云計算環境下基于數據關聯度的海洋監測大數據布局策略*
2015-03-19 00:36:14黃冬梅隨宏運趙丹楓杜艷玲
計算機工程與科學 2015年11期
黃冬梅,隨宏運,賀 琪,趙丹楓,杜艷玲,蘇 誠
(1.上海海洋大學信息學院,上海201306;2.國家海洋局東海信息中心,上海200136)
1 引言
“空天地底”海洋立體觀測技術的飛速發展,使得高精度、高頻度、大覆蓋的多模態海洋數據[1]呈幾何級數爆炸式增長。此外,海洋監測數據具有多學科交叉性、海洋數據獲取手段和數據格式復雜化、數據種類多樣化等特性,是典型的大數據。對于獲得的海洋監測大數據,如何有效地進行存儲和布局是日后研究人員合理使用和分析海洋大數據的基礎。
數據布局策略主要解決如何合理地將海量數據布局到合適的數據中心的問題。隨著大規模數據存儲系統體系結構的發展,數據布局策略從設計目標到應用環境發生了很大的改變,并應用于多種存儲系統中。如在傳統的RAID 機制中,運用分條技術將數據分成多個條帶單元,以每個條帶單元為單位將數據分布在多個磁盤上以提高讀/寫速度[2]。在P2P系統中,通過分析數據的可用性,將文件作為數據存儲[3]的基本單位對數據進行布局。然而,由于海洋監測大數據[4]自身具有特殊的性質,使得傳統的布局策略在對海洋監測大數據布局時缺乏實用性。例如,在對海洋大數據進行監測時,監測點數據的分布呈分散性,不同監測點對應不同的領域。同時,一些用戶在執行某特定監測任務時,將集中應用某些監測點,從而產生監測點之間的關聯。因此,在對海洋監測大數據布局時應適當考慮監測點間的關聯度。此外,監測點內海洋數據的屬性繁多,在這些屬性之間也存在著潛在的聯系,故需進一步考慮監測數據間的關聯度。
隨著科學技術與海洋監測設備技術的不斷發展,海洋的數據量已發展到PB、EB 級甚至更大級別,成為名副其實的大數據。此外,海洋監測過程中,每個數據都呈分散性,傳統的集中式數據布局策略對海洋監測大數據具有一定的局限性,這使得如何將關聯緊密的海洋監測大數據合理地布局在同一數據中心,有效地減少響應時間顯得十分重要。因此,本文采用云環境下的分布式存儲模式對海洋監測大數據進行布局,提出云計算環境下基于數據關聯度的海洋監測大數據布局策略。通過分析云環境下的數據中心容量以及海洋監測數據、監測點和監測任務之間的關聯,利用具備超大規模、高可擴展性等特點的云計算環境來實現海洋監測大數據的存儲。
2 相關工作
本節首先闡述了現有的數據布局策略[5~9],分析各個策略的布局效果;然后介紹了目前關于云計算環境下的數據管理方法[10~18];最后介紹當前針對云計算環境下的海洋數據布局問題的相關研究,指出其局限性。
數據布局主要解決如何合理地存放數據的問題。在分布式計算中,針對數據布局的問題進行了很多研究。文獻[6]從數據密集型計算中負載均衡性方面,提出了在特定環境下實現負載均衡的數據布局方法,有效地提高了并行性。文獻[7]提出一種基于釋放和重構的數據布局策略,使得在超大規模的解空間中盡快找到更加接近全局最優的數據布局方案,有效地減少了數據的傳輸代價。文獻[8]采取將一致Hash方法和聚類算法相結合的方法,按照設備的權重大小進行聚類,同時按照類別分配區間對數據進行布局,減少了對存儲空間的消耗。文獻[9]從節能方面介紹了一種適于連續數據存儲的節能數據布局方案,通過關閉部分處于空閑狀態的磁盤達到數據布局過程中節能的效果。上述工作分別從負載均衡性、數據傳輸代價、存儲空間和節能不同的角度對數據進行布局。然而,在當前大數據時代,上述研究把更多的注意力放在提高存儲設備性能上,忽略了海洋監測大數據之間的關聯性,尤其是對于如何根據海洋數據關聯性進行數據布局的研究較少。
