一種網格k-近鄰集的邊界點識別算法
2015-03-11 03:29:35李光興
艦船電子工程 2015年7期
李光興
(成都農業科技職業學院基礎部 成都 611130)
?
一種網格k-近鄰集的邊界點識別算法
李光興
(成都農業科技職業學院基礎部 成都 611130)
為了高效識別聚類邊界,根據邊界周圍區域存在密度差異的特征,提出了一種網格k-近鄰集的邊界識別算法(BGN)。在網格空間中,該算法根據網格單元和它最近鄰居單元的k-近鄰集的質量及其單元間中心距離確定邊界度,由邊界度和邊界閾值判斷每個網格單元是否為邊界單元或噪聲單元。通過從邊界單元中提取更靠邊緣的數據作為邊界點的方式,使得邊界更精細。實驗結果表明,該算法能有效和快速識別出多密度數據集的聚類邊界和噪聲。
網格單元;k-近鄰集; 邊界度; 邊界點; 噪聲
Class Number TP311
1 引言
邊界點是指位于不同密度數據區域邊緣的數據對象,邊界就是邊界點的集合[1]。邊界反映了數據的分布特征和結構信息,同時也提供了一種有用的模式,如果數據分布的邊界確定了,那么就可以根據邊界對數據聚類或分類[2~4]。邊界識別研究有助于提高聚類的精度以及分類的準確度。另外,邊界識別也是圖像處理和數據分析的有用手段[5~7]。
DBSCAN是基于密度的聚類算法[8],它定義了聚類的邊界點,如果一個對象不是核心對象,且它對某個核心對象是直接密度可達,則該對象為邊界點。由于識別的邊界點與全局參數密切相關,不能有效識別多密度數據集的邊界點,算法時間復雜度較高,為O(nlogn)(n是數據規模的大小)。BORDER算法[1]是基于密度的邊界點識別算法。若一個對象p在某個對象o的k-近鄰中,則稱對象o是對象p的反向k-近鄰。利用邊界點的反向k-近鄰個數一般小于處于聚類內部對象的反向k-近鄰的個數思想來識別邊界點。數據集的所有對象按它的反向k-近鄰數從小到大排列順序,并把前w個對象作為邊界點。因為噪聲和聚類內部的一些點的反向k-近鄰數可能少于邊界點的反向k-近鄰數,所以該算法不能正確地從多密度和帶噪聲的數據集中提取聚類的邊界點。另外,參數w的多寡取舍比較困難。算法時間代價也較高為O(kn2)。BDKD算法[9]用基于密度的聚類思想,把數據對象的k-近鄰距離與其鄰域內數據對象的平均k-近鄰距離之比定義其k-離群度,對k-離群度超過閾值的數據對象規定為邊界點。但時間復雜度為O(kn2)消耗不低。
BOURN算法[10]是根據數據分布的統計信息來識別邊界模式的算法,由數據分布的均值和方差定義數據對象的邊界度,按邊界度的大小對數據集降序排列,選取前w個邊界度最大的對象作為邊界點輸出。雖然該算法在含有噪聲的數據集上能有效地識別出邊界點,但參數選擇較困難,算法的執行效率不高,時間復雜度與DBSCAN相當。在基于網格聚類的算法中,文獻[11~12]只考慮了識別低密網格聚類的邊界點,并沒有給出提取所有聚類邊界點的策略。
BPGG算法[13]是基于網格的邊界識別算法。該算法的思路是:當一個網格處在類的邊界區域時,其梯度會明顯大于那些處在類內部的網格的梯度。算法首先通過卷積運算定義網格梯度,運用梯度算子,近似求出網格所對應的每一個維的梯度值,然后從中選取絕對值最大的梯度值與給定閾值比較確定邊界網格,再把邊界網格中的對象標記為邊界點。算法的不足是運算較復雜,且把邊界網格中的數據點都作為邊界點,得到的邊界較粗糙精度不高。文獻[14]提出了一種基于網格的邊界點識別算法,利用相鄰網格單元間的數據分布關系識別邊界單元和邊界點。但由于邊界識別過程中只分析了單元和相鄰單元小范圍內的數據分布信息,因而結果受網格劃分方法和劃分數量的影響較大。
為克服現有邊界識別算法難以有效地對帶噪聲的多密度和大數據集的聚類進行邊界識別,絕對參數選擇困難以及精度和效率低的缺點,減少基于網格的邊界識別算法中網格劃分方法對結果影響,提出一種網格k-近鄰集的邊界點識別算法(The boundary point recognition algorithm for Gridk-nearest neighbor set,BGN)。
2 相關概念
2.1 網格單元和k-近鄰集
