數據流Eager傳輸:一種分布式流體系結構中的性能優化技術*
2015-03-19 00:36:42郭曉威林宇斐
計算機工程與科學 2015年11期
李 鑫,郭曉威,林宇斐
(1.國防科學技術大學高性能計算國家重點實驗室,湖南 長沙410073;2.國防科學技術大學研究生院,湖南 長沙410073;3.總參第六十三研究所,江蘇 南京210007)
1 引言
在互聯網上提供面向大數據計算的運行環境需要應對資源異構性、動態性、通信長延遲與帶寬有限等挑戰,現有的分布式計算模型尚存在一些不足,如云計算[1]可以實現對多種異構物理資源的統一虛擬化資源池管理,僅僅為大數據平臺提供支撐運行環境。目前主流的大數據技術,如MapReduce[2]、Spark Streaming[3]、Shark[4]、Hive[5]、Spark[6~7]等,主要是基于數據中心較穩定的大規模同構資源,對互聯網資源異構性與節點動態性的支持還存在一定不足。網格計算[8]采用了類MPI編程模型,利用中間件屏蔽資源異構性,但是其靜態綁定資源與數據的方式對資源動態性的支持還存在一定不足。P2P 計算模型[9]利用作業高度并行的特點進行分布式計算,較難適應流程復雜的應用。
近年來,流計算模型已經成功應用在高性能計算等領域,如通用圖形處理器GPGPU 和Intel Xeon Phi[10]在“Tianhe-1A”[11]與“Tianhe-2”[12]的應用,并應用于石油勘探、動漫渲染、磁約束聚變數值模擬等大規模計算與數據處理應用上,充分驗證了流計算模型的實際性能與良好應用特性。因此,針對上述挑戰與難題,作者基于流計算模型已提出了分布式流體系結構作為其解決方案,可以有效適應互聯網上不同的異構計算資源、數據格式與多種執行模式,為大數據應用提供高效、低成本的互聯網計算環境。
雖然分布式流體系結構已經挖掘了相鄰計算核心函數之間的并行性,通過計算與通信等操作的重疊以隱藏通信長延時。但是,互聯網長通信開銷仍然是一個艱巨的挑戰。在分布式流體系結構中,數據傳輸操作通常直到計算核心任務啟動操作之前才會請求執行,由主程序通知數據所在節點將數據發送到后繼計算節點,從模擬實驗結果數據分析看,在互聯網有限帶寬與長延遲的情況下,這種被動數據請求方式的通信時間會占用較長的數據等待時間(模擬實驗顯示至少占40%以上執行時間)。本文將這種被動響應數據請求的方式稱之為數據流Lazy傳輸技術,顯然,它是一種保守的數據傳輸技術,嚴格按照程序原本的順序串行執行并傳輸數據,以確保程序語義的正確性。本文提出了一種主動傳輸數據的方式,即數據流Eager傳輸技術。該技術可以將數據提前發送到目標節點,挖掘非相鄰連續計算核心間之間潛在的并行性,執行任務時不需要被動地等待數據傳輸,從而加快程序執行性能。
2 分布式流體系結構概述
2.1 基本概念
傳統的流計算模型以一種流(Stream)的觀點來組織程序結構,數據被抽象為可并行操作的數據流,應用被分解為并行執行的若干計算核心函數程序(Kernel)。Kernel可以被映射到支持程序運行的任何計算資源上,通過數據通道進行數據交換,從而簡化計算流程,提高計算效率。這使得流計算模型具有計算資源普適性、高度數據并行性與延遲計算綁定特性、流水線并行性等特性。
作者基于流計算模型提出了一種新型的分布式流體系結構DSA(Distributed Stream Architecture),在分布式環境下提供大數據運行環境,從分布式計算模型的角度出發,將所有可用的軟硬件對象定義為計算核心(Kernel),所有計算數據與控制狀態數據定義為數據流(Stream),以描述分布式流體系結構中的計算機制,刻畫其程序的執行特點,其基本概念包括:
定義1 數據流包括兩種類型:
(1)控制數據流(ControlStream):控制計算流程的數據或狀態數據;
(2)計算數據流(ComputeStream):封裝計算核心并行處理的數據。
定義2 計算核心包括六種類型:
(1)軟計算核心SK(SoftKernel):封裝計算核心程序信息的對象,其元信息包括軟件共享庫名稱、網絡位置等;
(2)硬計算核心HK(HardKernel):封裝節點內可用硬件資源信息的對象,其元信息包括網絡地址、處理器類型等;
(3)應用計算核心AK(ApplicationKernel):封裝應用程序中主程序代碼相關信息的對象,是一種特殊的SK 代碼對象,負責申請獲取資源,監控任務運行狀態;
