基于協(xié)同過濾的Web緩存替換算法研究*
2015-03-19 00:33:26吳俊龍
計算機工程與科學 2015年11期
吳俊龍,楊 清
(湖南科技大學計算機科學與工程學院,湖南 湘潭411201)
1 引言
隨著信息技術的迅猛發(fā)展,互聯(lián)網(wǎng)已深入滲透社會生活的各個方面,網(wǎng)絡接入用戶數(shù)與信息數(shù)據(jù)量的急劇增加導致各種網(wǎng)絡問題日益明顯,線路擁塞和服務器超載加劇了訪問延遲,嚴重影響了用戶網(wǎng)絡訪問體驗。為解決這些問題,研究人員提出了各種解決方案,最具代表性的是Web緩存技術,該技術利用了Web訪問模式的時間局部性,可有效提升用戶網(wǎng)絡訪問體驗。其基本原理是:代理服務器預先存儲一些網(wǎng)絡文件以備用戶訪問,若存儲空間不足,則按照某種標準將過期的網(wǎng)絡文件進行替換,以保持文件的新鮮度,并保證緩存空間的可用性。當有新的用戶請求到達時,代理服務器將已存儲的請求文件反饋給用戶,從而減少用戶感知的訪問延時[1,2]。
緩存替換算法是Web緩存技術的核心,可分為以下四種類型[3]:基于時間特性的替換算法、基于頻率特性的替換算法、基于文件大小的替換算法和基于成本/價值模型的替換算法。前三種類型的替換算法分別考慮了用戶訪問的時間特性、頻率特性與Web文件的大小特性,實現(xiàn)起來較為簡單,但性能較差,而基于成本/價值模型的替換算法通過綜合考慮各種影響因素為Web 對象計算緩存價值,在性能與系統(tǒng)開銷之間取得了不錯的均衡,是今后主要研究方向之一。
本文在成本/價值模型的基礎上,研究了Web對象之間和用戶之間的關聯(lián)性,并將協(xié)同過濾思想應用于貪婪雙尺寸頻率緩存替換算法GDSF(Greedy Dual Size Frequency)[4],提出一種基于協(xié)同過濾的Web 緩存替換算法GDSF-CF(Greedy Dual Size Frequency Collaborative Filtering)。該算法運用協(xié)同過濾算法的思想考察用戶-文件以及文件-文件之間的關系,計算緩存空間中每個文件的預測訪問頻率并形成關于緩存價值的目標函數(shù),然后通過計算得到文件的緩存價值,最后將對最小緩存價值的文件進行替換。
2 研究現(xiàn)狀
作為Web緩存替換策略的核心技術之一,緩存替換算法已有大量研究成果,Geetha K[5]提出了SEMA-LRU (SEMAntic and Least Recently Used)替換算法,SEMA-LRU 在LRU(Least Recently Used)的基礎上,依據(jù)網(wǎng)頁內(nèi)容的語義關聯(lián)和最近訪問次數(shù)來判斷是否將網(wǎng)頁替換出去。