S=A1×A2×…×Am是一個m維數據空間,其中Aj(j=1,2,…,m)是第j個屬性的有界定義域,X={x1,x2,…,xn}是包含n個數據點的m維空間中的數據集,數據點xi=(xi1,xi2,…,xim)(i=1,2,…,n),其中xij∈Aj,每個數據點的質量規定為1,一個數據集的質量就是這個數據集中的數據點數。
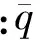
定義2 給定近鄰距離k,若p和q是非空單元,p與q的幾何中心歐式距離rqp不超過k,除j維外其它各維p與q的劃分區間相同。
1) 當p在j維的劃分區間的左端點大于或等于q在j維劃分區間的右端點,則稱p是q的j維右鄰居,與q的幾何中心距離最短的j維右鄰居,稱為q的j維最近右鄰居。
2) 當p在j維劃分區間的右端點小于或等于q在j維劃分區的左端點,p與q在其它各維的劃分區間相同,則稱p是q的j維右鄰居,與q的幾何中心距離最短的j維左鄰居,稱為q的j維最近左鄰居。
從定義可知,若p是q的j維最近左鄰居,則q是p的j維最近右鄰居。一個非空單元在某維不一定有鄰居單元。
定義3 單元q的k-近鄰集k{q}是由單元q和它的各維左右鄰居組成。k{q}的質量N(k{q})為它所含的各單元質量的和。

圖1 k-近鄰集圖
并不是所有與單元q的幾何中心距離小于k的單元都是k{q}的元素,而只有那些沿維軸正負方向q的鄰居,才成為k{q}的元素,這樣規定能減少算法的復雜度。如圖1,取近鄰距離k為單元劃分區間長度的三倍,則k{q}={a,q,b,c,d,e,f},單元a,b,e是q單元的最近鄰居,N(k{q})=10。
2.2 邊界度與邊界單元

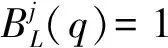
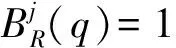
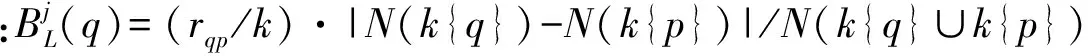
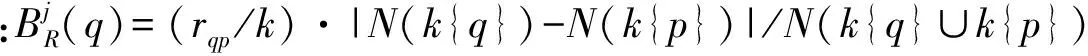
定義中|N(k{q})-N(k{p})|/N(k{q}∪k{p})為k{q}的質量與k{p}的質量差的絕對值比k{q}與k{p}并集的質量,值越大表明k{q}與k{p}分布密度相對差越大。rqp/k越大表明p與q相距越遠。邊界度的范圍為[0,1]。
顯然,如果p是q的j維最近左鄰居,q是j維右邊界單元,那么p是j維右邊界單元。如果p的j維無左(右)鄰居,則p是j維左(右)邊界單元。

噪聲單元實質上是一種特殊的邊界單元,它對每一維的左右兩個方向而言都是邊界單元,或者說噪聲單元與它的任意一維的最近左或右鄰居都不是同類,因而噪聲單元又可看成是孤立單元。不是噪聲單元的邊界單元稱為非噪聲邊界單元。
3 BGN邊界點識別算法
3.1 邊界的細化

3.2 BGN邊界點識別算法步驟
BGN邊界點識別算法包括網格劃分、數據映射,確定k-近鄰集和邊界度,判斷邊界單元或噪聲單元,提取邊界點和噪聲等過程。具體步驟如下:
輸入 數據集X,每維網格劃分區間數t,近鄰距離k,邊界閾值h
輸出 邊界點和噪聲
步驟1 將數據空間S劃分為網格單元,確定網格單元的中心,并將數據集X映射到網格單元中,統計和計算非空網格單元的質量和質心。
步驟2 查找每個非空單元的k-近鄰集。
步驟3 計算每個非空單元的每一維的左右邊界度,根據定義5判斷單元是否是邊界單元。
步驟4 根據定義6從邊界單元中找出噪聲單元,提取噪聲數據。
步驟5 提取非噪聲邊界單元中的初邊界點。
步驟6 按邊界細化的方法提取非噪聲邊界單元中的細邊界點。
步驟7 輸出噪聲數據、初邊界點和細邊界點,算法結束。
網格劃分一般可按平均每個網格單元的數據不少于一個來確定每維劃分數。近鄰距離k一般取單元劃分區間長度的倍數。邊界度是一種相對數,比采用絕對數來說,更容易確定邊界閾值h,一般取為0 3.3 算法復雜度分析 m維數據空間中有n個數據,劃分網格并將數據投影到網格中,掃描網格空間一次,統計單元的數據數量,時間復雜度為O(2n)。一個k-近鄰集最多只有2km個元素,計算非空單元d(d≤n)的邊界度,時間復雜度為O(2kmd),對邊界單元進行細化處理,其時間復雜度為O(md),所以BGN整個算法的時間復雜度為O(2n+(2k+1)md),算法的時間復雜度與數據規模呈線性關系。 4.1 算法性能實驗 比較BGN與BORDER的時間效率。九個數據集分布為正六形。BGN邊界閾值h=0.32。