(4)客戶管理計算核心CMK(Client Management Kernel):提供用戶查詢和請求服務的接口;
(5)資源管理計算核心RMK(Resource Management Kernel):提供命令解釋器與執行器的功能,負責向SMK 注冊本地資源信息;
(6)服務管理計算核心SMK(Service Management Kernel):提供應用服務等功能,負責維護服務(查詢、添加、刪除、更新等)與Kernel(HK、SK、AK、RMK 與CMK)的元信息,并調度軟硬件資源。
如圖1所示,以MPEG2編碼應用為例說明分布式流體系結構的運行機制,如圖1a所示,N0節點上部署了SMK,N1~N9節點上部署了RMK,N10節點上部署了CMK,且CMK 有應用程序MPEG2的主程序與各個計算核心程序。用戶運行MPEG2編碼應用的過程如下:
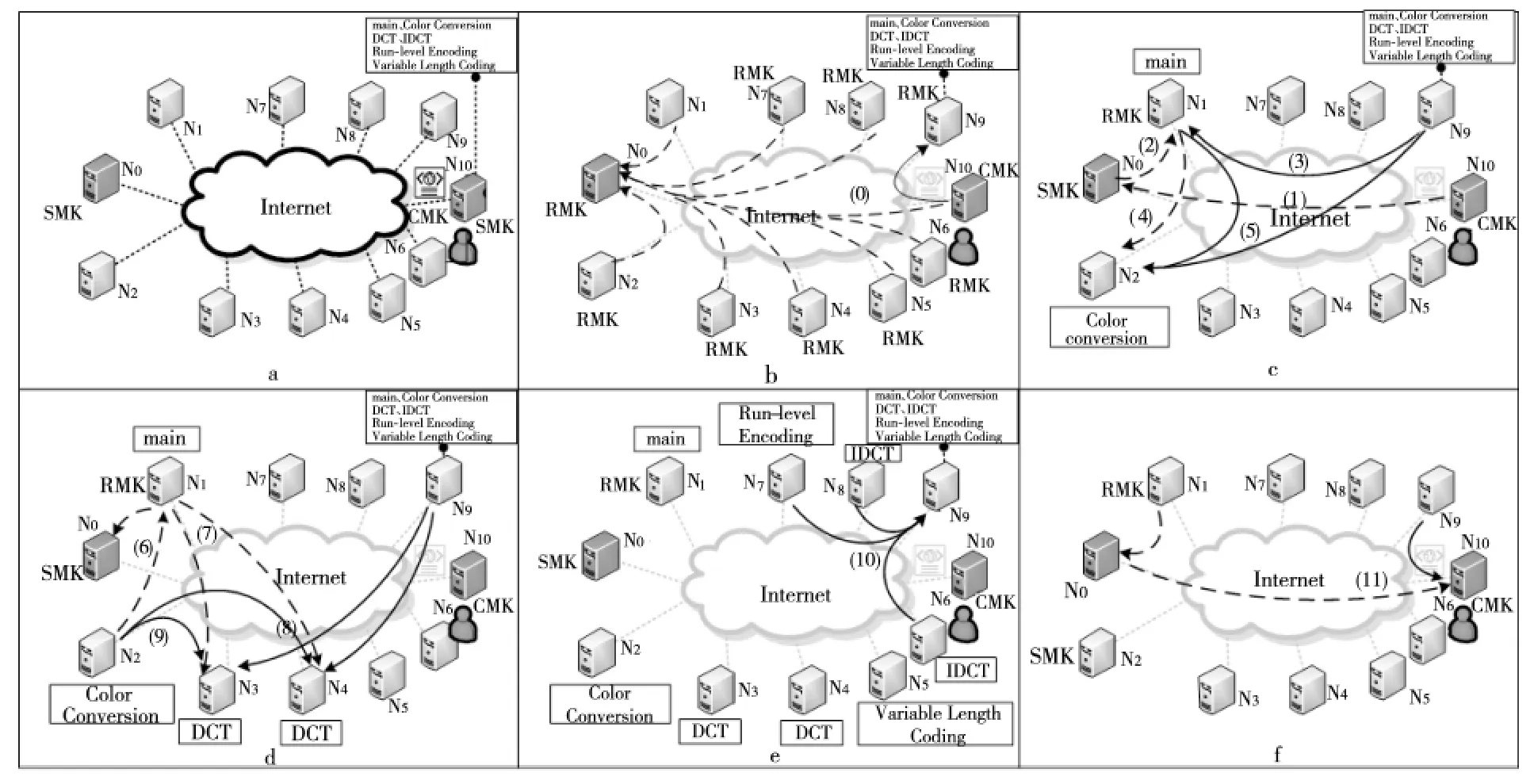
Figure 1 Execution flow diagram of the MPEG2encoding application in the distributed stream architecture圖1 在分布式流體系結構上MPEG2編碼應用執行流程圖
(1)用戶通過CMK 向SMK 申請運行應用程序,SMK 返回資源節點N9等信息,CMK 接收后將主程序以及計算核心程序上傳到N9。同時,N1~N9節點上的RMK 啟動后主動將本地硬件資源注冊到SMK 上,如圖1b所示。
(2)CMK 向SMK 申 請 啟 動MPEG2 應 用 程序,SMK 返回資源節點N1作為host主節點并啟動主程序(AK),如圖1c 的(2)所示。N1上的RMK 啟動線程從N9下載代碼及數據,并啟動AK 計算核心,如圖1c的(3)所示。
(3)當AK 執行到第一個計算核心(Color Conversion)時,AK 主動向SMK 申請計算資源,并分配得到計算節點N2作為device計算節點,AK 請求N2上的RMK 啟動線程運行該計算核心,如圖1c的(4)所示,并從N1與N9下載代碼與數據,如圖1c的(5)所示。
(4)N2在獲取計算核心代碼與輸入數據后,啟動程序(Color Conversion)執行計算任務,計算完畢后更新任務狀態與數據狀態給AK,如圖1d的(6)所示。AK 繼續執行主程序,當其執行到計算核心(DCT)時根據編譯指導語句向SMK 申請兩個節點執行代碼,SMK 分配N3與N4用于并行執行計算任務,AK 劃分子任務后通知N3與N4上的RMK 啟動線程,并下載代碼與數據啟動子任務計算,如圖1d的(7)~(9)所示。
AK 如此推進其他計算核心的執行,直至所有任務計算完畢,最后通知將輸出數據上傳到資源節點N9上,如圖1e的(10)所示。AK 通知SMK 應用程序計算完畢,請求釋放資源,SMK 主動釋放所有計算節點,重新添加到空閑資源池中,并通知CMK 從資源節點N9下載結果數據,至此,MPEG2應用運行完畢。
2.2 編程模型
分布式流體系結構編程模型Brook#提供了三種基本的編譯指導語句形式:parallel_mode、distribute與barrier,采用C 和C++標準提供的pragma機制,均以#pragma brs開頭,允許程序員以顯式的方式指明代碼區域的程序執行模式,使用時添加在代碼區域的起始與結束位置。表1展示了Brook#核心編譯指導語句的所有語法細節。從計算執行過程中數據流與計算核心的并行度看,Brook#支持四種Kernel執行模式:
(1)SKSS(Single Kernel Single Stream):即在一個計算節點上執行一個Kernel,處理單一數據流,這是最基本的執行模型,主要依靠開發節點內處理器的并行性來提升計算能力。
(2)SKMS(Single Kernel Multiple Streams):即多個計算節點執行相同的Kernel,但是處理不同的數據流,每個計算節點處理各自的數據流,通過空間并行方式或時間并行方式來提高單個Kernel處理性能,即SKMS-S與SKMS-T。該執行模式利用數據并行性將同一任務盡可能平均劃分成多個子任務執行,使其工作負載盡可能均衡。
(3)MKSS(Multiple Kernels Single Stream):即多個計算節點上執行多個Kernel以流水線方式處理同一個數據流,可以通過時間并行方式隱藏通信延遲,提高處理效率。