近年來,大數據技術的發展為海洋信息化開辟了新的研究途徑與產業化的新思路。隨著面向海洋的大數據管理與布局技術不斷地發展,云計算受到了眾多國內外研究者的關注。文獻[15]認為云計算環境由多個分布的數據中心組成,并利用云計算環境,從跨數據中心數據傳輸、數據依賴關聯和全局負載均衡三個方面,提出一種三階段的面向數據密集型流程應用的數據布局策略,有效地降低了跨數據中心數據傳輸的時間開銷。文獻[16]模擬混合云計算模式,針對科學工作流數據,從跨數據中心時數據移動的時間開銷和產生的傳輸費用方面對數據進行布局,提出了一種優化的數據布局方法。文獻[17]以紅十字會組織物資采購的例子,提出了在云計算環境下對隱私數據和非隱私數據的布局方法。這些學者針對一般數據進行了高效的布局,但是海洋監測大數據不同于一般數據,有其自身的特點[18],在監測任務、監測點和監測數據間存在著一定的關聯。因此,面對具有特殊性質的海洋監測大數據,在進行布局時還需要考慮數據本身存在的特性。
綜上所述,文獻[19~24]從多角度研究了數據布局方法以及云計算環境下數據管理策略,在通用數據上具有顯著的效果,但是對于海洋監測大數據間潛在關聯性分析的研究較少,數據布局的同時易丟失海洋監測大數據原有的特色。針對此問題,本文將在考慮海洋監測大數據自身特點的基礎上,綜合考慮監測任務、監測點和監測數據三者之間的關聯度,研究云計算環境下更加適合于海洋監測大數據的布局策略。
3 基本定義
本文主要研究云計算環境下的海洋監測大數據布局問題。云計算環境由多個分布式數據中心組成,每一個數據按照合理的數據布局策略[25~28]存儲在數據中心內,每一個監測任務按照用戶需求調用所需的數據。云計算環境下的數據存儲、海洋監測數據和監測任務之間的關聯如圖1所示。
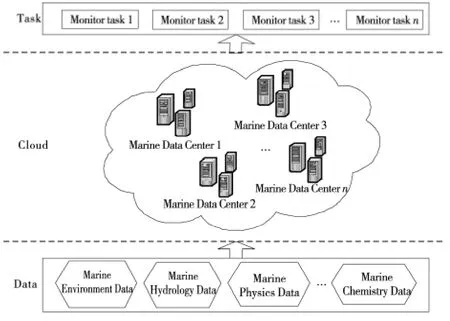
Figure 1 Dependency map of data storage,marine monitoring data and applications圖1 數據存儲、海洋監測數據和監測任務之間的關聯圖
定義1(云計算環境) 云計算環境由多個分布式數據中心組成,數據中心集表示為DC,每個數據中心dci∈DC,可表示為一個三元組〈IDdc,λ,f〉。其中,IDdc是數據中心的標識符;λ是存儲數據時數據中心的使用百分比,它是數據中心負載的一個閾值,用于保證各個數據中心負載均衡;f是數據中心的個數。
定義2(海洋監測數據集) 海洋監測數據集表示為D,每個數據di∈D,可表示為一個四元組〈IDd,si,pi,ui〉。其中,IDd表 示 海 洋 監 測 數 據 的標識符,si表示海洋監測數據的大小,pi表示海洋監測數據di所屬的監測點,ui表示海洋監測數據的屬性。
定義3(監測任務集) 監測任務集表示為T,每個監測任務ti∈T,可表示為一個三元組〈IDt,pi,A〉。其中,A表示監測任務ti在監測點pi處所監測的屬性集。
4 基于關聯度分析的數據布局策略
為了實現同一數據中心內的每個數據之間具有較高的關聯度,不僅需要考慮數據中心存儲容量λ的值,還需要考慮監測點間和監測數據間的關聯度。對于這兩個標準,本文優先考慮海洋監測點間和監測數據間的關聯度。首先,通過分析云計算環境下海洋監測過程中監測任務、監測點和監測數據之間的關聯,得出監測點間的關聯矩陣、監測數據間的關聯矩陣、監測數據全局關聯矩陣;然后,運用鍵能算法BEA(Bond Energy Algorithm)[29]將關聯矩陣轉換為聚類矩陣;最后,通過非重疊劃分算法[30]對聚類后的矩陣進行劃分,形成N類子數據集,使得每類子數據集中各個數據間具有較高的關聯度,并根據數據中心的存儲容量進行布局。