BORDER實驗參數為近鄰居數10,在相同數據規模情況下,取BORDER邊界點數量與BGN算法識別的初邊界點數相同。 不同數據規模的數據集的分布結構不一樣,因而識別的邊界點數也不相同。從表1可見,數據量遞增時GAB算法的時間復雜度呈線性增長,執行時間遠遠低于BORDER,具有良好的數據規模可擴展性。 表1 BORDER與BGN數據規模執行時間比較 4.2 算法有效性對比實驗 試驗1 二維數據集呈葉形分布(圖2(a)),共16666個數據。BGN每維網格劃分區間數為t=129,共劃分成8281單元,邊界閾值0.23。BGN識別出邊界單元838個,共有1066個初邊界點(圖2(c)),經過細化后邊界點精減為745個(圖2(d)),邊界更精致平滑,如葉柄部分邊界更清楚。識別出分布于葉邊緣的10個噪聲點。BORDER參數為近鄰個數12,邊界點數為900。從圖2(b)中可見,BORDER算法的效果沒有BGN好,表現在葉形外圍邊界完整性差,丟失了較多的外圍邊界點,因為葉內部的一些點的反向k-近鄰個數比聚類邊界點的反向k-近鄰個數還少,所以葉內部的這些點也被當作邊界點。 圖2 葉型邊界識別比較 試驗2 二維多密度數據集包含13885個數據,分布形成“花”型(圖3(a))。構成花(數據量13728個)的花瓣、花蕊、葉及枝等部分密度不同,形狀各異。分布在花周圍有157個隨機離散點。 BORDER參數為近鄰個數30,邊界點2200個。BGN每維網格劃分區間數為t=117,邊界閾值0.16。BGN識別出邊界單元1778個,共有3028個初邊界點(圖3(c)),經過細化后邊界點精減為1935個(圖3(d))。識別出噪聲數據150個(圖3(e))。從圖3可見,BORDER識別出構成“花”的花瓣、花蕊、葉及枝等部分外圍邊界完整性較差,沒能把噪聲點與邊界點相區分。BGN能較完整地識別出構成“花”的各部分邊界和分布在“花”周圍的小聚類邊界,有效地去除了噪聲。經細化后的邊界更清晰簡潔。這說明BGN算法邊界點的識別效果比BORDER好。 圖3 花型數據集邊界識別效果比較 在充分考慮了局部區域數據分布相對差異能反映不同密度數據集邊界分布特征的基礎上,給出了相應邊界點識別算法BGN。利用相對參數來降低參數選擇的難度。通過按維分析單元k-近鄰集和該單元的左右最近鄰單元的k-近鄰集數據分布關系來識別邊界單元方法,較好地克服網格劃分對邊界單元識別的影響。理論分析和實驗顯示,BGN算法能識別出分布呈任意形狀的多密度數據集的聚類邊界點和噪聲,輸入參數少,與數據輸入順序和單元順序無關,具有較高的邊界檢測精度和執行效率。 [1] Xia C, Hsu W, Lee M L, et al. BORDER: efficient computation of boundary points[J]. Knowledge and Data Engineering, IEEE Transactions on,2006,18(3):289-303. [2] 張選平,祝興昌,馬琮.一種基于邊界識別的聚類算法[J].西安交通大學學報,2007,41(12):1387-1390. [3] 邱保志,琚長濤.具有聚類功能的邊界檢測技術的研究[J].計算機工程與應用,2010,46(20):133-137. [4] 樓曉俊,孫雨軒,劉海濤.聚類邊界過采樣不平衡數據分類方法[J].浙江大學學報(工學版),2013,47(6):944-949. [5] 李燦燦,王寶,王靜,等.基于K-means聚類的植物葉片圖像葉脈提取[J].農業工程學報,2012,28(17):157-161. [6] 安萌,姜志國,趙丹培.邊界片段模板方法在空間探測識別中的應用[J].宇航學報,2009,30(3):1231-1236. [7] 邱磊,楊承志,何佃偉.一種新的基于網格聚類的雷達信號預分選算法[J].現代防御技術,2013,41(2):167-172. [8] Ester M, Kriegel H P, Sander J. A density-based algorithm for discovering clusters in large spatial databases with nosise[C]//Proceedigs of the 2nd International Conference on Knowledge Discovery and Data Mining. Portland, Oregon:[s.n.],1996:226-231. [9] 王桂芝,李井竹,狄志超.