(4)MKMS (Multiple Kernels Multiple Streams):即多個計算節點上同時執行不同的Kernel處理不同的數據流,通過空間并行方式或時間并行方式同時執行,用于開發多個計算核心之間的并行性,即MKMS-S與MKMS-T,每個Kernel只處理相關的數據流(任務級并行)。MKSS屬于MKMS的一個特例。
分布式流編程模型Brook#可以充分利用互聯網分布式環境下的資源,能夠開發多個任務的任務級并行性與線程級并行性,挖掘程序間通信與計算的重疊操作,并提供多種性能優化技術。
表1 中 的clause 指in/out{streamName[(BLOCK/*(n),…),BLOCK/CYCLE(n)]},表示數據流輸入或輸出方向、數據流名稱、子流的數據分布方式以及與子任務的映射方式,通過該語句實現數據流空間到子任務空間的映射。

Table 1 Brook#compilation directives表1 Brook#編譯指導語句列表
2.3 資源管理系統
在分布式流體系結構中,資源管理系統一方面負責互聯網節點資源信息的維護,包括對硬件資源、軟件資源、服務以及用戶等元信息進行查詢、添加、刪除、更新等;另一方面提供調度器對用戶的資源請求進行資源調度,從資源池中選出符合請求的資源,同時實現對計算任務的監控、啟動等任務管理功能。如圖2所示,資源管理系統主要由SMK、RMK、CMK、AK、SK、HK 等組件構成。
SMK 負責維護節點資源元信息,其功能包括:
(1)負責注冊RMK 與CMK、RMK 的本地硬件信息、用戶作業的計算核心代碼等;
(2)負責管理作業的生命周期過程;
(3)負責對資源請求進行資源調度,實現不同作業的安全隔離運行。
RMK 資源管理計算核心是本地節點的命令解釋器、資源管理器與任務執行器,其功能包括:
(1)管理本地硬件資源、作業文件資源與數據資源,并提供資源請求服務;
(2)管理與監控本地計算任務,周期性發送心跳消息到SMK 更新狀態。
CMK 客戶管理計算核心類似于客戶端的功能,負責提交程序代碼(AK 或SK)以及數據到資源節點上,在SMK 上注冊作業信息,并接收結果數據。
AK應用計算核心封裝了作業主程序代碼信息,負責具體每個應用程序的執行流程,其功能包括:
(1)負責向SMK 申請資源并分配給子任務;
(2)負責通知節點RMK 啟動子任務并監控計算核心任務(SK)任務狀態;
(3)負責維護應用程序數據的一致性。
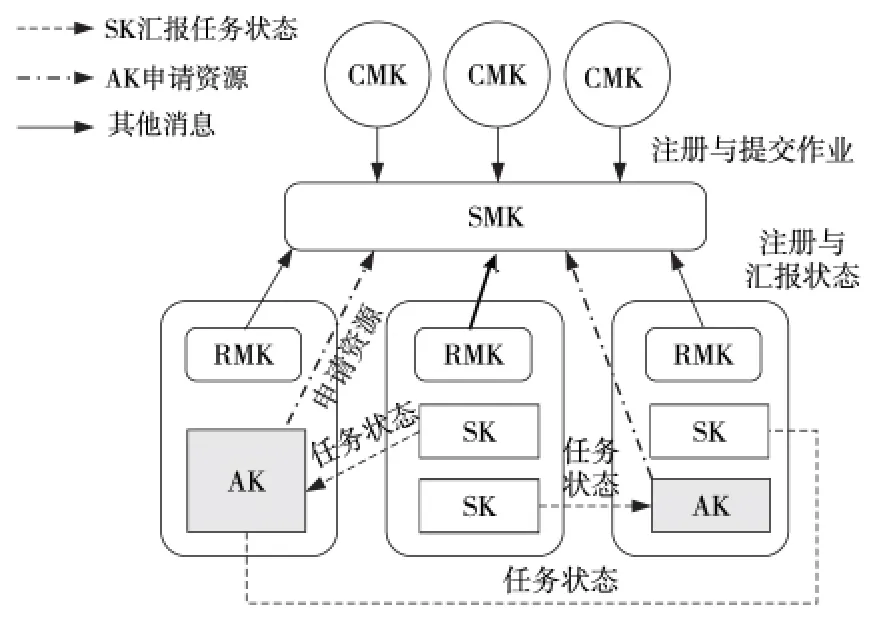
Figure 2 Resource manager system framework of the distributed stream architecture圖2 分布式流體系結構資源管理系統架構
3 數據流Eager傳輸技術
3.1 基本概念
定義3 給定一個有向圖G=〈V*,E*〉,程序每條語句都映射為圖中的節點V∈V*,語句間的執行次序關系映射為圖中的有向邊E∈E*,有向邊的方向指明語句執行順序,這樣形成的有向圖稱為程序控制依賴圖或控制流圖。
定義4 程序執行層次是指程序執行時進入分支循環結構的深度。當進入一個分支結構或循環結構時程序的執行層次增加一層,當退出同一個分支結構或循環結構時程序的執行層次減少一層。程序啟動執行時的執行層次默認為第0層。
定義5 當Kernel函數調用語句Pt0與Pt1存在控制依賴關系時,
(1)若Pt0與Pt1在同一個程序執行層次上,兩者在同一個分支結構上、循環體結構或順序結構的同一條執行路徑上,不能跨越分支循環結構層次,則稱Pt0與Pt1之間存在確定性控制依賴關系,記為[Pt0,Pt1]Dc;
(2)若Pt0與Pt1不存在確定性控制依賴關系,則稱兩者具有非確定性控制依賴關系,記為[Pt0,Pt1]UDc。
因此,分布式流程序中具有確定性控制依賴關系的計算核心需要遵循兩個基本約束規則:
(1)規則1:[Pt0,Pt1]Dc中的Pt0與Pt1是同一個層次執行路徑的必經節點,不能跨越分支循環結構,若Pt0計算核心在分支循環結構里,則Pt1不能在分支循環結構外。
(2)規則2:[Pt0,Pt1]Dc中的Pt0或Pt1可以是單個計算核心、MKMS-T 或MKMS-S并行執行模式程序塊中的計算核心,但兩者不能同時是同一個MKMS-S并行執行模式程序塊里的計算核心。
3.2 數據流Eager傳輸技術的充分條件