4.1 關聯度定義
4.1.1 監測點間的關聯度
研究人員在執行海洋數據監測任務前,首先需要確定監測點的信息,然后對監測點進行數據采集。在對數據布局時,如果僅以單一監測點數據為基準進行布局,將會忽略監測點之間存在的潛在相關性,使得有關聯的幾個監測點本應存儲在同一數據中心,卻被存儲到不同的數據中心內,導致用戶在執行某項監測任務時需要訪問多個數據中心,造成不必要的時間消耗。因此,本文通過分析監測任務與監測點間的關聯度,計算同時應用兩個監測點的監測任務個數,構建兩監測點之間的關聯矩陣。當某些監測點常常被多個監測任務同時應用時,便把他們歸為一類。
被歸為一類的監測點可以同屬某單一領域,也可屬于不同領域,例如監測區1內的監測點都屬于物理海洋領域,而監測區2內的監測點既有屬于物理海洋領域的監測點,又有屬于生物生態領域的監測點,雖然含有不同領域的監測點,但是他們之間有著潛在的、隱藏的內在聯系。
定義4(監測點間的關聯度) 設Tpi表示對監測點pi進行監測的監測任務;Tpj表示對監測點pj進行監測的監測任務;i,j=1,2,…,n;n表示監測點的個數。兩點間的關聯度由同時在監測點pi和pj進行監測的任務個數總和得出,則監測點pi和pj之間的關聯度Iij為:
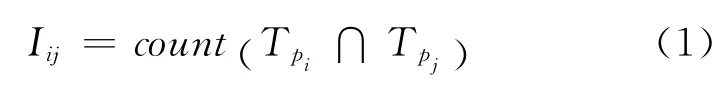
4.1.2 監測數據間的關聯度
各監測點的海洋數據屬值繁多,包括經度、緯度、溫度、濕度、鹽度、大氣壓、螢光度等,在這些監測數據的屬性之間也存在著一定的聯系,如由物理知識可知大氣壓值與溫度值有密切的關聯。因此,在對海洋監測大數據進行布局時,除了考慮監測點間的關聯度,還需要考慮監測數據間的關聯度。但是,由于不同監測點擁有不同的屬性集,如在p1點監測的數據屬性包括u0、u1、u3、u4,而在p2點監測的數據屬性包括u1、u3、u5、u6、u7,這使得在以數據屬性關聯度為基準進行布局時難以分辨數據來源。因此,在數據布局時將屬性值和監測點進行對應,構建形如的對應監測數據(注,簡稱為監測數據),表示監測點pi處的第k個數據,其中,k=1,2,…,N;N為監測點pi處的數據個數。對于每個監測數據,通過計算同時應用兩個數據的監測任務個數構建兩監測數據間的關聯矩陣。
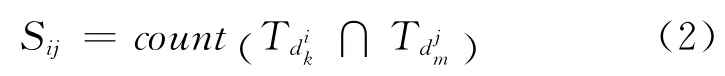
4.1.3 監測數據全局關聯度
Iij反映了監測點間的關聯度,Sij反映了監測數據間的關聯度,但是單獨考慮某一關聯度,較難很好地從整體角度反映數據之間的緊密程度。例如,在監測過程中應用pr處數據di的頻數為5,應用ps處的數據dj的頻數為20,從數值上可看出dj比di的使用量高,但是對于監測點pr的任務個數為15,監測點ps的任務個數為100,則在平均頻率上數據di較高。因此,需綜合分析數據布局中監測點間的關聯度和監測數據間的關聯度。
定義6(監測數據全局關聯度) 全局關聯度反映了監測數據間的整體緊密程度,可由監測數據關聯度與監測點間關聯度的比值得出。此處,由于比值較小不利于計算,為了便于數據處理以及保證程序運行時收斂加快,利用f(·)函數將其歸一化處理[31],并取不大于其值的最大整數作為監測數據的全局關聯度,即:
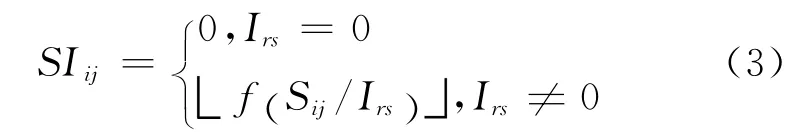
其中,r對應數據di所在的監測點,s對應數據dj所在的監測點。
4.2 海洋監測大數據的聚類
4.2.1 關聯矩陣的建立
通過分析監測點、監測任務和監測數據之間的關聯(見表1),利用公式(1)~公式(3)得到監測點間的關聯矩陣I圖、監測數據間的關聯矩陣S圖和全局關聯矩陣IS圖(見圖2)。

Table1 Dependency table of monitoring points,monitoring applications and part of the monitoring data表1 監測點、監測任務和部分監測數據之間的關聯表
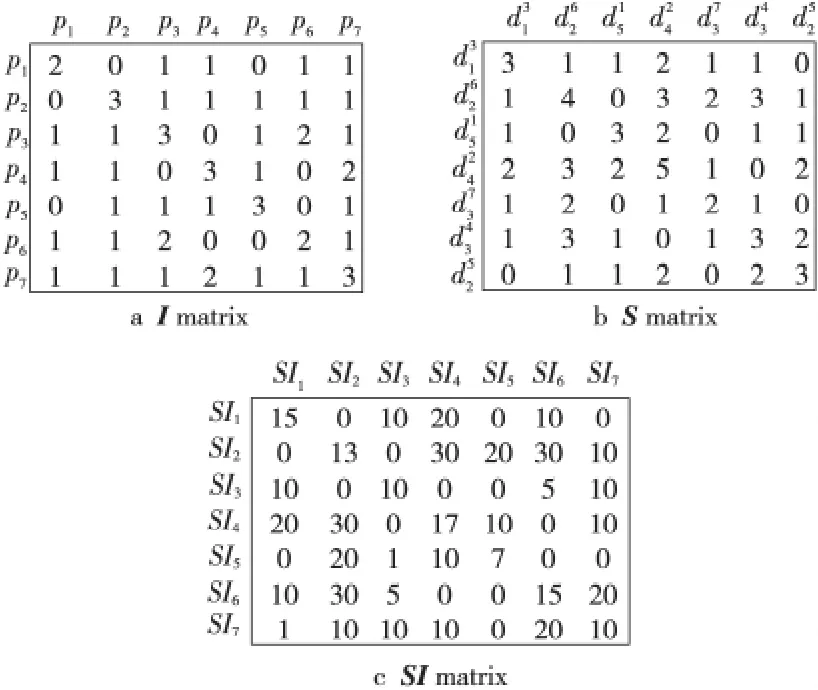
Figure 2 Correlation matrixes圖2 關聯矩陣
4.2.2 聚類矩陣的建立
將關聯矩陣轉換為聚類矩陣旨在使矩陣中相似的元素聚集在一起,本文利用BEA 算法將關聯矩陣轉換為聚類矩陣。BEA 算法[29]是應用于分布式數據庫系統中表的垂直劃分算法,它通過對矩陣中的行和列不斷改變和排列,使聚集在一起的元素具有較高的相似性。通過BEA 算法將得到的三個矩陣I、S、SI分別做行列變換運算,轉換后的聚類矩陣I′、S′、和SI′如圖3所示。
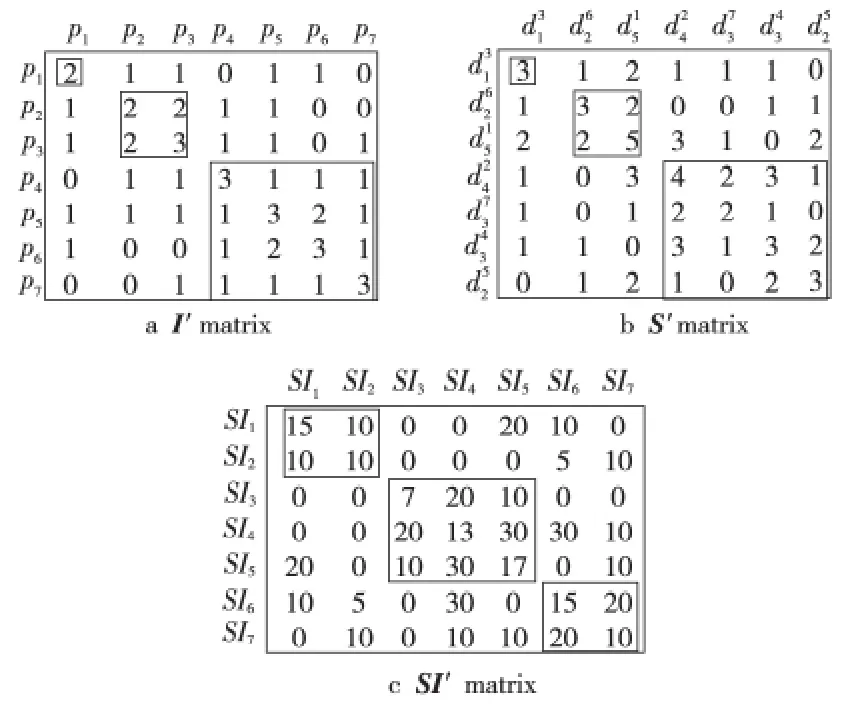
Figure 3 Converted clustering matrixes圖3 轉換后的聚類矩陣
4.2.3 海洋監測大數據的劃分
為了使劃分后的每類子數據集中各個數據之間具有較高的關聯度,而與其余數據集內數據具有較低的關聯度,需對聚類矩陣中的數據進行劃分。本文利用非重疊劃分算法[30],計算dp值,如公式(4)所示。當dp取最大值時,記錄此時對應的劃分點h的值,這時的劃分點h將聚類矩陣劃分為兩個不重疊的數據子塊,依次遞歸地劃分直到滿足數據中心的存儲容量λ為止。

由圖3可以發現,根據非重疊劃分算法,聚類矩陣被劃分為三個數據塊,數據塊1由監測點p1組成,數據塊2由監測點p3和p6組成,數據塊3由監測點p2、p4、p5和p7組成。
4.3 海洋監測大數據的布局
云計算環境下基于監測數據關聯度的海洋大數據布局過程描述如下:
輸入:監測任務、監測點、海洋監測大數據;
輸出:海洋監測大數據的布局方案。
主要步驟:
步驟1 初始化云計算環境下的數據中心個數f、存儲容量λ;
步驟2 根據公式(1)~公式(3)計算數據集內各監測點間的關聯度、監測數據的關聯度和監測數據全局關聯度;
步驟3 構建關聯矩陣I、S和監測數據全局關聯矩陣SI;
步驟4 通過BEA 算法使得矩陣中的相似項聚集在一起,形成聚類矩陣I′、S′和SI′;
步驟5 以各類數據中心間關聯度低、數據中心內數據關聯度高為標準,利用非重疊劃分算法劃分聚類矩陣,將具有較高關聯度的數據劃分為一類子數據集;
步驟6 判斷劃分后各子數據集合的容量是否滿足數據中心的存儲容量λ。如果滿足,則將該子數據集分配到相應的數據中心,否則,轉到步驟5。
步驟7 根據步驟6,輸出海洋監測大數據的布局方案。
5 實驗與分析
仿真實驗平臺配置為酷睿四核處理器,2.8GHz,6GB內存,采用開源的Openstack云計算管理平臺,在云計算環境下對海洋監測大數據布局。經過調研得知,某國家海洋局某監測中心有監測點8個,每個監測點有7~10個監測數據屬性,選用相關的600個監測任務作為實驗數據集,如表2所示。實驗選用五折交叉驗證法,隨機選擇80%的數據集作為訓練集,剩余作為測試集,通過數據傳輸速度、用戶訪問數據的響應時間和算法運行時間來評估算法的執行效率。
