
基于多特征的視頻中單人行為識(shí)別
2015-01-04 08:51:26胡興旺祁云嵩袁玉龍
電子設(shè)計(jì)工程 2015年12期
胡興旺,祁云嵩,袁玉龍
(江蘇科技大學(xué) 計(jì)算機(jī)科學(xué)與工程學(xué)院 江蘇 鎮(zhèn)江 212003)
人體行為識(shí)別技術(shù)主要包括人體目標(biāo)識(shí)別、人體跟蹤與行為識(shí)別三個(gè)方面。其中,行為識(shí)別是基于前兩者的更高級(jí)別的計(jì)算機(jī)視覺(jué)部分。研究出一種健壯的行為識(shí)別算法具有重要的理論意義與廣泛的應(yīng)用前景,其中包括智能視頻監(jiān)控、視頻檢索、人機(jī)交互等領(lǐng)域,因此行為識(shí)別領(lǐng)域受到廣泛學(xué)者的關(guān)注[1-3]。而研究的難點(diǎn)主要體現(xiàn)在運(yùn)動(dòng)背景復(fù)雜、行為多變、數(shù)據(jù)量大、實(shí)時(shí)性要求高等方面。行為識(shí)別流程包括了人體的檢測(cè)與跟蹤、特征提取和行為識(shí)別三個(gè)重要環(huán)節(jié)。本文通過(guò)提取屬性,得到動(dòng)作單元,用這些動(dòng)作單元的序列組成動(dòng)作。本文僅僅找了一個(gè)方法在一個(gè)視頻集上將這些動(dòng)作區(qū)分開(kāi)了,并沒(méi)有到動(dòng)作理解的層次。同時(shí)很難運(yùn)用到現(xiàn)實(shí)中的異常行為檢測(cè)方面。
1 前景提取
1.1 相鄰幀差法
該方法是從第二幀開(kāi)始,將當(dāng)前幀減去前一幀得到前景(如圖1)。由于幀差法是相鄰兩幀想減,易產(chǎn)生空穴。并且當(dāng)前景靜止的時(shí)候,很容易導(dǎo)致前景消失[4]。
1.2 混合高斯模型
背景建模過(guò)程如下:
1)高斯分布模型匹配
2)高斯分布模型的更新
在處理前L個(gè)樣本的時(shí)候,使用以下的更新方程:

當(dāng)達(dá)到L個(gè)樣本的時(shí)候使用以下的更新方程:
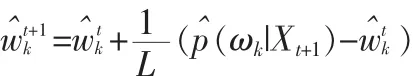
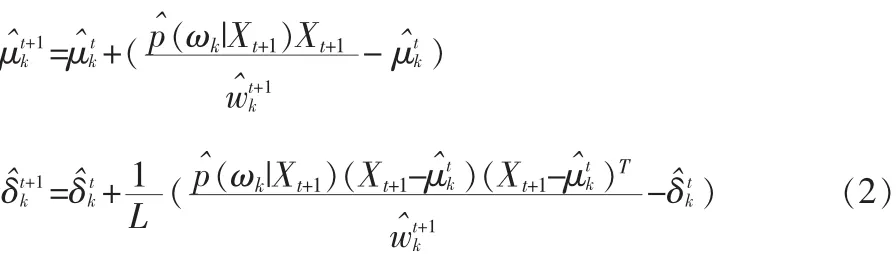
如果 ωk是第一個(gè)滿足的高斯分布,p^(ωk|Xt+1)=1,否則p^(ωk|Xt+1)=0。
3)生成背景模型
重新對(duì)混合高斯分布按優(yōu)先級(jí)ρi,t由大到小排列,取前B個(gè)高斯分布聯(lián)機(jī)的生成背景:

4)陰影去除
1.3 平均背景法提取前景(AVG)
前景提取[5-6]:
1)將前景圖像減去背景圖像。
如果亮度或色度分別大于一定的閾值則認(rèn)為他們屬于前景部分否則為陰影部分。
3)在將之前的HSV空間的圖像轉(zhuǎn)到RGB空間diffRGB

