基于OpenMP的包絡對齊并行方法研究與實現*
2015-03-19 00:36:40張佳佳姜衛東
計算機工程與科學 2015年11期
張佳佳,姜衛東,李 寬
(1.國防科學技術大學電子科學與工程學院,湖南 長沙410073;2.國防科學技術大學計算機學院,湖南 長沙410073)
1 引言
在逆合成孔徑雷達(ISAR)成像中,包絡對齊是決定成像質量的關鍵技術。包絡對齊的經典算法有最大互相關法[1~3]、最小熵法[4]、峰值最大法,最大互相關法包括相鄰互相關法[1]、積累互相關法[2]以及整體互相關法[3]。積累互相關法和最小熵法性能較好,然而兩者對齊精度直接受限于雷達距離分辨單元。超分辨技術[5]可以提高距離分辨率,但是該方法需要足夠的信噪比,工程上難于實現。而巧妙利用Fourier變換的頻域移位性質,可以縮短包絡對齊處理步長,有效減小一維距離像對齊誤差[6]。
本文采用加矩形窗的積累互相關法獲得粗對齊包絡,而后基于頻移因子利用最小熵準則調整對齊結果。一般ISAR 成像原始回波數據量大,互相關法和最小熵法計算量都很大,在序列成像、實時成像等條件下對計算資源是一大挑戰。為提高包絡對齊速度,文獻中出現多種方案:基于GPU 的最 小 熵 包 絡 對 齊 法[7]、FPGA 加 多 片 單 核DSP 的ISAR 實時成像[8]、基于多核DSP的信號處理平臺減少對齊時間[9]等硬件處理手段,但是硬件優化結構研制和改進周期長、費用高昂且維護不便。
針對上述問題,考慮到CPU 計算性能飛速提升以及多核處理器的廣泛應用,本文提出基于OpenMP(Open Multi-Processing)[10]共享存儲的包絡對齊優化算法,分別將互相關法和最小熵法劃分為多個獨立任務,利用OpenMP 將各任務映射到不同線程中并行執行,充分利用多核處理器資源,提高程序運行效率。實驗結果顯示,并行算法加速效果明顯,加速效率最高可達98%,并且該方法無需額外硬件支持,費用低廉,易于實現。
2 包絡對齊算法
逆合成孔徑雷達成像經典算法為距離-多普勒(R-D)成像算法,包含三個步驟:距離壓縮、運動補償和方位壓縮,運動補償又由包絡對齊和相位補償組成。R-D 算法如圖1所示。
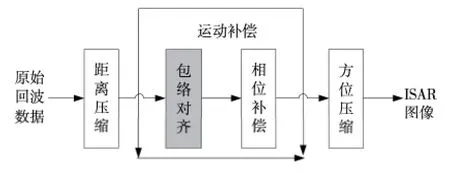
Figure 1 Range-Doppler algorithm圖1 ISAR 成像距離-多普勒算法
由圖1知,包絡對齊的前提是原始回波的距離壓縮,其實質為對每個脈沖回波進行FFT 獲得相應的一維距離像。而由于目標相對于雷達的平動,距離像之間出現未對齊現象。本文包絡對齊分兩步:加矩形窗的積累互相關對齊和基于頻移因子的最小熵對齊。