支持k-離群度的邊界點檢測方法[J].計算機工程與應用,2011,47(33):140-142. [10] 邱保志,張楓,岳峰.基于統計信息的聚類邊界模式檢測算法[J].計算機工程,2008,34(3):91-93. [11] 高亞魯,宋余慶,朱玉全.改進的CLIQUE優化算法[J].計算機工程與設計,2009,30(16):3801-3804. [12] 張鴻雁,劉希玉,付萍.一種網格聚類的邊緣檢測算法[J].控制與決策,2011,26(12):1846-1850. [13] 邱保志,余田.基于網格梯度的邊界點檢測算法的研究[J].微電子學與計算機,2008,25(3):77-80. [14] Li G, Li B. Boundary Point Recognition Algorithm Based on Grid Adjacency Relation[M]//Recent Advances in Computer Science and Information Engineering. Heidelberg,2012:Springer:211-218. Boundary Point Recognition Algorithm for Gridk-nearest Neighbor Set Li Guangxing (Department of Fundamental Courses, Chengdu Vocational College of Agricultural Science and Technology, Chengdu 611130) In order to efficiently identify the cluster boundary, based on the existence of density differences in the surrounding area of the boundary, a boundary point recognition algorithm for Gridk-nearest neighbor set(BGN) is proposed. In the grid space, based on the number of elements of grid cell and its nearest neighbor’sk-neighbor set, along with the cell-center distance of the unit grids, the boundary degree is determined by this algorithm. According to boundary degree and boundary threshold, this algorithm determines if each unit grid is boundary unit or noise unit. By extracting the data closer to the edge of the boundary to represent as boundary points, this algorithm is capable to make finer boundary. The experimental results indicate that the algorithm can effectively and quickly identify the cluster boundaries and noise for multi-density datasets. grid cell,k-nearest neighbor set, boundary degree, boundary point, noise 2015年1月13日, 2015年2月27日 作者簡介:李光興,男,副教授,研究方向:人工智能與計算數學。 TP311 10.3969/j.issn1672-9730.2015.07.0354 實驗結果及分析




5 結語
