云環境下基于Bayesian主觀信任模型的動態級調度算法*
2015-03-19 00:33:20王福成朱桂宏
計算機工程與科學 2015年11期
關鍵詞:資源
齊 平,王福成,朱桂宏
(銅陵學院數學與計算機學院,安徽 銅陵244000)
1 引言
云計算(Cloud Computing)是繼并行計算、分布式計算、網格計算后的新型計算模式[1]。云計算平臺利用虛擬化技術將多種計算資源(包括網絡、服務器、存儲、應用和服務等)在云端進行整合,對資源進行統一管理和調度,使得這些資源可以根據負載的變化動態配置,以達到最優化的資源利用率。因此,采用何種資源提供策略對這些大規模資源進行組織和管理,實現資源提供的高效靈活和按需分配,對云計算具有重要意義。
近些年在云計算資源管理方面已有了較多的研究,針對不同的計算任務和優化目標,云資源調度算法可以分為以下幾類:(1)以提高資源利用率和降低任務完成時間為目標[2,3];(2)以降低 云計算中心能耗為目標[4~6];(3)以提 高 用戶QoS(Quality of Service)為目標[7,8];(4)基于經濟學的云資源管理模型研究[9,10];(5)多目標優化的混合算法[11,12]。
然而,由于云環境中包含著大量分散、異構資源,這些資源不僅地理位置分布廣泛,甚至屬于不同的自治系統,因而這些資源節點往往具有動態性、異構性、開放性、自愿性、不確定性、欺騙性等特征。云服務的可靠性是指用戶提交的服務被成功完成的概率,是從用戶的角度反映云完成用戶提交服務的執行能力。在擁有無數資源節點的云環境中,節點的不可靠不可避免,因此如何獲取可信的云資源,并將應用任務分配到值得信任的資源節點上執行成為云資源調度算法研究中急需解決的關鍵問題之一。
目前,在國內外分布式系統資源管理的相關研究中,有關如何獲取可信資源的研究已經取得了不少成果。Dogan A 等人首先提出了RDLS(Reliable Dynamic Level Scheduling)算法,研究如何在異構分布式系統中獲取可信資源[13,14]。在此基礎上,隨后的研究包括:Dai Yuan-sun等人[15]提出了網格服務可靠性概念,采用最小檔案擴展樹對網格服務可靠性進行了求解;Levitin G[16]針對星型網格,提出了考慮服務可靠性和服務性能的信任評估算法;Foster I等人[17]將云服務和網格服務進行比較,給出了云服務可靠性的評估方法。上述文獻采用不同的信任模型,從不同角度研究網格服務、云服務的可靠性,并給出了相應的調度算法,有效地提高了任務執行的成功率。
然而,自從Blaze M[18]首先提出了信任管理概念后,Josang A 等人[19,20]引入證據空間(Evidence Space)的概念,以描述二項事件后驗概率的Beta分布函數為基礎,將信任分為直接信任和推薦信任,根據節點間交互的肯定經驗和否定經驗計算出實體能夠完成任務的概率,并以此概率作為實體信任度的度量。基于證據的信任模型都是通過量化實體行為和計算實體信任度來評估實體間的相互信任關系。而在上述研究中,建立的信任評估模型并未考慮資源節點本身的行為特性。文獻[21,22]在此基礎上,綜合考慮時間、權重等相關因素,利用Bayesian方法構造了一個基于節點行為的可信度評估模型,并將其引入網格服務、云服務的可靠性研究中,分別提出了Trust-DLS和Cloud-DLS 算法。
在文獻[21,22]所提出的算法中,通常假設資源分配具有公平性,即在有限的資源條件下,節點之間不會因為爭奪資源而相互影響,造成損害,任意兩對節點之間的交互都是獨立的,交互信息都是真實可靠的。然而,在真實的云環境中,為得到更多的資源,節點可能會通過需求欺騙、長期占用等手段非法使用資源,成為自私節點而對資源分配的公平性造成破壞;此外,在非可信網絡環境中,節點也有可能被攻擊而成為惡意節點,提供虛假的交互信息。這些自私節點和惡意節點蠶食系統資源,在破壞資源分配公平性的同時,使得云平臺內正常節點因資源需求無法滿足而不能正常作業,從而降低系統的可靠性。節點間交互過程中可能出現的這些威脅,都會導致作為信任值評估證據的樣本空間不一定完整和可靠,因而現有的信任評估模型不太適用。