Lee D 和Kim K J[6]使用了延遲緩存替換策略保證用戶穩(wěn)定訪問體驗,當請求數(shù)量出現(xiàn)異常高時,代理服務器不會將網(wǎng)頁緩存,而只記錄數(shù)據(jù)的元信息,當請求數(shù)量恢復至正常值后,再使用這些數(shù)據(jù)元信息為用戶請求數(shù)據(jù),通過緩解服務器的負載為大多數(shù)用戶提供穩(wěn)定的服務質(zhì)量。張旺俊[7]運用成本/價值模型,在貪婪雙尺寸頻率緩存替換算法GDSF 的基礎上提出了一種改進的GDSF-AI(Greedy Dual Size Frequency Access Interest)替換算法,該算法綜合考慮Web 對象的訪問特性、Web對象所屬的內(nèi)容類型以及用戶興趣,為緩存空間中的每個Web對象計算緩存價值,然后將價值最小的Web 對象從緩存空間中替換出去。
同樣作為訪問加速技術的一種,協(xié)同過濾技術CF(Collaborative Filtering)[8]通過分析用戶的興趣與愛好,在用戶群中為指定用戶找出具有相似興趣用戶,綜合這些相似用戶對某一信息的評價,形成系統(tǒng)對該指定用戶對此信息的喜好程度預測。這種技術能夠根據(jù)相似用戶的評分來預測當前用戶的興趣。協(xié)同過濾的核心技術是協(xié)同過濾算法,一般而言可將協(xié)同過濾算法分成兩種類型:基于內(nèi)存的協(xié)同過濾(Memory-based CF)和基于模型的協(xié)同過濾(Model-based CF)。基于內(nèi)存的協(xié)同過濾算法運用十分廣泛,這種類型的算法可以基于用戶,也可以基于對象,或者是用戶對象兩者混合形式。基于用戶的協(xié)同過濾(User-based CF)根據(jù)相似用戶的評分預測當前用戶的評分;而基于對象的協(xié)同過濾(Item-based CF)根據(jù)相似對象的評分預測當前用戶的評分。基于模型的協(xié)同過濾算法首先對用戶評分數(shù)據(jù)信息進行分析,然后在此基礎上進行學習并建立一個預測模型,最后利用這個模型來進行關于用戶評分值的預測。此種類型的預取算法通過利用統(tǒng)計方法和機器學習這兩種途徑建立模型,包括聚類模型、貝葉斯模型關系模型、線性回歸模型等。本文選用了基于內(nèi)存的協(xié)同過濾算法,通過此種類型的協(xié)同過濾技術來為貪婪緩存替換算法進行改進。
3 GD系列算法
GD(Greedy Dual)算法是一種基于代價的貪婪算法,在一個代理服務器的存儲空間中,有多個Web對象i,GD 替換算法根據(jù)每個Web對象緩存所需的代價為其賦值一個數(shù)值H,當存儲空間不足需要進行Web對象替換時,H值最小的Web對象會被最先替換出去,然后根據(jù)最小H值來調(diào)整剩余頁面的H值。但是,該類算法存在“緩存污染”問題,即存儲空間會駐留大量長時間沒有被訪問的大尺寸Web對象。
