比值的對數。
在TF-IDF值較高的詞語中人工挑選了40個情感詞作為情感基準詞[11],即非常典型而且確定只含褒義或者貶義的情感傾向詞。褒貶義情感基準詞如下:(1)褒義基準情感詞:大氣,出色,完美,漂亮,幸福,先進,優秀,文明,美麗,真實,可愛,健康,認真,美好,和平,贊美,積極,歡樂,頑強,開朗。(2)貶義基準情感詞:腐敗,非法,惡意,誹謗,浪費,變態,漏洞,欺詐,野蠻,陷阱,墮落,自大,貪污,色情,虛假,壓榨,惡魔,謊言,變態,造假。
2.3 情感傾向權值的計算
利用PageRank算法對形成的情感詞網絡進行情感詞評分。主要如下:
(1)把每個待預測情感詞賦予正負面2個情感度權值,分別表示它們正負面的情感強烈度,負值代表貶義傾向,正值代表褒義傾向。絕對值越大表示情感傾向越強,正負面情感詞權值在迭代過程中相互獨立。即:
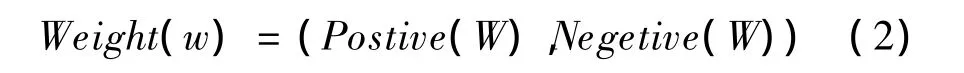
(2)情感基準詞只會向周圍傳遞它唯一的褒義或者貶義情感傾向權值,另一傾向權值始終設為0。例如“快樂”只有正面的含義,在負面傾向權值計算過程中,其負面權值始終為0,相當于在負面的計算過程中忽略了“快樂”這個詞對周圍相似情感詞的影響。而正面傾向權值計算過程方法不變。

其中,式(3)表示待預測情感詞之間關系出現的統計頻率;式(4)表示待預測情感詞正面的權值向量P第i次迭代的過程;式(5)表示待預測情感詞負面的權值向量N第j次迭代的過程。
初始化:
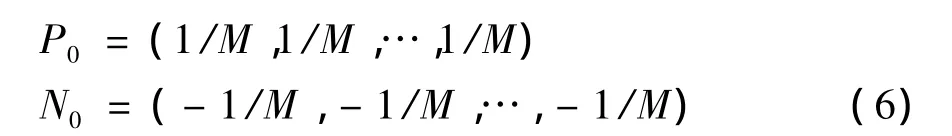
其中,M表示待計算的情感詞數量,以上對情感基準詞某一傾向歸零的處理相當于在該傾向計算過程中忽略該詞在圖中的影響作用,不會影響圖模型的收斂速度,所以通過多次的迭代之后,該方法最終會得到穩定的正負權值向量。
2.4 情感詞典優化
在之前計算結果的基礎之上對情感詞的情感權值進行標準化,通過式(7)、式(8)將其轉換至[-1,1]區間。
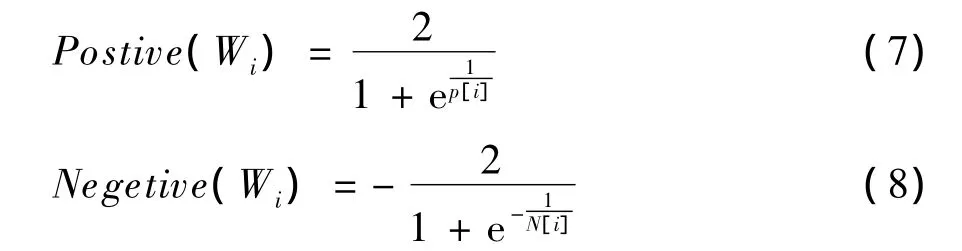
其中,P[i]和 N[i]分別表示情感詞的 Wi正負面情感權值,且不為0。式(7)、式(8)2個擠壓函數將初始的權值調整至[-1,1]區間,由于擠壓函數為S型增長函數,對少量初始權值絕對值較大或者較小的情況都有較好的控制作用。S型函數中間坡度較大,對兩者之間的大量中間情況有較好的區分度,所以此處的轉換具有較大的意義。
最后對情感權值的絕對值低于θ(0<θ<1)的情況,將情感權值歸0,視為無正面或負面的情感傾向,當其正負情感權值均為0時,將該詞從情感字典刪除,以提高圖模型的效果。
3 微博情感傾向分析
3.1 特征選擇