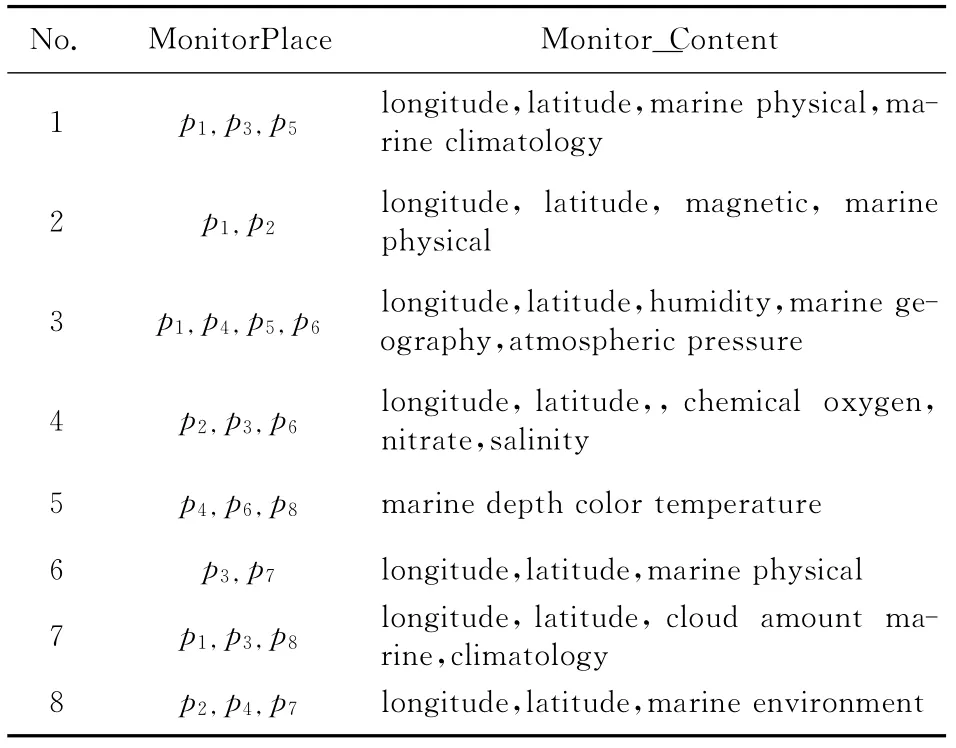
Table 2 Part of the monitoring missions supplied by a monitoring center表2 監測中心提供的部分監測任務列表
為了說明本文提出的策略能有效地減少數據傳輸次數,實驗將其與數據隨機布局策略(簡稱Random 策略)進行比較。其中,IRM 表示以監測點間關聯度為標準時的布局策略,DRM 表示以監測點數據間關聯度為標準時的布局方策略,MRM表示以監測數據全局關聯度為標準時的布局策略。
如圖4所示,隨著數據集數量的增加,對應的跨數據中心數據傳輸次數呈明顯上升趨勢,然而,由于本文提出的IRM、DRM 和MRM 策略根據監測點和監測數據間的關系將相關度大的數據集放置到同一數據中心,在一定程度上降低了數據傳輸次數,因此IRM、DRM 和MRM 在數據傳輸次數上明顯少于Random 策略,且具有一定穩定性。
圖5反映了每50個監測任務的響應時間對比圖。從圖5中可看出,MRM 策略在響應時間方面優于其他方法。其中,Random 方法的響應時間最長,原因在于對數據布局是該方法忽略了海洋數據的特點,降低了響應效率。IRM 和DRM 的響應時間相近,而MRM 具有明顯的優勢,較IRM 和DRM,MRM 布局策略能夠較快速地響應監測任務,具備高效數據布局的特點。當監測任務量提升時,效果尤為顯著。
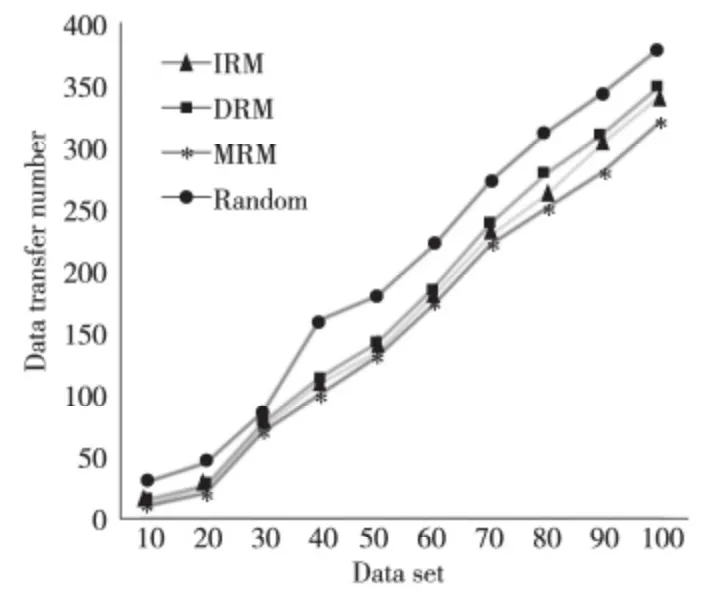
Figure 4 Comparison chart of data’s transfer numbers圖4 數據傳輸次數對比圖
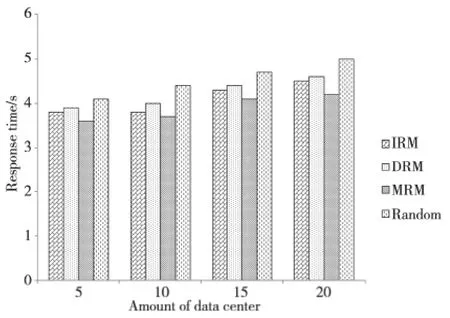
Figure 5 Comparison chart of data’s response time圖5 數據響應時間對比圖
雖然MRM 在圖5中響應時間最短,但由圖6可以明顯看出,隨著數據集個數的增加,四種算法的運行時間有明顯的變化,本文提出的三種策略在運行時間方面明顯優于Random 策略。其中,IRM的計算量相對較少,尤其是當數據集超過50的時候,IRM 算法運行時間最短,具有快速數據布局的特點,雖然DRM 的計算量較大,但算法的運行時間與其他策略相差不大,仍可接受。
為了進一步分析本文提出的方法在各類型海洋數據上的布局效果,將數據集分為六個類別進行數據響應時間對比,分別是:大氣化學、海洋氣象、走航皮溫、海表溫鹽、海洋營養鹽和海水葉綠素。從圖7中可以發現,對于大氣化學類別,響應時間相差不大,基本保持一致。但是,對于海洋氣象、走航皮溫、海表溫鹽、海洋營養鹽和海水葉綠素,Random 方 法 的 響 應 時 間 最 長,IRM 和DRM 的 響應時間相近,而MRM 具有明顯的優勢,較IRM 和DRM,MRM 布局策略能夠較快速地響應監測任務,具備高效數據布局的特點。原因在于:海洋監測數據不同于一般數據,有其自身的特點,Random方法忽略了數據之間的關聯性。由此可見,面對真實的海洋大數據,本文方法在布局時具備較強的泛化能力和高可擴展性。
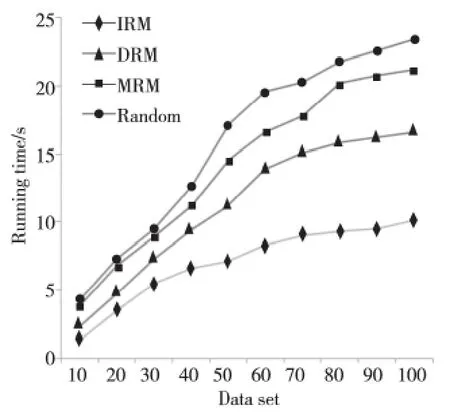
Figure 6 Comparison chart of running time圖6 運行時間對比圖