GDS(Greedy Dual Size)是一種改進的貪婪緩存替換算法,該類算法針對GD 算法的“緩存污染”問題進行了改進,GDS算法使用一個優(yōu)先級序列,并且為將來的H值設置了偏差。H值的目標函數(shù)如下所示:
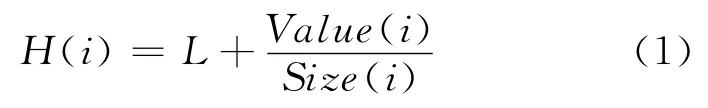
其中,Value(i)為Web對象i的緩存價值;Size(i)為i的尺寸大小;L為替換變量參數(shù),每次有Web對象被替換出去時,L都會被重新賦值為價值最小的、被替換出去的Web對象的價值H(i)。
GDS簡單明了,但是沒有考慮Web對象的內(nèi)容類型、訪問頻率、訪問時間間隔以及流行度,可能會出現(xiàn)以下情況:在存儲空間內(nèi)存在一組Web對象,根據(jù)目標函數(shù)的計算每個Web對象具有相同的H值,但是各個對象的訪問頻率不一致,具有較高訪問頻率的Web對象反而可能會被替換出存儲空間,不符合Web 對象訪問特性的局部性規(guī)律。針對該類問題,通過為目標函數(shù)引入Web對象的訪問頻率,提出了GDSF 算法。該算法充分考慮了Web對象的尺寸大小、緩存代價以及訪問頻率。其目標函數(shù)如下所示:
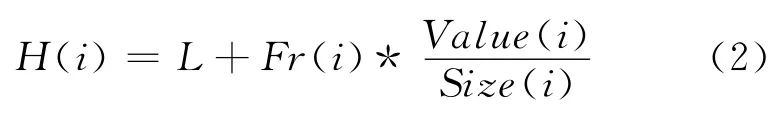
其中,F(xiàn)r(i)為Web對象i的訪問頻率。
GDSF算法通過在目標函數(shù)的計算中加入Web對象的訪問頻率,可有效提高緩存替換效率,但對Web對象的內(nèi)容類型、流行度以及修改頻率這幾個因素缺乏關注,GDSF算法還有進一步改進的空間。
4 GDSF-CF算法
4.1 算法描述
GDSF-CF替換算法將協(xié)同過濾中的項目作為Web對象處理,并將用戶對項目的評分值歸一化為用戶對文件的訪問頻率,通過相似度的計算來預測文件的用戶訪問頻率,并最終建立目標函數(shù)計算文件的緩存價值,如以下三個步驟:
(1)運用協(xié)同過濾算法生成用戶對于Web對象的預測訪問次數(shù);
(2)考慮齊普夫定律參數(shù)與訪問時間間隔因素建立Re(i)參數(shù);
(3)結合上述各項參數(shù)建立關于Web對象緩存價值的目標函數(shù)。
下面就GDSF-CF算法的原理做出具體描述:
(1)形成相似Web對象集合。
①計算Web 對象之間的相似性。訪問過Web對象i與Web對象j的用戶可形成用戶Ui,j,Ui,j=Ui∩Uj,c為Ui,j中的任意一個用戶。計算i,j之間的相似度可以使用皮爾孫算法,如公式(1)所示:
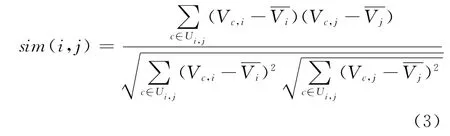