Bayesian方法是建立在主觀概率的基礎上,通過對歷史經驗、各方面信息等客觀情況的了解,再進行分析推理后得到的對特定事件發生可能性大小的度量,本文借鑒社會學中人際關系信任模型,旨在構造一種云環境下基于Bayesian方法的主觀信任管理模型。本文提出的Bayesian主觀信任模型是在文獻[21,22]基礎上,并對其進行了較大的擴充,主要體現在以下幾點:(1)研究了信任的定義、描述、評估方法和合成、傳遞、推導機制;(2)針對原有信任模型對推薦信任關系的評估較為簡單的問題,細化了推薦信任關系及相應的評估方法;(3)考慮網絡中節點的不確定性、欺騙性等問題,研究風險因素,引入了懲罰機制和分級剪枝過濾機制。最后將該模型引入傳統的DLS算法中,提出了基于Bayesian主觀信任管理模型的動態級調度算法,仿真實驗結果表明,提出的BST-DLS 算法能夠以較小的調度長度為代價,有效地提高云環境下任務執行的成功率。
2 Bayesian主觀信任模型
人們在生活中進行各種各樣的交易、交互和通信都是基于一個基礎理念——信任。信任本質上是一個社會心理關系,在人際關系網絡中,信任是對他人可信行為的評價,而個體的可信與否往往取決于其他個體的推薦。云計算平臺下的資源節點與人際關系網絡中的個體具有很大的相似性,這表現在以下幾點:(1)節點在和其他資源節點交互時,會留下反映其行為特征的交互信息;(2)不同的節點可以通過其不同的主觀判斷標準選擇交互節點,節點具備信任的主觀性;(3)節點之間的交互關系可以是一對一、一對多,也有可能是多對多或者多對一;(4)和信任關系類似,節點間的交互具有一定的傳遞性。因此,云環境下的資源節點可以根據其歷史交互經驗進行信任評估。
在信任評估模型中,節點間信任關系分為兩類:一類為直接信任關系,如圖1a所示,當節點i和節點j之間存在可作為可信度評估依據的直接交互,即可以設法估算出直接交互成功的概率,稱為直接信任度評估,用Tdt表示直接信任度;另一類為推薦信任關系,如圖1b所示,當節點i和節點j之間不存在可作為可信度評估的直接交互,而節點i可以獲取其他節點(例如節點k)關于節點j的可作為可信度評估依據的交互,這種需要通過第三方來建立的信任關系,稱為推薦信任度評估,用Trt表示推薦信任度。

Figure 1 Trust relationship among nodes圖1 節點間信任關系
當同時存在直接信任關系和推薦信任關系時,如圖1c所示,為混合信任關系,需要將上述兩種信任關系進行合并,得到總體的信任評估。如同在人際關系網絡中,當個體之間進行信任評估時,往往既存在直接信任關系也存在推薦信任關系,不同的個體由于其個性、情緒等主觀因素不同,具有不同的量化判斷標準。本文選擇線性函數作為兩種信任關系的合并函數,如式(1)所示:

其中,λ表示個體對兩種信任關系的調節因子,當0<λ<0.5時,表示個體更信任推薦信任關系,而當λ>0.5時,表示個體相信直接交互經驗超過其他個體的推薦經驗。
2.1 直接信任關系
直接信任是節點根據歷史交互經驗,對目標節點未來行為的主觀期望,在這里借鑒文獻[23]提出的模型,根據二項事件后驗概率分布服從Beta分布來求解信任值。設兩個云資源節點i和j,使用二項事件(交互成功/交互失敗)描述它們之間的交互結果;當節點i和j之間發生n次交互后,其中成功交互的次數為α,失敗交互的次數為β;同時假設隨機變量x為一次交互過程中獲得成功的概率,且x服從(0,1)的均勻分布U(0,1)。定義i對j的直接信任度Tdt為:

由式(2)可以看出,直接信任關系的評估與節點間成功交互次數以及總交互次數有關。雖然通過式(2)可以得到節點間的直接信任度,然而當節點間沒有交互或者交互較少時,較少的樣本數將不足以評估節點間直接信任關系。
針對該問題,本文使用區間估計理論[24]對信任度的置信水平進行度量,設(Tdt-δ,Tdt+δ)為直接信任度Tdt的置信度為γ的置信區間,δ為可接受誤差,則Tdt的置信度γ計算公式如下:
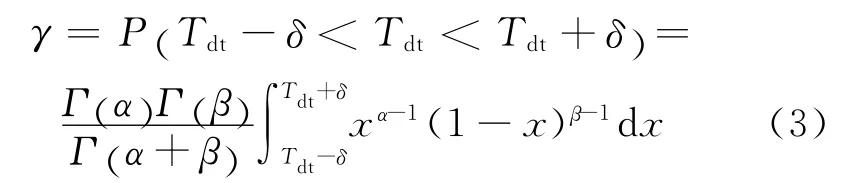
由于區間估計的置信度與精度相互制約,因此先選定置信度閾值為γ0,然后通過增加總的交互次數n提高精度,直到達到可接受水平,即γ≥γ0時,可以根據這時的直接交互信息進行信任度計算。此時的樣本容量n0、可接受誤差δ和置信度閾值γ0之間的關系由式(4)給出:
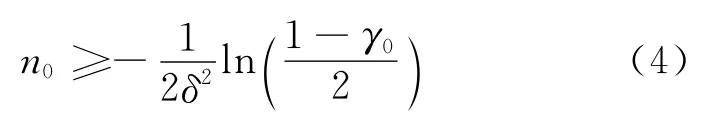
通過上述分析可知,根據節點間直接交互樣本的置信度值,可以將直接信任關系評估作如下設定:(1)當節點間不存在直接交互,或交互樣本置信度值γ<γ0時,設定節點間的直接信任度Tdt=1/2;(2)當交互樣本置信度值γ≥γ0時,節點間的直接信任度Tdt按照式(2)計算。
2.2 推薦信任關系