定義6 給定一個有向圖GK=〈V*,E*〉,程序Kernel函數調用語句都映射為圖中節點V∈V*,Kernel之間的數據依賴關系映射為圖中有向邊E∈E*,有向邊方向指明數據依賴方向,對于任意兩個Kernel函數調用語句Pt0與Pt1的映射節點Vt0與Vt1,若兩節點之間存在有向邊Et∈E*,則稱Kernel函數調用語句Pt0與Pt1之間存在數據依賴關系,記為[Pt0,Pt1]d。
定義7 給定同一個程序的控制依賴圖Gc=〈Vc,Ec〉與計算核心數據依賴圖Gd=〈Vd,Ed〉,對于其中任意兩個計算核心Kernel調用語句Pt0與Pt1,若在控制依賴圖Gc中存在確定性控制依賴關系[Pt0,Pt1]Dc,并且在數據依賴圖Gd中對應地存在數據依賴關系[Pt0,Pt1]d,則稱Pt0與Pt1之間存在控制與數據依賴關系對,記為[Pt0,Pt1]dc,簡稱Pt0與Pt1為計算核心對。
定理1 數據流Eager傳輸的充分條件是計算核心Kernel調用語句之間存在控制與數據依賴關系對。
證明 若計算核心Kernel調用語句Pt0與Pt1存在控制與數據依賴關系對[Pt0,Pt1]dc,則在控制依賴圖中一定存在確定性控制依賴關系[Pt0,Pt1]Dc,即程序執行完Pt0后才會執行Pt1,而且一定會按照兩者的依賴關系順序執行。因此,Pt0執行完畢后才會有數據傳輸給Pt1,確保數據生成、傳輸與接收操作順序的正確性。
同時,Pt0與Pt1在數據依賴圖中存在數據依賴關系[Pt0,Pt1]d,則它們之間具有明確的數據流,Pt1的輸入數據依賴于Pt0的輸出數據,因此,當Pt0計算完畢后,其輸出數據就是Pt1的輸入數據,確保了數據傳輸方向的正確性。
因此,若計算核心Kernel調用語句之間存在控制與數據依賴關系對,則可以采用數據流Eager傳輸技術提前傳輸數據到后繼目標節點上。
3.3 識別控制與數據依賴關系對的靜態編譯分析方法
本文認為分布式流計算程序是可歸約的或結構良好的,即能夠通過一系列的變換將程序歸約為單個節點,而且不存在非正常區域或非結構化區域的控制結構。靜態編譯分析方法采用結構分析的思路,將程序通過分析變換生成控制樹,找出所有符合條件的計算核心對集合。
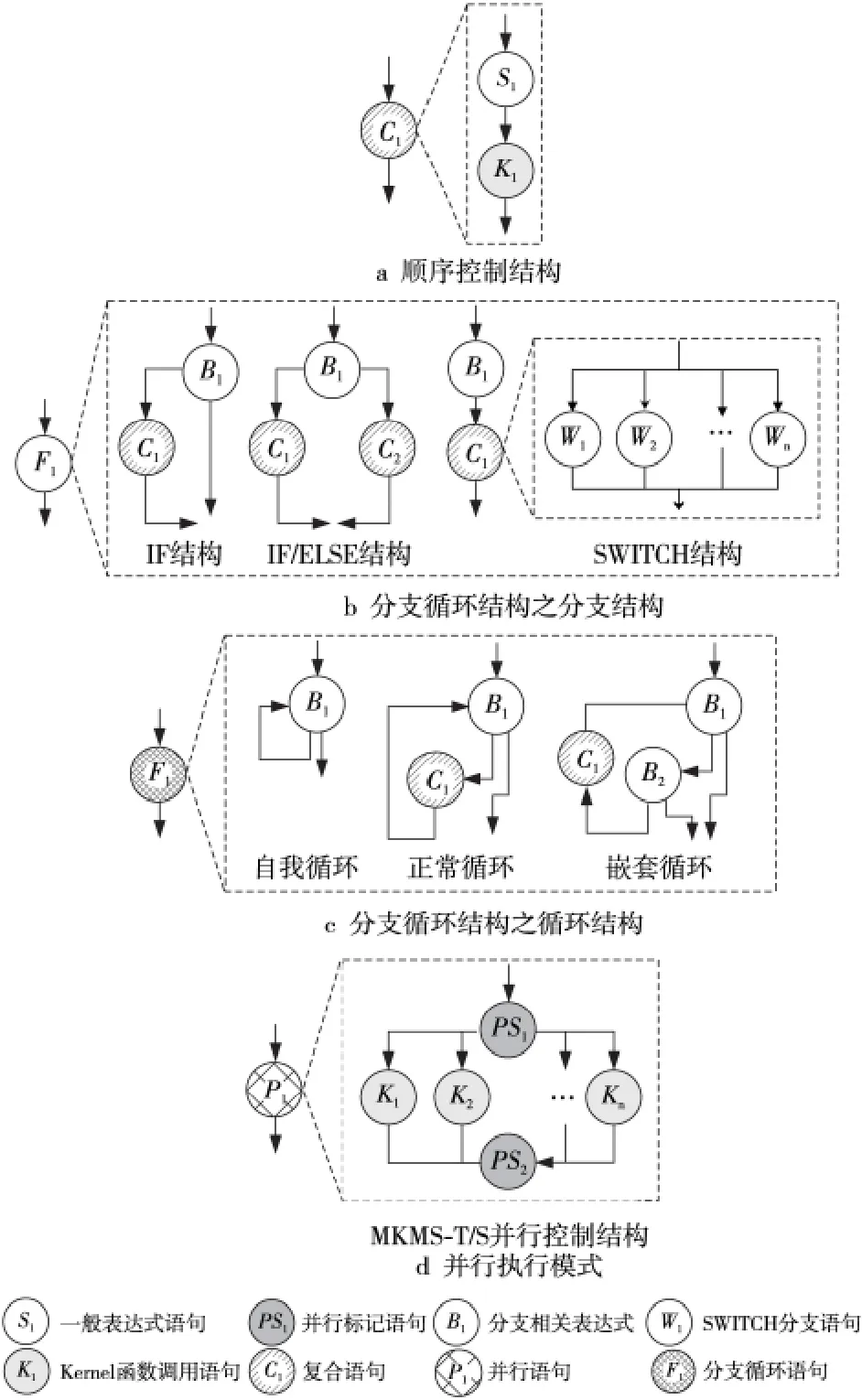
Figure 3 Three program control structures of the distributed stream computing program圖3 分布式流計算程序的三類程序控制結構
Brook#編譯器基于LALR 算法對整個程序進行分析并形成語句鏈表,根據語句相關屬性及其連接關系,將語句抽象為節點,將控制依賴關系抽象為邊,從而生成程序控制樹。其中,主程序包括六類語句:一般表達式語句與編譯指導語句、Kernel函數調用語句、SWITCH 分支語句、復合語句、分支循環語句與并行語句,且不允許出現復合語句與并行控制結構存在相互嵌套的語法,如圖3 所示。同時,編譯器將語句變換為節點,并標記節點類型:將一般表達式語句(S類型)、并行標記語句(PS類型)與Kernel函數調用語句(K 類型)都變換為葉節點,將SWITCH 分支語句(W 類型)、復合語句(C類型)、分支循環語句(F類型)與并行語句(P類型)都變換為抽象節點。這樣,程序中的每條語句與表達式都一一映射到抽象節點與葉節點上,不存在二義性問題,其中,控制樹的根節點是原來的主程序,根節點和葉節點中間的節點是三種控制結構的抽象節點,樹的邊表示每個控制結構對應抽象節點(即父節點)和那些構成該控制結構的語句(即后裔節點)之間的復合構造關系。
假設控制樹一共m層,計算核心對集合NT初始化為空,其搜索方法如下:
(1)第一遍深度優先后序遍歷控制樹:
①若當前節點NC是P類型抽象節點,則將K類型子節點放入本節點的候選計算核心集合N中,置位搜索標志位;
②若當前節點NC是C類型抽象節點,則將K類型子節點、C類型子節點與P類型子節點候選計算核心集合加入到候選計算核心集合N中,置位NC搜索標志位,并取消子節點搜索標志位;
③若當前節點NC是W類型或F類型抽象節點,則合并節點下所有子孫節點中的K類型節點的輸出流到該抽象節點輸出流集合OS。
(2)第二遍深度優先后序遍歷控制樹:
①若當前節點NC是P類型或C類型抽象節點,并且設置了搜索標志位。首先,識別出本節點候選集合N中所有存在數據依賴關系的集合NBTC,其中,后繼節點集合記為NKTC。接著,假設其子節點中存在為W類型或F類型的抽象節點,其輸出流集合為OS,則在NKTC中含有OS的后繼節點集合為NKO,則記NK=NKTC-NKO。最后,在NBTC中搜索出含有后繼節點集合NK的計算核心對集合NTC,則搜索樹的計算核心對集合NT=NT∪NTC。
②其他類型的節點均沒有設置標志位,不做任何操作。
至此,搜索存在控制與數據依賴關系對的計算核心對集合的靜態編譯方法識別過程結束,NT包含了控制樹所有存在控制與數據依賴關系對的計算核心對集合。
3.4 編譯指導語句與實現機制
在Brook#語法中增加數據流Eager傳輸技術的編譯指導語句,即

該編譯指導語句使用在指定程序段的開始和結尾處,其語義是指由編譯器分析與標記程序中的控制與數據依賴關系對集合,在計算核心執行完畢時主動發送數據。
如圖4所示案例,兩個串行執行的計算核心K1與K2均采用SKMS-S執行模式,分別劃分為四個子任務與兩個子任務來并行執行,并采用數據流Eager傳輸技術。host節點上為K1創建一個executor thread 線 程 執 行 主 程 序(AK),一 個worker thread線程與四個subworker thread線程管理子任務的執行過程,不同線程之間通過事件消息隊列來傳遞信息,其中,worker thread 與subworker thread的事件消息隊列分別簡記為wq與sq。同時,在四個device節點上創建了executor thread線程用于執行計算核心代碼(SK)。其中,host節點上:
(1)executor thread:執行AK 計算核心主 程序,管理整個程序的執行流程,它為每個計算核心啟動一個worker thread維護其計算流程,并阻塞等待當前Kernel計算完畢后才會繼續執行下一個Kernel;
(2)worker thread:負責執行對計算核心任務的所有相關操作與狀態監控,在任務結束后負責更新數據流信息,以保證數據一致性;
(3)subworker thread:負責執行對計算核心子任務的所有相關操作與狀態監控;
(4)device節點上executor thread:負責直接執行子任務的相關操作,包括請求下載數據與代碼、啟動計算執行等,并將計算完成狀態發送給主節點。
為了支持數據流Eager傳輸技術,分布式流體系結構引入了code thread線程與cq事件消息隊列,其中:
(1)code thread:負責更新采用Eager技術傳輸的數據狀態信息,以維護數據一致性;
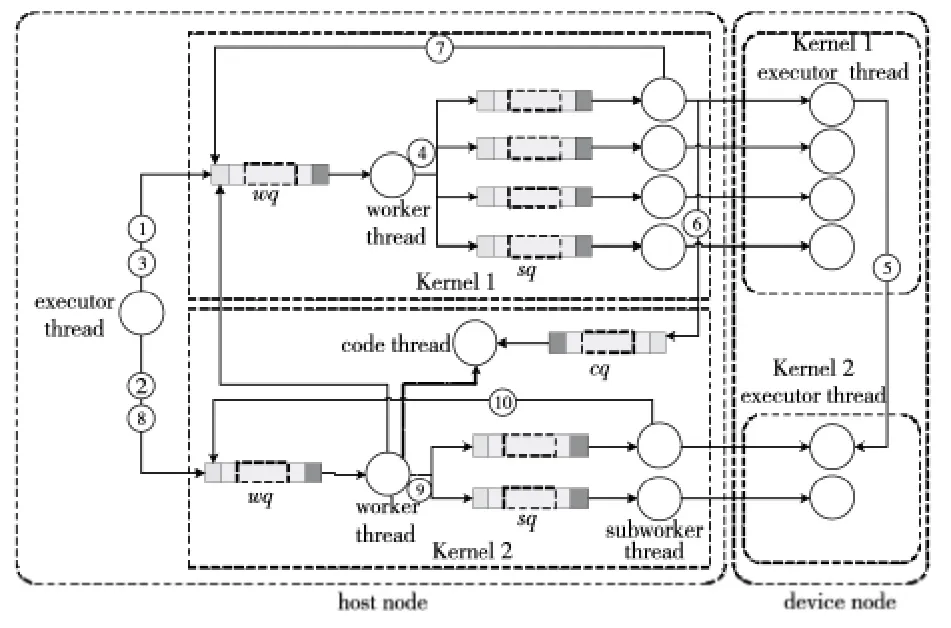
Figure 4 Organization structure of the runtime that supports the stream Eager transmission technique圖4 支持數據流Eager傳輸技術的運行時組織結構示意圖
(2)cq事件消息隊列:當Kernel子任務采用Eager傳輸技術發送完數據后,后繼Kernel的cq隊列會接收到更新的數據狀態消息。
本節采用一種線程操作表的偽代碼方法來描述分布式流體系結構技術實現的相關細節。所使用到的操作符號如表2 所示。假設計算核心K2劃分為兩個子任務并行執行,則分別記為K21與K22,使用K21.OP表示計算核心子任務K21執行相關操作OP,用ex(OP)表示當前線程執行操作OP,wq.p(OP)表示wq事件消息隊列壓入相應工作線程執行的操作OP,并交給相應的工作線程處理。
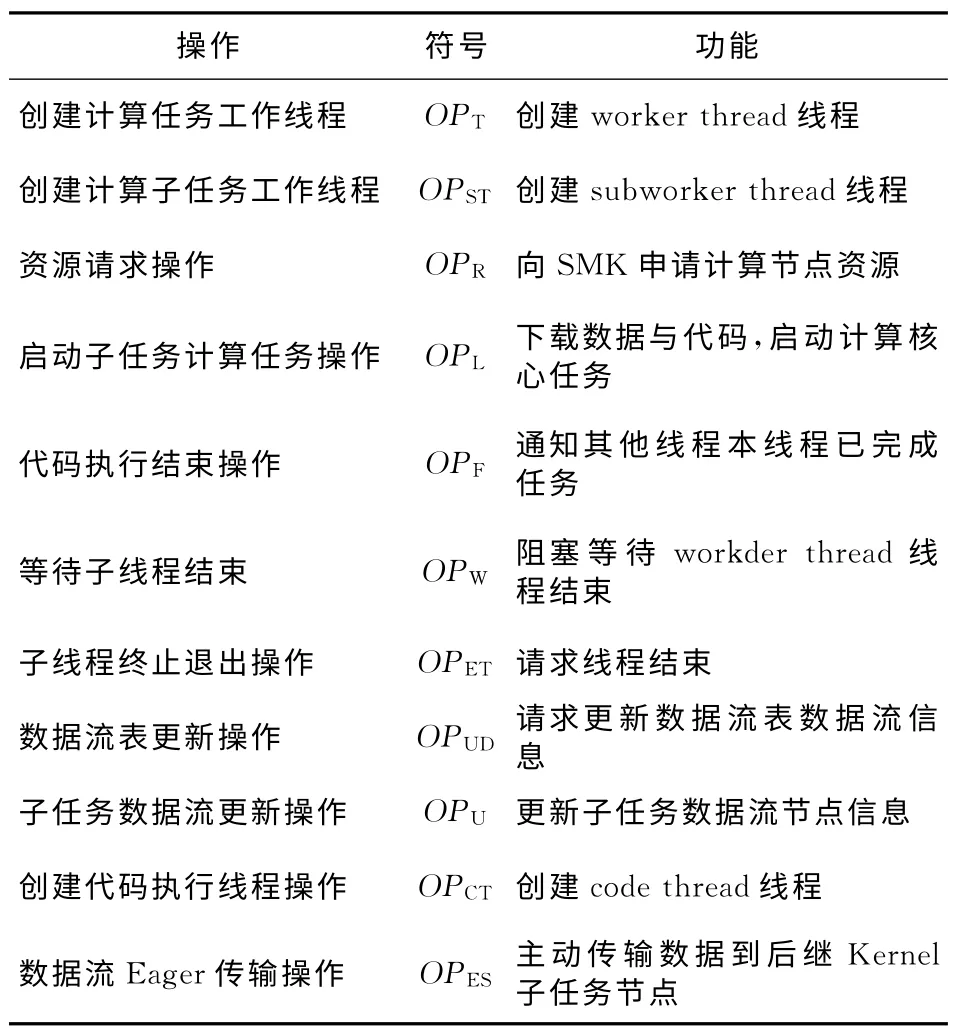
Table 2 Operation list of Kernel and Stream表2 計算核心與數據流相關操作列表
如表3所示為K1與K2計算核心在SKMS-S執行模式下各個線程的處理操作序列。表3 中executor thread列中代碼的執行順序代表了應用主程序(AK 代碼)的執行順序,同一行的操作代碼表示對應操作在不同線程中的執行流程,不同線程執行操作的先后順序是由該操作決定的,圖3最后一列指明了事件消息在各線程執行順序的大致方向。圖4中的關鍵操作都標記在表3相應的位置,且1≤i≤4,1≤j≤2,i與j均為整數,其中,host節點上:
(1)executor thread:負責執行主程序。
①ex(K1.OPT):創建work thread線程用于管理計算核心任務的執行流程;