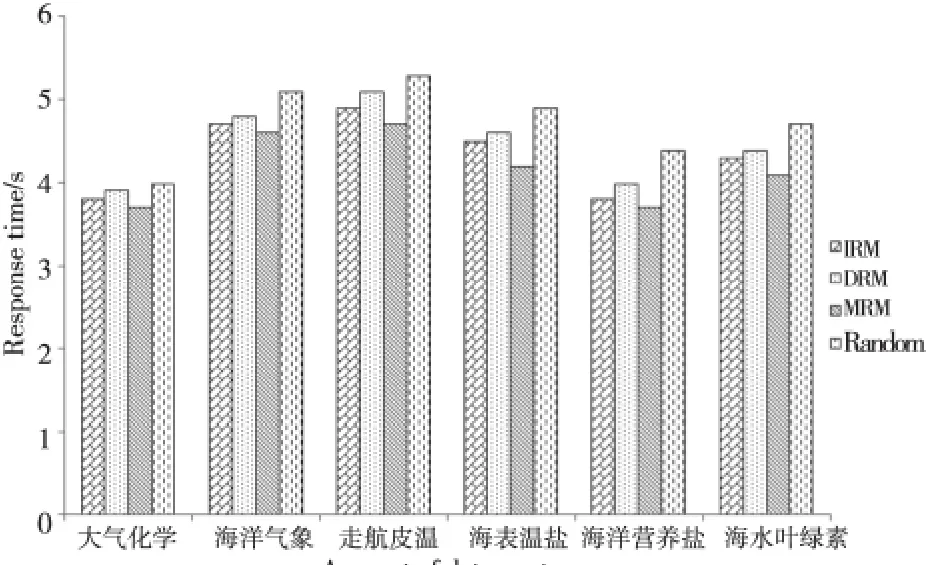
Figure 7 Comparison chart of data’s response time for different categories of marine data圖7 不同類型的海洋數據響應時間對比圖
因此,對于海洋監測大數據的布局,當用戶需要快速運行算法時,可采用快速布局策略IRM;當數據存儲容量充足時,可考慮快速布局策略IRM和高效布局策略MRM。而數據容量有限時,由于IRM 得到的子數據集容量較大,無法很好地滿足數據中心的容量限制,可使用高效布局策略MRM。
6 結束語
大數據技術的發展為海洋信息化開辟了新的研究途徑與產業化的新思路。本文提出了一種云計算環境下基于監測數據關聯度的海洋大數據布局策略,取得了較滿意的實驗結果。本文主要貢獻有:
(1)針對海洋監測大數據具有海量、異構、強數據關聯的特點,以及在監測過程中,監測數據呈分散性的情況,采用云環境下的分布式存儲模式對海洋監測大數據進行布局,充分利用云計算超大規模、高可擴展性等特點滿足海洋監測大數據的存儲管理要求。
(2)綜合考慮了監測任務、監測點和監測數據之間的關聯度,從海洋監測點間的關聯度、監測數據間的關聯度和監測數據全局關聯度三個角度對海洋監測大數據進行布局,在數據中心存儲均衡的情況下,很大程度上降低了用戶訪問海洋監測大數據的響應時間。
然而,在布局過程中數據副本的延時響應問題呈現逐步上升的趨勢,下一步工作將進一步探索云計算環境下布局海洋監測大數據時的數據副本布局技術。
[1] Petes L,Diamond J,Fisher B,et al.Ocean management challenges,adaptation approaches,and opportunities in a changing climate[M]∥Oceans and Marine Resources in a Changing Climate.Washington:Island Press/Center for Resource Economics,2013:140-155.
[2] Park K,Lee D H,Woo Y,et al.Reliability and performance enhancement technique for SSD array storage system using RAID mechanism[C]∥Proc of the 9th International Symposium on Communications and Information Technology,2009:140-145.
[3] Caron S,Giroire F,Mazauric D,et al.P2Pstorage systems:Study of different placement policies[J].Peer-to-Peer Networking and Applications,2014,7(4):427-443.
[4] Herlihy D R,Matula S P,Andreasen C.Swath mapping data management within the national iceanic and atmospheric administration[J].The International Hydrographic Review,2015,65(2):1.