推薦信任關系由兩類或多類直接交互關系形成,由于推薦信任關系涉及多方實體的交互關系,因而較難評估,這表現在:(1)根據推薦節點之間的相互關系,可以把推薦信任關系進一步分為單徑信任推薦關系和多徑信任推薦關系;(2)由于惡意節點和自私節點的存在,在推薦信任關系中,并不能保證所有的推薦者都是可信的,也不能確定所有可信的推薦者所推薦的信息都是準確的。
因此,針對推薦信任關系的上述特點,借鑒人類接受推薦信息的心理過程,本文利用Bayesian方法模擬人類判斷推薦信息的認知模型,建立抵御惡意節點推薦的機制,使得信任模型更加合理。
2.2.1 單徑推薦信任關系
如圖2所示為單徑推薦信任關系模型,在單徑推薦信任關系傳遞過程中,推薦信任的傳遞由節點間的信任關系和該信任關系的可靠程度(即信任強度)構成。
定義1 信任強度是指在推薦信任傳遞的過程中,節點間信任關系的可靠程度;它刻畫了主體節點對中間推薦節點和目標節點之間信任關系的相信程度。信任強度用S表示,且滿足0≤S≤1。
定義2 推薦信任關系由中間推薦節點對目標節點的信任關系和該信任關系的可靠程度組成,可以表示為推薦信任向量(T,S)。

Figure 2 Recommendation trust relationship(single path)圖2 單徑推薦信任關系
圖2a為含有三個節點的二級單徑推薦關系,設節點i對中間推薦節點k的直接信任度為節點k對目標節點j的直接信任度為則節點j向節點i傳遞的推薦信任向量為(Tkj,Skj)。其中Skj定義為主體節點i對節點k傳遞信任信息的相信程度,因此滿足式(5):
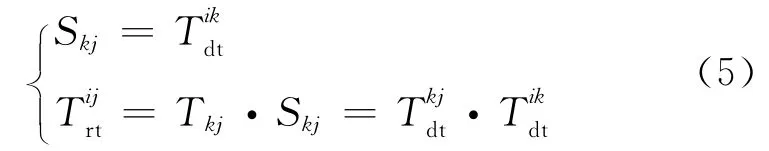
圖2b為含有四個節點的三級單徑推薦關系,設節點i、s、k、j之間的直接信任度分別為和則節點j向節點s和節點i傳遞的推薦信任向量為(Tkj,Skj)和(Tsj,Ssj),滿足式(6):
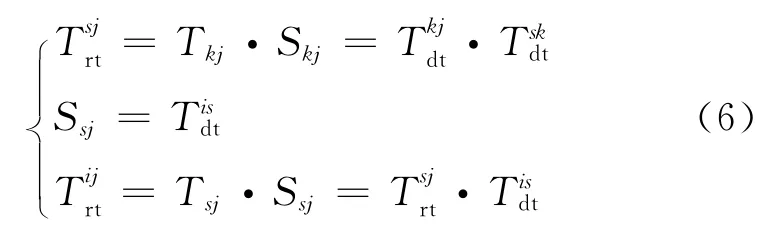
同理可以得到多級單徑推薦關系的評估方法,當存在n個節點(1,2…,n)的n-1級單徑推薦關系時,節點n對節點1 的推薦信任向量為(T2n,S2n),其中
通過上述公式可以發現,推薦信任在傳遞的過程中經過了若干中間推薦節點,推薦信任值發生了衰減。而這正符合人類判斷推薦信息的認知模型,即經過多人傳遞的推薦信息,其可信度逐漸降低。
2.2.2 多徑推薦信任關系
在云平臺中,資源節點之間常常有多條路徑,圖3所示為兩條路徑的推薦信任關系模型:包含路徑{i,k,s,j}和路徑{i,d,f,j}。設節點j通過兩條路徑向i傳遞的推薦信任向量分別為(Tkj,Skj)和(Tdj,Sdj),那么節點i可以根據式(7)得到節點j的多徑推薦信任。
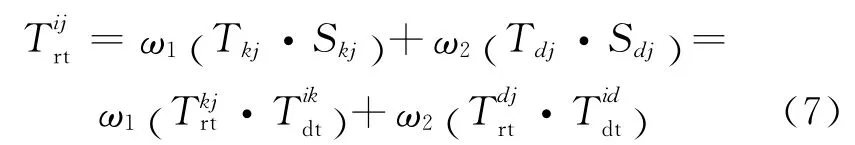
其中,ω1和ω2為兩條路徑推薦信任的權重,有ω1=Skj/(Skj+Sdj),ω2=Sdj/(Skj+Sdj)。同理可以得到多級(n級)多徑推薦信任關系模型。設多條路徑推薦信任向量分別為{(T1,S1),(T2,S2),…,(Tn,Sn)},那么節點i可以根據式(8)得到節點j的多徑推薦信任。


Figure 3 Recommendation trust relationship(multipath)圖3 多徑推薦信任關系
2.2.3 推薦信任關系的進一步討論
在實際的云計算平臺中,云資源節點除正常節點外,通常同時還存在自私節點和惡意節點,因此并不能保證所有推薦節點傳遞的推薦信息都是非惡意的。同時,當推薦路徑中存在惡意節點時,該推薦路徑傳遞的推薦信息也是不合理的。惡意節點和惡意推薦往往會提供虛假的交互信息或篡改歷史交互結果,導致作為信任值評估證據的樣本空間不一定完整和可靠。
針對上述問題,本文在評估推薦信任關系之前,首先建立分級剪枝過濾機制,過濾偏離直接信任度過大的推薦和可信度較低的推薦;再通過懲罰機制對多徑推薦信任的終點是同一推薦節點這一易出現惡意推薦的情況進行討論。
(1)分級剪枝過濾機制。
如前文所述,節點可以通過搜索網絡中的其他節點和目標節點的歷史交互信息獲取推薦信任關系。在多徑推薦信任關系模型中,主體節點和目標節點之間往往會存在多條推薦路徑(推薦路徑可以為一個推薦節點,也可以由多個推薦節點組成的多級推薦關系)。然而,由于惡意節點的存在,并不是所有的推薦信息都是可靠的,因此需要過濾掉惡意和無用的推薦信息。參照人類接受推薦的認知過程可知:①可信度較低的推薦者的推薦信息參考價值較低;②偏離直接交互經驗或心理預期較大的推薦難以接受。因此,本文使用分級剪枝過濾機制在可選推薦路徑中篩選有用的推薦信息,對推薦信任度較低或推薦偏差較大的推薦進行剪枝過濾。