加矩形窗的積累互相關算法中,參考包絡是窗長的已對齊包絡的加權和產生的合成包絡(此處為矩形窗加權,即權值都為1,窗長盡可能大)。本文對參考包絡和待對齊包絡分別進行FFT 處理,FFT 結果相乘,之后進行IFFT 處理獲得粗對齊一維距離像,如圖2所示。
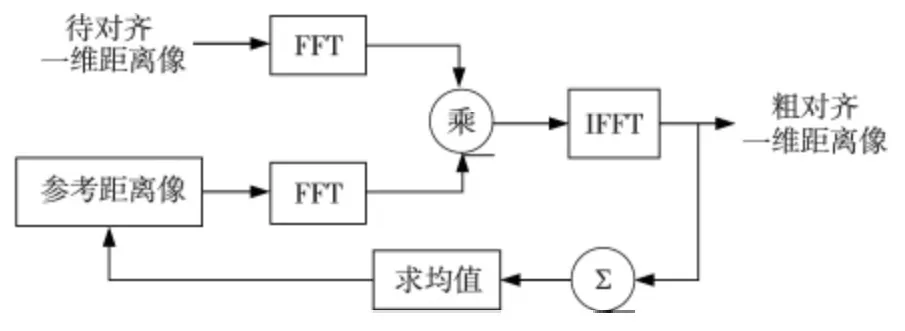
Figure 2 Accumulated cross correlation algorithm based on rectangular window圖2 加矩形窗的積累互相關包絡對齊法
基于頻移因子的最小熵法以積累互相關得出的每次回波的對齊偏移量τi為中心,在[τi-Δτ,τi+Δτ] 內 求 得L個 頻 移 因 子 exp(j2πτilΔfnTs)(Δf為FFT 頻譜分辨單元,Ts為脈內采樣周期),與該次回波si()n相乘,然后依據最小熵準則調整互相關對齊精度,如圖3所示。
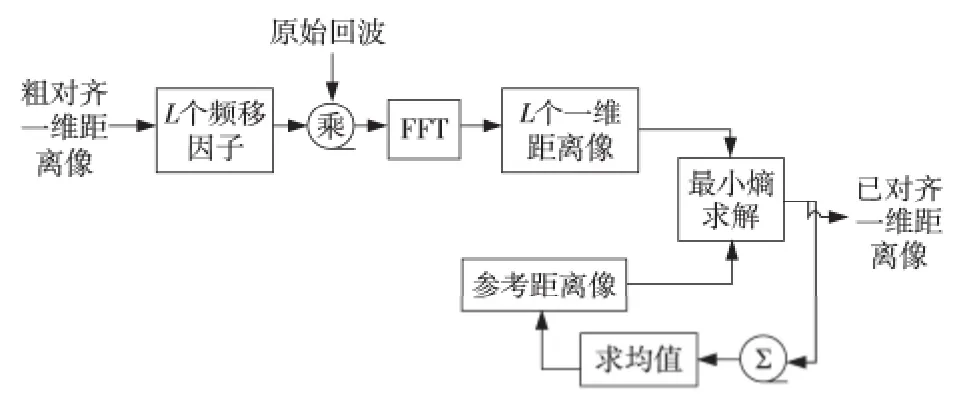
Figure 3 Minimum entropy range alignment algorithm based on frequency shifting property圖3 基于頻移因子的最小熵包絡對齊法
3 包絡對齊并行策略
3.1 OpenMP簡介
OpenMP[11]是共享存儲多核處理器編寫并行程序的一套編程接口,由環境變量、編譯制導指令以及支持它的函數庫組成。OpenMP 并行執行模型為分叉-合并(Fork-Join)模式(如圖4所示):程序開始時,主線程串行執行;遇到派生點后,主線程創建并行線程隊列,執行并行區代碼;并行代碼執行完畢,派生線程掛起或退出,由主線程繼續執行串行程序,直到遇到下一個派生點。
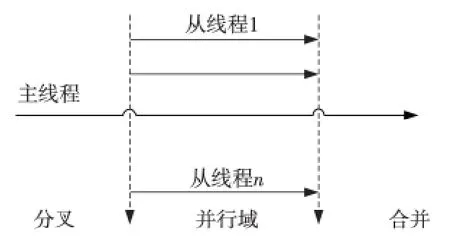
Figure 4 Fork-Join pattern of OpenMP圖4 OpenMP分叉-合并模型
使用OpenMP 開發并行程序簡單且通用性強,無需關注并行化細節。在源代碼中加入合適的#pragma編譯指導指令,編譯器自動并行化程序。OpenMP與編譯器無關,開發平臺不支持OpenMP時,編譯器自動忽略#pragma指令,程序轉為串行代碼順序編譯并正常運行。
3.2 包絡對齊的并行設計思想
包絡對齊數據流為二維矩陣,算法以距離像包絡為單位循環執行對齊任務。因此,本文主要是對循環部分進行并行化設計,研究帶有循環結構的大數據量計算的并行方法時,首先分析計算數據之間的相關性,然后討論計算執行時的數據劃分方法,最后進行必要的調整。