②wq.p(K1.OPST):壓入創建子任務工作線程操作OPST,請求worker thread創建子任務工作線程;
③wq.p(K1.OPCT):壓入創建code thread線程操作OPCT,該操作只適用于存在控制與數據依賴關系對的后繼計算核心,如本例中的K2;
④ex.p(K1.OPR):請求執行申請計算資源的操作OPR;
⑤wq.p(K1.OPL):壓入wq事件消息隊列中請求worker thread執行計算任務;
⑥ex(K1.OPW):阻塞等待worker thread線程執行完計算任務;
⑦ex(K1.OPW)與ex(K2.OPW):K1與K2都需要生成等待工作線程結束的代碼,以確保當前已啟動的計算任務執行完成,由于采用了SKMS-S執行模式,則直接在當前Kernel執行處的最后位置生成K.OPW語句。
(2)worker thread:負責管理計算核心任務執行過程,通過讀取并解析wq事件消息隊列中的事件消息來執行相關操作。
①ex(K1i.OPST):根據當前計算核心子任務數目創建相應數目的subworker thread用于管理子任務的實際執行過程;
②sq.p(K1i.OPL):向sq事件消息隊列中壓入子任務請求計算任務的操作OPL,如圖4與表3中標記②所示;
③ex(K1.OPUD):當發現子任務執行完畢時,主動更新當前計算核心的輸出流節點信息與已完成的子任務信息;
④ex(K1.OPET):當更新完數據流信息時,worker thread主動退出工作線程,以響應executor thread等待工作線程結束的阻塞操作ex(K1.OPW),使其可以正常繼續執行。
(3)subworker thread:負責管理計算核心子任務的執行過程,通過讀取解析sq事件消息隊列中的消息來執行相關操作。

Table 3 Thread operations in the stream Eager transform technique表3 數據流Eager傳輸技術中各線程操作表
①ex(K1i.OPL):根據分配的資源信息請求遠程RMK執行子任務;
②wq.p(K1i.OPF):子任務計算完畢后將狀態反饋給workerthread,將OPF操作壓入wq隊列,該操作如圖4與表3中標記③所示;
③ex(K1i.OPU):當子任務計算完畢后,其工作線程主動將計算完畢后的數據流狀態更新到主執行線程(AK代碼);
④ex(K1i.OPES):若當前計算核心K1采用數據流Eager傳輸技術,則對所有后繼Kernel(K2)執行數據傳輸操作,發送數據到K2綁定的節點,完成后通過K2.cq.p(K1i.OPES)操作通知后繼Kernel的code thread進一步處理。
(4)code thread:接收處理前驅Kernel發送來的數據狀態消息,若是OPES操作,說明前驅Kernel相應的子任務計算完畢,且相應數據已經傳輸到目的節點,則codethread更新相應數據流狀態到全局信息中。
如上所述,分布式流體系結構基于改進的組織結構可以有效支持數據流Eager傳輸技術,盡可能使得通信與計算相互重疊,以減少程序等待數據傳輸的時間。
4 實驗驗證
4.1 實驗方法
本文在由10個節點組成的互連網絡上完成整個實驗評估,其中,每個節點都是由一個多核CPU組成,實驗平臺參數如表4所示。實驗測試用例采用NAS Grid Benchmarks(NGB)3.1中的Visualization Pipe(VP)與Mixed Bag(MB)兩個用例,都是由單個NPB 實例求解器(BT、SP、LU、MG 或FT)組成的串行數據流處理模式,涉及到多個任務(計算核心函數)的交互與數據通信,代表了兩種典型的程序執行模型。同時,它們在不同實例求解器之間使用MF 過濾器來轉換數據,其中每一個NPB實例求解器都必須按照順序依次執行。本文選取兩個用例各自反復執行兩次的數據流流程作為實驗測試用例,每個實例求解器與過濾器都封裝為一個計算核心,計算核心均采用CPU 代碼,使用Brook#語言移植到分布式流體系結構上,在主程序中所有計算核心都是順序執行的,并通過模擬的方法產生原始數據到達CMK1。每個測試用例執行流程如圖5所示,計算核心之間的連線表示存在數據依賴關系。

Table 4 Parameter list of the experimental platform表4 實驗平臺參數列表
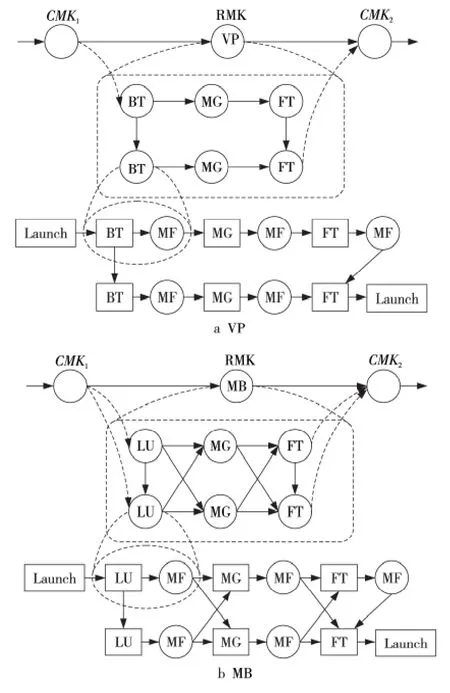