其中,sim(i,j)為i、j之間的相似度,Vc,i與Vc,j分別是用戶c訪問i與j的統(tǒng)計次數(shù),和分別為每個用戶訪問i與j的平均統(tǒng)計次數(shù)。由于緩存空間中的Web對象具有相對穩(wěn)定性,即新進入的Web對象不會被立即替換出緩存空間,因此可在系統(tǒng)處于離線時計算對象之間的相似度,然后將所得數(shù)值存放于數(shù)據(jù)列表中。
②形成每個Web對象的相似集合。對緩存空間中任意Web對象k,在整個對象集合上進行搜索,選取并集合與k相似度最高的前H個Web對象,作為k的相似對象集SIk。
③計算預測訪問次數(shù)Va,k。設用戶a與用戶b分別訪問過不同的Web對象,這些Web對象的并集為Ia,b,Ia,b=Ia∪Ib,有Web對象k和n,k∈Ia,b,n∈SIk,目標用戶a未訪問過k,可通過SIk預測用戶a訪問k的次數(shù)Va,k,如公式(4)所示:
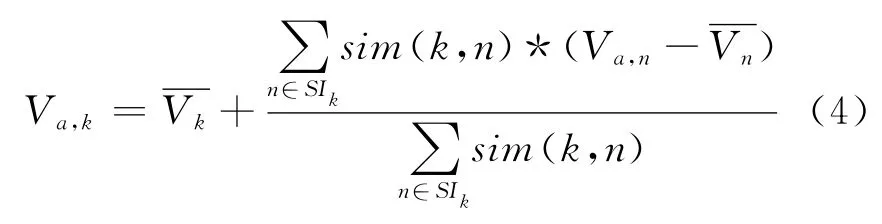
通過公式(4)可計算出緩存空間內(nèi)任意用戶對于緩存空間中任意Web對象i的預測訪問次數(shù),其值可用V(i)來表示。
(2)計算Re(i)頻率參數(shù)。
本文考慮到緩存空間中的Web對象有可能被用戶再次訪問,為此設置了一個相關參數(shù)Re(i),Re(i)與用戶訪問頻率因素相關,Web對象的流行度、訪問頻率和用戶訪問請求之間的時間間隔均對用戶再次訪問的概率有較大影響。結合齊普夫(Zipf)定律[8]以及本文提出的用戶預測訪問次數(shù)參數(shù)V(i)來對用戶訪問頻率因素Re(i)進行計算,如公式(5)所示:
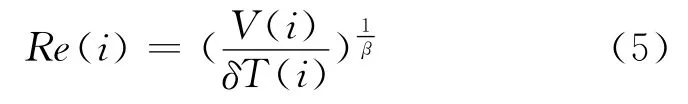
其中,V(i)是用戶訪問i的預測次數(shù),δT(i)是用戶請求i的時間間隔,β是齊普夫定律中的參數(shù)。
(3)計算節(jié)省數(shù)據(jù)包的價值。
將Web對象i引入緩存空間也需考慮付出的代價值,通常在緩存策略中考慮以下三種類型的代價值:常數(shù)、延遲時間和數(shù)據(jù)包個數(shù)。為了準確衡量因使用緩存替換算法而節(jié)省下來的數(shù)據(jù)包傳送個數(shù),本文選擇數(shù)據(jù)包的傳送個數(shù)作為代價,其代價值為Value(i)。因TCP分段大小為536bytes,Value(i)的計算如公式(6)所示:
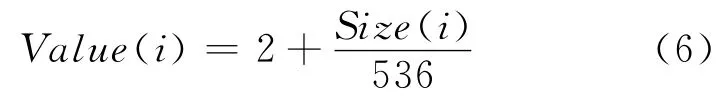
(4)形成計算緩存價值的目標函數(shù)。
根據(jù)以上關于各種因素的計算,在貪婪雙尺寸頻率替換算法GDSF 的基礎上,本文提出了一種結合協(xié)同過濾技術的緩存替換算法GDSF-CF。在緩存替換過程中,該算法利用目標函數(shù)公式計算Web對象的緩存價值并對最小緩存價值的對象進行替換。其目標函數(shù)如公式(7)所示:
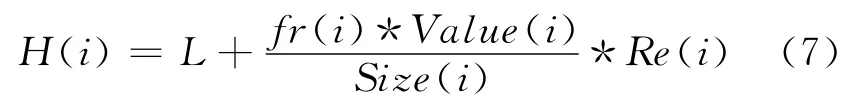
其中,參數(shù)L是一個膨脹因子,Value(i)為獲取Web對象i所需的代價,Size(i)為Web對象i的尺寸大小。
4.2 算法流程
為方便介紹GDSF-CF算法替換流程,首先設置如下參數(shù):
L:為初始閾值,當有最小緩存價值H(i)min的Web對象從緩存空間中替換出去時,L會被重新賦值,其值為H(i)min;
fr(i):用戶訪問Web對象i的次數(shù),初始值為1;
Value(i):引入Web 對象i至緩存空間所需付出的代價;
Ctotal:緩存空間的總大小;
Cused:已使用的緩存空間大小;
Size(i):Web對象i的尺寸大小。
GDSF-CF具體流程如下所示:
(1)初始參數(shù),令L=0,Cused=0。
(2)如果緩存空間中已有用戶請求的Web對象i,則令fr(i)增加1,即fr(i)=fr(i)+1,Cused的值不發(fā)生改變。
(3)如果緩存空間中不存在用戶請求的Web對象i,則表示用戶請求沒有被命中,此時用戶請求將會轉交至遠程Web服務器,通過與Web服務器的直接連接獲取Web對象i,然后將此Web對象i保存至緩存空間中,待下次使用。
此時令fr(i)=1,即Web對象i訪問次數(shù)為1,根據(jù)替換算法的目標函數(shù)公式(8)計算Web對象i的緩存價值H(i),由于緩存空間發(fā)生改變,有:
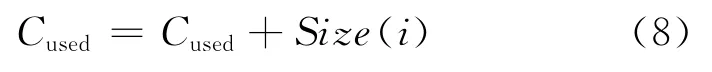
依據(jù)剩余空間大小,接下來會有兩種狀況:
①Cused≤Ctotal,表明剩余緩存空間充裕,則可以將Web對象i直接放入緩存空間中,無需進行緩存替換。
②Cused>Ctotal,剩余緩存空間不足,Web對象i無法放入緩存空間,需要進行緩存替換以釋放空間。可在緩存空間中選取n個緩存價值H(i)的Web 對 象,形 成Web 對 象 組i1,i2,…,in,這 組Web對象滿足以下兩個條件:
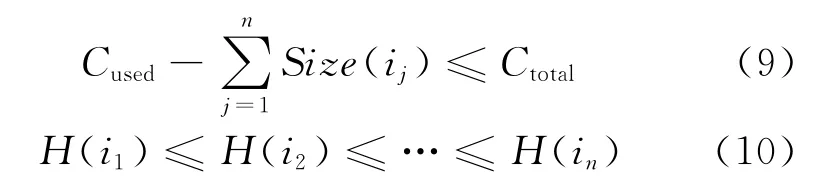
按照用戶請求的Web對象i所處位置,分為以下兩種情況:
a Web對象i位于這一組Web對象中,表明i的緩存價值很小,沒必要進行緩存,也無需替換緩存空間中的任何對象,恢復Cused值至原值即可。
b Web對象i不處于這一組Web對象中,表明i的緩存價值超過了這組對象,則令L取值為這一組Web對象中最大的緩存價值H(i),其值為H(i)max,Cused的取值也發(fā)生變化,計算公式如下:
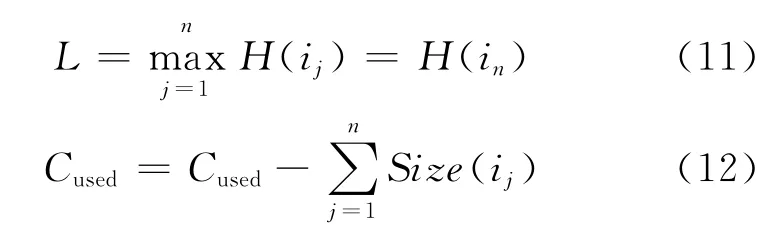
然后計算出L與Cused的數(shù)值,從緩存空間中替換出這n個對象i1,i2,…,in,最后將Web對象i保存至緩存空間中,完成緩存過程。