原始回波數據矩陣由回波個數和回波采樣點數組成,一般回波個數和采樣點數都較大。距離壓縮時各個脈沖回波相互獨立,循環對每個回波進行FFT 處理,因此只需在循環外直接使用OpenMP指令即可有效實現程序并行優化。包絡對齊基于相鄰脈沖回波的強相關性,當前回波的參考信號依賴前面矩形窗長的已對齊回波距離像包絡,但是與矩形窗外回波相關性較小,而且脈沖回波數目遠遠大于矩形窗內回波數目,因此,本文提出依據處理器核數對回波數據進行均勻分塊,每塊回波數目遠大于窗長,能夠大大消除數據塊間的相關性。同時,為保證對齊質量,本文提出由第一塊待對齊數據獲得的參考信號作為其它各塊待對齊回波的參考距離像。因此,本文在多核處理器上進行數據分塊并行執行包絡對齊任務,既保證對齊質量,又提高對齊速度。
3.3 距離壓縮并行方法
由于原始回波數目大,各次回波循環執行FFT,OpenMP利用函數omp_set_num_threads()設置線程數目,編譯指導指令#pragma omp for直接作用于循環語句,程序即自動依照線程數目并行執行循環運算,有效減少距離壓縮時間且實現簡單。
3.4 加矩形窗的積累互相關并行方法
積累互相關包絡對齊是每個待對齊一維距離像與參考距離像進行互相關得到粗對齊一維距離像。首先,根據處理器核數n,將待對齊數據順序均勻分成n塊,利用OpenMP 編譯指導指令#pragma omp section將各塊數據分配到各線程,每個線程參考包絡都使用第一塊數據獲得的參考包絡以保證對齊質量。整個并行互相關運算就是各塊待對齊數據分別與參考包絡在各線程中并行執行互相關,執行結果合并即為粗對齊一維距離像,并行過程如圖5所示。
3.5 基于頻移因子的最小熵并行方法
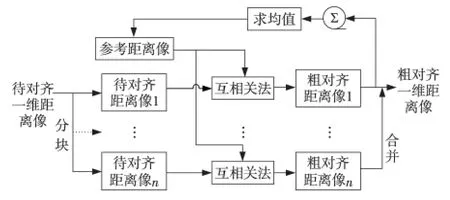
Figure 5 Parallel accumulated cross correlation algorithm圖5 積累互相關并行方法
該模塊依據處理器核數n,將粗對齊數據均勻分為n塊,第一塊數據計算得到參考距離像作為其它各塊數據的參考包絡,利用OpenMP 編譯指導指令#pragma omp section自動將各塊數據與參考數據分配到各線程,并行執行基于頻移因子的最小熵運算,并行過程如圖6所示。此時,各數據塊的數據量基本相同,運算量相當,因此各線程負載均衡,并行執行效率高。
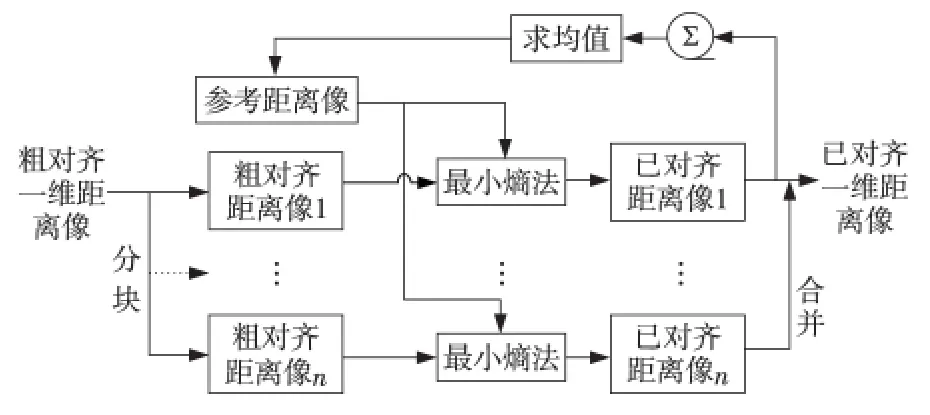
Figure 6 Parallel minimum entropy algorithm圖6 最小熵并行方法