由于微博語句簡短,口語化較多,隨意性比較強,以及結構的不嚴謹性等特點,因此在特征提取時不僅要考慮到普通文本特征,還要提取一些專門針對微博語境的特征,具體的特征如表1所示。

表1 特征抽取項
3.2 褒貶極性分類
褒貶極性分類的主要流程如下:
(1)在前文建立的情感詞典基礎上,利用條件隨機場模型(Condition Random Field,CRF)對具體語境下的情感詞進行情感傾向預測。
具體語境下的情感詞情感傾向會隨著語境的變化而出現正負面變化,所以情感詞在語境中的實際傾向也可以作為褒貶分類的特征之一,并且在實驗中也證實了其重要性,對結果有較明顯的改善和提高。處理流程如圖3所示。
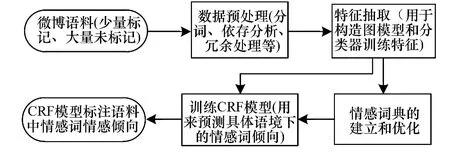
圖3 CRF情感詞標注處理流程
具體的CRF訓練預測流程如下:
1)根據圖模型和PageRank算法構建情感詞典和計算情感傾向權值。
2)預測過程:
①一條微博訓練語料;
②抽取該微博特殊句式、特殊符號、情感詞和特殊微博表情等特征;
③提取情感詞典中出現在該微博里的情感詞信息;
④將之前信息根據特征模板組成特征序列,特征序列包括表2中微博符號、表情和句式等在句子中的相對位置和特征編號,情感詞典中出現在該微博里的情感詞的情感傾向權值和在微博中相對位置,標注序列為人工標注的情感詞情感傾向。
3)將特征序列和標注序列整理成語料并作為輸入序列訓練CRF模型。
(2)結合語言特征和情感詞具體傾向,由支持向量機模型(Support Vector Machine,SVM)進行主客觀分類和情感傾向分類。
把CRF對情感詞的傾向預測結果也作為特征,結合特征抽取的特征集,對支持向量機模型進行訓練分類,當分類點到訓練模型的超平面距離為正值時,即為褒義的情感傾向微博,反之為貶義的情感傾向微博。
3.3 主客觀分類
有時可以直接對文本進行情感傾向性分類,但是如果能預測文本的主客觀情況,就可以在分類之前排除客觀語料,一定程度上提高情感傾向分析的性能,本文在主客觀文本分類上還是使用了之前的模型和方法,只是為了平衡數據結構,在測試集中添加了部分手工標注的客觀微博數據。經過主客觀分類之后的數據僅包含主觀的情感傾向數據,只需要進行二元分類就能得到最終的結果。具體流程和前面類似,不再贅述。
4 實驗及結果分析
4.1 語料預處理
在使用微博語料之前要對其進行語料預處理。本文的處理主要包括以下7點:(1)“#話題#”過濾;(2)“@昵稱”過濾;(3)鏈接過濾;(4)分詞;(5)停用詞處理;(6)網絡新詞、熱詞處理;(7)對語料進行依存分析。
4.2 訓練語料和測試數據
本文通過新浪微博API獲取大約10萬條未標記語料作為訓練圖模型的數據,再加上計算機學會中文情感傾向評測的標記數據選擇6 740條作為訓練語料,其中,正面3 532條;負面3 208條。另外還選擇5 021條作為測試語料,其中正面2 323條,負面2 198條,另外還人工標注了2 000條客觀微博數據作為主客觀分析的語料。