[5] Kameda H,Li J,Kim C,et al.Optimal load balancing in distributed computer systems[M].Incorporated:Springer Publishing Company,2011.
[6] Song Jie,Li Tian-tian,Yan Zhen-xing,et al.Load-balanced data layout approach in data-intensive computing[J].Journal of Beijing University of Posts and Telecommunications,2013,36(4):76-80.(in Chinese)
[7] Zhang Tian-tian,Cui Li-zhen.A data placement strategy based on relaxation and reconstruction for scientific workflow applications[J].Journal of Computer Research and Development,2013,50(suppl):71-76.(in Chinese)
[8] Chen Tao,Xiao Nong,Liu Fang,et al.Clustering-based and consistent Hashing-aware data placement algorithm [J].Journal of Software,2010,21(12):3175-3185.(in Chinese)
[9] Liu Jing-yu,Zheng Jun,Li Yuan-zhang,et al.Hybrid SRAID:An energy-efficient data layout for sequential data storage[J].Journal of Computer Research and Development,2013,50(1):37-48.(in Chinese)
[10] Yao W,Lu L.A selection algorithm of service providers for optimized data placement in multi-cloud storage environment[M]∥Intelligent Computation in Big Data Era.Berlin:Springer Berlin Heidelberg,2015:81-92.
[11] Calder B,Wang J,Ogus A,et al.Windows azure storage:A highly available cloud storage service with strong consistency[C]∥Proc of the 23rd ACM Symposium on Operating Systems Principles,2011:143-157.
[12] Maia G,Guidoni D L,Viana A C,et al.A distributed data storage protocol for heterogeneous wireless sensor networks with mobile sinks[J].Ad Hoc Networks,2013,11(5):1588-1602.