4 實驗性能評測與結果分析
4.1 實驗性能評測標準
為方便描述并行性能,采用傳統的加速比和效率性能評價標準。加速比定義為:
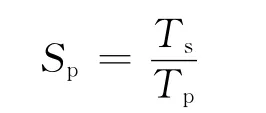
其中,Ts是串行算法單線程運行時間,Tp是并行算法在多核處理器上用P個核并行處理運行時間。
效率定義為:
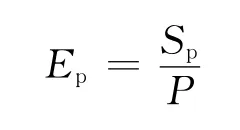
其中,P為處理器核數。相同線程下加速比越大,并行效率越高,則并行程序性能越好。
4.2 算法并行效率理論分析
本文包絡對齊并行方法為依據線程數目n對各算法輸入數據進行分塊處理,即輸入數據分為n塊共同執行各處理算法,故而理論上各算法并行執行時間為串行程序耗時的1/n倍,加速比達到n,并行效率高達100%。但是,由于算法程序無法完全并行化、計算機性能的影響以及多核處理器共享內存訪問帶寬增大訪問開銷,導致并行效率無法達到理論數值,后續工作應該盡可能減少搶占內存資源帶來的訪問開銷。
4.3 實驗結果
本文使用Microsoft Visual Studio 2010開發工具,采用OpenMP 并行編程接口設計并行優化程序。仿真實驗平臺為八核處理器Intel(R)Core(TM)i7-4770CPU @3.40GHz,16GB內存,64位操作系統。實驗數據為1 024×1 001的雷達回波數據,即單脈沖采樣點數1 024點,脈沖回波個數為1 001個,數據大小為7 104KB。
實驗分為距離壓縮和包絡對齊兩部分。為提高對齊精度,包絡對齊分兩個模塊:積累互相關對齊模塊和最小熵對齊模塊。因此,距離壓縮、互相關法和最小熵法為三個獨立模塊,包絡對齊是互相關法與最小熵法的整體執行效果。文中用單線程以及2、4、6、8個線程分別進行程序性能優化處理,為了得到更直觀的視覺效果,四個模塊的執行時間、加速比及并行效率用折線圖表示,如圖7~圖9所示。
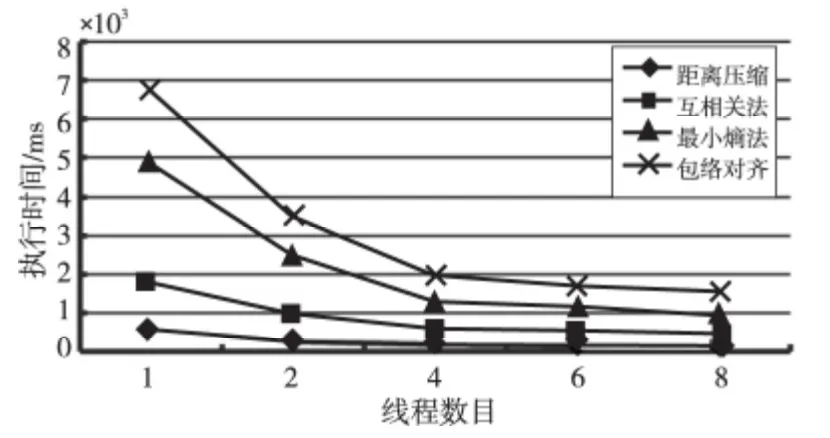
Figure 7 Execution time of the serial and parallel algorithms圖7 各算法模塊串行、并行執行時間(ms)
由圖7可知,包絡對齊法執行時間略大于互相關模塊和最小熵模塊運算時間的總和,完全符合互相關法和最小熵法共同執行得到對齊包絡的事實。距離壓縮、互相關對齊和最小熵對齊模塊中,相同線程數目下,距離壓縮處理耗時最少,最小熵法計算量最大,且隨著線程數目增加,各模塊執行時間逐漸減少,有效提高成像速度。