Figure 5 Schematic diagrams of the computing process in test case VP and MB圖5 實驗測試用例VP與MB的計算流程示意圖
本文在實驗中通過測量wall-clock執行時間記錄實驗結果,其中,國際互聯網延時采用Internet Traffic Report網站統計中2015年五大洲延遲時間平均值100ms,國際互聯網帶寬Speedtest在2013年180多個國家與地區測量帶寬的30 天移動平均值13.98 Mbps進行模擬,其余時間都采用實際測試的時間統計數據,包括任務計算執行時間、軟件控制開銷等。
本文采用的實驗基準程序是未采用數據傳輸優化技術的程序版本,即只使用了Lazy被動傳輸技術,只有當任務執行時才會請求數據傳輸。本文實驗同時測試采用了數據流Eager傳輸優化技術的程序版本,通過比較這兩個程序版本的執行時間,以減少的執行時間開銷來評估數據流Eager傳輸技術的有效性。在實驗中本文采用了A與B兩個規模級別的測試集,以評估其在不同規模下的效果,如VP.A就表示采用了A級別測試集的VP測試用例。
4.2 實驗結果
如圖6 所示,在采用數據流Eager傳輸技術后,在分布式流體系結構下的各個測試用例在性能上都獲得了不同程度的提升,執行時間開銷平均下降了19.58%。
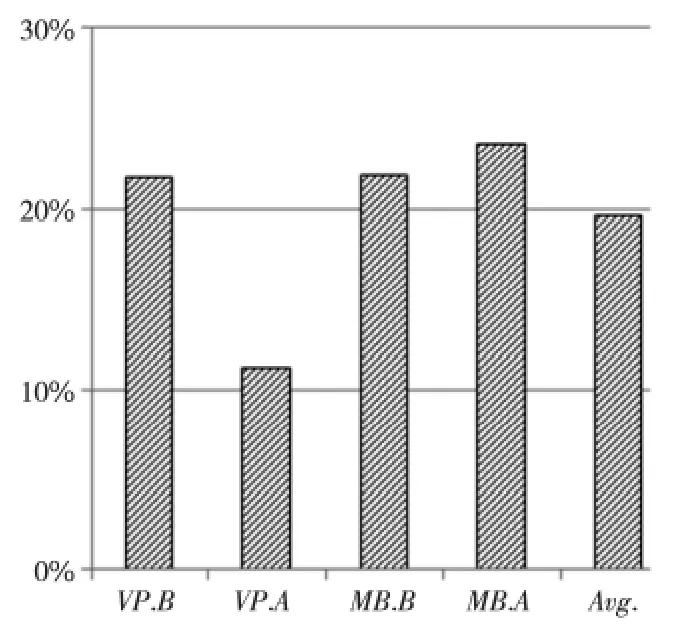
Figure 6 Reduction percentage of the execution time of test benchmarks with the stream Eager transmission technique圖6 采用數據流Eager傳輸技術后測試用例執行時間開銷下降的百分比
當采用數據流Eager傳輸技術時,VP測試用例中的各個計算核心(BT、MG與FT)之間是以流水線方式形成計算流程的,其中,計算核心BT 與FT 可以在計算完畢后主動將數據傳輸給下一個循環執行過程對應的BT與FT,并與其他計算通信過程重疊起來,而不需要按照串行執行順序等到執行該計算核心時才啟動數據傳輸。在VP.A測試用例中,BT的執行時間較長而FT 通信時間較短,而在VP.B測試用例中,BT的執行時間較短而FT 通信時間較長,這使得兩者執行時的性能關鍵路徑是不同的,VP.B中在FT通信未結束前就完成其他執行路徑上的計算過程。這樣,VP.B在關鍵路徑上就不需要等待BT較長的數據傳輸時間,而在原來采用Lazy被動傳輸技術的版本中,第二個BT 的數據傳輸必須等待計算任務執行時才能開始,從而需要的執行時間相對較長。因此,VP.A與VP.B兩者的優化效果差別較大,VP.A的時間開銷降低了11.18%,而VP.B降低了21.75%的時間開銷。
MB測試用例中的各個計算核心(LU、MG 與FT,其中MB.B還包含BT 計算核心)是以混合交叉方式傳輸數據形成計算過程的,其中,前一階段的計算核心結束后可以直接向后面依賴的兩個計算核心傳輸數據,同樣不需要等待后面兩個計算核心啟動時才被動傳輸數據。BT 與LU 的執行時間較長,它們的通信時間可以被有效隱藏,而MG 與FT 的通信時間較長而執行時間相對較短,因此,MB 的兩個循環執行過程對應的通信過程可以相互重疊,使得MB.A與MB.B的優化效果相差不大,分別達到21.81%與23.58%。
通過以上分析可見,數據流Eager傳輸技術可以開發潛在的通信與其他操作的并行性,降低應用程序執行時間,提升計算性能。
5 結束語
互聯網較長的通信開銷等制約了應用在分布式流體系結構下的計算性能,為了充分挖掘計算與通信之間的并行性,本文提出了一種面向分布式流體系結構的性能優化技術,即數據流Eager傳輸技術,并在分布式體系結構原型系統中實現了該技術。實驗結果驗證了該優化技術的有效性,表明該優化技術能夠顯著提高應用的性能,具有良好的應用前景。
下一步研究工作將針對通信帶寬等特點定制自適應優化策略,通過被動感知通信環境的方式改進資源調度策略,引入人工智能算法,基于主動分析與被動感知策略相結合的方法來提高系統通信的效率。
本文的主要創新工作在第3節,描述了數據流Eager傳輸優化技術的基本原理和設計實現機制。第2節概述了作者已提出的分布式流體系結構,第4節和第5節分別是實驗結果與結束語。