定義3(推薦偏差) 設節點i和節點j的直接信任度為推薦路徑Pk的推薦信任度為則推薦偏差dk為:
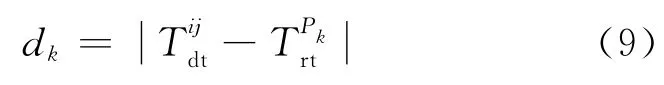
其中,推薦路徑Pk推薦信任度的偏差dk越大,被接受的可能性越小,當節點i和節點j不存在直接交互時,設定直接信任度的值為1/2。
對于信任度較高的推薦,如果其推薦偏差較大,在一定的偏差范圍內可以接受該推薦,而對于信任度較低的推薦,可接受的偏差范圍則較小。本文使用文獻[25]提出的信任等級劃分方法,對推薦路徑按照其信任度的不同劃分其等級,并提供不同的可接受范圍。信任等級劃分方法如式(10)所示:

其中,x表示信任度,l(x)表示其信任等級。
按照信任度劃分為不同信任等級后,其分級剪枝過濾過程如下:
①對于推薦路徑{P1,P2,…,Pn},根據路徑推薦信任度將其劃分為l+1個等級,按照不同的等級包含在不同的推薦路徑集合{Pk}l中,對每一信任等級l,其可接受推薦偏差為εl。
②設0<m<l,對于信任等級低于m的較低信任度的推薦路徑集合進行剪枝,排除低信任度的推薦路徑。
③對于剩余推薦路徑集合{Pk}(l|l>m),推薦路徑Pk的可接受范圍由其推薦偏差決定,如式(11)所示:

(2)懲罰機制。
在多徑推薦信任關系模型中,當多條推薦路徑的終點為同一推薦節點時,如果該節點恰好為惡意節點進行惡意的信任推薦,那么最終得到的評估結果一定是不合理的。如圖4所示,當推薦路徑{i,k,s}和{i,d,f}的終點為節點m時,節點m的信任傳遞對節點i和節點j之間的推薦信任評估有著重要意義。針對該問題,本文引入懲罰機制[26]并加以討論。
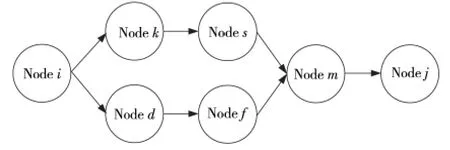
Figure 4 Punishment mechanism in recommendation trust relationship(multipath)圖4 多徑信任推薦關系中的懲罰機制
設多徑推薦信任關系模型中包含n個節點,其中含有c個自私節點和z個惡意節點,定義I為推薦路徑上第1個推薦節點是惡意節點的事件,Hk表示推薦路徑上第一個惡意節點占據第k個位置的事件,則從第k個位置開始推薦路徑上存在惡意節點的事件可以用Hk+=Hk∨Hk+1∨Hk+2∨…表示。因此,當推薦路徑上存在惡意節點的情況下,設惡意節點冒名正常節點的概率為P(I|H1+),滿足式(12):
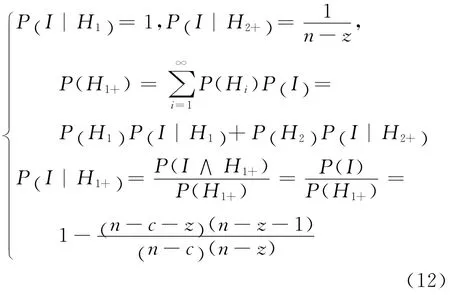
針對上述問題,引入懲罰因子ps,用于調整多徑信任推薦中一些推薦路徑的終點可能是同一個推薦節點時,該節點為惡意節點對推薦信任評估帶來的影響。如圖4所示,當兩條推薦路徑的推薦信任向量分別為(Tkj,Skj)和(Tdj,Sdj),且兩條推薦路徑中含有相同的節點m時,節點i可以根據式(13)得到節點j的新的多徑推薦信任:

其中,ω1和ω2為兩條路徑推薦信任的權重。
在引入懲罰因子后,惡意節點冒名正常節點的概率P′(I|H1+)為:
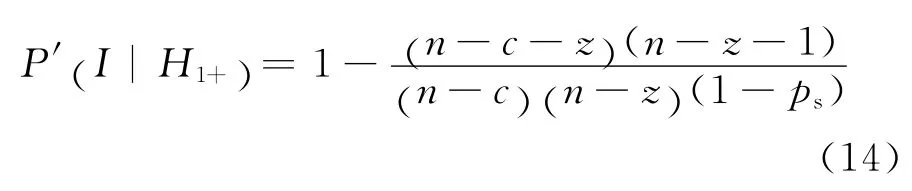
由式(12)和式(14)可以看出,引入懲罰因子ps后,惡意節點冒名正常節點的概率減少,能夠在一定程度上提高系統的可靠性。
2.3 時間因素
為體現信任評估的動態性,本文考慮時間因素對信任評估的影響。借鑒人類對歷史信息的認知方法可知,不同時期的歷史交互信息對信任評估過程產生的影響是不同的,越接近的歷史交互信息影響越大,而時間跨度越長的歷史交互信息影響越小直至對評估失去意義而不對其進行考慮。
類似文獻[27],在這里采用時間分段的概念,將時間段設置為一天,并引入時間影響力衰減因子η刻畫不同時期歷史交互信息的重要程度。因此,對于n個時間段,設時間段i的成功交互和失敗交互次數分別為αi和βi,則第n個時間段后總的交互成功次數和失敗次數α(n)和β(n)如式(15)所示:
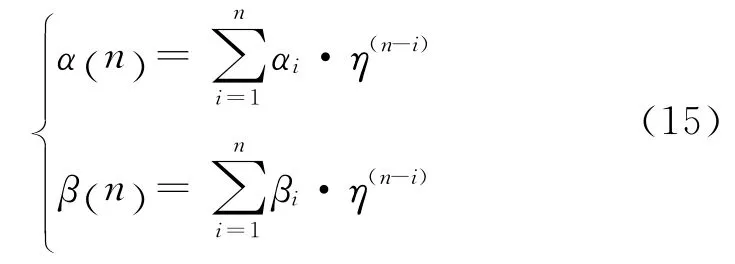
其中,0≤η≤1,η=0表示只考慮最近一次的歷史交互影響,而η=1表示不考慮時間影響力衰減因子。
3 基于Bayesian主觀信任模型的動態級調度算法
根據上一節討論的Bayesian主觀信任模型,本文充分考慮云資源節點的可信度,針對節點中存在惡意推薦問題,擴展了傳統的DLS 算法[28],使得基于有向無環圖(DAG)的云資源調度算法更加全面合理。