GDSF-CF算法的偽代碼如下所示:
算法1 GDSF-CF算法
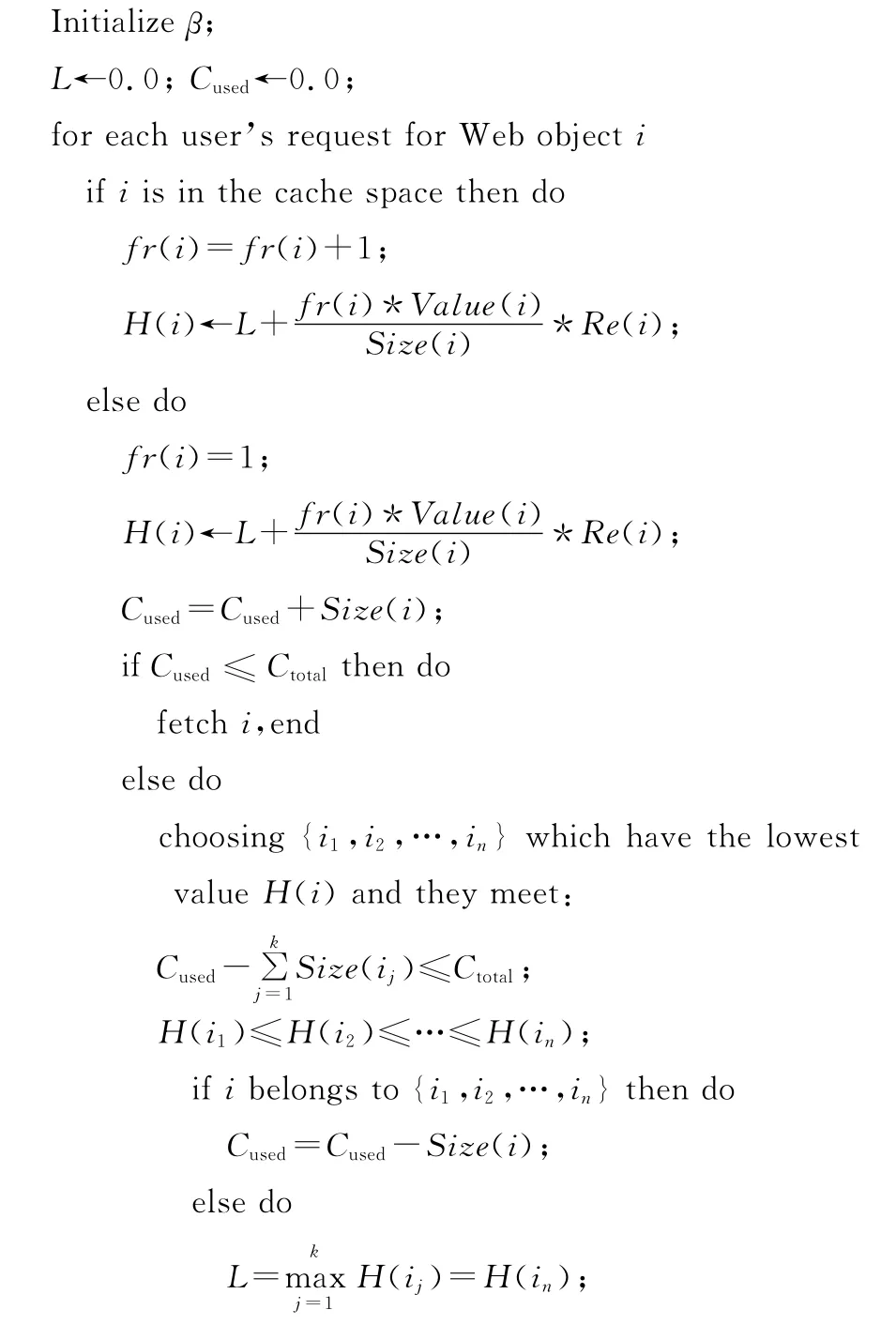
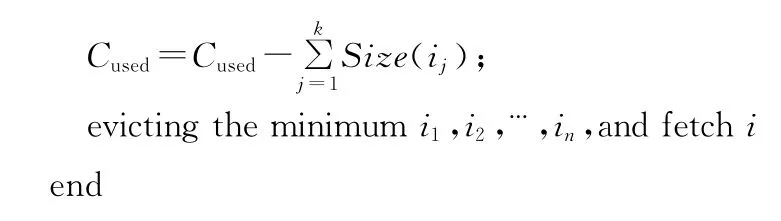
5 仿真實驗
5.1 實驗環(huán)境
仿真實驗使用了SimpleScalar模擬器[9]作為仿真平臺,輸入數(shù)據(jù)采用來自銳捷緩存加速器RGPowerCache W5中的訪問日志,共473 134條請求記錄,日志總容量為199 MB,整個實驗在一臺DELL服務器上進行,該服務器配置為至強E7520 1.866GHz處理器,16GB DDR3內(nèi)存,運行Red Hat Linux 9.0系統(tǒng)。
5.2 測試數(shù)據(jù)和實驗分析
首先,按照不同的文件擴展名,將各類型的Web加以區(qū)分,確定各種類型的Web文件在所有用戶請求記錄中所占的比例。Web文件類型可分為文本、圖像、音頻、視頻、程序和其他六種類型,經(jīng)處理后得到的結果如表1所示。
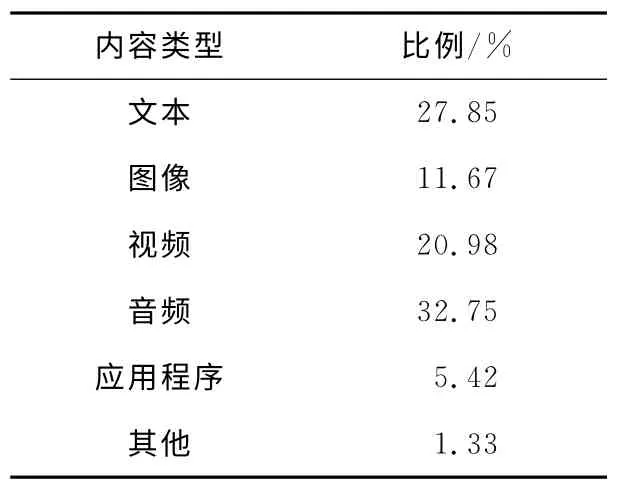
Table 1 Types of Web objects表1 Web對象類型
隨后,將用戶的服務器訪問日志發(fā)送至日志處理程序,經(jīng)過處理后輸出為SimpleScalar模擬器可以處理的格式,然后輸入至SimpleScalar的Simcache模擬器進行仿真實驗。本文采用了SIZE、LRU 與GDSF 這三種經(jīng)典緩存替換算法與GDSF-CF算法進行性能對比。
表2為仿真實驗所得到的各種算法命中率HR比較結果。
表3為為仿真實驗所得到的各種算法字節(jié)命中率BHR 比較結果。
本文采用了以下兩種指標衡量替換算法的性能:請求命中率HR(Hit Rate)和字節(jié)命中率BHR(Byte Hit Rate)
圖1表示的是輸入的日志文件在緩存相對大小分別 為1%、2%、3%、5%、10%、20%的條件下,GDSF-CF算法命中率與其他算法命中率的比較。當緩存相對大小處于0%~5%時,GDSF-CF 的命中率從0.377上升至0.472,命中率隨著緩存相對大小的增加而持續(xù)提高,最高可達到0.512,但是命中率不會一直持續(xù)增加,而是逐漸趨于平穩(wěn)。相對于GDSF算法的命中率,GDSF-CF 的命中率提升了12%。
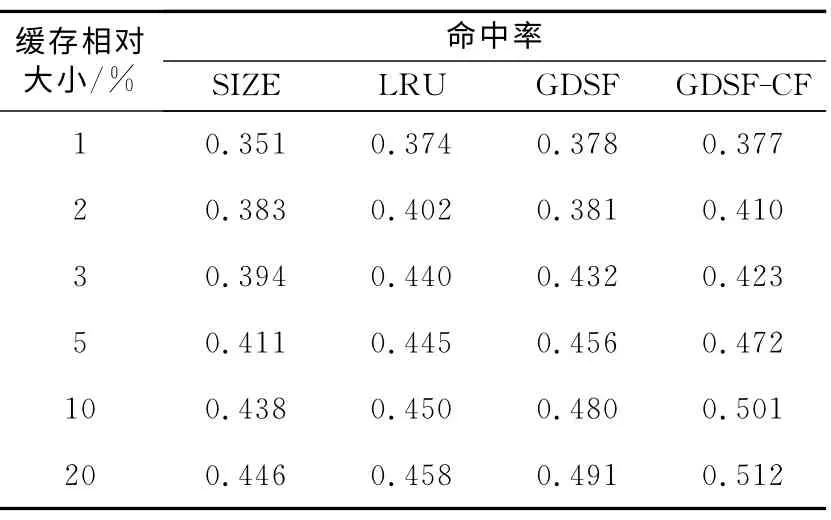
Table 2 Results of hit rate表2 算法命中率HR
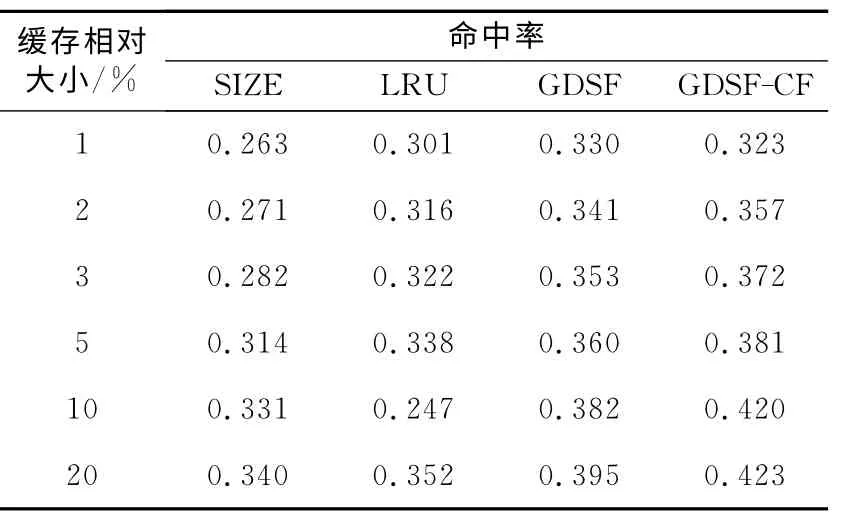