[1] Mell P,Grance T.The NIST definition of cloud computing[R].NIST,2011.
[2] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters [J].Communications of the ACM,2008,51(1):107-113.
[3] Zaharia M,Das T,Li H,et al.Discretized streams:Faulttolerant streaming computation at scale[C]∥Proc of the 24th ACM Symposium on Operating Systems Principles,2013:423-438.
[4] Xin R S,Rosen J,Zaharia M,et al.Shark:SQL and rich analytics at scale[C]∥Proc of the 2013ACM SIGMOD International Conference on Management of DataACM,2013:13-24.
[5] Thusoo A,Sarma J S,Jain N,et al.Hive-apetabyte scale data warehouse using Hadoop[C]∥Proc of IEEE 26th International Conference on Data Engineering,2010:996-1005.
[6] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:A fault-tolerant abstraction for in-Memory cluster computing[C]∥Proc of the 9th USENIX Conference on Networked Systems Design and Implementation,2012:2.
[7] Zaharia M,Chowdhury M,Franklin M J,et al.Spark:Cluster computing with working sets[C]∥Proc of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010:10.
[8] Foster I,Kesselman C.The Grid 2:Blueprint for a new computing infrastructure[M].New York:Elsevier,2003.
[9] Chawathe Y,Ratnasamy S,Breslau L,et al.Making gnutella-like P2Psystems scalable[C]∥Proc of the 2003Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications,2003:407-418.
[10] Jeffers J,Reinders J.Intel Xeon Phi coprocessor high-performance programming[J].San Francisco:Morgan Kaufmann,2013.
[11] Xie M,Lu Y,Liu L,et al.Implementation and evaluation of network interface and message passing services for Tian-He-1Asupercomputer[C]∥Proc of the 2011 19th Annual IEEE Symposium on High Performance Interconnects,2011:78-86.
[12] Xue W,Yang C,Fu H,et al.Enabling and scaling aglobal shallow-water atmospheric model on Tianhe-2[C]∥Proc of the 2014IEEE 28th International Parallel and Distributed Processing Symposium,2014:745-754.