DLS算法是一種靜態啟發式的表調度算法,主要用于將基于DAG 的應用分配到一個異構的資源節點集合上。在調度的每一步,DLS 算法通過尋找具有最高“動態級”的任務vi-資源mj對,從而將任務vi調度到資源mj上執行,完成任務分配。任務-資源(vi-mj)對的動態級DL(vi,mj)定義如式(16)所示:
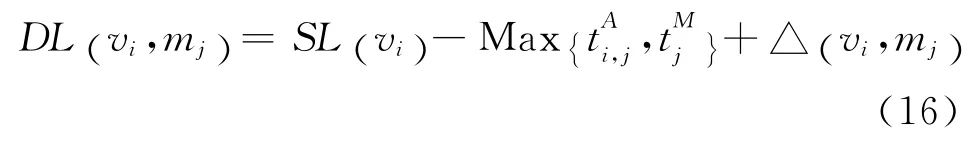
其中,SL(vi)為任務靜態級,在一個調度期間內為常數,指DAG 中從任務vi到終止節點的最大執行時間;表示任務vi在資源mj上執行的時間,表示任務vi調度到資源mj上所需輸入數據可獲得的時間,表示資源mj空閑時可以用于執行任務vi的時間;Δ(vi,mj)表示資源mj的相對計算性能,為任務vi在所有資源上的平均執行時間與其在資源mj上的執行時間之差。
當任務調度到目標節點上執行時,可信度反映目標節點提供服務的可靠程度,DLS算法考慮資源的異構性,能夠適應資源異構性的特征,但沒有考慮到云資源的可信度對任務調度效果的影響。為解決該問題,文獻[22,23]考慮節點間行為特性和歷史交互信息,提出了可信動態級調度算法,并應用到網格服務和云服務中。然而,該算法假設資源分配具有公平性,認為各節點給出的歷史交互信息都是真實可靠的,并未考慮自私節點和惡意節點對交互信息和推薦信任評估結果的影響。因此,本文引入分級剪枝過濾機制和懲罰機制,提出云環境下基于Bayesian主觀信任模型的動態級調度算法(BST-DLS),對于任務vi和云資源節點nj,其可信動態級BST-DL(vi,mj)定義如式(17)所示:

其中,TS(vi,nj)表示云資源節點ns調度任務vi到云資源節點nj上時對nj可信度的評估,即第2節中討論的合并信任度T。
4 仿真實驗及結果分析
為驗證提出的信任評估模型和動態級調度算法,本文在PlanetLab 環境[29]中設計了基于云仿真軟件CloudSim[30]的實驗平臺。分布于全球的計算機群項目PlanetLab始于2003年,由普林斯頓大學、華盛頓大學、加州大學和Intel研究人員共同開發,其目標是提供一個用于開發下一代互聯網技術的開放式全球性測試實驗平臺。在Planet-Lab的網絡模擬實驗環境中,設定節點數和節點之間的鏈路數預先給定,鏈路間的數據傳輸速度介于[1,10]Mbit/s。
云仿真軟件CloudSim 是一個通用、可擴展的新型仿真框架,它通過在離散事件模擬包SimJava上開發的函數庫支持基于數據中心的虛擬化建模、仿真功能和云資源管理、云資源調度的模擬。同時,CloudSim 為用戶提供了一系列可擴展的實體和方法,用戶根據自身的要求調用適當的API實現自定義的調度算法。本文所有的仿真實驗中,每組實驗分為10次,最終結果采用平均值。相關實驗參數設置如下:根據文獻[22,23]討論,信任關系調節因子λ和時間影響衰減因子η均設置為0.8;式(3)和式(4)中δ和γ0的取值分別為0.1 和0.95;同時按照式(18)將信任等級劃分如下:

其中,對于信任等級l(x)=0 的推薦路徑進行剪枝,對于信任等級l(x)=1 和l(x)=2 的推薦路徑,其可接受偏差范圍εl分別設為ε1和ε2。
在實際的云計算平臺中,由于不同類型的惡意節點通過組合都可以產生一類新的惡意節點,因此對惡意節點的刻畫較為困難。為簡化實驗,本文僅對以下幾類節點進行測試:(1)簡單惡意節點,這類節點提供的服務是不真實的;(2)詆毀惡意節點,這類節點詆毀與其交互過的正常節點,其目的是借此降低其信譽度;(3)合謀惡意節點,這類節點通過修改交易信息,夸大同伙節點的可信度,同時詆毀正常節點。此外,設置兩類自私節點,分別占節點總數的10%,它們在分配到任務時,以80%和50%的概率執行任務失敗。
本文首先對提出的懲罰機制和分級剪枝過濾機制進行討論,主要討論懲罰因子ps以及分級剪枝過濾機制中的參數對信任度評估的影響。
4.1 信任模型的有效性
(1)懲罰機制ps。
為考察多徑推薦信任關系中引入懲罰機制的有效性,當懲罰因子ps的取值分別為0.3、0.7、1時,對任務執行成功率進行比較。
實驗中相關參數設置如下:云資源節點數為200,鏈路數為200,任務數為100,設定網絡中存在的惡意節點為提供不真實服務的簡單惡意節點。
由式(13)可知,懲罰因子ps可以調節懲罰機制的影響力,當ps=1 時,未使用懲罰機制,而當ps的值越小則懲罰機制的影響力越強。如圖5所示,當網絡中的惡意節點不超過20%時,ps=1和ps=0.3、ps=0.7的任務執行成功率相似;隨著網絡中的惡意節點比例增加,任務執行成功率均有不同程度的降低,而當惡意節點比例超過35%時,未考慮懲罰機制時的任務執行成功率下降速度較快,且數值明顯低于其他兩類,這充分體現了本文提出的懲罰機制的有效性。