圖8顯示,隨著線程數目增加,各模塊加速比逐漸增大。相同線程數目下進行程序優化處理時,最小熵法加速比最大,這是因為最小熵對齊運算量最大,耗時最長,因此多線程性能優化最好。但是,包絡對齊加速比反而小于最小熵模塊加速比,這是因為互相關包絡對齊法運算復雜,多線程并行優化性能較差,抑制包絡對齊整體優化性能。
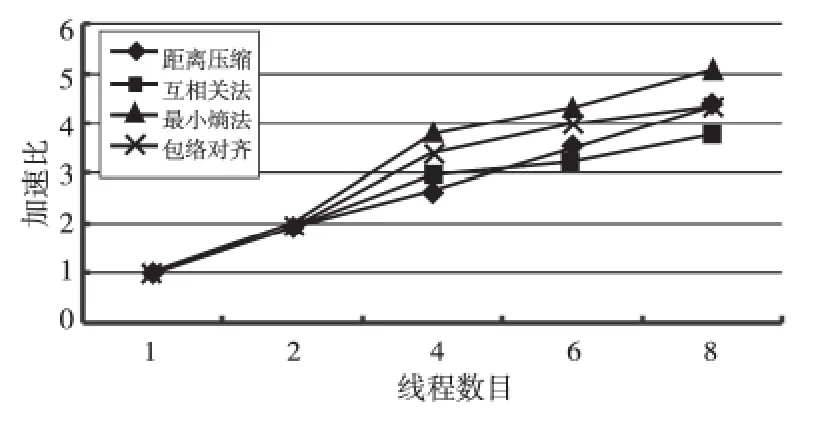
Figure 8 Speed-up of the four algorithms圖8 各算法模塊加速比
圖9為多線程并行優化效率,并行線程數目較少時,并行效率高達95%以上,隨著線程數目增加,優化效率降低,甚至八線程互相關并行效率降到50%以下,綜合圖7和圖8內容,隨著線程個數達到一定數目,程序執行時間減小速度下降且加速比增大速度降低,這是由于OpenMP 是基于共享存儲的并行編程模型,多核處理器共享內存訪問帶寬,線程過多會搶占帶寬資源,增大內存訪問開銷。但是,最小熵模塊的八線程并行效率依然在60%以上,而且最小熵法各線程并行效率和加速比都高于其他模塊,這是因為最小熵處理計算量大,并行性能優化空間大,即耗時長的程序比耗時短的程序優化效果更明顯。然而,盡管互相關法加速比不高,并行效率低,但是相對于最小熵方法,其執行時間較短,故而綜合積累互相關對齊和最小熵對齊的并行效果,包絡對齊整體優化性能較好。因此,多線程并行算法并不是線程越多越好,要根據數據量、算法計算量以及算法復雜程度選擇適當的線程數目進行并行優化。
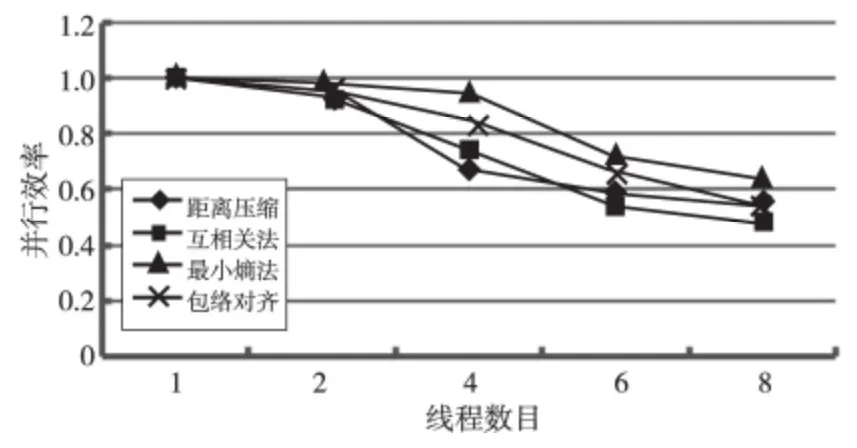
Figure 9 Parallel efficiency of the four algorithms圖9 各算法模塊并行效率
5 結束語
本文設計了基于OpenMP的包絡對齊并行方法,在多核處理器上對程序進行多線程并行優化。從減少程序執行時間和保證對齊質量著手,對計算數據分塊,各塊數據并行執行對齊任務。仿真實驗結果表明,包絡對齊的多線程并行處理有效縮短對齊時間,提高一維距離成像速度,為ISAR 成像的實時性提供條件。
本文是在多核處理器上進行包絡對齊并行優化研究,在未來的工作中,針對雷達處理上的多種復雜算法,考慮使用消息傳遞機制MPI實現多機并行優化,以及使用GPU(CUDA)實現異構加速。
[1] Chen C C,Andrews H C.Target-motion-induced radar imaging[J].IEEE Transactions on Aerospace Electronic Systems,1980,16(1):2-14.