圖1 視頻前景提取對(duì)比圖Fig.1 Video prospects extract comparison chart
2 前景處理
為了得到較好的連通的前景又不引入過(guò)多的噪聲,將FD、MOG、AVG三者得到的前景做相應(yīng)的處理后相加,然后再進(jìn)行濾波、去噪等一系列的操作。將過(guò)小的以及過(guò)大的連通區(qū)域去除,并將連通區(qū)域過(guò)多的幀去除。為了得到整個(gè)人體的屬性,需要將人進(jìn)入視頻以及離開(kāi)視頻時(shí)導(dǎo)致不完整人體的視頻幀去掉。對(duì)處理過(guò)后的視頻將前面以及后面空的視頻幀去除。
3 屬性提取
在處理后的視頻上提取時(shí)空屬性、姿勢(shì)屬性等十個(gè)屬性。提取的屬性以及屬性的組合有:1)pos(位置分布)2)size(大小分布)3)maindir(由邊緣方向直方圖得到的主方向)4)maindirSD (主方向的標(biāo)準(zhǔn)差)5)speed(速度)6) 速度方差(speedSD)7)hchange(高度變化)8)hchangeSD(高度變化標(biāo)準(zhǔn)差)9)wchange(寬度變化)10)wchangeSD(寬度變化標(biāo)準(zhǔn)差)
視頻采樣集合 VSample={f1,f2,…,fT},第 t個(gè)視頻采樣幀ft中的連通域集合為CASet(t)={ca(t)1,ca(t)2,…,ca(t)nt}
1)pos屬性的提取
pos屬性的求取如下:①初始化pos矩陣,pos=[0]height*width.
②對(duì)于新的視頻采樣幀,計(jì)算其質(zhì)心 CEN(CASet(t))=[y(t)c,y(t)c],并更新pos矩陣。
2)size屬性的提取
對(duì)于新的采樣視頻計(jì)算其前景大小BOX(CASet(t))=[x1(t)b,y1(t)b,x2(t)b,y2(t)b],并更新size矩陣。
3)maindir屬性的提取
每一個(gè)視頻采樣幀的maindir屬性是該視頻中的前景輪廓的邊緣方向的加權(quán)和。視頻采樣集的maindir屬性該集合中所有視頻幀的maindir的平均值。
4)maindirSD屬性的提取 maindirSD 取 maindir(fi)的標(biāo)準(zhǔn)差
5)speed 屬性的提取
設(shè)t時(shí)刻視頻采樣幀的質(zhì)心為CEN(CASet(t))=[x(t)c,y(t)c],t-1時(shí)刻的質(zhì)心為CEN(CASet(t-1))=[x(t-1)c,y(t-1)c],則視頻采樣集的speed屬性是相鄰兩個(gè)視頻采樣幀之間質(zhì)心速度的平均值。
6)speedSD 屬性的提取 speedSD 取 speed( ftft-1)的標(biāo)準(zhǔn)差
7)hchange屬性的提取
設(shè)t時(shí)刻的包圍盒為BOX(CASet(t))=[x1(t)b,y1(t)b,x2(t)b,y2(t)b],t-1時(shí)刻的包圍盒為BOX(CASet(t-1)=[x1(t-1)b,y1(t-1)b,x2(t-1)b,y2(t-1)b]),則視頻采樣集的hchange屬性是相鄰兩個(gè)視頻采樣幀中前景包圍盒高度差的平均值。
8)hchangeSD 屬性的提取 hchangeSD 取 hchange( ftft-1)的標(biāo)準(zhǔn)差
9)wchange屬性的提取
10)wchangeSD 屬性的提 wchangeSD 取 wchange( ftft-1)的標(biāo)準(zhǔn)差
經(jīng)過(guò)以上10種屬性的提取,可以將每一個(gè)視頻表征為一個(gè)屬性向量 F=[pos,size,md,mdSD,s,sSD,hc,hcSD,wc,wcSD]
4 分 類
將視頻集分為兩部分,一部分用于訓(xùn)練,一部分用于測(cè)試。第i類的特征平均值表示如下:
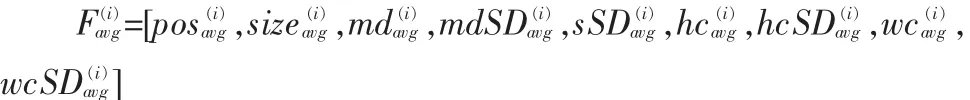
根據(jù)十種屬性定義一下13種距離。
測(cè)試集中的第j個(gè)視頻到第i類的pos距離:
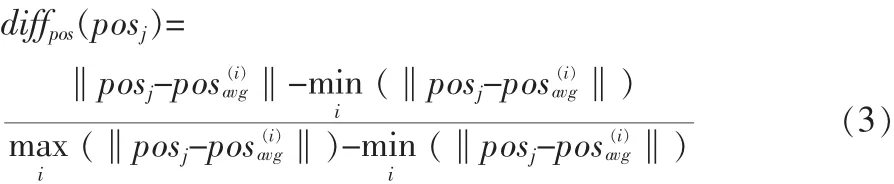
測(cè)試集中的第j個(gè)視頻到第i類的size距離為:

測(cè)試集中的第j個(gè)視頻到第i類的dir距離為:
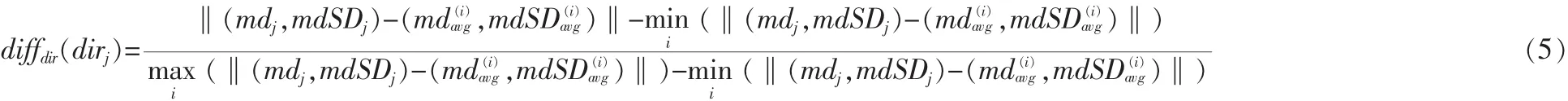
測(cè)試集中的第j個(gè)視頻到第i類的maindir距離為:
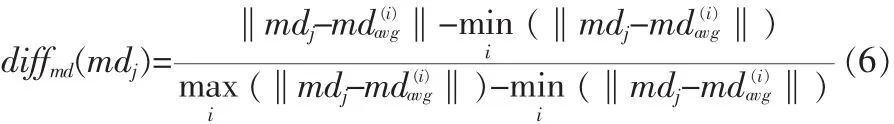
測(cè)試集中的第j個(gè)視頻到第i類的maindirSD距離為:

測(cè)試集中的第j個(gè)視頻到第i類的speed距離為:
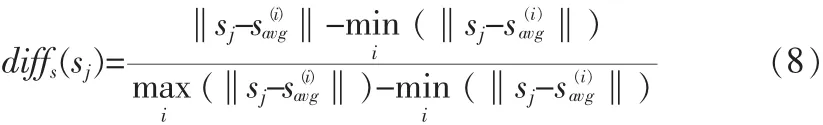
測(cè)試集中的第j個(gè)視頻到第i類的speedSD距離為:

測(cè)試集中的第j個(gè)視頻到第i類的sizechange距離如式(10):
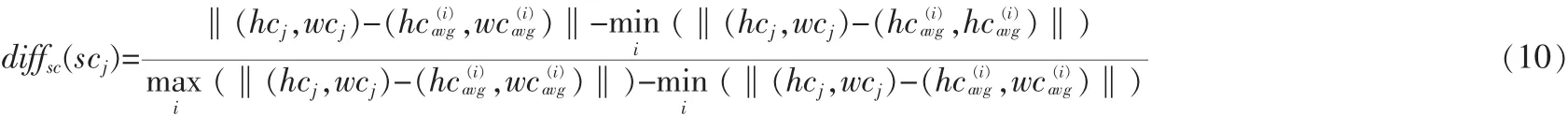
測(cè)試集中的第j個(gè)視頻到第i類的sizechangeSD距離如 式(11):
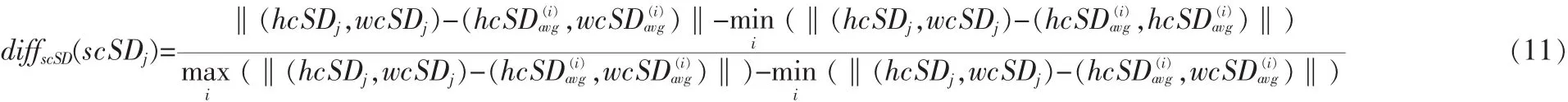
測(cè)試集中的第j個(gè)視頻到第i類的hchange距離為:

測(cè)試集中的第j個(gè)視頻到第i類的hchangeSD距離為:
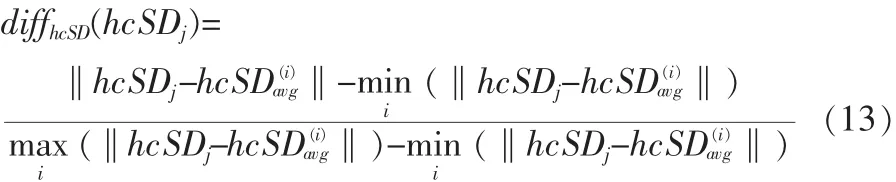
測(cè)試集中的第j個(gè)視頻到第i類的wchange距離為:
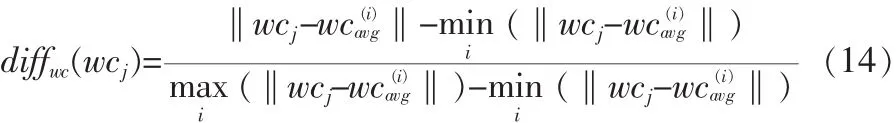
測(cè)試集中的第j個(gè)視頻到第i類的wchangeSD距離為:

分類算法定義如下:
1)單獨(dú)對(duì)各個(gè)距離采用最近鄰方法進(jìn)行分類。然后選出識(shí)別率大于0.4的距離,并記下它們的識(shí)別率。以這些距離的識(shí)別率為權(quán)重的加權(quán)和為分類的距離
2)對(duì)測(cè)試集中的任意一個(gè)視頻,計(jì)算他們的距離。從這些距離中選出最小的一個(gè),并把該視頻分為與之為最小距離的那一類的同類。
5 實(shí) 驗(yàn)
在CASIA行為分析數(shù)據(jù)庫(kù)上進(jìn)行了實(shí)驗(yàn)。CASIA行為分析 數(shù) 據(jù) 庫(kù) 定 義 了 bend、car、crouch、faint、jump、run、walk、wonder8種行為。由于CASIA行為分析數(shù)據(jù)庫(kù)中的類別為car的行為樣本數(shù)太少不具有統(tǒng)計(jì)特征,故將其去除。
各個(gè)屬性在CASIA行為分析數(shù)據(jù)庫(kù)上的識(shí)別率如下圖所示。
如圖 2和圖3其中識(shí)別率大于 0.4的距離有 duffpos、difsize、diffdir、diffs, 他 們 的 識(shí) 別 率 分 別 為 49.62% 、63.27% 、45.19%、51.92%。
以此為分類距離的十次分類結(jié)果如表1所示。
十次分類的混淆矩陣為:

圖2 各距離識(shí)別率Fig.2 Each distance recognition rate

圖3 加權(quán)距離的識(shí)別率Fig.3 Recognition rate weighted distance

表1 分類結(jié)果Tab.1 Results of Classification
如圖 4 所示由于 run、jump、walk 在屬性 pos、size、speed、dir上的值相差不大,再加上前景提取的噪聲,他們的識(shí)別率并不是很高。
6 結(jié) 論
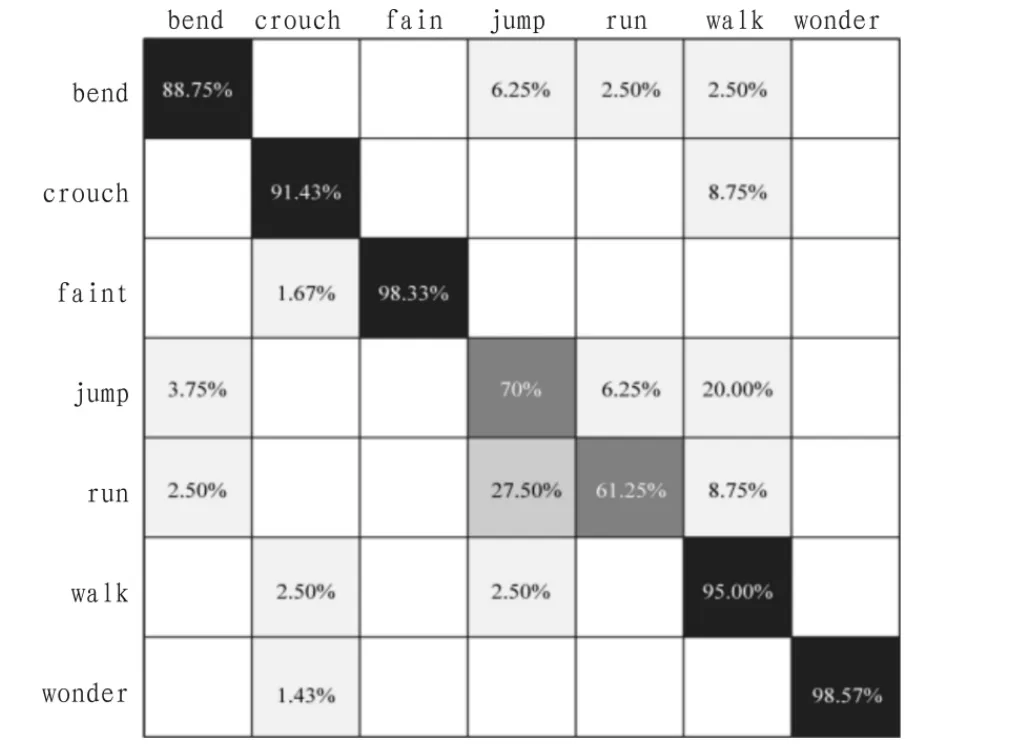
圖4 實(shí)驗(yàn)結(jié)果Fig.4 Result of the experiment
本文本論文圍繞智能視頻監(jiān)控相關(guān)的關(guān)鍵技術(shù)展開(kāi)研究,研究?jī)?nèi)容涉及運(yùn)動(dòng)目標(biāo)的檢測(cè)、人體運(yùn)動(dòng)特征的描述和識(shí)別方法等。具有一定的理論研究?jī)r(jià)值和現(xiàn)實(shí)的應(yīng)用意義。通過(guò)在視頻的基礎(chǔ)上提出位置分布圖、大小分布圖等一系列的屬性將單人的行為進(jìn)行分類。并取得了不錯(cuò)的分類結(jié)果。
[1]杜友田,陳峰.基于視覺(jué)的人的運(yùn)動(dòng)識(shí)別綜述[J].電子學(xué)報(bào),2007,35(1):84-90.DU You-tian,CHEN Feng.Summary of visual recognition based on the movement of people[J].Journal of Electronic,2007,35(1):84-90.
[2]Ronald Poppe.A survey on vision-based human action recognition Image and Vision Computing [J]Computer Engineering and Design,2010,28(6):976-990.
[3]Aggarwal J K,Cai Q.Human motion analysis:A review Computer Vision and Image Understanding[J].Electronic Measurement Technology,1999,73(3):428-440.
[4]Jolly M P D,Lakshmanan S,Jain A K.Vehicle segmentation and classification using deformable templates[J].IEEE Trans.on PAMI,1996,18(3):293-308.
[5]Yilmaz A,Li X,Shah M.Contour-based object tracking with occlusion handling in video acquired using mobile cameras[J].IEEE Trans.on PAMI,2004,26(11):1531-1536.
[6]Marc Niethammer,Allen Tannenbaum,Sigurd Angenent.Dynamic active contours for visual tracking[J].IEEE Trans.on Automatic Control,2006,51(4):562-579.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
建材發(fā)展導(dǎo)向(2021年6期)2021-06-09 05:57:08
大眾健康(2021年6期)2021-06-08 19:30:06
現(xiàn)代國(guó)際關(guān)系(2021年2期)2021-04-13 01:59:16
今日農(nóng)業(yè)(2020年17期)2020-12-15 12:34:28
中國(guó)外匯(2019年11期)2019-08-27 02:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
太空探索(2016年10期)2016-07-10 12:07:01

- 電子設(shè)計(jì)工程的其它文章
- 英飛凌推出具有智能保護(hù)功能的智能功率模塊MIPAQTM Pro,助力開(kāi)發(fā)緊湊可靠的物聯(lián)網(wǎng)逆變器
- 安森美半導(dǎo)體推出全系列雙倍數(shù)據(jù)速率(DDR)終端穩(wěn)壓器
- Imagination發(fā)布可實(shí)現(xiàn)下一代SoC安全性的OmniShield技術(shù)
- 36V、800mA堅(jiān)固型線性穩(wěn)壓器具有擴(kuò)展的SOA并提供了簡(jiǎn)單的三端操作
- 英飛凌推出新款大功率光觸發(fā)晶閘管 首次集成保護(hù)功能
- Imagination的ClearCallTM VoIP應(yīng)用現(xiàn)可支持Cavium的OCTEON? Ⅲ多核處理器