Figure 5 Impact of penalty factor ps on average ratio of successful execution圖5 懲罰因子ps 對平均執行成功率的影響
值得一提的是,當網絡中惡意節點所占比例小于10%時,未使用懲罰機制的任務執行成功率略高于使用懲罰機制的任務執行成功率。這是由于在多徑推薦信任關系模型中,懲罰機制是針對多條推薦路徑的終點為同一推薦節點,且該節點恰好為惡意節點的情況。因此,如果網絡中存在較少的惡意節點或不存在惡意節點,則該懲罰機制會在一定程度上降低算法選擇最可靠路徑的可能性,從而使得任務執行成功率有一定程度的降低。
(2)分級剪枝過濾機制。
為考察本文提出分級剪枝過濾機制的有效性,對于信任等級l(x)=1和l(x)=2的推薦路徑,對其可接受偏差(ε1,ε2)分別取(0.1,0,2)、(0.2,0,4)和不考慮該機制時的任務執行成功率進行比較。為表達清楚,用Ε1、Ε2和Ε3分別表示可接受偏差(ε1,ε2)的取值為(0.1,0,2)、(0.2,0,4)和未使用分級剪枝過濾機制的情況。
其他實驗環境設置如下:云資源節點數為200,鏈路數為200,任務數為100,懲罰因子ps=0.7,設定網絡中存在的惡意節點為提供不真實服務的簡單惡意節點。
實驗結果如圖6所示,隨著網絡中惡意節點的比例的增加,Ε1、Ε2和Ε3的任務執行成功率均有不同程度的降低,其中未考慮分級剪枝過濾機制的Ε3成功率降低較快,而Ε1和Ε2在惡意節點比例超過30%時仍然具有相對較高的任務執行成功率,說明了本文提出分級剪枝過濾機制的有效性。
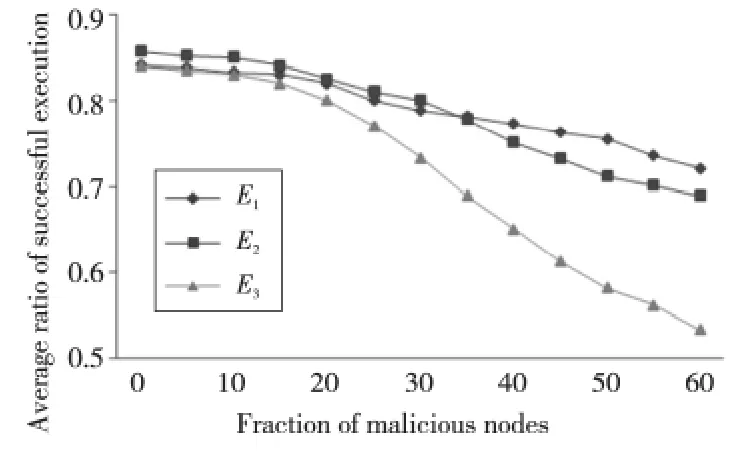
Figure 6 Impact of hierarchical pruning mechanism on average ratio of successful execution圖6 分級剪枝過濾機制對平均執行成功率的影響
當惡意節點比例超過40%時,可以看出E1的執行成功率略高于E2,說明在惡意節點比例較大的網絡環境中,適合采用更小的可接受范圍以保證任務執行的可靠性。
4.2 各類惡意節點情況下的比較
該仿真實驗針對網絡中存在三類典型的惡意節點,即簡單惡意節點、詆毀惡意節點和合謀惡意節點,比較本文提出的BST-DLS算法、Cloud-DLS算法和傳統的DLS算法在不同類型惡意節點情況下的性能。實驗相關參數設置如下:云資源節點數為200,鏈路數為200,任務數為100,設置懲罰因子ps為0.7,可接受偏差(ε1,ε2)取(0.1,0,2)。
(1)簡單惡意節點。圖7為惡意節點為簡單惡意節點情況下,BST-DLS算法、Cloud-DLS算法和傳統的DLS算法的任務執行成功率。從圖7可以看出,當增加惡意節點所占比例時,三種算法的任務執行成功率都呈下降趨勢。BST-DLS算法與Cloud-DLS算法、DLS算法相比下降速度最慢,當惡意節點比例達到40%時,Cloud-DLS 算法和DLS算法任務執行成功率分別只有50.9%和18.9%,而BST-DLS算法能夠有效地抵御惡意節點,任務執行成功率為77.4%,說明BST-DLS 算法能夠有效抑制簡單惡意節點的攻擊。
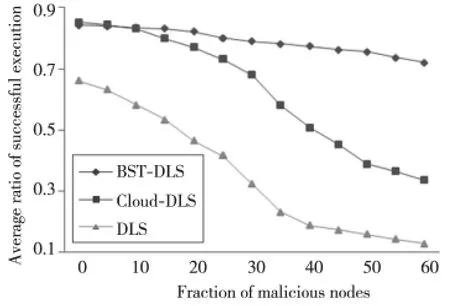
Figure 7 Average execution success ratio(simple malicious nodes)圖7 簡單惡意節點情況下的平均執行成功率
(2)詆毀惡意節點。圖8為惡意節點為詆毀惡意節點情況下,BST-DLS算法、Cloud-DLS算法和傳統的DLS算法的任務執行成功率。詆毀惡意節點通過提供不真實服務詆毀與其交易過的可信節點,通過圖8可以看出,雖然當增加惡意節點比例時,三種算法的任務執行成功率都呈下降趨勢,但是在有40%為詆毀惡意節點的情況下,BST-DLS算法仍然具有75.7%的任務執行成功率,明顯高于其他兩種算法,較為有效地抑制了詆毀惡意節點的影響。

Figure 8 Average execution success ratio(denigration malicious nodes)圖8 詆毀惡意節點情況下的平均執行成功率