[2] Delisle G Y,Wu H Q.Moving target imaging and trajectory computation using ISAR[J].IEEE Transactions on Aerospace Electronic Systems,1994,30(3):887-899.
[3] Xing Meng-dao,Bao Zheng,Zheng Yi-ming.Rang alignment using global optimization criterion in ISAR imaging[J].Acta Electronic Sinica,2001,29(12A):1807-1811.(in Chinese)
[4] Wang Gen-yuan,Bao Zheng.The minimum entropy criterion of range alignment in ISAR motion Compensation[C]∥Proc of Conference Radar,1997:236-239.
[5] Wang Kun,Luo Lin,Bao Zheng.Using super resolution technique improve range alignment accuracy of ISAR imaging[J].Journal of Xidian University,1997,24(Supp):109-115.(in Chinese)
[6] Liu Ai-fang,Li Yu-sheng,Zhu Xiao-hua.ISAR range alignment using improved envelope minimum entropy algorithm[J].Journal of Signal Processing,2005,21(1):49-51.(in Chinese)
[7] Shi Xin-liang,Xie Xiao-chun.GPU acceleration of range alignment based on minimum entropy criterion[C]∥Proc of IET International Radar Conference 2013,2013:1-4.
[8] Yang Jian,Du Lin-lin,Xin Yu-lin,et al.Real-time ISAR imaging of multilevel parallel processing based on R-D method[J].Journal of Astronautics,2010,31(5):1427-1432.(in Chinese)
[9] Guo Rui,Zhang Yue,Sun Gang,et al.Research on ISAR real-time imaging technology using multicore DSP[J].Journal of Signal Processing,2013,29(9):1238-1243.(in Chinese)
[10] OpenMP application program interface version 3.0[EB/OL].[2010-10-10].http://www.openmp.org/mp-documents/spec30.pdf.
[11] Cai Jia-jia,Li Ming-shi,Zheng Feng.OpenMP-based parallel computation on multi-core PC[J].Computer Technology and Development,2007,17(10):88-91.(in Chinese)
附中文參考文獻:
[3] 邢孟道,保錚,鄭義明.用整體最優準則實現ISAR 成像的包絡對齊[J].電子學報,2001,29(12A):1807-1811.
[5] 王琨,羅琳,保錚.應用超分辨技術提高逆合成孔徑雷達成像包絡對齊精度[J].西安電子科技大學學報,1997,24(增刊):109-115.
[6] 劉愛芳,李彧晟,朱曉華.用改進的包絡最小熵法進行包絡對齊[J].信號處理,2005,21(1):49-51.
[8] 楊劍,杜琳,辛玉林,等.基于多級并行處理的R-D 方法的ISAR 實時成像[J].宇航學報,2010,31(5):1427-1432.
[9] 郭瑞,張月,孫剛,等.多核DSP上的ISAR 實時成像技術研究[J].信號處理,2013,29(9):1238-1243.
[11] 蔡佳佳,李名世,鄭鋒.多核微機基于OpenMP的并行計算[J].計算機技術與發展,2007,17(10):88-91.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
時代英語·高二(2015年1期)2015-03-16 00:08:11
現代企業(2015年2期)2015-02-28 18:45:09