4.3 結果分析
實驗結果與分析如下:
(1)情感詞的正確率和覆蓋率,如圖4所示。
在情感權值計算的過程中會對情感絕對權值小于閾值θ的情感詞舍去,降低圖模型在計算迭代的過程中產生的干擾。圖4顯示了不同閾值對情感詞典正確率和覆蓋率的影響。
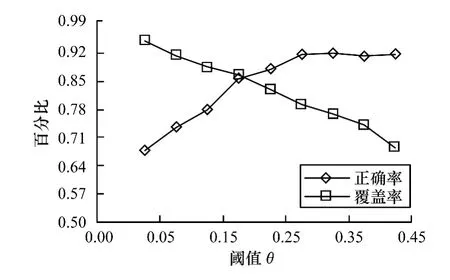
圖4 閾值θ的影響
覆蓋率是指測試文本中由圖模型得出的情感詞出現頻率和情感詞出現的總頻率比值。從圖4可以看出:閾值越大正確率越高,最后正確率會逐漸穩定到一個定值。而覆蓋率會隨著閾值上升而逐漸降低,所以綜合考慮將閾值設置在0.18比較合適。
(2)潛在相似情感詞詞頻閾值X對最終傾向分析準確性的影響,如圖5所示。
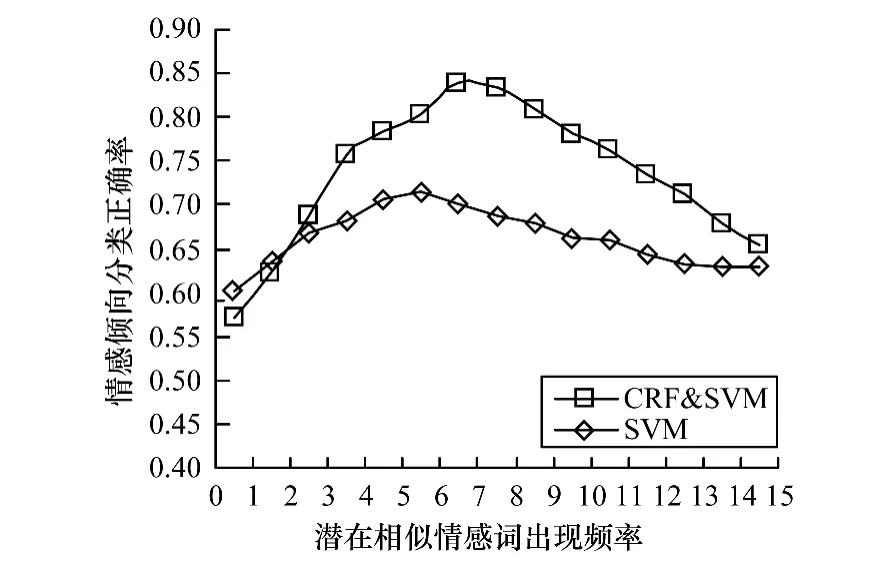
圖5 閾值X對結果的影響
潛在相似情感詞詞頻的閾值會影響到圖模型中節點和邊的數量,從而影響最終的情感詞典和權值,進而影響結果,從實驗數據來看,最后的正確率首先會受到詞頻的增大而增加,到達峰值后,由于詞頻過大導致限制嚴格,最終效果反而下降。
(3)微博特征對情感傾向分類的影響,如圖6所示。圖6表示對應表2各特征項當其缺省時的最終正確率。可知情感權值、特殊句式和網絡流行語等對效果有更顯著的影響作用。
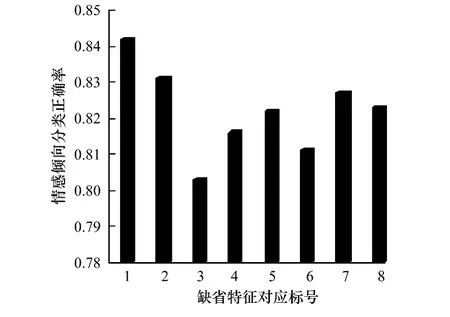
圖6 各缺省特征對結果的影響
(4)主客觀分類結果如表2所示。
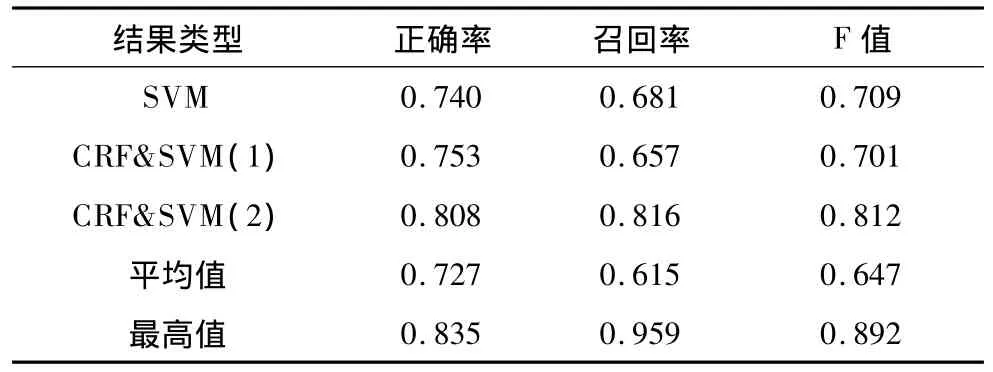
表2 主客觀分類結果
其中,CRF&SVM(1)表示使用臺灣大學情感詞典的實驗結果;CRF&SVM(2)表示使用本文方法建設情感詞典得出的結果,平均值和最高值均參考2013年CCF中文情感評測的結果。
(5)情感傾向分析的結果如表3所示。

表3 情感傾向分類結果
從表3數據可以看出:CRF預測情感詞傾向加上SVM情感傾向分類的方法比僅僅使用SVM模型效果明顯有提升,這是因為情感詞典只是整個微博環境下情感詞的傾向分布,而CRF模型能夠利用特征之間的序列關系和微博情感詞的傾向分布較好的預測具體語境下的情感詞傾向,這對之后的情感傾向分類有比較積極的作用,一定程度上提高了傾向分類預測的準確率。
另外本文方法通過使用普通情感詞典和本文建立的情感詞典的比較可知利用微博數據建立的情感詞典更具有領域適應性,分類預測效果更好。但是實驗效果離最高值還有一定的距離,還需要不斷努力和改進。
5 結束語