(3)合謀惡意節點。圖9為惡意節點為合謀惡意節點情況下,BST-DLS算法、Cloud-DLS算法和傳統的DLS算法的任務執行成功率。合謀惡意節點通過提供不真實服務信息夸大同伙節點可信度的同時,也會詆毀與其交易過的可信節點,試圖降低可信節點的信任度。由圖9可見,當增加合謀惡意節點的比例時,三種算法的任務執行成功率同樣都呈下降趨勢,在有40%為合謀惡意節點的情況下,BST-DLS 算 法 具 有72.9%的 任 務 執 行 成 功率,明 顯 高 于Cloud-DLS 算 法 和DLS 算 法 的47.1%和19.6%。

Figure 9 Average execution success ratio(collusion malicious nodes)圖9 合謀惡意節點情況下的平均執行成功率
由上述實驗結果可以看出,本文提出的BSTDLS算法在網絡中存在三類典型的惡意節點的情況下,通過分級剪枝過濾機制和懲罰機制可以有效地抑制惡意節點,保證任務執行的可靠性。而Cloud-DLS算法和DLS算法由于并未對惡意節點作任何處理,因此當惡意節點比例增加時,惡意節點很容易獲得較高的可信度。同時,在網絡中存在詆毀惡意節點和合謀惡意節點的情況下,往往可信節點的信任度還會由于惡意節點的詆毀反而變得較低。惡意節點由此得到大量的交互,并使得這些交互失敗而導致系統可靠性降低。
4.3 不同節點數情況下的比較
該仿真實驗在網絡中具有不同節點數的情況下,比較本文提出的BST-DLS 算法、Cloud-DLS算法和DLS算法在任務執行成功率和調度長度方面的性能。實驗相關參數設置如下:設定實驗中隨機產生100~1 000個云資源節點,任務數為100,鏈路數為200;設置懲罰因子ps為0.7,可接受偏差(ε1,ε2)取(0.1,0,2),設定網絡中存在的惡意節點為提供不真實服務的簡單惡意節點,惡意節點占網絡中節點的比例為40%。

Figure 10 Average ratio of successful execution of DLS,Cloud-DLS and BST-DLS algorithms with varying numbers of nodes圖10 不同節點數下DLS、Cloud-DLS和BST-DLS的平均執行成功率比較
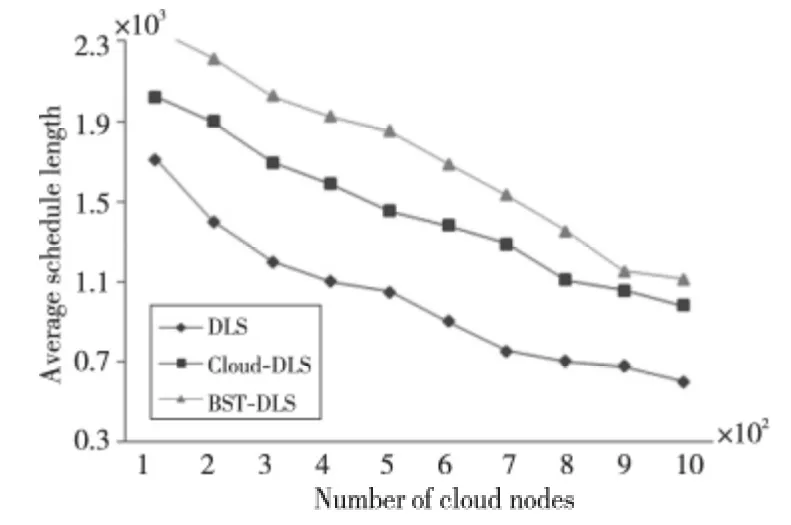
Figure 11 Average schedule length of DLS,Cloud-DLS and BST-DLS algorithms with varying numbers of nodes圖11 不同節點數下DLS、Cloud-DLS和BST-DLS的平均調度長度比較
由圖10、圖11可見,當網絡中惡意節點比例為40%時,隨著網絡中總節點數的增加,三種算法的任務執行成功率均略有提高,而調度長度均有不同程度的減少。圖10中,BST-DLS算法的平均任務執行成功率為82.39%,明顯高于Cloud-DLS算法的60.89%和DLS算法的23.48%,充分體現了本文提出BST-DLS算法的有效性。圖11中本文提出的BST-DLS算法的平均調度長度為1 721.7,高于Cloud-DLS 算 法 的1 447.1 和DLS 算 法 的1 009.6。
綜上可知,BST-DLS算法與DLS算法相比平均執行成功率和平均調度長度的增加分別為250.89%和70.53%,與Cloud-DLS算法相比平均執行成功率和平均調度長度的增加分別為35.3%和18.97%。可見,本文提出的BST-DLS 算法雖然能夠顯著地提高系統的可靠性,但在獲得較高的任務執行成功率的同時,也犧牲了一定的調度長度,且該算法在可靠性方面性能的提高遠高于所增加的調度長度。
5 結束語
本文深入研究云環境下節點間直接信任及推薦信任的傳遞與合成問題,針對云環境中存在自私節點和惡意節點的情況,引入懲罰機制和分級剪枝過濾機制,通過對云環境下節點可信度的評估,提出一種云環境下基于Bayesian方法的主觀信任模型和相應的可信動態級調度算法。該算法作為一種有效的評價分析和推導工具,能夠為云環境中主體節點的信任決策提供有效的支持,使得應用任務在值得信賴的環境下運行。本文的下一步工作將考慮云環境中的相關安全機制與時間花費、價格花費等服務質量因素相結合,滿足不同用戶的服務質量要求。
[1] Rajkumar B,Shin Y C,Broberg V S,et al.Cloud computing and emerging IT platforms:Vision,hype,and reality for delivering computing as the 5th utility[J].Future Generation Computer Systems,2009,25(6):599-616.