Table 3 Results of byte hit rate表3 算法字節(jié)命中率BHR
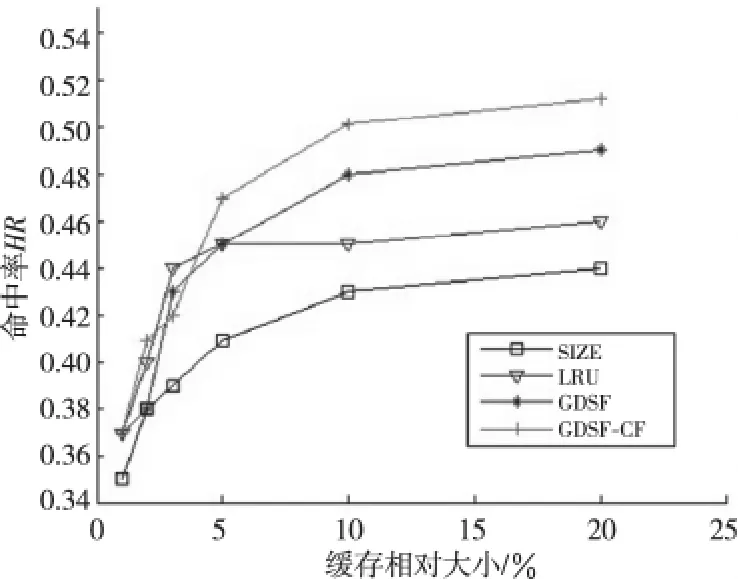
Figure 1 Comparison of hit rate圖1 算法命中率比較
圖2 表示的是在緩存相對大小分別為1%、2%、3%、5%、10%、20%的條件下,GDSF-CF算法字節(jié)命中率與其他算法字節(jié)命中率的比較。當緩存相對大小處于5%~10%時,GDSF-CF 的字節(jié)命中率從0.381 上升至0.420,最大可以達到0.423。與命中率的增幅情況相類似,字節(jié)命中率不會一直持續(xù)增加,而是逐漸趨于平穩(wěn)。相對于GDSF算法,GDSF-CF的字節(jié)命中率提升了9%。
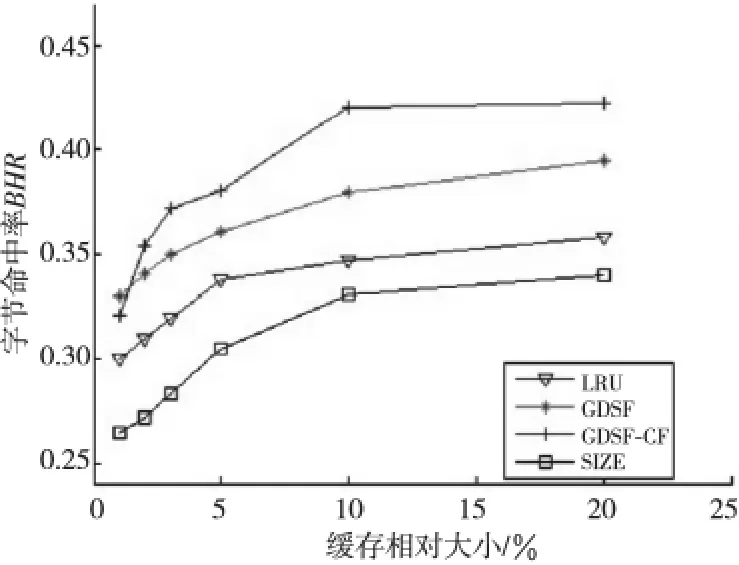
Figure 2 Comparison of byte hit rate圖2 算法字節(jié)命中率比較
6 結束語
Web緩存技術是提升用戶訪問體驗、優(yōu)化帶寬使用率的快速捷徑。緩存替換算法是Web緩存研究中的核心問題之一,由于替換算法的性能對環(huán)境因素的設置相當敏感,不同設置環(huán)境下導致替換效果具有差異性。本文綜合考慮各項因素對Web對象的影響,針對GDSF 算法在預測方面的不足,提出了基于協(xié)同過濾的緩存替換算法GDSF-CF。實驗結果表明,GDSF-CF 算法較GDSF 算法具有更好的命中率和字節(jié)命中率。
[1] World Internet Usage and Population Statistics[R].NY:Internet World Stats,2009.
[2] Deshpande S.Systems and methods for implementing a cache model:U S Patent Application 10/737,543[P].2003-12-16.
[3] Song Bing.Research on web prefetch and web cache model[D].Zhengzhou:Zhengzhou University,2006.(in Chinese)
[4] Cherkasova L.Improving www proxies performance with greedy-dual-size-frequency caching policy[R].H P Laboratories Report No HPL-98-69R1.Palo Alto:Hewlett-Packard Laboratory,1998.