本文利用情感詞之間的相互關系,建立一個包含情感詞及其關系的圖模型,采用PageRank算法計算情感詞的正負情感傾向權值,并結合其他特征利用CRF模型進行具體語言環境下的情感詞傾向預測,并以此為基礎采用SVM模型來預測句子的主客觀性和褒貶極性。在普通的微博語料中,本文方法都獲得較好的效果。下一步將在本文情感詞典建設的基礎上豐富詞典和提高精確度,繼續對使用的分類方法進行優化,并嘗試結合其他算法進行情感傾向分析。
[1] 周立柱,賀宇凱,王建勇.情感分析研究綜述[J].計算機應用,2008,28(11):2725-2728.
[2] 周勝臣,瞿文婷,石英子,等.中文微博情感分析研究綜述[J].計算機應用與軟件,2013,30(3):161-164.
[3] Meena A,Prabhakar T,Amati G,et al.Sentence Level Sentiment Analysis in the Presence of Conjuncts Using Linguistic Analysis[C]//Proceedings of Advances in Information Retrieval.Berlin,Germany:Springer,2007:573-580.
[4] 楊 超,馮 時,王大玲,等.基于情感詞典擴展技術的網絡輿情傾向性分析[J].小型微型計算機系統,2010,4(4):691-695.
[5] 朱嫣嵐,閔 錦,周雅倩,等.基于HowNet的詞匯語義傾向計算[J].中文信息學報.2006,20(1):245-251.
[6] 楊昱昺,吳賢偉.改進的基于知網詞匯語義褒貶傾向性計算[J].計算機工程與應用,2009,45(21):91-93.
[7] 劉志廣,董喜雙,關 毅.基于分類器融合的中文微博情感傾向性研究[C]//2012年第一屆自然語言處理與中文計算會議論文集.北京:[出版者不詳],2012.
[8] 傅向華,劉 國,郭巖巖,等,中文博客多方面話題情感分析研究[J].中文信息學報,2013,27(1):47-55.
[9] 楊 源,林鴻飛.基于產品屬性的條件句傾向性分析[J].中文信息學報,2011,25(3):86-92.
[10] 王 勇,呂學強,姬連春.基于極性詞典的中文微博客情感分類[J].計算機應用與軟件,2014,31(1):34-37.
[11] 趙 煜,蔡皖東,樊 娜,等.利用詞匯分布相似度的中文詞匯語義傾向性計算[J].西安交通大學學報,2009,20(06):33-37.
[12] 聞 彬,何婷婷,羅 樂,等.基于語義理解的文本情感分類方法研究[J].計算機科學,2010,37(6):261-264.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