[13] Yan Lin,Xing Jing,Huo Zhi-gang,et al.A survey on storage architectures and core algorithms for big data management on new storages[J].Computer Engineering & Science,2013,35(5):20-27.(in Chinese)
[14] Wang Yi-jie,Sun Wei-dong,Zhong Song,et al.Key technologies of distributed storage for cloud computing[J].Journal of Software,2012,23(4):962-986.(in Chinese)
[15] Zheng Pai,Cui Li-zhen,Wang Hai-yang,et al.A data placement strategy for data-intensive applications in cloud[J].Chinese Journal of Computers,2010,33(8):1472-1480.(in Chinese)
[16] Ma Fei.Data placement strategy research for scientific workflow in hybrid cloud computing[D].Hefei:Anhui University,2014.(in Chinese)
[17] Zhang Peng,Wang Gui-ling,Xu Xue-hui.A data placement approach for workflow in cloud[J].Journal of Computer Research and Development,2013,50(3):636-647.(in Chinese)
[18] Xie Peng-fei,Sui Wei-na,Tao Guan-feng,et al.Cloud computing in the marine environment monitoring[J].Marine Environmental Science,2013,32(4):576-580.(in Chinese)
[19] Majeti D,Barik R,Zhao J,et al.Compiler-driven data layout transformation for heterogeneous platforms[C]∥Proc of Euro-Par 2013:Parallel Processing Workshops,2014:188-197.
[20] Wildani A,Miller E L,Adams I F,et al.PERSES:Data layout for low impact failures[C]∥Proc of 2014IEEE 22nd International Symposium on Modelling,Analysis &Simulation of Computer and Telecommunication Systems (MASCOTS),2014:71-80.
[21] Zhao Wei,Zhuo Wei,Li Zhan-bo,et al.A novel data exchange architecture based on cloud computing[J].Computer Engineering &Science,2013,35(8):15-19.(in Chinese)
[22] Wei L,Zhu H,Cao Z,et al.Security and privacy for storage and computation in cloud computing[J].Information Sciences,2014,258(10):371-386.
[23] Heath M A,Coker K T,Viraraghavan P.Data storage device overlapping host data transfer for a write command with inter-command delay:U.S.Patent 8,631,188[P].2014-01-14.
[24] Liu C,Chen J,Yang L T,et al.Authorized public auditing of dynamic big data storage on cloud with efficient verifiable fine-grained updates[J].IEEE Transactions on Parallel and Distributed Systems,2014,25(9):2234-2244.
[25] Jenkins J,Zou X,Tang H,et al.RADAR:Runtime asymmetric data-access driven scientific data replication[C]∥Proc of the 28th International Supercomputing Conference,ISG’14,2014:296-313.
[26] Yang K,Jia X.An efficient and secure dynamic auditing protocol for data storage in cloud computing[J].IEEE Transactions on Parallel and Distributed Systems,2013,24(9):1717-1726.
[27] Barsoum A F,Hasan A.Enabling dynamic data and indirect mutual trust for cloud computing storage systems[J].IEEE Transactions on Parallel and Distributed Systems,2013,24(12):2375-2385.
[28] Anjos J C S,Carrera I,Kolberg W,et al.MRA++:Scheduling and data placement on MapReduce for heterogeneous environments[J].Future Generation Computer Systems,2015,42:22-35.
[29] McCormick Jr W T,Schweitzer P J,White T W.Problem decomposition and data reorganization by a clustering technique[J].Operations Research,1972,20(5):993-1009.
[30] Song H,Yin Y,Sun X H,et al.A segment-level adaptive data layout scheme for improved load balance in parallel file systems[C]∥Proc of the 2011 11th IEEE/ACM International Symposium on Cluster,Cloud and Grid Computing,2011:414-423.
[31] Sun X,Shi L,Luo Y,et al.Histogram-based normalization technique on human brain magnetic resonance images from different acquisitions[J].Biomedical Engineering Online,2015,14(1):73.
附中文參考文獻:
[6] 宋杰,李甜甜,閆振興,等.數據密集型計算中負載均衡的數據布局方法[J].北京郵電大學學報,2013,36(4):76-80.
[7] 張甜甜,崔立真.基于釋放和重構的科學工作流數據布局策略[J].計算機研究與發展,2013,50(suppl):71-76.
[8] 陳濤,肖儂,劉芳,等.基于聚類和一致Hash 的數據布局算法[J].軟件學報,2010,21(12):3175-3185.
[9] 劉靖宇,鄭軍,李元章,等.混合S-RAID:一種適于連續數據存儲的節能數據布局[J].計算機研究與發展,2013,50(1):37-48.
[13] 嚴林,邢晶,霍志剛,等.面向海量數據存儲的Erasure-Code分布式文件系統I/O 優化方法[J].計算機工程與科學,2013,35(5):20-27.
[14] 王意潔,孫偉東,周松,等.云計算環境下的分布存儲關鍵技術[J].軟件學報,2012,23(4):962-986.
[15] 鄭湃,崔立真,王海洋,等.云計算環境下面向數據密集型應用的數據布局策略與方法[J].計算機學報,2010,33(8):1472-1480.
[16] 馬飛.混合云環境下科學工作流數據布局研究[D].合肥:安徽大學,2014.
[17] 張鵬,王桂玲,徐學輝.云計算環境下適于工作流的數據布局方法[J].計算機研究與發展,2013,50(3):636-647.
[18] 解鵬飛,隋偉娜,陶冠峰,等.云計算與海洋環境監測[J].海洋環境科學,2013,32(4):576-580.
[21] 趙偉,卓偉,李占波,等 基于云計算的一種新的數據交換架構[J].計算機工程與科學,2013,35(8):15-19.