[5] Geetha K.SEMALRU:An implementation of modified web cache replacement algorithm[C]∥Proc of Nature &Biologically Inspired Computing,2009:1406-1410.
[6] Lee D,Kim K J.A study on improving web cache server performance using delayed caching[C]∥Proc of 2010International Conference on Information Science and Applications(ICISA),2010:1-5.
[7] Zhang Wang-jun.Research of web cache replacement policy and pre-fetching[D].Hefei:University of Science and Technology of China,2011.(in Chinese)
[8] Fan Bo,Cheng Jiu-jun.Multiple similarity between users in collaborative filtering recommendation algorithm [J].Computer Science,2012,39(1):23-26.(in Chinese)
[9] Ma Hai-feng,Yao Nian-min,F(xiàn)an Hong-bo.Cache performance simulation and analysis under SimpleScalar platform[C]∥Proc of International Conference on New Trends in Information and Service Science,2009:607-612.
附中文參考文獻:
[3] 宋冰.Web 預取與緩存一體化模型研究[D].鄭州:鄭州大學,2006.
[7] 張旺俊.Web 緩存替換策略與預取技術的研究[D].合肥:中國科學技術大學,2011.
[8] 范波,程久軍.用戶間多相似度協(xié)同過濾推薦算法[J].計算機科學,2012,39(1):23-26.
猜你喜歡
當代陜西(2019年18期)2019-10-17 01:48:58
華人時刊(2019年23期)2019-05-21 03:31:36
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
商用汽車(2016年11期)2016-12-19 01:20:16
小天使·四年級語數(shù)英綜合(2016年11期)2016-11-29 22:37:30
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