[2] Darbha S,Agrawal D P.Optimal scheduling algorithm for distributed memory machines[J].IEEE Transactions on Parallel and Distributed Systems,2002,9(1):87-95.
[3] Lee Y C,Zomaya A Y.A novel state transition method for metaheuristic-based scheduling in heterogeneous computing systems[J].IEEE Transactions on Parallel and Distributed Systems,2008,19(9):1215-1223.
[4] Zhu D,Mosse D,Melhem R.Power-aware scheduling for and/or graphs in real-time systems[J].IEEE Transactions on Parallel and Distributed Systems,2004,15(9):849-864.
[5] Kim K H,Buyya R,Kim J.Power aware scheduling of bagof-tasks applications with deadline constraints on DVS-enabled clusters[C]∥Proc of the 7th IEEE International Symposium on Cluster Computing and the Grid,2007:541-548.
[6] Bunde D P.Power-aware scheduling for makespan and flow[J].Journal of Scheduling,2009,12(5):489-500.
[7] Li M S,Yang S B,Fu Q F,et al.A grid resource transaction model based on compensation[J].Journal of Software,2006,17(3):472-480.
[8] Xu B M,Zhao C Y,Hua E Z,et al.Job scheduling algorithm based on Berger model in cloud environment[J].Advances in Engineering Software,2011,42(3):419-425.
[9] Buyya R,Murshed M M,Abramson D,et al.Scheduling parameter sweep applications on global grids:A deadline and budget constrained cost-time optimization algorithm[J].Software Practice and Experience,2005,35(5):491-512.
[10] Blanco C V,Huedo E,Montero R S,et al.Dynamic provision of computing resources from grid infrastructures and cloud providers[C]∥Proc of Grid and Pervasive Computing Conference,2009:113-120.
[11] Topcuoglu H,Hariri S,Wu M Y.Performance-effective and low complexity task scheduling for heterogeneous computing[J].IEEE Transactions on Parallel and Distributed Systems,2002,13(3):260-274.
[12] Mezmaz M,Melab N,Kessaci Y,et al.A parallel bi-objective hybrid metaheuristic for energy-aware scheduling for cloud computing systems[J].Journal of Parallel and Distributed Computing,2011,71(10):1497-1508.
[13] Dogan A,Ozguner F.Reliable matching and scheduling of precedence constrained tasks in heterogeneous distributed computing[C]∥Proc of the 29th International Conference on Parallel Processing,2000:307-314.
[14] Dogan A,Ozguner F.Matching and scheduling algorithms for minimizing execution time and failure probability of applications in heterogeneous computing[J].IEEE Transactions on Parallel and Distributed Systems,2002,13(3),308-323.
[15] Dai Yuan-sun,Xie Min.Reliability of grid service systems[J].Computers and Industrial Engineering,2006,50(1/2):130-147.
[16] Levitin G ,Dai Yuan-sun.Service reliability and performance in grid system with star topology[J].Reliability Engineering and System Safety,2007,92(1):40-46.
[17] Foster I,Zhao Y,Raicu I,et al.Cloud computing and grid computing 360-degree compared[J].IEEE Grid Computing Environments(GCE 2008),2008:1.
[18] Blaze M,Feigenbaum J,Lucy J.Decentralized trust management[C]∥Proc of the IEEE Computer Society Symposium on Research in Security and Privacy,1996:164-173.
[19] Josang A.Trust-based decision making for electronic transactions[C]∥Proc of the 4th Nordic Workshop on Secure Computer Systems(NORDSEC’99),1999:1.
[20] Josang A.A logic for uncertain probabilities[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2001,9(3):279-311.
[21] Wang W,Zeng G S,Yuan L L.A reputation multi-agent system in semantic web[C]∥Proc of the 9th Pacific Rim International Workshop on Multi-Agents,2006:211-219.
[22] Wang W,Zeng G S,Tang D Z,et al.Cloud-DLS:Dynamic trusted scheduling for cloud computing[J].Expert Systems with Applications,2012,39(5):2321-2329.
[23] Mui L,Mohtashemi M,Halberstadt M.A computational model of trust and reputation[C]∥Proc of the 35th Hawaii International Conference on System Sciences,2002:1.
[24] Thomas L,John S J.Bayesian methods:An analysis of statisticians and interdisciplinary[M].New York:Cambridge University Press,1999.
[25] Jameel H,Hung L X,Kalim U,et al.A trust model for ubiquitous systems based on vectors of trust values[C]∥Proc of the 7th IEEE International Symposium on Multimedia,2005:674-679.
[26] Shi Jin-qiao,Cheng Xiao-ming.Research on penalty mechanism against selfish behaviors in anonymous communication system[J].Journal on Communication,2006,27(2):80-86.(in Chinese)
[27] Josang A,Ismail R.The beta reputation system[C]∥Proc of the Bled Conference on Electronic Commerce,2002:1.
[28] Sih G C,Lee E A.A compile-time scheduling heuristic for interconnection-constraint heterogeneous processor architectures[J].IEEE Transactions on Parallel and Distributed Systems,1993,4(2):175-187.
[29] Peterson L,Bavier A,Fiuczynski M,et al.Towards a comprehensive PlanetLab architecture[R].Technical Report PDN-05-030.New Jersey:PlanetLab Consortium,2005.
[30] Calheiros R N,Ranjan R,De Rose C A F,et al.CloudSim:A novel framework for modeling and simulation of cloud computing infrastructures and services[R].Technical Report GRIDS-TR-2009-1.Australia:Grid Computing and Distributed Systems Laboratory,The University of Melbourne,2009.
附中文參考文獻:
[26] 時金橋,程曉明.匿名通信系統中自私行為的懲罰機制研究[J].通信學報,2006,27(2):80-86.
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
